



LlamaIndex基础知识
核心概念
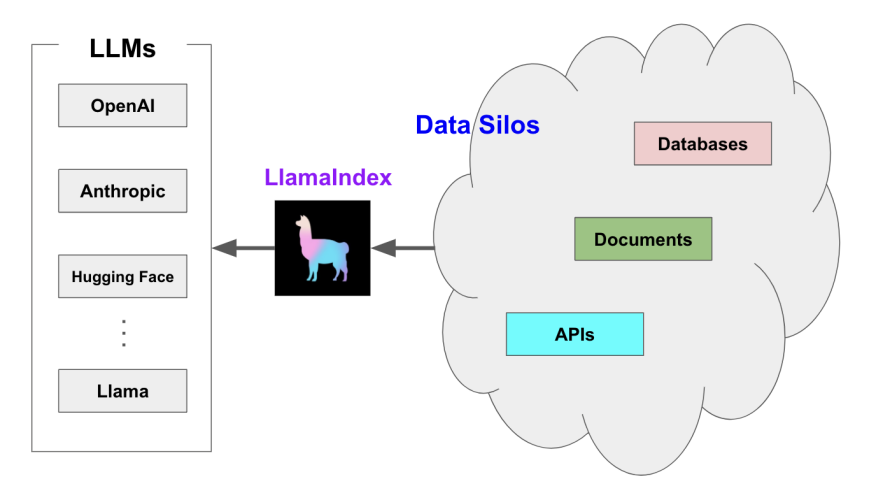
# 什么是LlamaIndex LlamaIndex是一个专注增强LLM数据处理和查询能力的工具库,用于数据注入、数据结构化、并访问私有或特定领域数据 数据注入:将私有或特定领域数据引入到大模型的过程(使LLM能够在特定的上下文或领域中更好的理解和生成信息) 数据结构化:将非结构化的数据转变成结构化格式的过程(自由文本、图片-->表格或数据库格式) 解决数据和大模型之间的衔接问题(将需要访问的私有或特定领域的数据分散在不同的应用程序和数据存储中) # RAG(检索增强生成):检索个人或私域数据来增强LLM的一种范式(用于解决大模型幻觉问题) 索引阶段 查询阶段 # 增强模型的方法 微调 RAG:通过数据来增强模型的技术
LlamaIndex五大核心工具
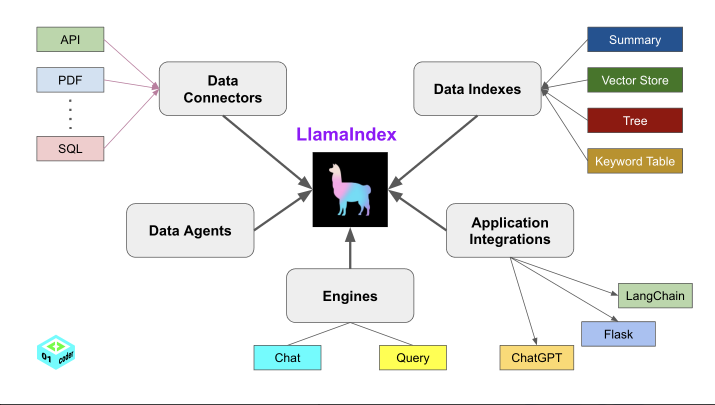
# 数据连接器(Data Connectors):用于从多样化源数据中提取数据并转换为结构化文档(Document对象:文本和元数据) from llama_index import SimpleDirectoryReader documents = SimpleDirectoryReader("./data").load_data() # 加载本地数据 # 数据索引(Data Indexes):将原始数据构建成为高效查询的索引结构(向量索引:通过嵌入模型将文本转换为词向量)
from llama_index import VectorStoreIndex index = VectorStoreIndex.from_documents(documents) # 创建向量索引 index.storage_context.persist(persist_dir="./storage") # 持久化索引 # 引擎(Engines):用于加载大模型(查询引擎、聊天引擎)
query_engine = index.as_query_engine()
response = query_engine.query("LlamaIndex的核心功能是什么?") # 执行查询
chat_engine = index.as_chat_engine()
response = chat_engine.chat("请解释数据索引的作用。") # 多轮对话 # 数据代理(Data Agents):由LLM驱动的智能代理,通过工具自动化处理数据任务 Agent = LLM(大脑) + Tools(手脚):通过自然语言理解任务,动态选择工具执行 核心价值:将静态的RAG系统升级为自主迭代的智能体 from llama_index.core.agent import ReActAgent from llama_index.core.tools import QueryEngineTool # 将查询引擎封装为工具供Agent调用 tool = QueryEngineTool.from_defaults(query_engine=query_engine) agent = ReActAgent.from_tools([tool], llm=llm) response = agent.chat("总结最近新增文档的核心观点") # 应用集成(Application Integrations):提供丰富的应用集成选项(如向量数据库集成、应用框架集成和与模型服务的对接) from llama_index.vector_stores.chroma import ChromaVectorStore import chromadb # 连接Chroma数据库 chroma_client = chromadb.PersistentClient(path="./chroma_db") vector_store=ChromaVectorStore(chroma_collection=chroma_client.create_collection("docs")) index = VectorStoreIndex.from_documents(documents,vector_store=vector_store)
索引阶段
索引阶段:通过数据连接器和索引构建知识库

查询阶段
查询阶段:从知识库检索相关上下文信息,以辅助LLM回答问题
# 在查询阶段,RAG管道根据的用户查询,检索最相关的上下文,并将其与查询一起传递给LLM,LLM合成响应 # RAG中查询挑战 # 检索 数据准确性:知识库中的信息如果过时或错误,检索结果就不可靠 嵌入向量问题(Embedding模型):文本转换为词向量不准确 # 排序(编排) 排名算法的不稳定:不够强大的排序算法可能把不相关结果排在前面 相关性与多样性平衡:需要找到相关性和答案多样性之间的平衡 # 模型推理能力 模型理解能力有限:某些生成模型可能理解上下文的能力较差,影响答案质量 上下文复杂性:复杂的上下文可能导致模型难以准确推理 # 查询阶段的构建包含 Retrievers(检索器):定义如何高效地从知识库查询检索相关上下文信息 Node Postprocessors(Node后处理器):对一系列文档节点(Node)实施转换、过滤、排名 Response Synthesizers(响应合成器):基于用户的查询,和一组检索到的文本块(形成上下文),利用LLM生成响应 # RAG管道包括 Query Engines查询引擎 端到端的管道,允许用户基于知识库,以自然语言提问,并获得回答,以及相关的上下文 Chat Engines聊天引擎 端到端的管道,允许用户基于知识库进行对话(多次交互,会话历史) Agents代理 它是一种由LLM驱动的自动化决策器(代理可以像查询引擎或聊天引擎一样使用) 主要区别在于代理动态地决定最佳的动作序列,而不是遵循预定的逻辑 Llamaindex提供可组合的模块,帮助开发者构建和集成RAG管道,用于回答、聊天机器人或作为代理的一部分 这些构建块可以根据排名偏好进行定制,并组合起来,以结构化的方式基于多个知识库进行推理

Llamaindex快速构建
