
102302124_严涛第一次作业
作业1.
(1)代码及结果截图:
点击查看代码
import urllib.request
from bs4 import BeautifulSoup
import ssl
# 解决SSL证书验证问题
ssl._create_default_https_context = ssl._create_unverified_context
def get_university_ranking_improved(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
try:
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
print("排名\t学校名称\t\t\t省市\t学校类型\t总分")
print("-" * 70)
# 方法1:直接通过CSS选择器查找
rows = soup.select('tbody tr')
for row in rows:
# 获取所有td单元格
cells = row.find_all('td')
if len(cells) >= 5:
# 排名(第一个td)
rank = cells[0].get_text().strip()
# 学校名称(第二个td中的a标签或直接文本)
name_cell = cells[1]
university_name = name_cell.find('a')
if university_name:
university_name = university_name.get_text().strip()
else:
university_name = name_cell.get_text().strip()
# 省市(第三个td)
province = cells[2].get_text().strip()
# 学校类型(第四个td)
school_type = cells[3].get_text().strip()
# 总分(第五个td)
total_score = cells[4].get_text().strip()
# 调整输出格式,根据名称长度调整制表符
if len(university_name) >= 7:
name_tab = "\t"
else:
name_tab = "\t\t"
print(f"{rank}\t{university_name}{name_tab}{province}\t{school_type}\t{total_score}")
except Exception as e:
print(f"爬取过程中出现错误: {e}")
def main():
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
print(f"正在爬取软科2020年中国大学排名...")
print(f"网址: {url}")
print()
get_university_ranking_improved(url)
if __name__ == "__main__":
main()
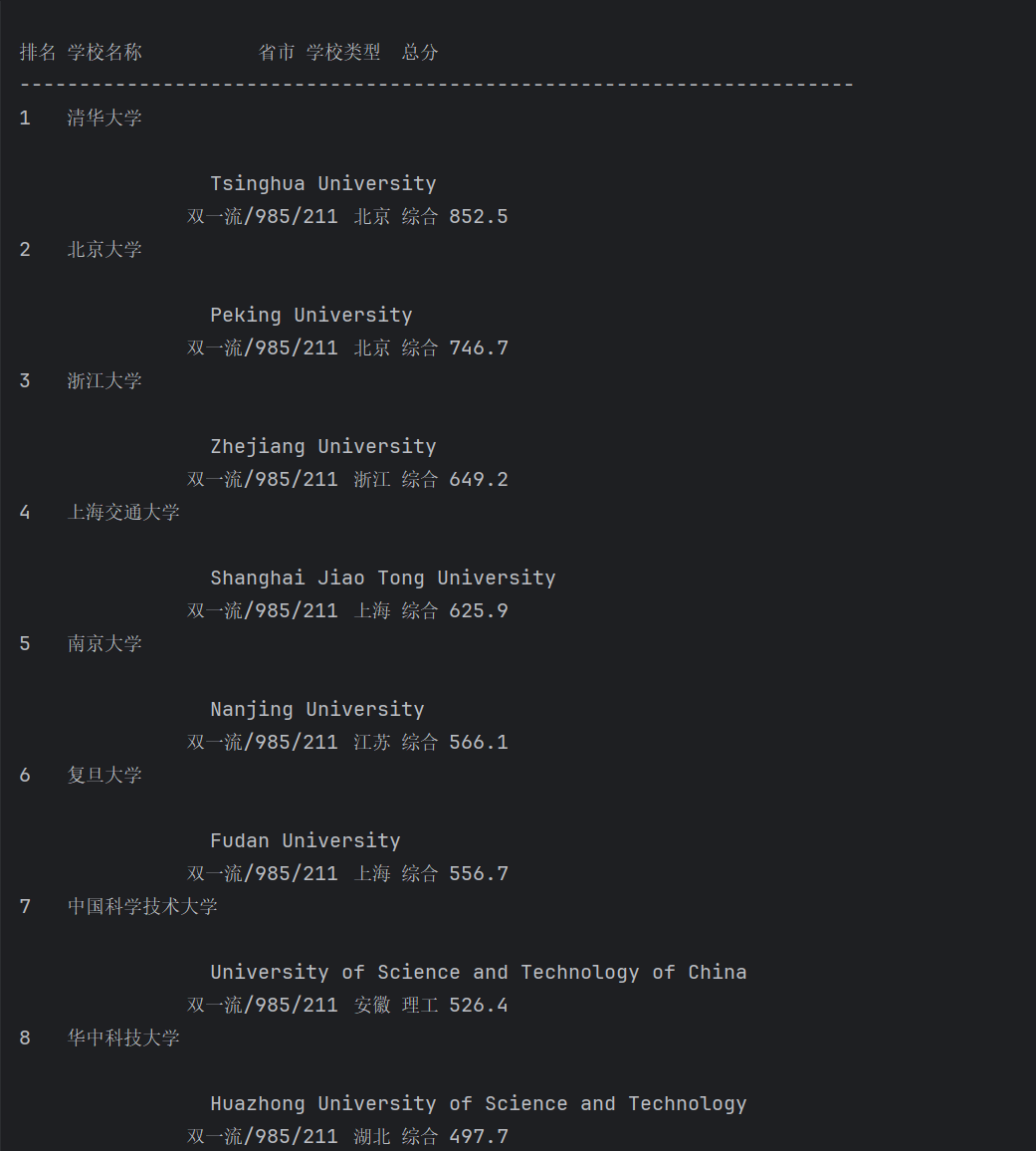
(2)心得体会:学会了如何使用requests库发送HTTP请求,设置请求头模拟浏览器访问,处理超时和异常情况;掌握了使用BeautifulSoup解析HTML文档,通过标签名、类名等属性定位目标元素;认识到很多网站会有反爬虫措施,需要通过设置合适的User-Agent等请求头来模拟正常浏览器访问;相比手动复制粘贴,爬虫技术可以快速、准确地获取大量结构化数据;明白了爬取数据时要尊重网站的robots.txt规定
作业2.
(1)代码及结果截图:
点击查看代码
import urllib3
import re
import time
import random
import json
import csv
from urllib.parse import quote
from bs4 import BeautifulSoup
class DangDangBookBagCrawler:
def __init__(self):
