Kafka(2)- consumer
1. 基本概念
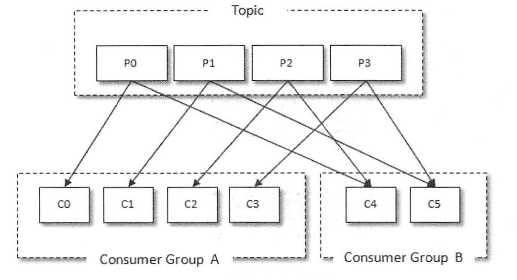
消费kafka消息的客户端称为consumer,consumer负责订阅kafka的topic,并从该topic上拉取消息。除了consumer本身,kafka还有一个消费组(consumer group)的概念。每个kafka consumer都属于一个消费者组,一条消息只会被一个消费者组内的一个消费者消费,因此一个消费者组内消费者的数量一般不会超过分区的数量。例如,某个主题共有4个分区:P0, P1, P2, P3;有两个消费者组A, B;A中有四个消费者(C0, C1, C2, C3),B中有两个消费者(C4, C5),则A中每个消费者分配到1个分区,B中每个消费者分配到两个分区,消费分配情况如下:
public void consume() {
// 1. 初始化client
Properties props = new Properties();
props.put( "key.deserializer" , "org.apache.kafka.common.serialization.StringDeserializer" );
props.put( "value.deserializer" , "org.apache.kafka.common.serialization.StringDeserializer" );
props.put( "bootstrap.servers" , brokerList);
props.put( "group.id" , groupId);
props.put( "client.id" , "XXX" )
KafkaConsumer<string, string=""> consumer = new KafkaConsumer<>(props);
// 2. 订阅主题
consumer.subscribe(topics)
// 3. 消费消息
try {
while (running) {
ConsumerRecords<string, string=""> records = consumer.poll(timeout); // 拉取消息
for (ConsumerRecord<string, string=""> record: records) {
// 消费消息
}
}
} catch (Exception e) {
log.error( "..." )
} finally {
consumer.close()
}
}</string,></string,></string,>
下面从consumer的使用流程上,来介绍每个部分的一些细节问题。
2. 初始化consumer
消费者有很多配置参数,都在ConsumerConfig当中,其中必须有KeyDeserializer, ValueDeserializer, bootstrap.servers。消费者有消费者组的概念,一条消息只会被同一个消费组内的一个消费者消费,通过指定groupId,来确定一个consumer属于哪一个group, groupId不能为空。
consumer不是线程安全的,不能多线程并发消费,在KafkaConsumer内部,有一个light lock(轻量级锁),用于防止多线程访问同一个consumer,通过aquire()和release()方法,防止并发访问。
private void acquire() { long threadId = Thread.currentThread().getId(); if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId)) throw new ConcurrentModificationException("KafkaConsumer is not safe for multi-threaded access"); refcount.incrementAndGet(); } private void release() { if (refcount.decrementAndGet() == 0) currentThread.set(NO_CURRENT_THREAD); }
- One consumer per thread(一个线程一个消费者)
- Decouple consumption and process(消费线程和数据处理线程解耦)
3. 订阅主题
kafka通过subscribe方法,实现数据订阅。subscribe共有四个重载方法:
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener); public void subscribe(Collection<String> topics); public void subscribe(Pattern pattern, ConsumerRebalanceListener listener); public void subscribe(Pattern pattern);
也可以通过assign方法,指定订阅某个分区的数据:
public void assign(Collection<TopicPartition> partitions)