# 环境搭建(使用LlamaIndex需要安装最新版的python) conda create --name llamaindex python=3.12 -y conda activate llamaindex pip install llama-index -i https://mirrors.aliyun.com/pypi/simple/ pip install llama-index-llms-huggingface -i https://mirrors.aliyun.com/pypi/simple/
pip install llama-index-embeddings-huggingface
没有使用RAG
from llama_index.core.llms import ChatMessage # ChatMessage:构建聊天消息的类(表示发送给聊天模型的消息) from llama_index.llms.huggingface import HuggingFaceLLM # 用于加载 Hugging Face 提供的大语言模型 # 使用HuggingFaceLLM加载本地大模型 llm = HuggingFaceLLM(model_name=r"E:\ai_model_data\model\Qwen\Qwen2___5-0___5B-Instruct", tokenizer_name=r"E:\ai_model_data\model\Qwen\Qwen2___5-0___5B-Instruct", # model_kwargs:传递给大模型的初始化参数、tokenizer_kwargs:传递给分词器的初始化参数 model_kwargs={"trust_remote_code":True}, # "trust_remote_code":信任远程代码 tokenizer_kwargs={"trust_remote_code":True}) # 调用模型chat引擎得到回复 rsp = llm.chat(messages=[ChatMessage(content="xtuner是什么?")]) print(rsp) # 模型会一本正经的胡说八道
使用RAG
from llama_index.embeddings.huggingface import HuggingFaceEmbedding # HuggingFaceEmbedding:用于将文本转换为词向量 from llama_index.llms.huggingface import HuggingFaceLLM # HuggingFaceLLM:用于运行Hugging Face的预训练语言模型 from llama_index.core import Settings,SimpleDirectoryReader,VectorStoreIndex # Settings:用于全局设置管理 # SimpleDirectoryReader:用于从指定目录读取文档 # VectorStoreIndex:用于创建和管理文档的向量索引
# 初始化一个HuggingFaceEmbedding对象(嵌入模型),用于将文本转换为向量表示 embed_model = HuggingFaceEmbedding( # 指定了一个预训练的sentence-transformer模型的路径 model_name=r"E:\ai_model_data\model\embedding_model\sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2" ) # 将创建的嵌入模型赋值给全局设置的embed_model属性,这样在后续的索引构建过程中,就会自动使用这个模型 Settings.embed_model = embed_model # 使用HuggingFaceLLM加载本地大模型 llm = HuggingFaceLLM(model_name=r"E:\ai_model_data\model\Qwen\Qwen2___5-0___5B-Instruct", tokenizer_name=r"E:\ai_model_data\model\Qwen\Qwen2___5-0___5B-Instruct", model_kwargs={"trust_remote_code":True}, # "trust_remote_code":信任远程代码 tokenizer_kwargs={"trust_remote_code":True}) # 设置全局的llm属性,这样在索引查询时会使用这个模型 Settings.llm = llm # 从指定目录读取文档,将数据加载到内存 documents = SimpleDirectoryReader(r"E:\ai_model_data\data").load_data() # 此处的地址是被加载数据的文件夹 print(documents) # 创建一个VectorStoreIndex,并使用之前加载的文档来构建向量索引 # 此索引将文档转换为向量,并存储这些向量(内存)以便于快速检索 index = VectorStoreIndex.from_documents(documents) #创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。 query_engine = index.as_query_engine() rsp = query_engine.query("xtuner是什么?") print(rsp)
Embedding Models 嵌入模型原理及其选择
概念与核心原理