# 创建连接池,禁用SSL验证避免证书问题
self.http = urllib3.PoolManager(cert_reqs='CERT_NONE')
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Referer': 'https://www.dangdang.com/',
'Accept-Encoding': 'gzip',
'Connection': 'keep-alive'
}
self.base_url = "http://search.dangdang.com" # 使用搜索域名
def check_robots_txt(self):
"""检查当当网的robots.txt - 修复编码问题"""
robots_url = "http://www.dangdang.com/robots.txt"
try:
response = self.http.request('GET', robots_url, headers=self.headers)
if response.status == 200:
# 尝试多种编码
try:
content = response.data.decode('gbk')
except:
try:
content = response.data.decode('utf-8')
except:
content = response.data.decode('utf-8', errors='ignore')
print("=== 当当网robots.txt内容 ===")
print(content)
print("=" * 50)
return content
else:
print(f"无法访问robots.txt,状态码: {response.status}")
return None
except Exception as e:
print(f"检查robots.txt时出错: {e}")
return None
def respectful_delay(self):
"""添加 respectful 的延迟"""
delay = random.uniform(1, 3)
time.sleep(delay)
def get_html(self, url):
"""获取页面HTML内容 - 修复编码问题"""
self.respectful_delay()
try:
print(f"正在请求: {url}")
response = self.http.request('GET', url, headers=self.headers)
print(f"响应状态码: {response.status}")
if response.status == 200:
# 尝试多种编码方式
try:
return response.data.decode('gbk')
except UnicodeDecodeError:
try:
return response.data.decode('utf-8')
except UnicodeDecodeError:
return response.data.decode('utf-8', errors='ignore')
elif response.status == 403:
print("访问被拒绝(403),可能触发了反爬虫机制")
return None
elif response.status == 404:
print("页面不存在(404)")
return None
else:
print(f"请求失败,状态码: {response.status}")
return None
except Exception as e:
print(f"请求错误: {e}")
return None
def search_book_bags(self, keyword="书包", pages=2):
"""搜索书包商品 - 使用正确的搜索URL"""
all_products = []
for page in range(1, pages + 1):
print(f"\n正在爬取第 {page} 页...")
