
Docker+ELK搭建 :一
亲测可以安装:ELK:分布式日志搜集分析系统
ELK分布式日志收集系统介绍
ElasticSearch 是一个基于Lucene的开源分布式搜索服务器。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
Logstash 是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。说到搜索,logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 是一个基于浏览器页面的Elasticsearch前端展示工具,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
filebeat
ELK分布式日志收集原理
1、每台服务器集群节点安装Logstash日志收集系统插件
2、每台服务器节点将日志输入到Logstash中
3、Logstash将该日志格式化为json格式,根据每天创建不同的索引,输出到ElasticSearch中
4、浏览器使用安装Kibana查询日志信息
环境安装
1、安装ElasticSearch
2、安装Logstash
3、安装Kibana
filebeat
简单概述
最近在了解ELK做日志采集相关的内容,这篇文章主要讲解通过filebeat来实现日志的收集。日志采集的工具有很多种,如fluentd, flume, logstash,betas等等。首先要知道为什么要使用filebeat呢?因为logstash是jvm跑的,资源消耗比较大,启动一个logstash就需要消耗500M左右的内存,而filebeat只需要10来M内存资源。常用的ELK日志采集方案中,大部分的做法就是将所有节点的日志内容通过filebeat送到kafka消息队列,然后使用logstash集群读取消息队列内容,根据配置文件进行过滤。然后将过滤之后的文件输送到elasticsearch中,通过kibana去展示。
这就是从机器上的日志,到可视化一个过程,蛮清晰的。
日志数据可以这样:
Filebeat(Shipper) -> Elasticsearch
索引(动词)之前如果要做过滤拆分字段就加个 Logstash:
Filebeat(Shipper) -> Logstash -> Elasticsearch
如果 Agent 量比较大,中间再加一个消息队列:
Filebeat(Shipper) -> 消息队列 -> Logstash -> Elasticsearch
下面安装的几个东西,注意一定要版本号统一
所需要的几个网址:
https://www.elastic.co/cn/downloads/
https://www.elastic.co/cn/what-is/kubernetes-monitoring
点击每个插件下载按钮,会有多个下载方式,本文中使用docker方式
几个常用的docker命令
sudo docker images // 查看本地已有镜像 sudo docker run [image] // 拉取并运行镜像 sudo docker ps -a // 查看容器状态 sudo docker stop [image_id] sudo docker rm [image_id] // 删除指定容器 sudo docker exec -it [image_id] /bin/bash // 进入容器,推荐bash //拷贝容器内文件至主机目录 sudo docker [image_id]:/etc/pki/tls/certs/logstash-beats.crt ~ exit // 退出容器
换了个运行环境,重新搭建一套公司本地内部的ELK,之前也搭过(可访问:https://yanganlin.com/31.html),最近做什么事情都想用Docker,这次也用Docker,还算顺利,没掉什么坑里,上次搭建,也用用的6.2+的版本,这都过了一年,Elk这三个产品,都已经上7了,用docker搭建的还是用6.2.4,稳定不落伍就好
安装elasticsearch
安装
docker run \ -d \ --name elasticsearch \ -p 9200:9200 \ -p 9300:9300 \ -e "discovery.type=single-node" \ docker.elastic.co/elasticsearch/elasticsearch:6.2.4
访问http://localhost:9200
安装kibana
安装
docker run \ -d \ -u 0 \ --name kibana \ -p 5601:5601\ docker.elastic.co/kibana/kibana:6.2.4
进入到容器内部:docker exec -it kibana /bin/bash
找到kibana的配置文件:/usr/share/kibana/config/ kibana.yml
vi 修改配置文件,因为要绕过x-pack的安全检查
elasticsearch.url: http://localhost:9200 实际中不要用127.0.0.1或者local这种的,要用虚拟机或服务器IP xpack.monitoring.ui.container.elasticsearch.enabled: false
重启容器:docker restart kibana
安装logstash
安装
docker run \ -d \ -u 0 \ --name logstash \ -p 5044:5044\ docker.elastic.co/logstash/logstash:6.2.4
进入容器:docker exec -it logstash /bin/bash
找到文件:/usr/share/logstash/pipeline
修改配置文件logstash.conf
input { tcp { port => 5044 codec => json_lines } } output{ elasticsearch { hosts => ["localhost:9200"] action => "index" index => "%{[appname]}" } stdout { codec => rubydebug } }
重启容器:doccker restart logstash
安装filebeat可视化工具
官网: https://www.elastic.co/cn/downloads/beats/filebeat
docker pull docker.elastic.co/beats/filebeat:7.10.2-----这里版本自己改一下,最好跟es版本对应
根据官网提示一步步用docker安装即可