嵌入模型不仅仅只是把文本或图片转换为向量,还要保证嵌入文本的语义关系

# 嵌入模型的本质 嵌入模型(Embedding Model)是一中将离散数据(文本、图片)转化为高维向量表示的技术。 模型通过高维向量表示可捕捉数据的语义信息,使得语义相似的文本在向量空间中距离更近。 例如:"忘记密码"和"账号锁定"会被编码为相近的向量,从而使模型支持语义检索而非仅关键字匹配 # 核心作用 语义编码:将文本、图像等转换为向量,并保留上下文信息(如使用BERT的CLS Token进行文本的向量表示) 相似度计算:通过余弦相似度、欧式距离等度量标准来评估数据之间的相似性 信息降维:压缩复杂数据为低秩稠密向量,提升存储与计算效率 # 关键技术原理 上下文依赖:现代模型(如BGE-M3)动态调整向量,捕捉多义词在不同语境中的含义 训练方法:对比学习(如Word2Vec的Skip-gram/CBOW)、预训练+微调(如BERT)
主流模型分类与选型指南
| 选择Embedding需要考虑的因素 | 说明 |
|---|---|
| 任务性质 | 匹配任务需求(问答、搜索、聚类等) |
| 领域特性 | 适用于专业领域(医学、法律等) |
| 多语言支持 | 需处理多语言内容的情况 |
| 维度 | 权衡信息丰富度与计算成本 |
| 许可证 | 开源vs专有服务 |
| 最大tokens | 适合的上下文文本口大小 |
- 通用全能型:
- BGE-M3:北京智源研究院开发,支持多语言,混合检索(稠密+稀疏向量),处理8K上下文,适合企业级知识库
- NV-Emb-ed-v2:基于Mistral-7B,检索精度高(MTEB得分62.65),但需要高算力设备
- 垂直领域特化型:
- 中文场景:BGE-large-zh-v1.5(合同/政策文件)、M3E-base(社交媒体分析)
- 多维度模型:BGE-LV(国文跨模态检索),联合编解码OCR文本与图像特征
- 轻量化部署型:
- nomic-embed-text:768维向量,推荐速度比OpenAI快3倍,适合初始训练
- gte-qwen2-1.5b-instruct:1.5B参数,16GB显存可运行,适合初创模型
- 选型策略
- 中文为主-->BEG系列>M3E
- 多语言需求-->BGE-M3>multilingual-e5
- 预算有限-->开源模型(如Nomic Embed)
使用HuggingFace加载BGE模型进行文本嵌入
import numpy as np from llama_index.embeddings.huggingface import HuggingFaceEmbedding # 加载BGE中文嵌入模型 model_name = r'E:\ai_model_data\model\embedding_model\sungw111\text2vec-base-chinese-sentence' embed_model = HuggingFaceEmbedding(model_name=model_name,device='cpu',normalize=True) # normalize:归一化处理,方便计算余弦相似度
# 文本嵌入(将文本转换为固定长度的数值向量) documents = ["忘记密码如何处理?","用户账号被锁定"] doc_embeddings = [embed_model.get_text_embedding(doc) for doc in documents] # 嵌入查询并计算相似度 query = "密码重置流程" query_embedding = embed_model.get_text_embedding(query) # 计算余弦相似度(因为 normalize=True,点积就是余弦相似度) similarity = np.dot(doc_embeddings, query_embedding) print("相似度:",similarity) # 相似度: [0.90134961 0.84643861]
评估embedding模型效果


{ "version": "v2.0", "data": [ {"title": "Normans", "paragraphs": [ {"qas": [ {"question": "In what country is Normandy located?", "id": "56ddde6b9a695914005b9628", "answers": [ {"text": "France", "answer_start": 159}, {"text": "France", "answer_start": 159}, {"text": "France", "answer_start": 159}, {"text": "France", "answer_start": 159}], "is_impossible": false}, {"question": "When were the Normans in Normandy?", "id": "56ddde6b9a695914005b9629", "answers": [ {"text": "10th and 11th centuries", "answer_start": 94}, {"text": "in the 10th and 11th centuries", "answer_start": 87}, {"text": "10th and 11th centuries", "answer_start": 94}, {"text": "10th and 11th centuries", "answer_start": 94}], "is_impossible": false} ] } ] } ] }
