生成式语言模型的对话模板介绍
对话模板的简介
- 对话模板(prompt template):用户与大模型进行交互或者对话的一种格式化样板,对文本输出的长短有影响
- 对话模板仅仅控制的是模型输出的样式,对数据做格式化操作操作数据,并不会影响到模型的能力
- 对话模板可以理解为显示生活中与人交流的方式(中文模板、英文模板),不会影响人的能力
框架对话模板简介
- 微调框架(llama-factory)的对话模板不是从模型的tokenizer_config.json中读取的,而是人家框架自己参考模型的官网定义
- 推理框架:
- vLLM:使用模型自带的模板,用户需自行处理输入格式
- LMDeploy:提供默认模板,可自定义
- Ollama:通过Modelfile自定义
- 前端界面:openweb-ui用的是自己的对话模板
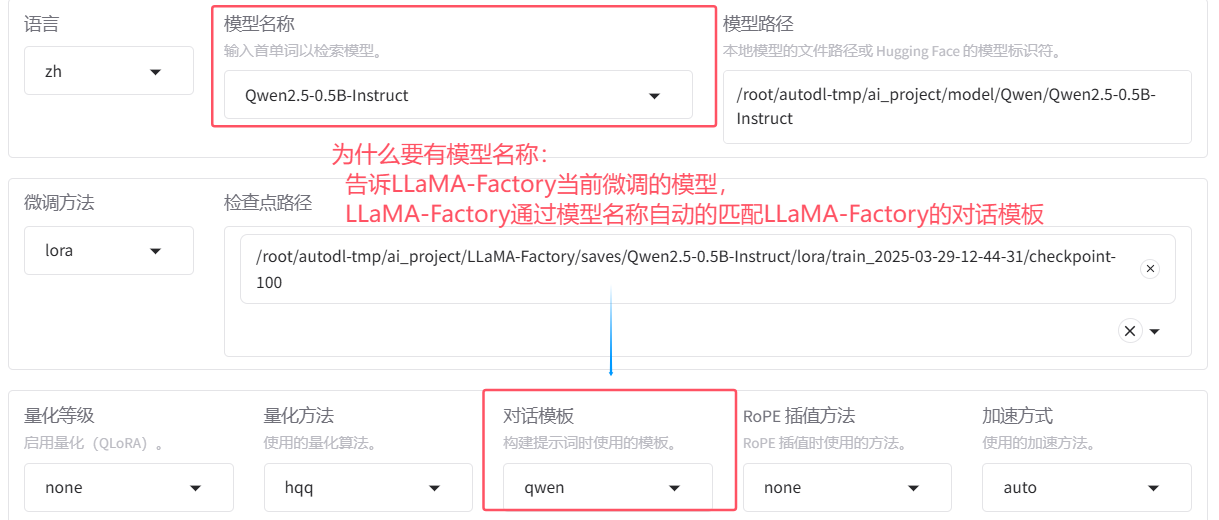
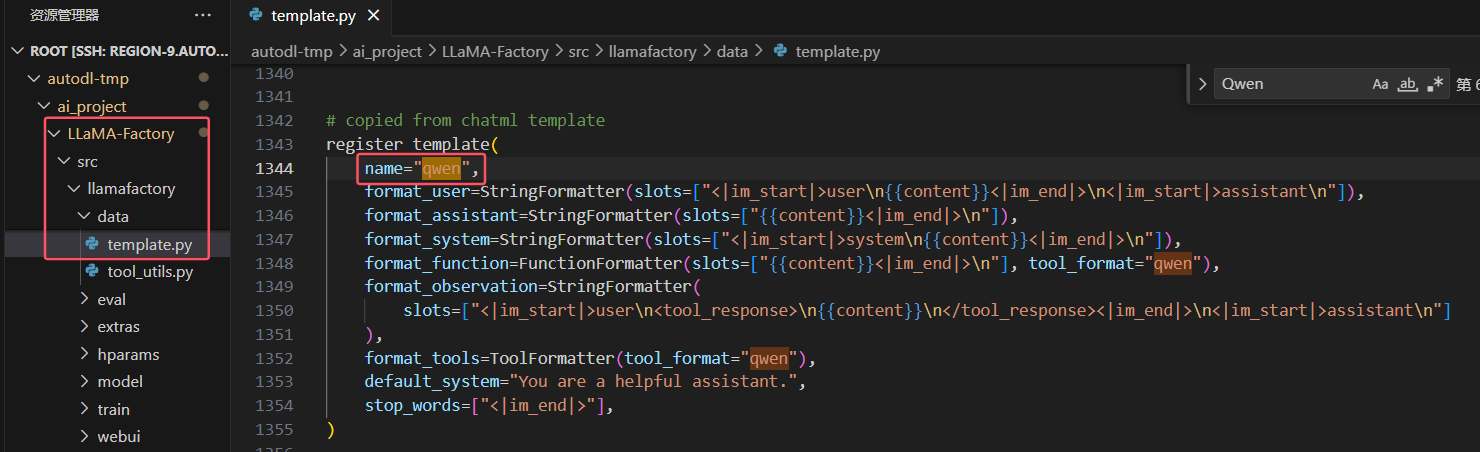
- LLaMA-Factory定义的对话模板存放位置:/LLaMA-Factory/src/llamafactory/data/template.py
文本输出的长短的影响因素
- 对话模板:如果设定了明确的格式或结果,会显示或引导模型输出的长度
- 输入提示:用户输入的提示和问题的复杂度影响着模型输出的长短
- 模型参数调节:最大生成长度、采样温度等
- 上下文窗口:模型生成相应是会考虑上下文信息
- 后处理命令:对生成的文本结果进行进一步的处理,以达到特定的要求或格式(截断、补充、后续格式化)
LLamaFactory微调效果与vllm、lmdeploy部署效果不一致如何解决
LLamaFactory与vllm对话模板对齐
如何导出LLamaFactory的对话模板
# mytest.py(存放的位置在LLaMA-Factory的templete的同级目录下)
import sys
import os
# 将项目根目录添加到 Python 路径
root_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
sys.path.append(root_dir)
from llamafactory.data.template import TEMPLATES
from transformers import AutoTokenizer
# 1. 初始化分词器(任意支持的分词器均可)
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/ai_project/model/Qwen/Qwen2.5-0.5B-Instruct")
# 2. 获取模板对象
template_name = "qwen" # 替换为你需要查看的模板名称
template = TEMPLATES[template_name]
# 3. 修复分词器的 Jinja 模板
template.fix_jinja_template(tokenizer)
# 4. 直接输出模板的 Jinja 格式
print("=" * 40)
print(f"Template [{template_name}] 的 Jinja 格式:")
print("=" * 40)
print(tokenizer.chat_template)
 LLaMA-Factory_Qwen.jinja
LLaMA-Factory_Qwen.jinja vllm推理模型时自定义对话模板
# 将生成的jinja文件内容保存:/root/autodl-tmp/ai_project//LLaMA-Factory/LLaMA-Factory_Qwen.jinja
vllm serve <model> --chat-template ./path-to-chat-template.jinja






 浙公网安备 33010602011771号
浙公网安备 33010602011771号