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) { acquireAndEnsureOpen(); // 调用aquire方法获取light lock,并确认consumer不是close状态 try { maybeThrowInvalidGroupIdException(); // 检查groupId的有效性(不能为空) if (topics == null) throw new IllegalArgumentException("Topic collection to subscribe to cannot be null"); if (topics.isEmpty()) { // treat subscribing to empty topic list as the same as unsubscribing this.unsubscribe(); // 如果传空list,等效于unsubscribe } else { for (String topic : topics) { if (Utils.isBlank(topic)) throw new IllegalArgumentException("Topic collection to subscribe to cannot contain null or empty topic"); } throwIfNoAssignorsConfigured(); fetcher.clearBufferedDataForUnassignedTopics(topics); // 清除还没消费完的缓存数据(1) log.info("Subscribed to topic(s): {}", Utils.join(topics, ", ")); if (this.subscriptions.subscribe(new HashSet<>(topics), listener)) // (2) metadata.requestUpdateForNewTopics(); // subscriptions为SubscriptionState类,如果有新的topic加入,需要重新获取元信息 } } finally { release(); // 释放light lock } }
3. 拉取消息并消费
拉取信息调用的是KafkaConsumer.poll()函数,该函数的实现如下:


private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) { acquireAndEnsureOpen(); // 获取cnsumer light lock并确认consumer不是close状态 try { this.kafkaConsumerMetrics.recordPollStart(timer.currentTimeMs()); if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) { throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions"); } do { client.maybeTriggerWakeup(); if (includeMetadataInTimeout) { // try to update assignment metadata BUT do not need to block on the timer for join group updateAssignmentMetadataIfNeeded(timer, false); } else { while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE), true)) { log.warn("Still waiting for metadata"); } } final Fetch<K, V> fetch = pollForFetches(timer); if (!fetch.isEmpty()) { // before returning the fetched records, we can send off the next round of fetches // and avoid block waiting for their responses to enable pipelining while the user // is handling the fetched records. // // NOTE: since the consumed position has already been updated, we must not allow // wakeups or any other errors to be triggered prior to returning the fetched records. if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) { client.transmitSends(); } if (fetch.records().isEmpty()) { log.trace("Returning empty records from `poll()` " + "since the consumer's position has advanced for at least one topic partition"); } return this.interceptors.onConsume(new ConsumerRecords<>(fetch.records())); } } while (timer.notExpired()); return ConsumerRecords.empty(); } finally { release(); this.kafkaConsumerMetrics.recordPollEnd(timer.currentTimeMs()); } }