# 当当网搜索URL的正确格式
encoded_keyword = quote(keyword)
url = f"http://search.dangdang.com/?key={encoded_keyword}&page_index={page}"
html = self.get_html(url)
if html:
# 保存HTML用于调试
with open(f"debug_page_{page}.html", "w", encoding="utf-8") as f:
f.write(html)
products = self.parse_products(html)
if products:
all_products.extend(products)
print(f"第 {page} 页找到 {len(products)} 个商品")
else:
print(f"第 {page} 页未找到商品,尝试备用解析方法...")
products_backup = self.parse_products_backup(html)
if products_backup:
all_products.extend(products_backup)
print(f"备用方法找到 {len(products_backup)} 个商品")
else:
print(f"第 {page} 页访问失败")
# 页间延迟
time.sleep(random.uniform(2, 4))
return all_products
def parse_products(self, html):
"""解析当当网商品信息 - 改进解析逻辑"""
products = []
try:
# 使用BeautifulSoup解析
soup = BeautifulSoup(html, 'html.parser')
# 方法1: 查找商品列表项
product_items = soup.find_all('li', class_=re.compile(r'line\d+'))
# 方法2: 查找具有特定属性的商品项
if not product_items:
product_items = soup.find_all('div', class_=re.compile(r'con shoplist'))
# 方法3: 查找所有包含价格的商品项
if not product_items:
product_items = soup.find_all(attrs={'ddt-pid': True})
print(f"找到 {len(product_items)} 个潜在商品项")
for item in product_items:
try:
product_info = self.extract_product_info(item)
if product_info and product_info['price'] > 0:
products.append(product_info)
except Exception as e:
continue
except Exception as e:
print(f"解析HTML时出错: {e}")
return products
def parse_products_backup(self, html):
"""备用解析方法 - 使用正则表达式"""
products = []
try:
# 正则表达式模式匹配商品信息
patterns = [
# 模式1: 商品名称和价格
r'"pic":\s*"([^"]*)".*?"name":\s*"([^"]*)".*?"price":\s*"([^"]*)"',
# 模式2: HTML结构
r'<a[^>]*title="([^"]*)"[^>]*>.*?<span[^>]*class="search_now_price"[^>]*>([^<]*)</span>',
# 模式3: 数据属性
r'data-name="([^"]*)"[^>]*data-price="([^"]*)"'
]
for pattern in patterns:
matches = re.findall(pattern, html, re.S | re.I)
for match in matches:
try:
if len(match) >= 2:
if len(match) == 3:
img, name, price = match
else:
name, price = match[0], match[1]
# 清理价格
price_clean = re.search(r'(\d+\.?\d*)', str(price))
if price_clean and name:
products.append({
'name': name.strip(),
'price': float(price_clean.group(1)),
'shop': '当当自营',
'source': '当当网',
'link': ''
})
except:
continue
except Exception as e:
print(f"备用解析出错: {e}")
return products
def extract_product_info(self, item):
"""从商品项中提取信息 - 改进提取逻辑"""
product = {}
try:
# 提取商品名称
name_elem = item.find('a', attrs={'title': True})
if not name_elem:
name_elem = item.find('p', class_=re.compile(r'name'))
if not name_elem:
name_elem = item.find(attrs={'dd_name': True})
if name_elem:
product['name'] = name_elem.get('title', '').strip()
if not product['name']:
product['name'] = name_elem.get_text().strip()
# 提取价格
price_elem = item.find('span', class_='search_now_price')
if not price_elem:
price_elem = item.find('p', class_=re.compile(r'price'))
if not price_elem:
price_elem = item.find(attrs={'dd_price': True})
if price_elem:
price_text = price_elem.get_text()
price_match = re.search(r'(\d+\.?\d*)', price_text)
if price_match:
product['price'] = float(price_match.group(1))
else:
product['price'] = 0.0
else:
product['price'] = 0.0
