01_Spark入门
1.spark的地位
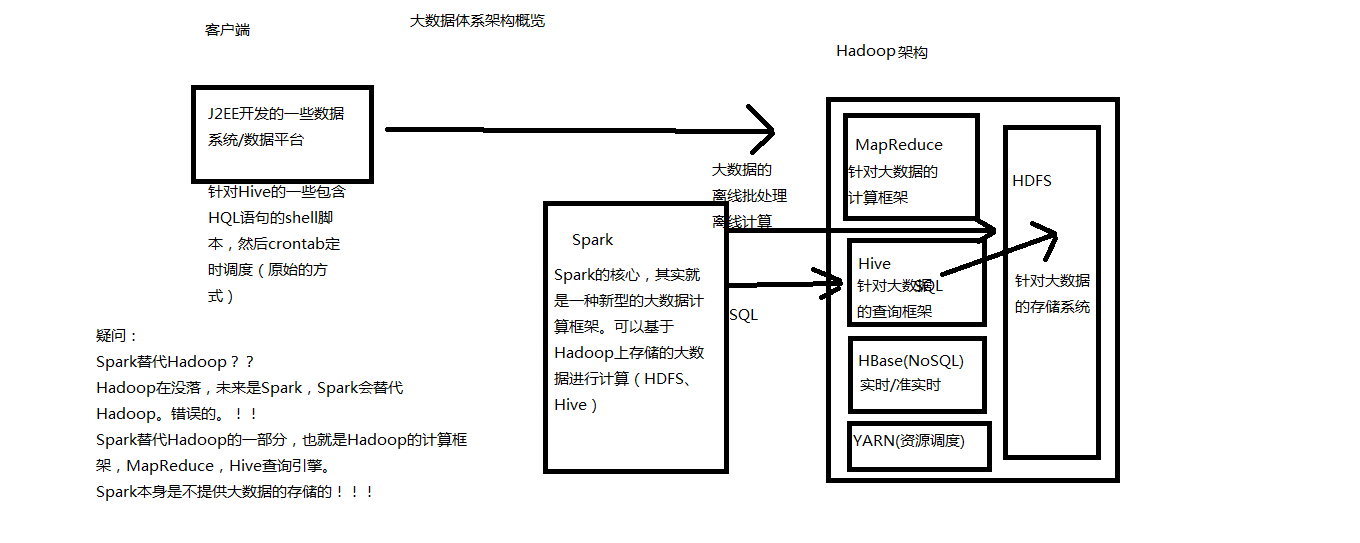
Hive(底层也是基于MR执行sql语句) spark sql针对hive进行交互式查询
HBase
Yarn
2.spark vs mapreduce 基于内存
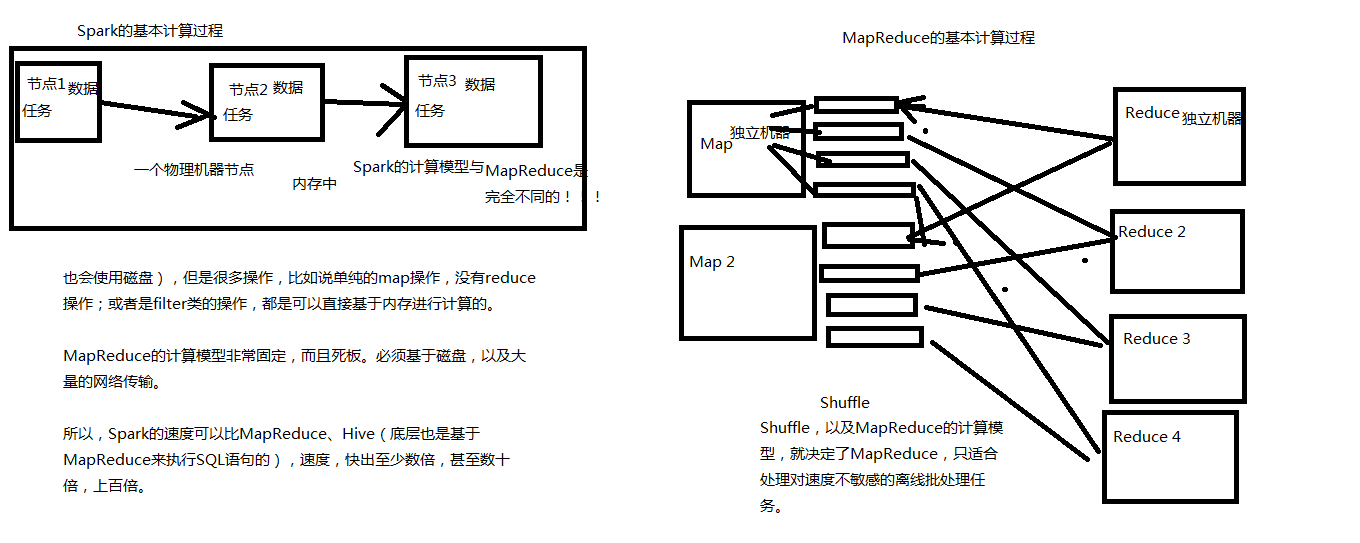
3.spark的特点
速度快:Spark基于内存进行计算(当然也有部分计算基于磁盘,比如shuffle);
容易开发;
通用性:Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图计算等常见的任务;
集成Hadoop:与Hadoop进行高度的集成,两者可以完美的配合使用。Hadoop的HDFS、Hive、HBase负责存储,YARN负责资源调度;Spark负责大数据计算
4.spark sql和hive的关系
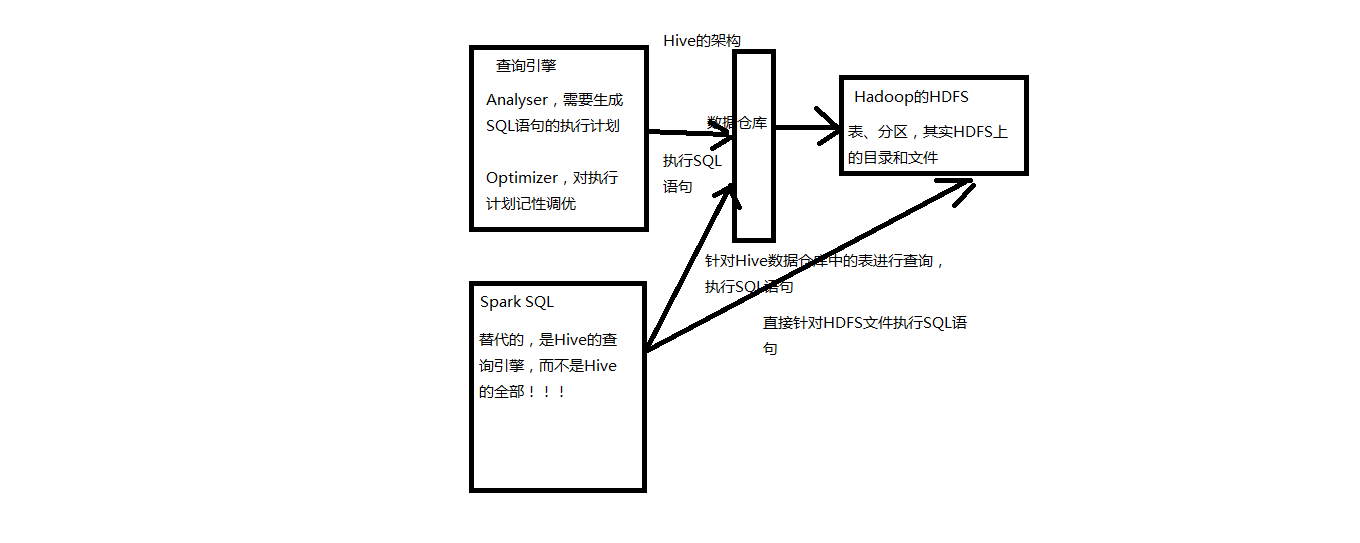
Spark SQL能够替代的,是Hive的查询引擎,而不是Hive本身,实际上即使在生产环境下,Spark SQL也是针对Hive数据仓库中的数据进行查询,Spark本身自己是不提供存储的
5.spark streaming和storm对比

Spark Streaming是基于RDD的,因此需要将一小段时间内的,比如1秒内的数据,收集起来,作为一个RDD,然后再针对这个batch的数据进行处理。而Storm却可以做到每来一条数据,都可以立即进行处理和计算。因此,Spark Streaming实际上严格意义上来说,只能称作准实时的流计算框架;而Storm是真正意义上的实时计算框架。
Storm支持的一项高级特性,是Spark Streaming暂时不具备的,即Storm支持在分布式流式计算程序(Topology)在运行过程中,可以动态地调整并行度,从而动态提高并发处理能力。而Spark Streaming是无法动态调整并行度的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号