docker run \ docker.elastic.co/beats/filebeat:6.2.4 \ setup -E setup.kibana.host=192.168.31.131:5601 \ -E output.elasticsearch.hosts=["192.168.31.131:9200"] curl -L -O https://raw.githubusercontent.com/elastic/beats/6.2.4/deploy/docker/filebeat.docker.yml docker run -d \ --name=filebeat \ --user=root \ --volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \ --volume="/var/lib/docker/containers:/var/lib/docker/containers:ro" \ --volume="/var/run/docker.sock:/var/run/docker.sock:ro" \ docker.elastic.co/beats/filebeat:6.2.4 filebeat -e -strict.perms=false \ -E output.elasticsearch.hosts=["192.168.31.131:9200"] docker run \ --label co.elastic.logs/module=apache2 \ --label co.elastic.logs/fileset.stdout=access \ --label co.elastic.logs/fileset.stderr=error \ --label co.elastic.metrics/module=apache \ --label co.elastic.metrics/metricsets=status \ --label co.elastic.metrics/hosts='${data.host}:${data.port}' \ --detach=true \ --name my-apache-app \ -p 8080:80 \ httpd:2.4 FROM docker.elastic.co/beats/filebeat:6.2.4 COPY filebeat.yml /usr/share/filebeat/filebeat.yml USER root RUN chown root:filebeat /usr/share/filebeat/filebeat.yml USER filebeat
至此es日志搜集系统部署完成
SpringBoot配置Logstash
logback.xml
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"> <destination>localhost:5044</destination> <encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"> <customFields>{"appname":"eureka-server"}</customFields> </encoder> </appender> <root level="INFO"> <appender-ref ref="LOGSTASH"/> </root>
pom.xml
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.9</version>
</dependency>
在Kibana创建索引
参考:https://yanganlin.com/31.html
注解:::::::::
最近项目有了上线计划,现在面临着日志收集分析的问题,所以让小编来研究一下日志收集分析架构,下面就给大家分享一下小编搭建的第一套日志框架。
环境搭建过程见Linux系统ELK环境搭建手册
架构图如下:
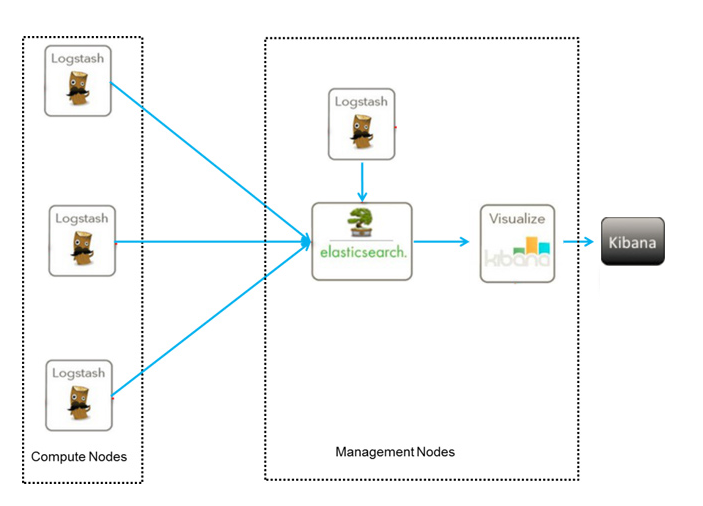
下面说一下这个架构的实现原理,logstash在架构中起到的作用是从每台服务器上的某个路径中的文件中收集数据,并且按照预先编写好的过滤规则来过滤数据,然后按照要求将日志传输到ES集群中,然后通过kibana进行数据的展示.
下面就是比较核心的一步,进行logstash的配置,里面包含对数据输入的配置,数据过滤的配置,数据输出的配置。这三个配置是最重要的。
文件名称为:elasticsearch_output.conf
input { file { path => "/var/log/nginx_access.log" type => "nginx" start_position => "beginning" sincedb_path => "/dev/null" } } filter { grok { match => ["message", "%{TIME}\s+(?<Level>(\S+)).*?\((?<http>(\S+))\)\s*%{TIMESTAMP_ISO8601:time}\s+\[(?<uuid>(\S+))\]\s*\[%{IPORHOST:clientip}\].*"] } } output { elasticsearch { host => "192.168.22.189" protocol => "http" index => "itoo_output-%{type}-%{+YYYY.MM.dd}" document_type => "nginx" workers => 5 } }
因为我们的系统按照约定将日志文件输入到某个路径下面的.log文件中,所以在选择输入类型的时候选择了file类型,其中还有TCP、UDP、rsyslog等类型。
filter是我们自己编写的过滤规则,这个规则需要我们分析自己的日志,然后利用logsta已经给我编写好的一下正则表达式来完成自己的过滤规则的编写。
下面的地址是已经编写好的正则匹配文档:
https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patterns
输出我们选择了ES,关于ES的介绍就不在本编博客中介绍,host是我们搭建的ES集群的主节点的ip地址。index就是在es中创建的名称。
然后我们在需要收集日志的服务器上面启动logstash服务运行这个配置文件即可,启动命令为
./logstash -f elasticsearch_output.conf
这样我们就会可以在es中查看已经导入的日志数据,并且当日志文件有更新的时候,logstash会自动将新增加的内容收集并传入到ES中供我们查看。
这个架构已经搭建完成了,但是这存在着几个问题?
