



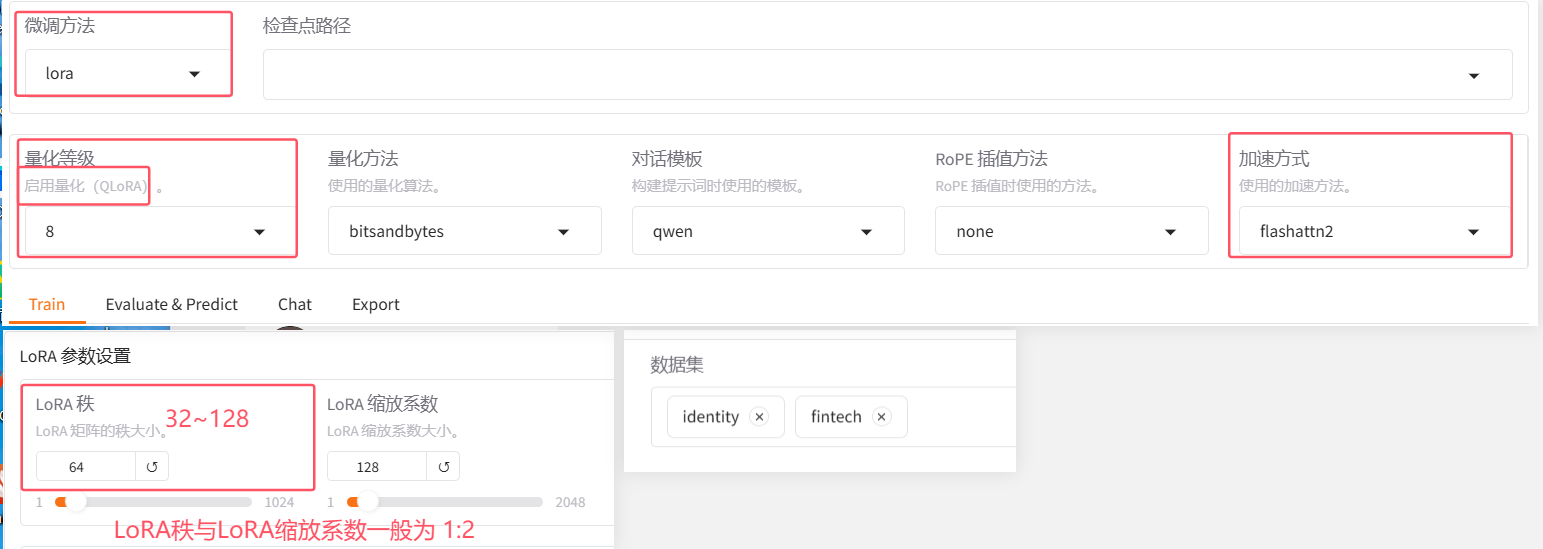
LoRA与QLoRA
# 在模型微调训练过程中,可以采用降低模型参数精度来节约训练的显存,以此来提升训练批次的大小,使得模型训练的更快 # 模型部署过程使用量化是以牺牲精度为代价来提升性能,那么在模型训练过程中使用量化是否会降低模型的精度? 不会 模型部署中,由于模型的参数已经固定,所以量化降低参数的精度一定会影响结果; 模型训练中,由于模型的参数没有固定,依然处于学习状态,所以量化降低参数的精度对模型的影响不会太大; ai训练的结果不是具体的数值,而是一种趋势; 在量化微调中,量化只发生在内部的训练过程,并不影响模型最周的数据类型 模型原有的参数类型是f16,在量化微调训练中会量化为8位,参数保存时又会还原到f16,因此,量化微调并不影响模型本身的参数类型
- LoRA:LoRA(低秩适应)是一种用于降低大型语言模型训练和微调成本的技术。它通过引入低秩矩阵来适应模型的权重,减少了需要调整的参数数量,从而降低了训练的计算和存储需求。
- QLoRA:QLoRA 是LoRA的一种扩展,一种高效的大型语言模型微调方法,它显著降低了内存使用量,同时保持了全 16 位微调的性能。
- LoRA与QLoRA的区别
| 特征 | LoRA | QLoRA |
| 参数更新方式 | 低秩矩阵 | 低秩矩阵+量化 |
| 内存使用 | 较低 | 更低 |
| 量化支持 | 不支持 | 支持 |
| 性能损失 | 清晰可控 | 较小,全精度接近 |
| 应用范围 | 泛用 |
大模型转换为GGUF以及使用ollama部署
GGUF 格式的全名为(GPT-Generated Unified Format),提到GGUF 就不得不提到它的前身 GGML(GPT-Generated ModelLanguage)。GGML 是专门为了机器学习设计的张量库,最早可以追溯到 2022/10。其目的是为了有一个单文件共享的格式,并且易于在不同架构的 GPU 和 CPU 上进行推理。但在后续的开发中,遇到了灵活性不足、相容性及难以维护的问题。
# 为什么要转换GGUF格式 在传统的 Deep Learning Model 开发中大多使用 PyTorch 来进行开发,但因为在部署时会面临相依 Lirbrary 太多、版本管理的问题于才有了 GGML、GGMF、GGJT 等格式,而在开源社群不停的迭代后 GGUF 就诞生了。 GGUF 实际上是基于 GGJT 的格式进行优化的,并解决了 GGML 当初面临的问题,包括: 1)可扩展性:轻松为 GGML 架构下的工具添加新功能,或者向 GGUF 模型添加新 Feature,不会破坏与现有模型的兼容性。 2)对 mmap(内存映射)的兼容性:该模型可以使用 mmap 进行加载(原理解析可见参考),实现快速载入和存储。(从 GGJT 开始导入,可参考 GitHub) 3)易于使用:模型可以使用少量代码轻松加载和存储,无需依赖的 Library,同时对于不同编程语言支持程度也高。 4)模型信息完整:加载模型所需的所有信息都包含在模型文件中,不需要额外编写设置文件。 5)有利于模型量化:GGUF 支持模型量化(4 位、8 位、F16),在 GPU 变得越来越昂贵的情况下,节省 vRAM 成本也非常重要。
将hf模型转换为GGUF
