
102302124_严涛_作业3
作业1.
(1)代码及结果截图:
单线程代码:
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
import time
from urllib.parse import urljoin, urlparse
class SingleThreadImageCrawler:
def __init__(self, base_url, max_pages=24, max_images=124):
self.base_url = base_url
self.max_pages = max_pages
self.max_images = max_images
self.downloaded_count = 0
self.visited_pages = set()
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
})
# 创建图片存储目录
self.image_dir = 'images_single'
if not os.path.exists(self.image_dir):
os.makedirs(self.image_dir)
def is_valid_url(self, url):
"""检查URL是否有效"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)
def download_image(self, img_url, page_url):
"""下载单个图片"""
try:
# 处理相对URL
if not img_url.startswith(('http://', 'https://')):
img_url = urljoin(page_url, img_url)
if not self.is_valid_url(img_url):
return False
# 检查图片格式
valid_extensions = ('.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp')
if not any(img_url.lower().endswith(ext) for ext in valid_extensions):
return False
print(f"正在下载: {img_url}")
response = self.session.get(img_url, timeout=10)
response.raise_for_status()
# 从URL提取文件名
filename = os.path.basename(urlparse(img_url).path)
if not filename:
filename = f"image_{self.downloaded_count + 1}.jpg"
# 确保文件名唯一
filepath = os.path.join(self.image_dir, filename)
counter = 1
while os.path.exists(filepath):
name, ext = os.path.splitext(filename)
filepath = os.path.join(self.image_dir, f"{name}_{counter}{ext}")
counter += 1
# 保存图片
with open(filepath, 'wb') as f:
f.write(response.content)
self.downloaded_count += 1
print(f"成功下载: {filename} (总计: {self.downloaded_count}/{self.max_images})")
return True
except Exception as e:
print(f"下载失败 {img_url}: {e}")
return False
def crawl_page(self, url):
"""爬取单个页面"""
if url in self.visited_pages or len(self.visited_pages) >= self.max_pages:
return
print(f"正在爬取页面: {url}")
self.visited_pages.add(url)
try:
response = self.session.get(url, timeout=10)
response.raise_for_status()
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有图片
img_tags = soup.find_all('img')
for img in img_tags:
if self.downloaded_count >= self.max_images:
return
img_src = img.get('src') or img.get('data-src')
if img_src:
self.download_image(img_src, url)
# 查找其他页面链接(限制深度)
if len(self.visited_pages) < self.max_pages:
links = soup.find_all('a', href=True)
for link in links[:10]: # 限制每页链接数量
if self.downloaded_count >= self.max_images:
return
next_url = link['href']
if not next_url.startswith('http'):
next_url = urljoin(url, next_url)
if self.base_url in next_url and next_url not in self.visited_pages:
self.crawl_page(next_url)
except Exception as e:
print(f"爬取页面失败 {url}: {e}")
def start_crawl(self):
"""开始爬取"""
print("开始单线程爬取...")
print(f"目标网站: {self.base_url}")
print(f"最大页数: {self.max_pages}")
print(f"最大图片数: {self.max_images}")
print("-" * 50)
start_time = time.time()
self.crawl_page(self.base_url)
end_time = time.time()
print("-" * 50)
print(f"爬取完成!")