该函数底层调用的是Fetcher类相关的函数。Fetcher是KafkaConsumer用于和NetworkClient交互的一个类,用于包装发送请求,获取响应消息。
3.1 Fetcher
上面介绍,Fetcher是KafkaConsumer用于和NetworkClient交互的一个类,负责包装拉取消息,元数据更新,获取消费位移等请求,并调用ConsumerNetworkClient(NetworkClient的客户端实现)的send方法和poll方法;同时负责解析收到的数据,包装成List<ConsumerRecord<K, V>>,相当于producer端的sender。对应的方法如下:
发送拉取请求:
public synchronized int sendFetches() { // Update metrics in case there was an assignment change sensors.maybeUpdateAssignment(subscriptions); Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests(); // 选取没有in-flight request的leader, 包装成map<node, requests>的形式 for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) { final Node fetchTarget = entry.getKey(); final FetchSessionHandler.FetchRequestData data = entry.getValue(); final short maxVersion; if (!data.canUseTopicIds()) { maxVersion = (short) 12; } else { maxVersion = ApiKeys.FETCH.latestVersion(); } final FetchRequest.Builder request = FetchRequest.Builder .forConsumer(maxVersion, this.maxWaitMs, this.minBytes, data.toSend()) .isolationLevel(isolationLevel) .setMaxBytes(this.maxBytes) .metadata(data.metadata()) .removed(data.toForget()) .replaced(data.toReplace()) .rackId(clientRackId); if (log.isDebugEnabled()) { log.debug("Sending {} {} to broker {}", isolationLevel, data.toString(), fetchTarget); } // 调用client.send(),发送请求。client.send为异步接口,不做实际的发送动作,底层仍然是调用client.poll() RequestFuture<ClientResponse> future = client.send(fetchTarget, request); // 注册回调函数 this.nodesWithPendingFetchRequests.add(entry.getKey().id()); future.addListener(new RequestFutureListener<ClientResponse>() { @Override public void onSuccess(ClientResponse resp) { synchronized (Fetcher.this) { try { FetchResponse response = (FetchResponse) resp.responseBody(); FetchSessionHandler handler = sessionHandler(fetchTarget.id()); if (handler == null) { log.error("Unable to find FetchSessionHandler for node {}. Ignoring fetch response.", fetchTarget.id()); return; } if (!handler.handleResponse(response, resp.requestHeader().apiVersion())) { if (response.error() == Errors.FETCH_SESSION_TOPIC_ID_ERROR) { metadata.requestUpdate(); } return; } // 将response封装成map<TopicPartition, PartitionData>的格式 Map<TopicPartition, FetchResponseData.PartitionData> responseData = response.responseData(handler.sessionTopicNames(), resp.requestHeader().apiVersion()); Set<TopicPartition> partitions = new HashSet<>(responseData.keySet()); FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions); for (Map.Entry<TopicPartition, FetchResponseData.PartitionData> entry : responseData.entrySet()) { TopicPartition partition = entry.getKey(); FetchRequest.PartitionData requestData = data.sessionPartitions().get(partition); if (requestData == null) { String message; if (data.metadata().isFull()) { message = MessageFormatter.arrayFormat( "Response for missing full request partition: partition={}; metadata={}", new Object[]{partition, data.metadata()}).getMessage(); } else { message = MessageFormatter.arrayFormat( "Response for missing session request partition: partition={}; metadata={}; toSend={}; toForget={}; toReplace={}", new Object[]{partition, data.metadata(), data.toSend(), data.toForget(), data.toReplace()}).getMessage(); } // Received fetch response for missing session partition throw new IllegalStateException(message); } else { long fetchOffset = requestData.fetchOffset; FetchResponseData.PartitionData partitionData = entry.getValue(); log.debug("Fetch {} at offset {} for partition {} returned fetch data {}", isolationLevel, fetchOffset, partition, partitionData); Iterator<? extends RecordBatch> batches = FetchResponse.recordsOrFail(partitionData).batches().iterator(); short responseVersion = resp.requestHeader().apiVersion(); // 结果添加到completedFetches completedFetches.add(new CompletedFetch(partition, partitionData, metricAggregator, batches, fetchOffset, responseVersion)); } } sensors.fetchLatency.record(resp.requestLatencyMs()); } finally { nodesWithPendingFetchRequests.remove(fetchTarget.id()); } } } @Override public void onFailure(RuntimeException e) { synchronized (Fetcher.this) { try { FetchSessionHandler handler = sessionHandler(fetchTarget.id()); if (handler != null) { handler.handleError(e); } } finally { nodesWithPendingFetchRequests.remove(fetchTarget.id()); } } } }); } return fetchRequestMap.size(); }
获取拉取响应:
public Fetch<K, V> collectFetch() { Fetch<K, V> fetch = Fetch.empty(); Queue<CompletedFetch> pausedCompletedFetches = new ArrayDeque<>(); int recordsRemaining = maxPollRecords; try { while (recordsRemaining > 0) { if (nextInLineFetch == null || nextInLineFetch.isConsumed) { CompletedFetch records = completedFetches.peek(); if (records == null) break; if (records.notInitialized()) { try { // 将CompletedFetch包装成nextInLineFetch nextInLineFetch = initializeCompletedFetch(records); } catch (Exception e) { // Remove a completedFetch upon a parse with exception if (1) it contains no records, and // (2) there are no fetched records with actual content preceding this exception. // The first condition ensures