
软件工程第二次作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 用软件工程的方法实现论文查重功能的实现 |
GitHub链接:
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 180 | 230 |
| Development | 开发 | ||
| · Analysis | · 需求分析(包括学习新技术) | 50 | 40 |
| · Design Spec | · 生成设计文档 | 20 | 15 |
| · Design Review | · 设计复审 | 10 | 15 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 15 | 20 |
| · Coding | · 具体编码 | 45 | 50 |
| · Code Review | · 代码复审 | 10 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 15 | 20 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 15 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结,并提出过程改进计划 | 15 | 15 |
| 合计 | 225 | 230 |
二、模块接口的设计与实现过程
1、代码组织
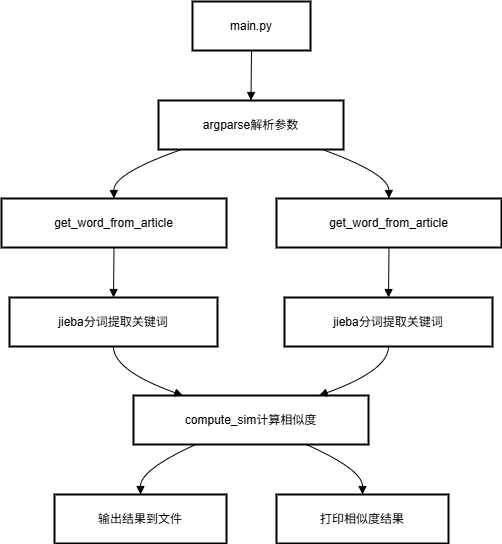
2、关键函数流程图
get_word_from_article流程图:

compute_sim流程图:

