

oracle over结合row_number分区进行数据去重处理
一、创建一个测试表A
CREATE TABLE A( ID INT, NAME VARCHAR2(20) );
二、向表中添加数据,且存在相同的数据
INSERT INTO A VALUES(1,'YUAN');
INSERT INTO A VALUES(1,'YUAN');
INSERT INTO A VALUES(1,'YUAN');
INSERT INTO A VALUES(2,'YUAN');
INSERT INTO A VALUES(3,'YUAN');
INSERT INTO A VALUES(4,'LI');
INSERT INTO A VALUES(5,'LI');
INSERT INTO A VALUES(6,'YANG');
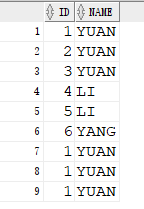
查询得到的结果如下:
三、现在我们要查询Name不同的所有数据,每个数据只取一条,当面对这样的需求时,可以使用row_number() 函数加 over()函数来解决。
(1) 首先我们要懂原理,原理就是按照某个字段进行分区,将该字段相同的数据进行标号处理,然后每个分区里面只取第一个标号的数据即可达到目的,首先我们来对数据按照字段NAME进行分区处理:
SELECT id,name ,row_number() over(partition by name order by id) as groupindex from A;
查询得到的结果如下:
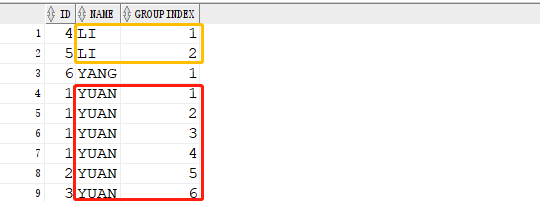
通过分区我们将NAME字段相同的一行数据做了标记处理,接下来只需要取标记为1的那一行数据即可达到数据去重的目的。
(2)根据分区,获取每个分区中对应分组下标的数据。
select * from (SELECT id,name ,row_number() over(partition by name order by id) as groupindex from A) B where b.groupindex=1 order by b.id; --这里获取的是分区中下标为1的那一条数据
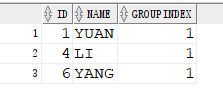
执行结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号