# embedding_model效果对比 from sentence_transformers import SentenceTransformer,util import numpy as np import json # 加载SQuAD数据 with open(r"E:\ai_model_data\data\squad_dev.json") as f: squad_data = json.load(f)["data"] # 提取问题和答案对 qa_pairs = [] for article in squad_data: for para in article["paragraphs"]: for qa in para["qas"]: if not qa["is_impossible"]: qa_pairs.append({ "question": qa["question"], "answer": qa["answers"][0]["text"], "context": para["context"] }) # 初始化两个本地Embedding模型 model1 = SentenceTransformer(r'E:\ai_model_data\model\embedding_model\sentence-transformers\paraphrase-multilingual-MiniLM-L12-v2') # 模型1 model2 = SentenceTransformer(r'E:\ai_model_data\model\embedding_model\sungw111\text2vec-base-chinese-sentence') # 模型2 # 编码所有上下文(作为向量库/知识库) contexts = [item["context"] for item in qa_pairs] context_embeddings1 = model1.encode(contexts) # 模型1的向量库 context_embeddings2 = model2.encode(contexts) # 模型2的向量库 # 评估函数 def evaluate(model,query_embeddings,context_embeddings): correct = 0 for idx, qa in enumerate(qa_pairs[:100]): # 测试前100条 # 查找最相似上下文 sim_scores = util.cos_sim(query_embeddings[idx], context_embeddings) best_match_idx = np.argmax(sim_scores) # 检查答案是否在匹配段落中 if qa["answer"] in contexts[best_match_idx]: correct += 1 return correct / len(qa_pairs[:100]) # 编码所有问题 query_embeddings1 = model1.encode([qa["question"] for qa in qa_pairs[:100]]) query_embeddings2 = model2.encode([qa["question"] for qa in qa_pairs[:100]]) # 执行评估 acc1 = evaluate(model1, query_embeddings1, context_embeddings1) acc2 = evaluate(model2, query_embeddings2, context_embeddings2) print(f"模型1准确率: {acc1:.2%}") print(f"模型2准确率: {acc2:.2%}")
Chroma向量数据库(只能在linux操作系统中使用)
Chroma是一款专为高效存储和检索高维向量数据设计的向量数据库,其核心能力在于语义相似性搜索(基于向量距离来衡量的数据的关联性而非关键字匹配)
核心优势:
- 轻量易用:以Python/JS包形式嵌入代码,无需独立部署,适合快速原型开发
- 灵活集成:支持自定义嵌入模型(如OpenAI、HuggingFace),兼容LangChain等框架
- 高性能检索:采用HNSW算法优化索引,支持百万级向量毫秒级响应
- 多模式存储:内存模式用于开发调试,持久化模式支持生产环境数据落地
安装与基础配置
# 安装(通过python包管理器安装ChromaDB) pip install chromadb # 完整功能 # 初始化客户端 内存模式(开发环境) import chromadb client = chromadb.client() 持久化模式(生产环境) client = chromadb.PersistentClient(path="/path/to/save") # 数据保存至本地目录
创建集合(collection)
集合是Chroma中管理数据的基本单元,类似于传统数据库的表
model_name = "E:\ai_model_data\model\embedding_model\sungw111\text2vec-base-chinese-sentence" collection = client.create_collection( name = "my_collection", metadata = {"hnsw:space": "cosine"}, # 指定余弦相似度计算 embedding_function=HuggingFaceEmbedding( # 自定义嵌入模型 model_name = model_name, device = "cuda" ) )
添加数据