# 提取店铺信息
shop_elem = item.find('a', class_=re.compile(r'link'))
if shop_elem:
product['shop'] = shop_elem.get_text().strip()
else:
product['shop'] = "当当自营"
# 提取商品链接
if name_elem and name_elem.get('href'):
link = name_elem['href']
if link and not link.startswith('http'):
product['link'] = "http:" + link
else:
product['link'] = link
else:
product['link'] = ""
product['source'] = '当当网'
# 验证必要字段
if not product.get('name') or product['price'] <= 0:
return None
except Exception as e:
return None
return product
def debug_html_structure(self, html):
"""调试HTML结构"""
print("\n=== 调试HTML结构 ===")
soup = BeautifulSoup(html, 'html.parser')
# 查找所有包含价格的元素
price_elements = soup.find_all(text=re.compile(r'¥|\$|¥|\d+\.?\d*元'))
print(f"找到 {len(price_elements)} 个价格相关元素")
# 查找所有链接
links = soup.find_all('a', href=True)
print(f"找到 {len(links)} 个链接")
# 查找所有图片
images = soup.find_all('img')
print(f"找到 {len(images)} 个图片")
# 保存调试信息
with open("debug_structure.txt", "w", encoding="utf-8") as f:
f.write("=== 页面标题 ===\n")
if soup.title:
f.write(str(soup.title.string) + "\n")
f.write("\n=== 前10个链接 ===\n")
for link in links[:10]:
f.write(f"{link.get('href')} - {link.get_text()[:50]}\n")
def analyze_results(self, products):
"""分析爬取结果"""
if not products:
print("未找到任何商品")
return
print(f"\n{'=' * 60}")
print(f"📊 当当网书包数据分析报告")
print(f"{'=' * 60}")
print(f"商品总数: {len(products)}")
# 价格分析
prices = [p['price'] for p in products]
if prices:
print(f"\n💰 价格分析:")
print(f" 最低价格: ¥{min(prices):.2f}")
print(f" 最高价格: ¥{max(prices):.2f}")
print(f" 平均价格: ¥{sum(prices) / len(prices):.2f}")
# 价格分布
price_ranges = {
"0-50元": 0,
"50-100元": 0,
"100-200元": 0,
"200-500元": 0,
"500元以上": 0
}
for price in prices:
if price <= 50:
price_ranges["0-50元"] += 1
elif price <= 100:
price_ranges["50-100元"] += 1
elif price <= 200:
price_ranges["100-200元"] += 1
elif price <= 500:
price_ranges["200-500元"] += 1
else:
price_ranges["500元以上"] += 1
print(f"\n📈 价格分布:")
for range_name, count in price_ranges.items():
if count > 0:
percentage = (count / len(products)) * 100
print(f" {range_name}: {count}件 ({percentage:.1f}%)")
def show_products(self, products, top_n=20):
"""显示商品列表"""
if not products:
return
print(f"\n🛍️ 商品列表 (显示前{top_n}个):")
print(f"{'-' * 100}")
sorted_products = sorted(products, key=lambda x: x['price'])
for i, product in enumerate(sorted_products[:top_n], 1):
print(f"{i:2d}. ¥{product['price']:6.2f} | {product['name'][:50]}...")
def save_to_files(self, products):
"""保存数据到文件"""
if not products:
print("没有数据可保存")
return
# 保存为JSON
json_filename = "dangdang_bookbags.json"
with open(json_filename, 'w', encoding='utf-8') as f:
json.dump(products, f, ensure_ascii=False, indent=2)
# 保存为CSV
csv_filename = "dangdang_bookbags.csv"
with open(csv_filename, 'w', newline='', encoding='utf-8') as f:
if products:
fieldnames = products[0].keys()
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(products)
print(f"\n💾 数据已保存:")
print(f" JSON文件: {json_filename}")
print(f" CSV文件: {csv_filename}")
def main():
print("🎒 当当网书包数据爬虫 (修复版)")
print("=" * 50)
# 创建爬虫实例
crawler = DangDangBookBagCrawler()
# 检查robots.txt(跳过如果出错)
try:
print("🔍 检查当当网robots.txt...")