# 需要用llama.cpp仓库的convert_hf_to_gguf.py脚本来转换,lama.cpp 是一个用于实现和运行LLaMA模型的C++版本
# 安装llama.cpp git clone https://github.com/ggerganov/llama.cpp.git pip install -r llama.cpp/requirements.txt # 安装所需要的依赖 # 执行转换 # 如果不量化,保留模型的效果 (ollama) root@autodl-container-c2da11b6fa-809f1df6:~/autodl-tmp/ai_project# python llama.cpp/convert_hf_to_gguf.py /root/autodl-tmp/ai_project/model/Qwen/Qwen2.5-0.5B-Instruct \ --outtype f16 --verbose --outfile /root/autodl-tmp/ai_project/model/Qwen/Qwen2.5-0.5B-Instruct-gguf.gguf # 如果需要量化(加速并有损效果),直接执行下面脚本就可以 (ollama) root@autodl-container-c2da11b6fa-809f1df6:~/autodl-tmp/ai_project# python llama.cpp/convert_hf_to_gguf.py /root/autodl-tmp/ai_project/model/Qwen/Qwen2.5-0.5B-Instruct \ --outtype q8_0 --verbose --outfile /root/autodl-tmp/ai_project/model/Qwen/Qwen2.5-0.5B-Instruct-q8_0-gguf.gguf --outtype是输出类型,代表含义: q2_k:特定张量(Tensor)采用较高的精度设置,而其他的则保持基础级别 q3_k_l、q3_k_m、q3_k_s:这些变体在不同张量上使用不同级别的精度,从而达到性能和效率的平衡 q4_0:这是最初的量化方案,使用4位精度 q4_1和q4_k_m、q4_k_s:这些提供了不同程度的准确性和推理速度,适合需要平衡资源使用的场景 q5_0、q5_1、q5_k_m、q5_k_s:这些版本在保证更高准确度的同时,会使用更多的资源并且推理速度较慢 q6_k和q8_0:这些提供了最高的精度,但是因为高资源消耗和慢速度,可能不适合所有用户 fp16和f32:不量化,保留原始精度
使用ollama运行gguf
# 安装ollama curl-fsSLhttps://ollama.com/install.sh|sh # 启动ollama服务 ollama serve # 创建路径文件ModelFile(使用ollama list 命令不能查看到自己创建的模型),文件内容如下 #GGUF文件路径 FROM /root/autodl-tmp/ai_project/model/Qwen/Qwen2.5-0.5B-Instruct-q8_0-gguf.gguf # 使用ollama create命令创建自定义模型 ollama create Qwen2.5-0.5B-Instruct-q8_0-gguf --file ModeFile文件路径 # 运行模型 ollama run Qwen2.5-0.5B-Instruct-q8_0-gguf



 浙公网安备 33010602011771号
浙公网安备 33010602011771号