第一:编写过滤规则比较费事
第二:如何将一条错误堆栈信息收集成一条信息存储在es库中
这种架构的优缺点
优点:搭建简单,易于上手。
缺点:logstash消耗资源大,运行占用的CPU和内存较高,并且没有消息队列缓存,这样存在数据的丢失的隐患。
架构二:
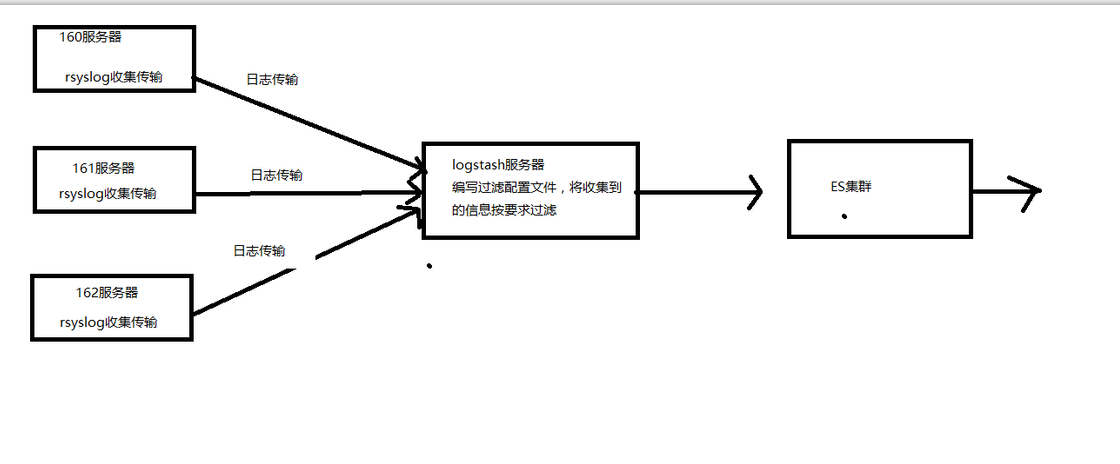
我们选择将Linux自带的rsyslog日志收集系统充当logstash Agent,解决我们日志收集的问题。这样我们将分散每台服务器上面的日志通过rsyslog日志收集到并传输到Logstash服务器上面的某个文件中,然后我们在通过logstash过滤后送到es集群中,在这个架构中,如果日志系统比较大的情况下,我们还可以将logstash做成集群。这样就可以承担更大的日志量了。
这种架构在日志量不是很大的中小型项目中足够使用,这样我们是在一定程度上解决了日志量过大的问题,但是我们并没有解决logstash过滤文件编写的问题,也就说logstash比较难于定义,这是因为logstash是ruby语言编写的,这对于我们java程序员来说不容易。所以我们也没有采用。
对于比较热衷于logstash的 用户,并且数据量比较大的情况下,采用第三种架构
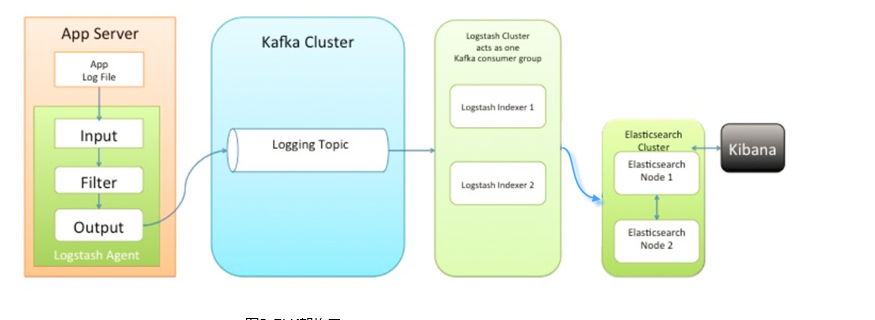
这种架构小编没有搭建,以为我们决定采用EFK架构了,所以对于这种架构,小编知识从理论方面进行了分析,基于上面两种架构的弊端,在架构三中我们引入了kafka消息中间件类似消息队列的功能。并且kafka的集群搭建也是非常容易的,这样如果日志产生量非常大的情况下,我们可以将过剩的日志缓存在kafka集群中,慢慢的提供给logstash集群中进行过滤、传输到ES集群中。这种架构均衡了网络传输、从而降低了网络闭塞尤其是丢失数据的可能性。但是也没有解决logstash占用资源的问题。
通过分析对比我们最终选择flume来代替logstash进行数据的收集和传输。在下面的博客中将分享flume+kafka+ES
框架的学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号