print(f"总耗时: {end_time - start_time:.2f}秒")
print(f"访问页面: {len(self.visited_pages)}个")
print(f"下载图片: {self.downloaded_count}张")
# 使用示例
if __name__ == "__main__":
crawler = SingleThreadImageCrawler(
base_url="http://www.weather.com.cn",
max_pages=24,
max_images=124
)
crawler.start_crawl()
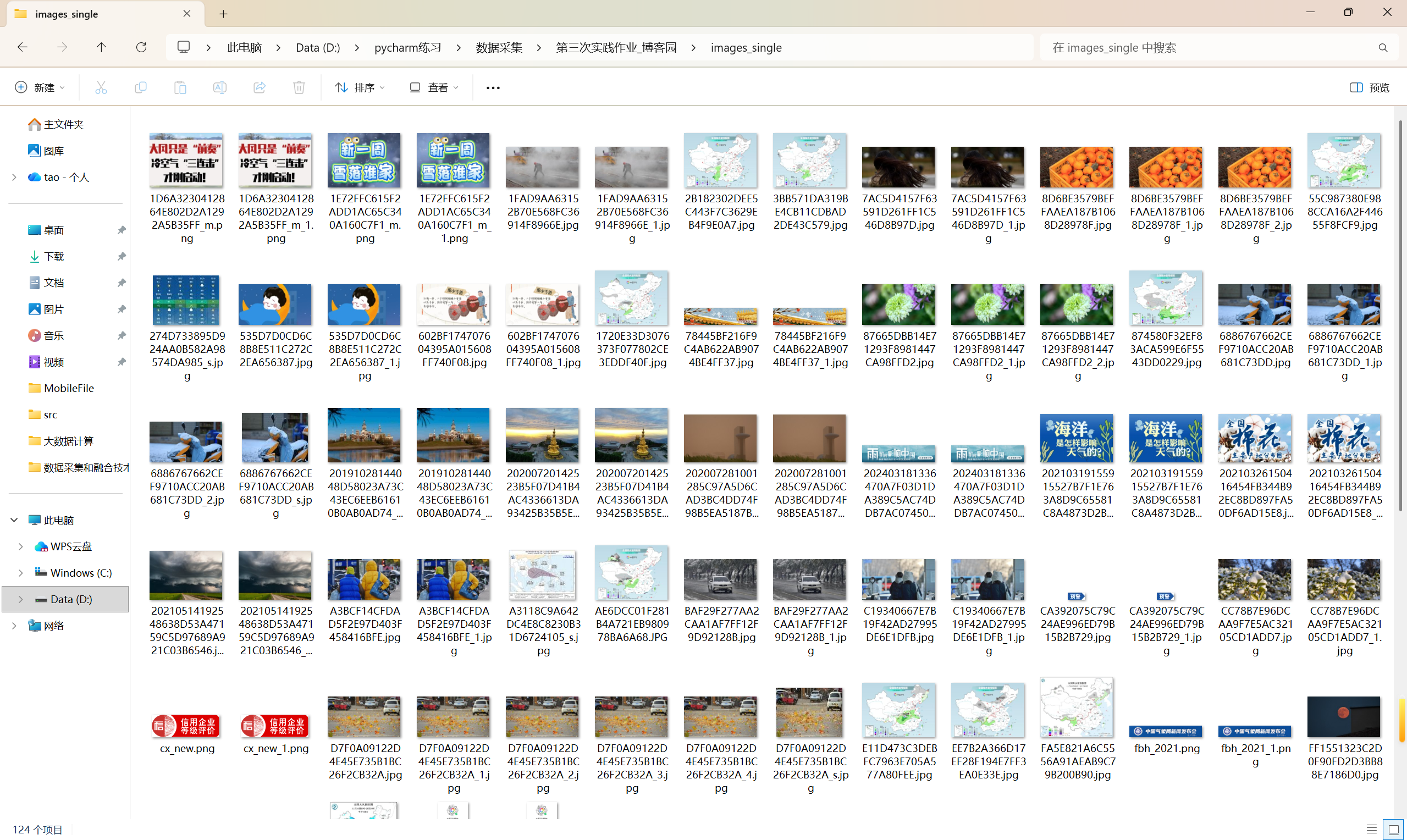
https://gitee.com/yan-tao2380465352/2025_crawl_project/blob/master/第三次实践作业_test_one.py
多线程代码:
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
import time
import threading
from urllib.parse import urljoin, urlparse
from queue import Queue
class MultiThreadImageCrawler:
def __init__(self, base_url, max_pages=24, max_images=124, thread_count=5):
self.base_url = base_url
self.max_pages = max_pages
self.max_images = max_images
self.thread_count = thread_count
self.downloaded_count = 0
self.visited_pages = set()
self.page_queue = Queue()
self.lock = threading.Lock()
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
})
# 创建图片存储目录
self.image_dir = 'images_multi'
if not os.path.exists(self.image_dir):
os.makedirs(self.image_dir)
# 添加初始URL到队列
self.page_queue.put(base_url)
self.visited_pages.add(base_url)
def is_valid_url(self, url):
"""检查URL是否有效"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)
def download_image(self, img_url, page_url):
"""下载单个图片"""
with self.lock:
if self.downloaded_count >= self.max_images:
return False
try:
# 处理相对URL
if not img_url.startswith(('http://', 'https://')):
img_url = urljoin(page_url, img_url)
if not self.is_valid_url(img_url):
return False
# 检查图片格式
valid_extensions = ('.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp')
if not any(img_url.lower().endswith(ext) for ext in valid_extensions):
return False
print(f"线程{threading.current_thread().name} 正在下载: {img_url}")
response = self.session.get(img_url, timeout=10)
response.raise_for_status()
# 从URL提取文件名
filename = os.path.basename(urlparse(img_url).path)
if not filename:
filename = f"image_{self.downloaded_count + 1}.jpg"
# 确保文件名唯一
filepath = os.path.join(self.image_dir, filename)
counter = 1
while os.path.exists(filepath):
name, ext = os.path.splitext(filename)
filepath = os.path.join(self.image_dir, f"{name}_{counter}{ext}")
counter += 1
# 保存图片
with open(filepath, 'wb') as f:
f.write(response.content)
with self.lock:
self.downloaded_count += 1
current_count = self.downloaded_count
print(
f"线程{threading.current_thread().name} 成功下载: {filename} (总计: {current_count}/{self.max_images})")
return True
except Exception as e:
print(f"线程{threading.current_thread().name} 下载失败 {img_url}: {e}")
return False
def process_page(self, url):
"""处理单个页面"""
print(f"线程{threading.current_thread().name} 正在爬取页面: {url}")
try:
response = self.session.get(url, timeout=10)
response.raise_for_status()
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有图片
img_tags = soup.find_all('img')
for img in img_tags:
with self.lock:
if self.downloaded_count >= self.max_images:
return
img_src = img.get('src') or img.get('data-src')
if img_src:
self.download_image(img_src, url)
# 查找其他页面链接
with self.lock:
if len(self.visited_pages) >= self.max_pages:
return
links = soup.find_all('a', href=True)
for link in links[:8]: # 限制每页链接数量
with self.lock:
if (self.downloaded_count >= self.max_images or
len(self.visited_pages) >= self.max_pages):
return
next_url = link['href']
if not next_url.startswith('http'):
next_url = urljoin(url, next_url)
if (self.base_url in next_url and
next_url not in self.visited_pages and
len(self.visited_pages) < self.max_pages):
with self.lock:
if next_url not in self.visited_pages:
self.visited_pages.add(next_url)
self.page_queue.put(next_url)
except Exception as e:
print(f"线程{threading.current_thread().name} 爬取页面失败 {url}: {e}")
def worker(self):
"""工作线程函数"""
while True:
with self.lock:
if (self.downloaded_count >= self.max_images or
(self.page_queue.empty() and len(self.visited_pages) >= self.max_pages)):
break
try:
url = self.page_queue.get(timeout=5)
self.process_page(url)
self.page_queue.task_done()
except:
break
def start_crawl(self):
"""开始爬取"""
print("开始多线程爬取...")
print(f"目标网站: {self.base_url}")
print(f"最大页数: {self.max_pages}")
print(f"最大图片数: {self.max_images}")
print(f"线程数量: {self.thread_count}")
print("-" * 50)
start_time = time.time()
# 创建并启动工作线程
threads = []
for i in range(self.thread_count):
thread = threading.Thread(target=self.worker, name=f"Thread-{i + 1}")
thread.daemon = True
thread.start()
threads.append(thread)
# 等待所有任务完成
self.page_queue.join()
# 等待所有线程结束
for thread in threads:
thread.join(timeout=1)
end_time = time.time()
print("-" * 50)
print(f"爬取完成!")
