
elastic search记录
安装与启动
插件安装
中文分词器 https://github.com/medcl/elasticsearch-analysis-ik
elastic api
GET _search
{
"query": {
"match_all": {}
}
}
GET /_cat/indices
## 查询所有索引中的字段映射
GET _mapping
## 查询index中的type, 所有文档
GET logstash-2019.11.10-000001/_search
## 根据id查询单个详情, 上面结果中返回的type=_doc
GET logstash-2019.11.10-000001/_doc/VL1cU24BpEn5ymJfSBRH?pretty
## 根据message字段全匹配查询, 提供type (已过期)
GET logstash-2019.11.10-000001/_doc/_search?q=message:ffffff
## 根据message字段模糊查询, 提供type (已过期)
GET logstash-2019.11.10-000001/_doc/_search?q=message:*f
## 根据message字段全匹配查询, 不提供type
POST logstash-2019.11.10-000001/_search
{"query":{"match":{"message":"ffffff"}}}
## 根据message字段模糊查询, 使用的是wildcard
POST logstash-2019.11.10-000001/_search
{"query":{"wildcard":{"message":"ff*"}}}
## 排序
GET logstash-2019.11.10-000001/_search
{
"query" : {
"bool" : {
"must": { "match": { "tweet": "manage text search" }},
"filter" : { "term" : { "user_id" : 2 }}
}
},
"sort": [
{ "date": { "order": "desc" }},
{ "_score": { "order": "desc" }}
]
}
_score是ES默认的匹配度计算
## 查询之后计算权重, 在查询表达式中定义函数function_score
# https://www.elastic.co/guide/cn/elasticsearch/guide/current/function-score-query.html
## todo
使用kibana查询
bin/kibana
http://localhost:5601
页面和阿里云的日志中心非常相似
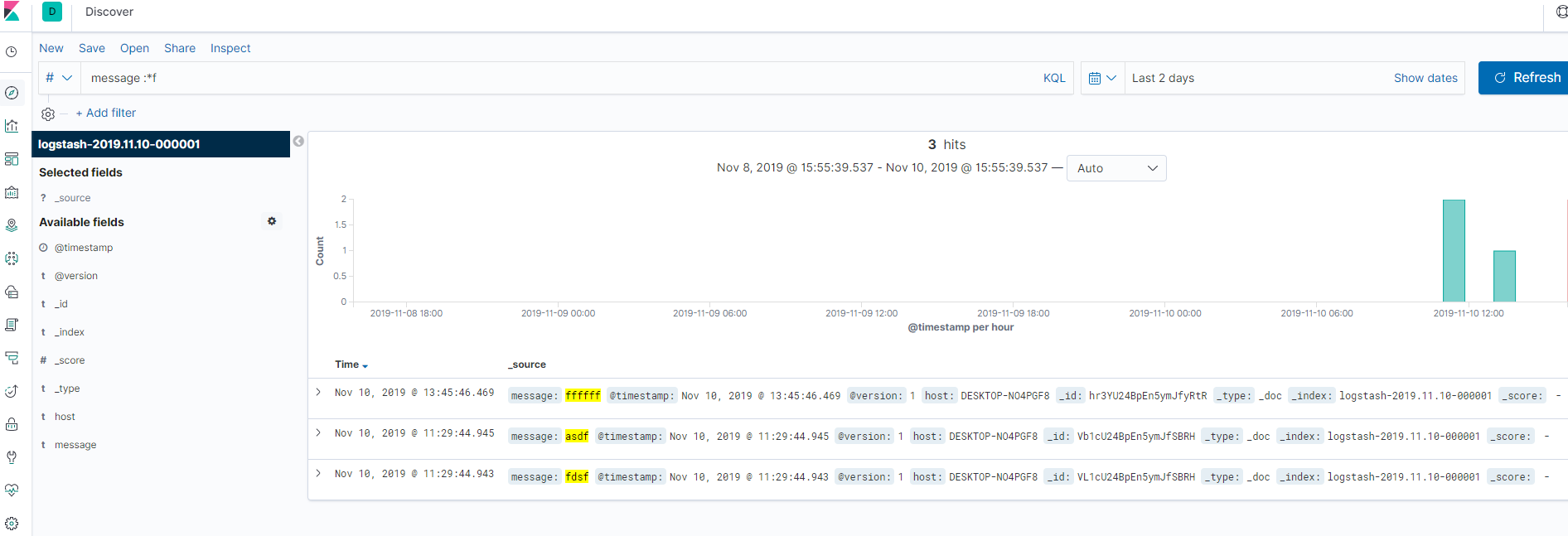
search KQL语法:
https://www.elastic.co/guide/en/kibana/current/kuery-query.html#_range_queries
https://catalog.us-east-1.prod.workshops.aws/workshops/60a6ee4e-e32d-42f5-bd9b-4a2f7c135a72/en-US/03-log-analysis-basics/03-02-log-analysis/03-02-2-search-method