crawler.check_robots_txt()
except:
print("跳过robots.txt检查")
# 爬取数据
print("\n🚀 开始爬取当当网书包数据...")
products = crawler.search_book_bags(keyword="书包", pages=2)
if products:
# 分析结果
crawler.analyze_results(products)
# 显示商品
crawler.show_products(products, top_n=20)
# 保存数据
crawler.save_to_files(products)
print(f"\n✅ 爬取完成!共获取 {len(products)} 个书包商品")
else:
print("\n❌ 未能获取商品数据")
print("尝试检查网络连接或网站结构")
if __name__ == "__main__":
main()
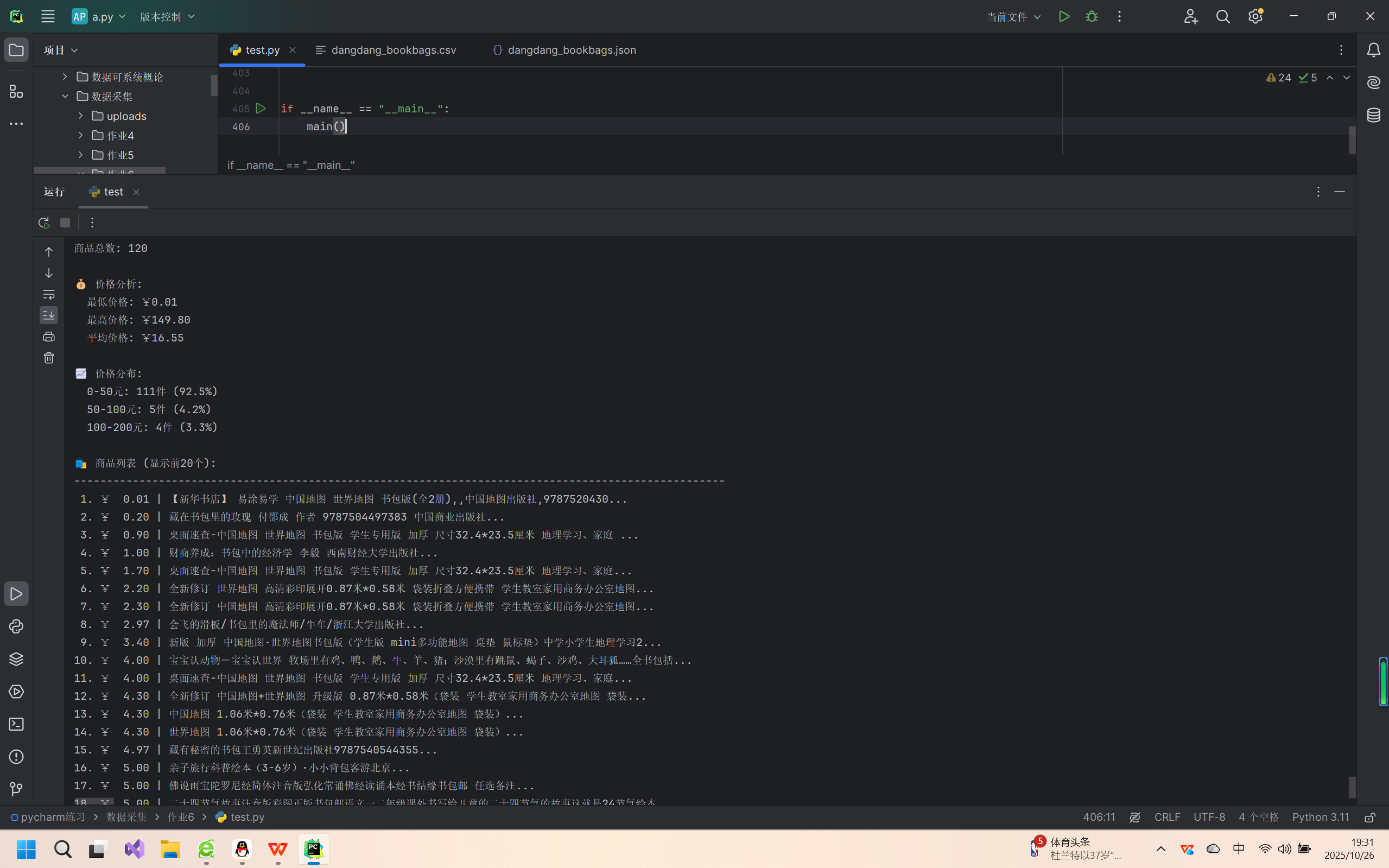
(2)心得体会:与第一个作业使用BeautifulSoup相比,正则表达式更灵活但编写难度更大,需要反复调试正则模式来准确提取目标数据;商品信息分布在多个HTML标签和属性中,提取逻辑复杂;认识到爬取商业数据需要遵守网站的使用条款
作业3.