print(f"总耗时: {end_time - start_time:.2f}秒")
print(f"访问页面: {len(self.visited_pages)}个")
print(f"下载图片: {self.downloaded_count}张")
# 使用示例
if __name__ == "__main__":
crawler = MultiThreadImageCrawler(
base_url="http://www.weather.com.cn",
max_pages=24,
max_images=124,
thread_count=5
)
crawler.start_crawl()
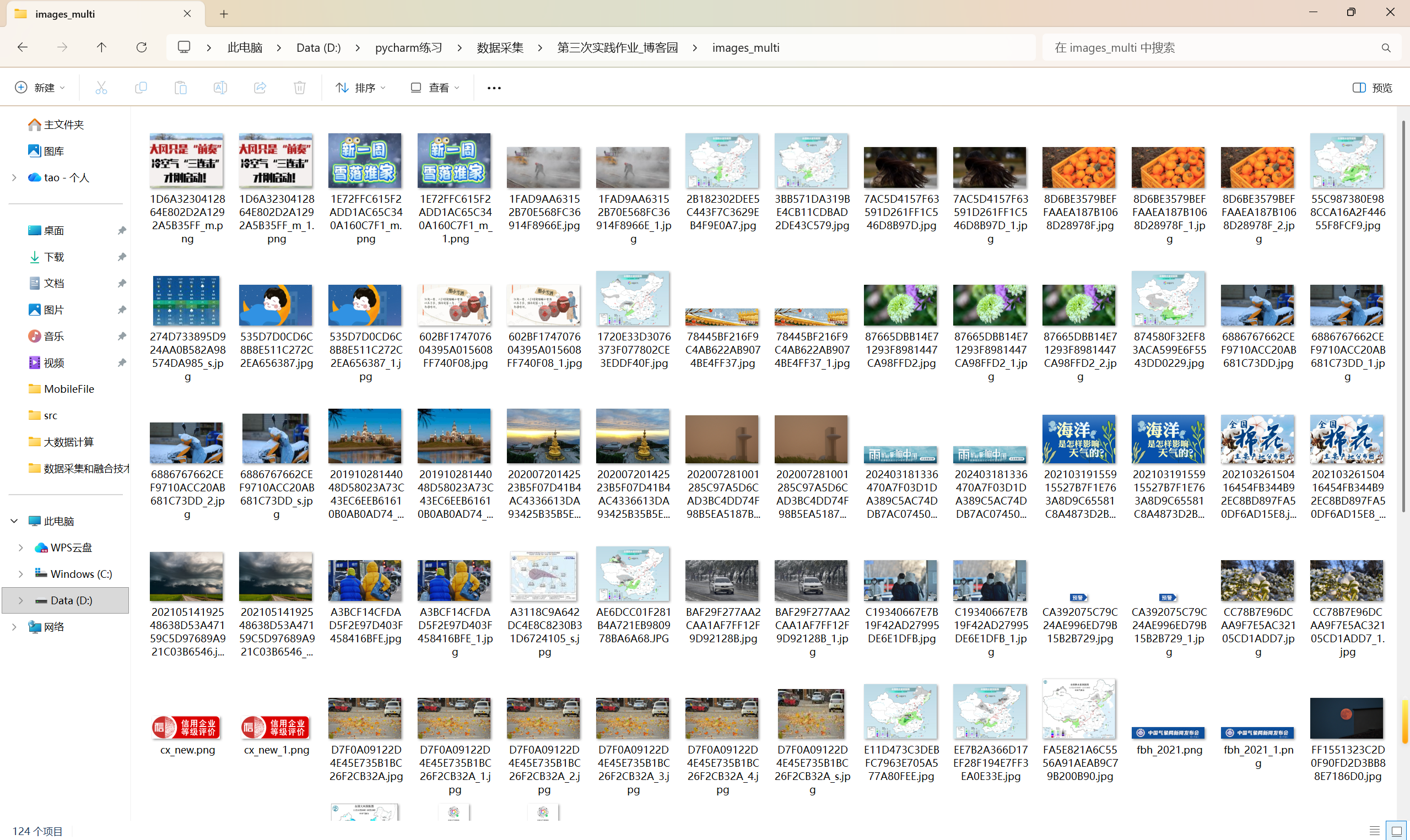
https://gitee.com/yan-tao2380465352/2025_crawl_project/blob/master/第三次实践作业_test_two.py
(2)心得体会:
在实现过程中,我深刻体会到了两种爬取方式的本质区别:
单线程爬虫:
实现简单,逻辑清晰,易于调试;按顺序执行,稳定性高,结果可预测;但效率较低,CPU和网络资源利用率不足;适合小规模爬取或学习理解爬虫原理多线程爬虫。
多线程爬虫:
效率显著提升,资源利用更充分;但复杂度增加,需要处理线程同步、资源竞争等问题;结果具有一定不确定性,爬取顺序不固定;适合大规模数据采集,但对编程能力要求更高。
作业2.