message: "xx xxxx" and message: "xxxxxxxx" value有空格的时候加上双引号
message.http.code: >500 and message: error
中文页面配置
kibana-7.4.2-linux-x86_64\config\kibana.yml最后一行
# Specifies locale to be used for all localizable strings, dates and number formats.
# Supported languages are the following: English - en , by default , Chinese - zh-CN .
i18n.locale: "zh-CN"
关于是否进行分词 分析
【场景:】 id是多个数字用中划线组成的, 如果默认设置type=text/string, 这时不能进行精确匹配的搜索,也不能搜索负号
这里oracle的contains()全文索引的时候 (为了解决like,instr的性能问题),也是同样的问题,查询负号的时候总是不正确,要么性能太低(查询中间的一段数字)
ES的解决方法时设置字段类型为‘keyword’, 而不是text或string, 这样就不会自动分词了 https://www.elastic.co/guide/cn/elasticsearch/guide/current/mapping-intro.html#custom-field-mappings
DELETE /my-index-000001
## 创建index
PUT /my-index-000001
## 设置mapping
PUT /my-index-000001/_mapping
{
"properties": {
"id": {
"type": "keyword"
}
}
}
PUT /my-index-000001/_mapping
{
"properties" : {
"tag" : {
"type" : "text",
"index": "false"
}
}
}
GET /my-index-000001
## 插入document
POST /my-index-000001/_doc/
{
"id": "-999-123123",
"message": "GET /search HTTP/1.1 200 1070000",
"@timestamp": "2099-11-15T13:12:00"
}
POST /my-index-000001/_doc/
{
"id": "999-123123",
"message": "INFO /abccccc HTTP/1.1 200 1070000",
"@timestamp": "2099-11-15T13:12:00"
}
POST /my-index-000001/_doc/
{
"id": "10300222-123123992",
"message": "POST FTP 400",
"@timestamp": "2099-11-15T13:12:00"
}
GET /my-index-000001/_search/
GET /my-index-000001/_search/
{
"query": {
"match": {
"id": "-999"
}
}
}
GET /my-index-000001/_search/
{
"query": {
"match": {
"id": "123123"
}
}
}
## 精确匹配, 要求字段mapping的时候就是"type": "keyword" (ES2的文档是说'not_analyzed'),不是"type": "text"
## https://www.elastic.co/guide/cn/elasticsearch/guide/current/mapping-intro.html#custom-field-mappings
GET /my-index-000001/_search/
{
"query": {
"term": {
"id": "-999-123123"
}
}
}
## 只返回 -999的数据
GET /my-index-000001/_search
{
"query": {
"wildcard": {
"id": "*-999*"
}
}
}
## 返回999和-999的数据
GET /my-index-000001/_search
{
"query": {
"wildcard": {
"id": "*999*"