(1)代码及结果截图:
点击查看代码
import re
import urllib.request
import os
from colorama import Fore, Style, init
from urllib.parse import urljoin, urlparse
init(autoreset=True)
# ------------------------------
# 1. 定义函数:下载网页
# ------------------------------
def get_html(url):
headers = {"User-Agent": "Mozilla/5.0"}
req = urllib.request.Request(url, headers=headers)
with urllib.request.urlopen(req) as response:
html = response.read().decode("utf-8", errors="ignore")
return html
# ------------------------------
# 2. 定义函数:从HTML中提取多种格式图片链接
# ------------------------------
def get_image_links(html, base_url):
# 匹配多种图片格式:jpg, jpeg, png (不区分大小写)
pattern = re.compile(r'src="([^"]+?\.(?:jpg|jpeg|png))"', re.IGNORECASE)
links = pattern.findall(html)
full_links = []
for link in links:
# 使用urljoin处理相对URL,更安全的方法
full_link = urljoin(base_url, link)
full_links.append(full_link)
return list(set(full_links)) # 去重
# ------------------------------
# 3. 定义函数:下载图片并保持原始格式
# ------------------------------
def download_images(links, folder="images"):
if not os.path.exists(folder):
os.makedirs(folder)
print(Fore.BLUE + f"创建文件夹: {folder}")
success_count = 0
fail_count = 0
for i, url in enumerate(links, start=1):
try:
# 从URL中提取原始文件名和扩展名
parsed_url = urlparse(url)
original_filename = os.path.basename(parsed_url.path)
# 如果原始文件名有效,使用原始文件名,否则生成默认文件名
if original_filename and '.' in original_filename:
# 保持原始文件名,但确保扩展名是小写
name, ext = os.path.splitext(original_filename)
filename = f"{name}{ext.lower()}"
else:
# 根据URL推断扩展名或使用默认
if url.lower().endswith('.jpeg'):
ext = '.jpeg'
elif url.lower().endswith('.jpg'):
ext = '.jpg'
elif url.lower().endswith('.png'):
ext = '.png'
else:
ext = '.jpg' # 默认扩展名
filename = f"img_{i}{ext}"
filepath = os.path.join(folder, filename)
# 如果文件已存在,添加序号
counter = 1
original_filepath = filepath
while os.path.exists(filepath):
name, ext = os.path.splitext(original_filepath)
filepath = f"{name}_{counter}{ext}"
counter += 1
# 下载图片
urllib.request.urlretrieve(url, filepath)
# 获取文件大小
file_size = os.path.getsize(filepath) / 1024 # KB
# 根据文件类型显示不同颜色
if filepath.lower().endswith('.jpg') or filepath.lower().endswith('.jpeg'):
color = Fore.CYAN
file_type = "JPG"
elif filepath.lower().endswith('.png'):
color = Fore.MAGENTA
file_type = "PNG"
else:
color = Fore.WHITE
file_type = "其他"
print(color + f"✓ 下载成功 [{file_type}]: {os.path.basename(filepath)} ({file_size:.1f} KB)")
success_count += 1
except Exception as e:
print(Fore.RED + f"✗ 下载失败: {url}")
print(Fore.YELLOW + f" 错误信息: {e}")
fail_count += 1
return success_count, fail_count