(1)代码及结果截图:
点击查看代码
import scrapy
import json
class EastmoneySpiderSpider(scrapy.Spider):
name = 'eastmoney_spider'
# 使用东方财富的API接口,更稳定
def start_requests(self):
# 上海A股
urls = [
'http://82.push2.eastmoney.com/api/qt/clist/get?pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse_api)
def parse_api(self, response):
data = json.loads(response.text)
stocks = data['data']['diff']
for i, stock in enumerate(stocks.items(), 1):
stock_code, stock_info = stock
item = {
'id': i,
'stock_code': stock_info.get('f12', 'N/A'), # 股票代码
'stock_name': stock_info.get('f14', 'N/A'), # 股票名称
'latest_price': stock_info.get('f2', 'N/A'), # 最新价
'change_rate': f"{stock_info.get('f3', 0)}%", # 涨跌幅
'change_amount': stock_info.get('f4', 'N/A'), # 涨跌额
'volume': stock_info.get('f5', 'N/A'), # 成交量
'turnover': stock_info.get('f6', 'N/A'), # 成交额
'amplitude': f"{stock_info.get('f7', 0)}%", # 振幅
'high': stock_info.get('f15', 'N/A'), # 最高
'low': stock_info.get('f16', 'N/A'), # 最低
'open': stock_info.get('f17', 'N/A'), # 今开
'previous_close': stock_info.get('f18', 'N/A'), # 昨收
}
yield item
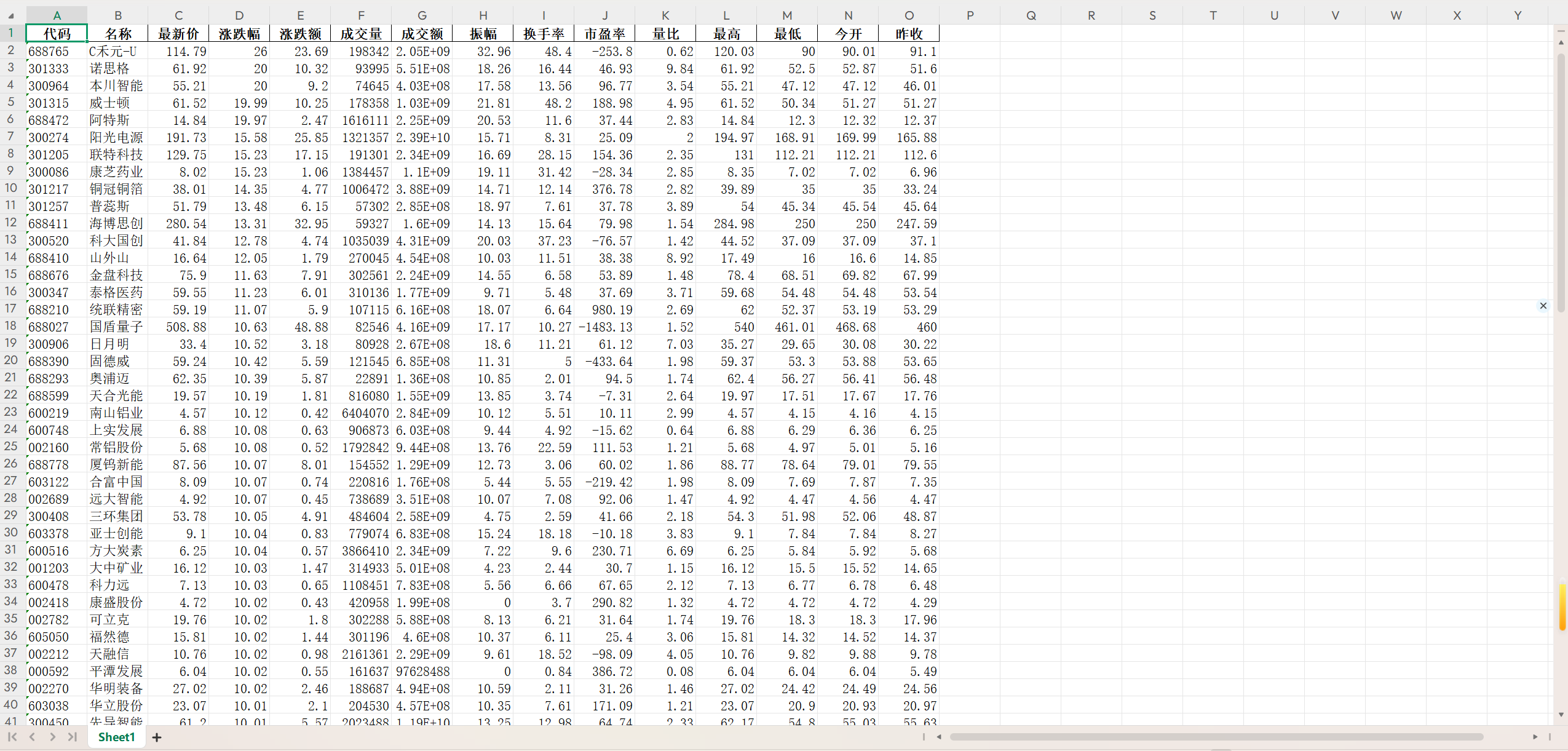
https://gitee.com/yan-tao2380465352/2025_crawl_project/blob/master/第三次实践作业_test_three.py
(2)心得体会:真正理解了Scrapy框架的组件架构:Spider、Item、Pipeline、Middleware的协作关系;掌握了XPath选择器的使用技巧,学会了如何定位动态变化的网页元素;理解了异步爬虫的工作原理,相比requests库效率更高。
作业3.
(1)代码及结果截图:
点击查看代码
import scrapy
from boc_forex.items import BocForexItem
class ForexSpider(scrapy.Spider):
name = 'forex'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response, **kwargs):
rows = response.xpath('//table[@align="left"]/tr[position()>1]')