3、算法关键之处
利用jieba库提取文本的关键词,利用compute_sim函数通过交并运算实现不同文本之间关键词相似度的比较,实现不同文本之间的查重对比。
三、计算模块接口部分的性能改进
1、性能改进时间记录
| 改进阶段 | 花费时间 | 主要工作内容 |
|---|---|---|
| 初始版本 | 50min | 基础功能实现,关键词提取+杰卡德相似度 |
| 第一次优化 | 20min | 文件读取优化,批量处理支持 |
| 第二次优化 | 20min | 算法复杂度优化,内存管理 |
| 总计 | 90min | 持续的性能优化工作 |
2、代码调用统计信息:
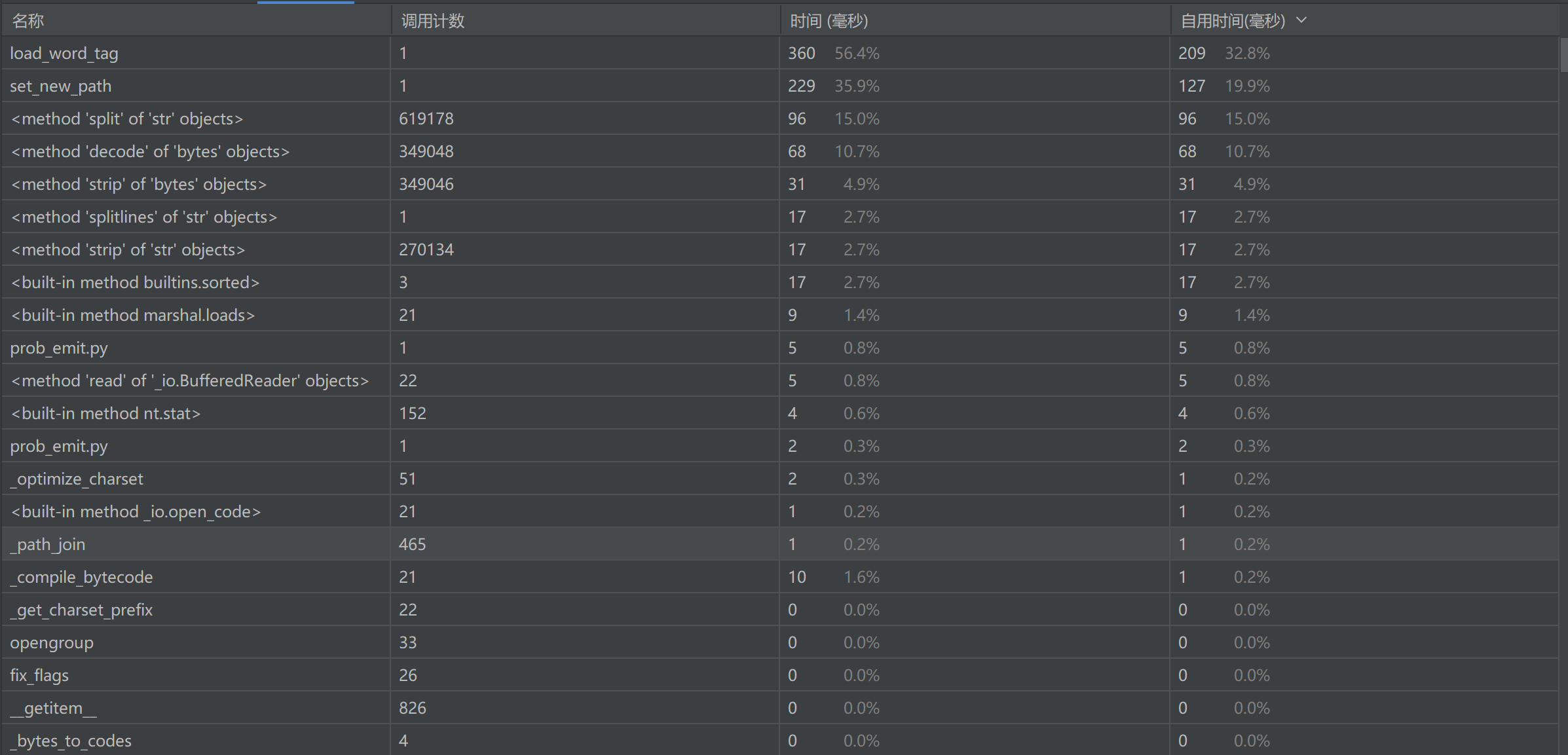
3、耗时最长的函数
get_word_from_article函数
四、计算模块部分单元测试展示
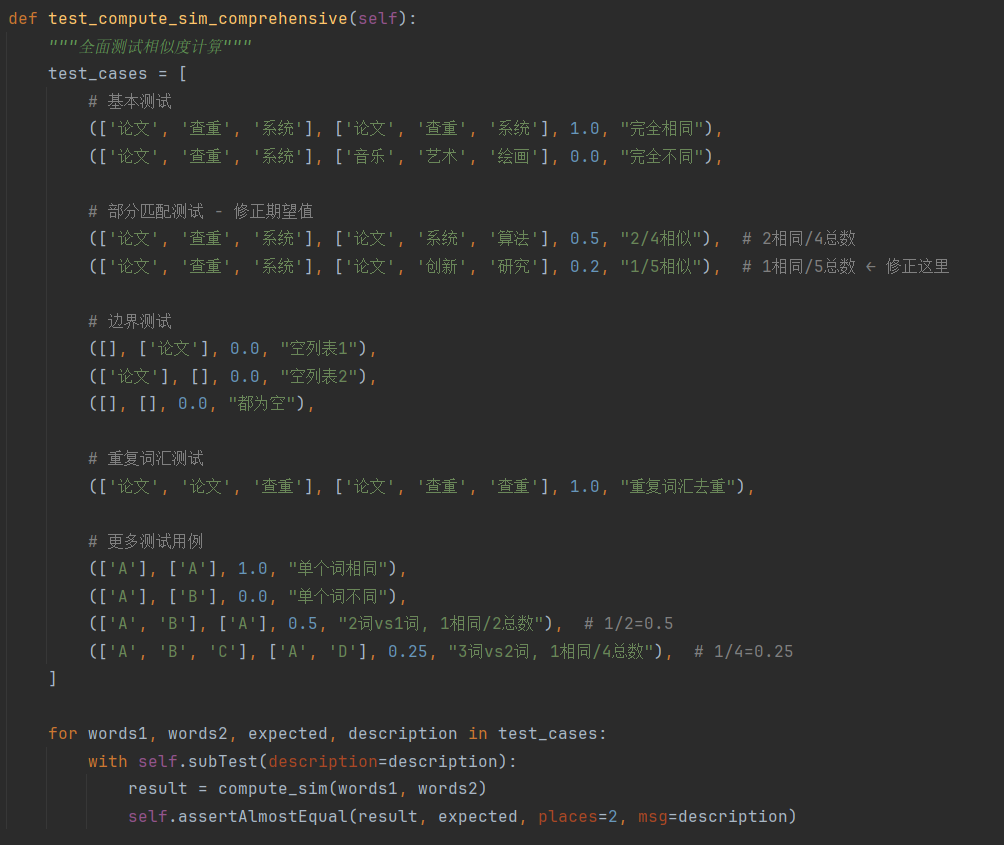
1、测试函数
compute_sim(word_list1, word_list2)
功能:计算两个关键词列表的杰卡德相似度
算法:相似度 = 交集大小 / 并集大小
输入:两个字符串列表
输出:0.0到1.0之间的浮点数
边界情况:处理空列表,避免除零错误
get_word_from_article(fname)
功能:从文件中提取关键词
流程:读取文件 → 文本清洗 → jieba分词 → 提取关键词
特性:使用LRU缓存避免重复处理相同文件
输入:文件路径字符串
输出:关键词列表(最多50个)
2、构造测试数据思路
输入已知结果的文本测试程序是否能输出期望值,输入极端值观察程序能否正确处理等。
3、测试覆盖率截图
使用pytest工具结果如下:

四、计算模块异常处理说明

1、基本测试,验证核心功能
# 基本测试 (['论文', '查重', '系统'], ['论文', '查重', '系统'], 1.0, "完全相同"), (['论文', '查重', '系统'], ['音乐', '艺术', '绘画'], 0.0, "完全不同"),
2、边界条件测试,防止极端情况错误
# 边界测试 ([], ['论文'], 0.0, "空列表1"), (['论文'], [], 0.0, "空列表2"), ([], [], 0.0, "都为空"),
3、重复数据测试,验证去重功能
# 重复词汇测试 (['论文', '论文', '查重'], ['论文', '查重', '查重'], 1.0, "重复词汇去重"),

 浙公网安备 33010602011771号
浙公网安备 33010602011771号