# ------------------------------
# 4. 统计和显示图片格式信息
# ------------------------------
def analyze_image_formats(links):
format_count = {
'jpg': 0,
'jpeg': 0,
'png': 0,
'other': 0
}
for link in links:
if link.lower().endswith('.jpg'):
format_count['jpg'] += 1
elif link.lower().endswith('.jpeg'):
format_count['jpeg'] += 1
elif link.lower().endswith('.png'):
format_count['png'] += 1
else:
format_count['other'] += 1
return format_count
# ------------------------------
# 5. 主程序:多页面爬取
# ------------------------------
if __name__ == "__main__":
base_pages = [
"https://news.fzu.edu.cn/yxfd.htm",
"https://news.fzu.edu.cn/yxfd/1.htm",
"https://news.fzu.edu.cn/yxfd/2.htm",
"https://news.fzu.edu.cn/yxfd/3.htm",
"https://news.fzu.edu.cn/yxfd/4.htm",
"https://news.fzu.edu.cn/yxfd/5.htm",
]
all_links = []
print(Fore.YELLOW + "=" * 60)
print(Fore.CYAN + "多格式图片爬虫程序启动")
print(Fore.YELLOW + "支持格式: JPG, JPEG, PNG")
print(Fore.YELLOW + "=" * 60)
# 爬取所有页面
for page_num, page in enumerate(base_pages, 1):
print(f"\n{Fore.BLUE}[页面 {page_num}/{len(base_pages)}] {Fore.WHITE}正在爬取: {page}")
try:
html = get_html(page)
links = get_image_links(html, page)
print(Fore.GREEN + f" ✓ 找到 {len(links)} 张图片")
all_links.extend(links)
except Exception as e:
print(Fore.RED + f" ✗ 页面爬取失败: {e}")
continue
# 去重
all_links = list(set(all_links))
print(Fore.YELLOW + "\n" + "=" * 60)
print(Fore.CYAN + "爬取完成,开始分析图片格式...")
# 分析图片格式
format_stats = analyze_image_formats(all_links)
print(Fore.WHITE + f"总共找到 {len(all_links)} 张图片:")
print(Fore.CYAN + f" JPG格式: {format_stats['jpg']} 张")
print(Fore.CYAN + f" JPEG格式: {format_stats['jpeg']} 张")
print(Fore.MAGENTA + f" PNG格式: {format_stats['png']} 张")
if format_stats['other'] > 0:
print(Fore.YELLOW + f" 其他格式: {format_stats['other']} 张")
print(Fore.YELLOW + "\n" + "=" * 60)
print(Fore.CYAN + "开始下载图片...\n")
# 下载所有图片
success_count, fail_count = download_images(all_links)
# 显示最终结果
print(Fore.YELLOW + "\n" + "=" * 60)
print(Fore.CYAN + "下载完成!")
print(Fore.GREEN + f"✓ 成功下载: {success_count} 张图片")
if fail_count > 0:
print(Fore.RED + f"✗ 下载失败: {fail_count} 张图片")
total_files = len([name for name in os.listdir('images') if os.path.isfile(os.path.join('images', name))])
print(Fore.BLUE + f"📁 图片保存位置: {os.path.abspath('images')}")
print(Fore.BLUE + f"📊 文件夹中现有文件: {total_files} 个")
print(Fore.YELLOW + "=" * 60)
(2)心得体会:学会了使用urljoin将相对URL转换为绝对URL,这是网页爬虫中的重要技能;不仅通过文件扩展名,还通过Content-Type头信息来识别图片格式;发现有些图片使用data-src而不是src属性,需要同时检查多个属性;使用stream=True进行大文件下载,避免内存溢出;控制请求频率,避免对目标网站造成压力

 浙公网安备 33010602011771号
浙公网安备 33010602011771号