for row in rows:
item = BocForexItem()
item['currency'] = row.xpath('./td[1]/text()').get(default='').strip()
item['tbp'] = row.xpath('./td[2]/text()').get(default='').strip()
item['cbp'] = row.xpath('./td[3]/text()').get(default='').strip()
item['tsp'] = row.xpath('./td[4]/text()').get(default='').strip()
item['csp'] = row.xpath('./td[5]/text()').get(default='').strip()
item['time'] = row.xpath('./td[7]/text()').get(default='').strip()
yield item
结果截图:
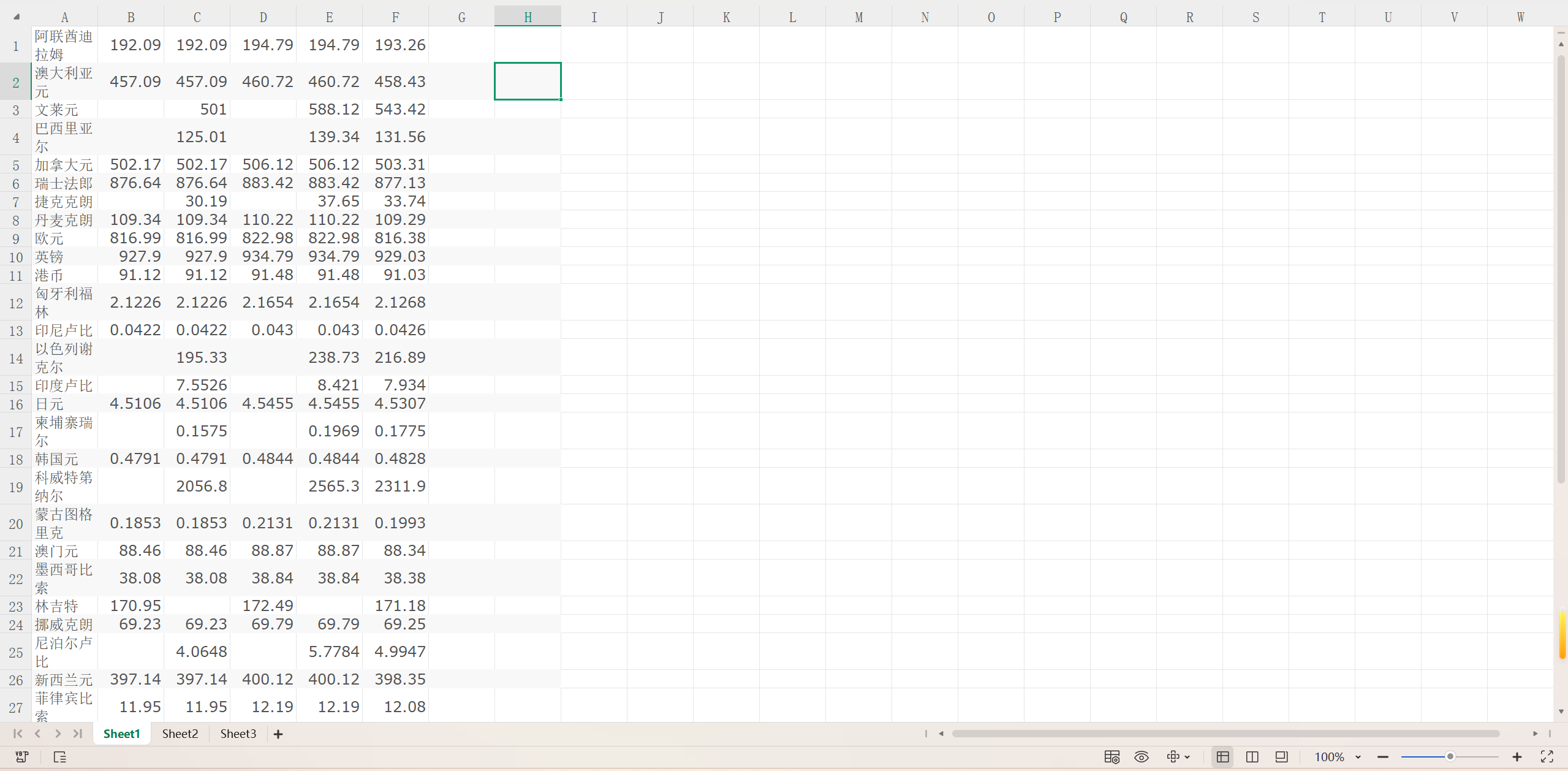
https://gitee.com/yan-tao2380465352/2025_crawl_project/blob/master/第三次实践作业_test_four.py
(2)心得体会:
中国银行外汇牌价页面采用传统的表格布局,看似简单但结构规整;掌握了时间参数在URL中的传递机制,理解了历史数据查询的原理;学会了分析网页的翻页逻辑和日期选择功能;从简单的元素定位到复杂的多层级数据提取;掌握了表格数据的结构化解析技巧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号