}
}
}
## NOT WORK!!!
GET /my-index-000001/_search
{
"query": {
"fuzzy": {
"id": "*-999*"
}
}
}
运维
集群中节点数 设置成奇数,防止脑裂
开启数据压缩
spring data elasticsearch
https://spring.io/projects/spring-data-elasticsearch#learn
根据BookRepository 方法名直接生成es查询api
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
</dependency>
spring-web默认没加上,启动报错
jpa接口比较重,spring cloud中可能有很多冲突问题, 使用原生的接口开发也许更快,
索引重建
java使用索引的别名查询, ES别名可以引用新的索引, java应用可以不重启
问题列表
磁盘空间不足时 不能重建索引
java api : upsert的操作 doc_as_update 设置为true,默认是false, update不成功可能是这个原因
Filebeat
window版本坑太多了,运行不起来
linux版本 filebeat.yml文件权限必须是rwxr-xr-x, 777的权限反而运行不起来, 简直了wsl chmod如何生效
./filebeat --strict.perms=false
修改filebeat.yml enabled=true, 默认竟然是false, 运行半天没收集到日志,突然看到这个坑

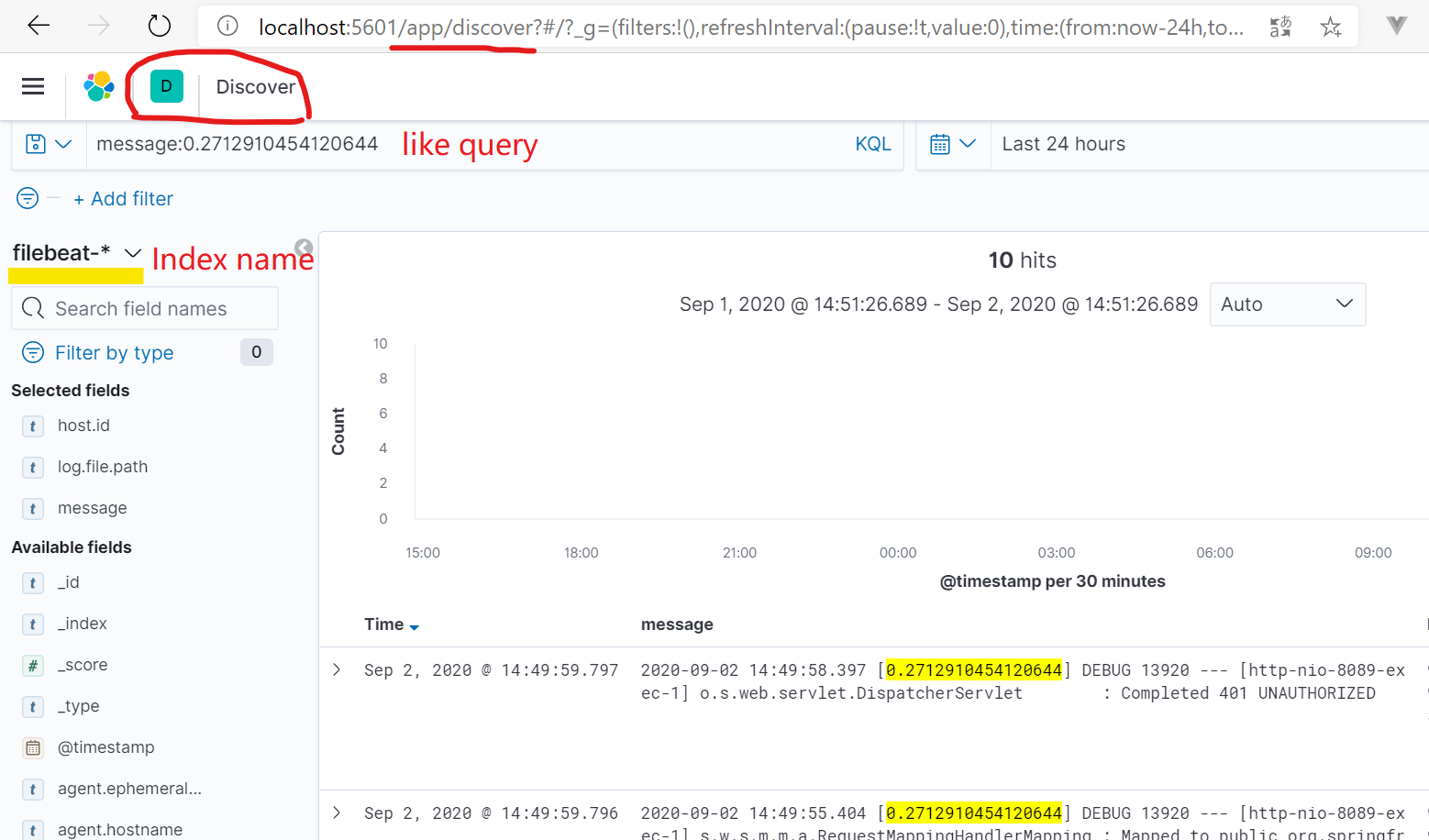
配置多行日志合并, 比如java exception stack log.
filebeat原理
监控日志文件的inode, 文件写入或者切片时,inode会变化,老的inode数据读完后 再到新的inode读数据,这样数据就不会丢失。
ES文档:
API ==> https://www.elastic.co/guide/en/elasticsearch/client/java-rest/6.3/java-rest-high-query-builders.html
book ==> https://www.elastic.co/guide/cn/elasticsearch/guide/current/icu-tokenizer.html
深入相似度算法 https://www.elastic.co/guide/cn/elasticsearch/guide/current/decay-functions.html#decay-functions

 浙公网安备 33010602011771号
浙公网安备 33010602011771号