# 自动生成向量(使用集合的嵌入模型) collection.add( documents = ["RAG是一种检索增强生成技术", "向量数据库存储文档的嵌入表示","三英战吕布"], metadatas = [{"source": "tech_doc"}, {"source": "tech_doc"}, {"source": "tutorial"}, {"source": "tech_doc"}], # metadatas = [{"来源":"开发者文档"}, {"来源":"开发者文档"}, {"来源":"教程"}], ids = ["id1", "id2", "id3", "id4"] ) # 元数据:在向量数据库中,元数据是与文档或向量关联的附加信息,可用于描述、分类、标识或提供上下文
查询数据
# 文本查询(自动向量化) results = collection.query( query_texts=["什么是RAG技术?", "向量数据库的表示方法"], n_results=1, # 每条查询返回的结果数量 where = {"来源":"开发者文档"}, # where参数用于过滤查询结果(只返回"来源":"开发者文档"的文档) # where_document = {"$contains":"关键词"} # 只有在文档中包含"关键词"的结果才会被返回 )

数据管理
# 更新: collection.update(ids = ["id1"], documents = ["新内容"]) # 删除: collection.delete(ids = ["id2"]) # 统计: collection.count() # 获取条目数 # 使用get()获取特定ID的内容(如果不指定内容则查询所有信息) print(collection.get(ids=["id1"])) {'ids': ['id1'], 'embeddings': None, 'documents': ['RAG是一种检索增强生成技术'],'uris': None, 'included': ['metadatas', 'documents'], 'data': None, 'metadatas': [{'source': 'tech_doc'}]} print(collection.get(ids=["id1"])["documents"]) ['RAG是一种检索增强生成技术']
实例测试

import chromadb from sentence_transformers import SentenceTransformer # 正确初始化 Chromadb 客户端 client = chromadb.Client() class SentenceTransformerEmbeddingFunction: def __init__(self, model_path: str, device: str = "cuda"): self.model = SentenceTransformer(model_path, device=device) def __call__(self, input: list[str]) -> list[list[float]]: if isinstance(input, str): input = [input] return self.model.encode(input, convert_to_numpy=True).tolist() model_name = "/aiproject/model/embedding_model/sungw111/text2vec-base-chinese-sentence" # 创建集合 collection = client.create_collection( name="my_collection", metadata={"hnsw:space": "cosine"}, # 指定余弦相似度计算 embedding_function=SentenceTransformerEmbeddingFunction( # 自定义嵌入模型 model_path=model_name, device="cpu", ) ) # 添加文档 collection.add( documents=["RAG是一种检索增强生成技术", "向量数据库存储文档的嵌入表示", "三英战吕布", "mysql是关系型数据库"], metadatas=[{"source": "tech_doc"}, {"source": "tech_doc"}, {"source": "tutorial"},{"source": "tech_doc"}], ids=["id1", "id2", "id3", "id4"] ) # 更新、删除、统计 # collection.update(ids = ["id1"], documents = ["新内容"]) # collection.delete(ids = ["id2"]) print(collection.count()) # 查询 results = collection.query( query_texts = ["RAG是什么","向量数据库的表示方法"], where = {"source": "tech_doc"}, n_results=1 ) # 打印查询结果 print(results)
4 {'ids': [['id1'], ['id2']], 'embeddings': None, 'documents': [['RAG是一种检索增强生成技术'], ['向量数据库存储文档的嵌入表示']],
'uris': None, 'included': ['metadatas', 'documents', 'distances'], 'data': None, 'metadatas': [[{'source': 'tech_doc'}],
[{'source': 'tech_doc'}]], 'distances': [[0.09759640693664551], [0.1690090298652649]]}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号