that the completedFetches is not stuck with the same completedFetch // in cases such as the TopicAuthorizationException, and the second condition ensures that no // potential data loss due to an exception in a following record. FetchResponseData.PartitionData partition = records.partitionData; if (fetch.isEmpty() && FetchResponse.recordsOrFail(partition).sizeInBytes() == 0) { completedFetches.poll(); } throw e; } } else { nextInLineFetch = records; } completedFetches.poll(); } else if (subscriptions.isPaused(nextInLineFetch.partition)) { // when the partition is paused we add the records back to the completedFetches queue instead of draining // them so that they can be returned on a subsequent poll if the partition is resumed at that time log.debug("Skipping fetching records for assigned partition {} because it is paused", nextInLineFetch.partition); pausedCompletedFetches.add(nextInLineFetch); nextInLineFetch = null; } else { Fetch<K, V> nextFetch = fetchRecords(nextInLineFetch, recordsRemaining); recordsRemaining -= nextFetch.numRecords(); fetch.add(nextFetch); } } } catch (KafkaException e) { if (fetch.isEmpty()) throw e; } finally { // add any polled completed fetches for paused partitions back to the completed fetches queue to be // re-evaluated in the next poll completedFetches.addAll(pausedCompletedFetches); } return fetch; }
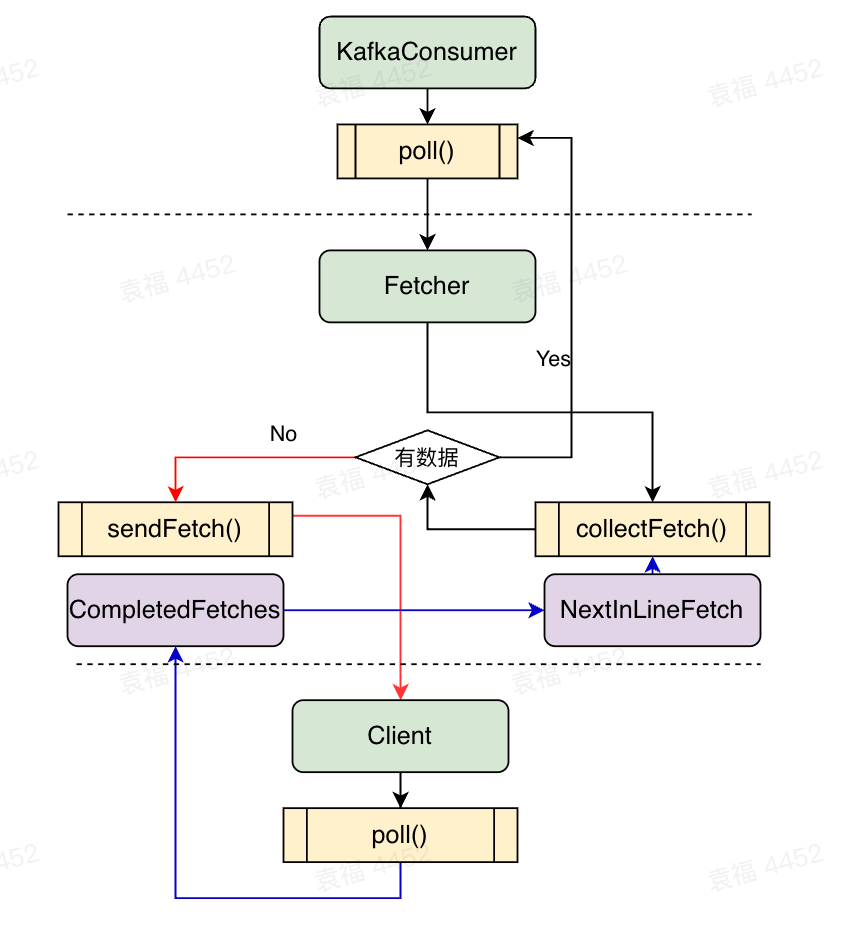
图2 kafka consumer和Fetcher的交互过程
4. 位移提交
位移提交,就是把当前消费到的消息的offset,反馈给服务端,记录消费的结果。一般情况下,我们都使用kafka的自动位移提交。当然KafkaConsumer也提供了手动提交位移的函数,分别是:
// 异步提交offset public void commitAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, OffsetCommitCallback callback) // 同步提交offset public void commitSync(final Map<TopicPartition, OffsetAndMetadata> offsets, final Duration timeout)
5. 总结
kafka consumer整体使用流程较为简单,需要重点注意以下几点:
(1)kafka consumer不是线程安全的,不能多线程共享一个consumer。因此在编写consumer对应的代码时,需要设计好对应的消费模型,见第二节的讲述。
(2)kafka的consumer支持使用subscribe()订阅主题,同时默认是自动rebalance。但是如果通过assign()指定partition进行消费,则不能进行rebalance。rebalance受到很多kafka配置参数的影响,实际使用时,可能导致频繁的rebalance,因此有些场合也会选择手动执行rebalance,并添加对于partition消费的lag的监控。
(3)一般情况下,一个partition只会被同一个group内的一个消费者消费,但是这个限制也可以打破,比如通过assign将多个消费者指定到了同一个partition。这种消费场景一定要注意消费位移的顺序提交问题,实际实现顺序提交消费位移是非常困难的,因此在实际使用中非常不建议这种方式。在大流量的场景下,最常用的消费模型是多个消费者线程+多个消息处理线程,如下:
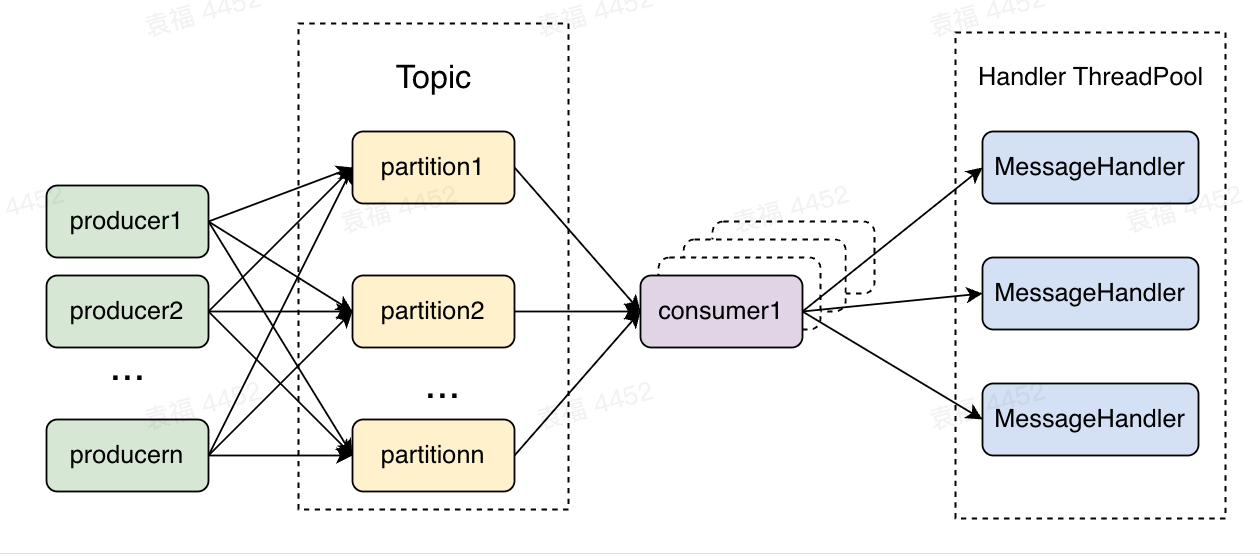
图3 大流量常用的消费模型
使用这种消费模型消费者和处理线程解耦,可以横向拓展消息处理能力,不受partition数量的影响。但是这种模型是异步提交消费位移,所以当MessageHandler出错时,需要设计一套额外的机制,实现错误重试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号