Object Orientated Programming: Summary of Unit 1
Program Structure
UML Graph
-
Homework 1:
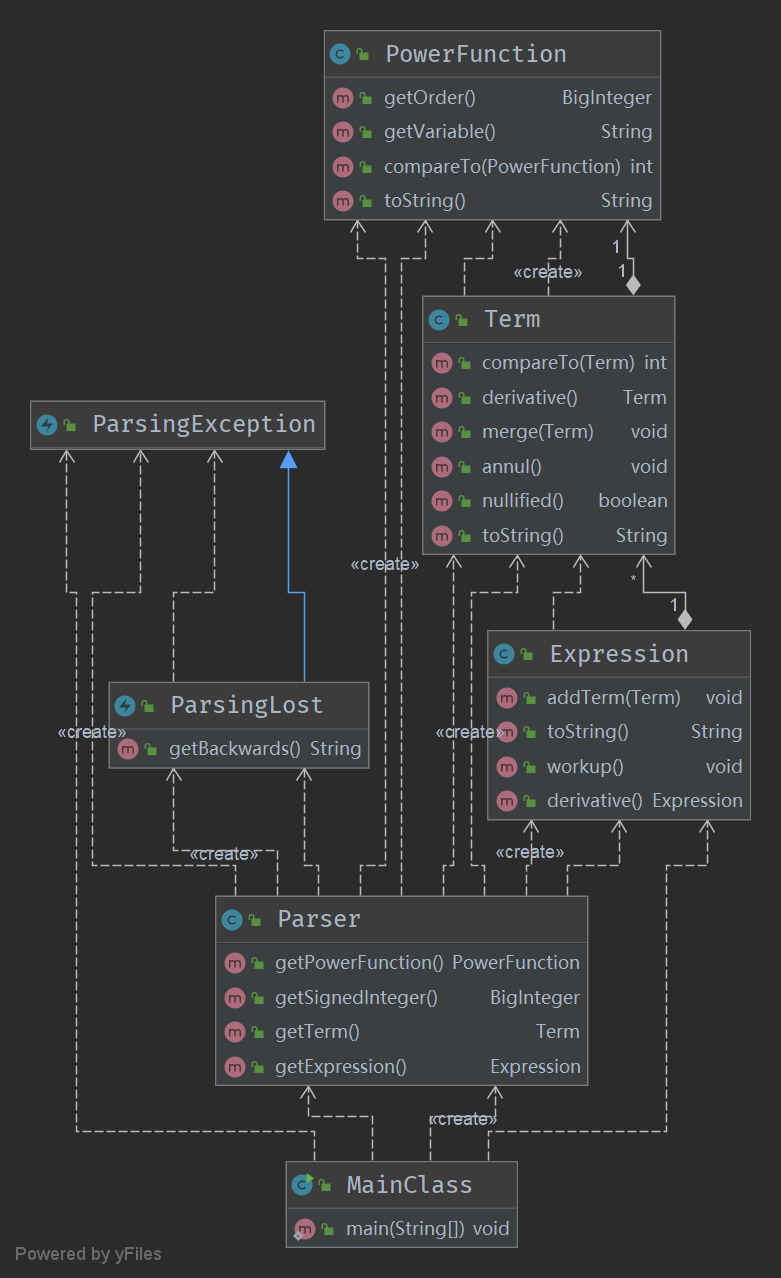
-
Homework 2:
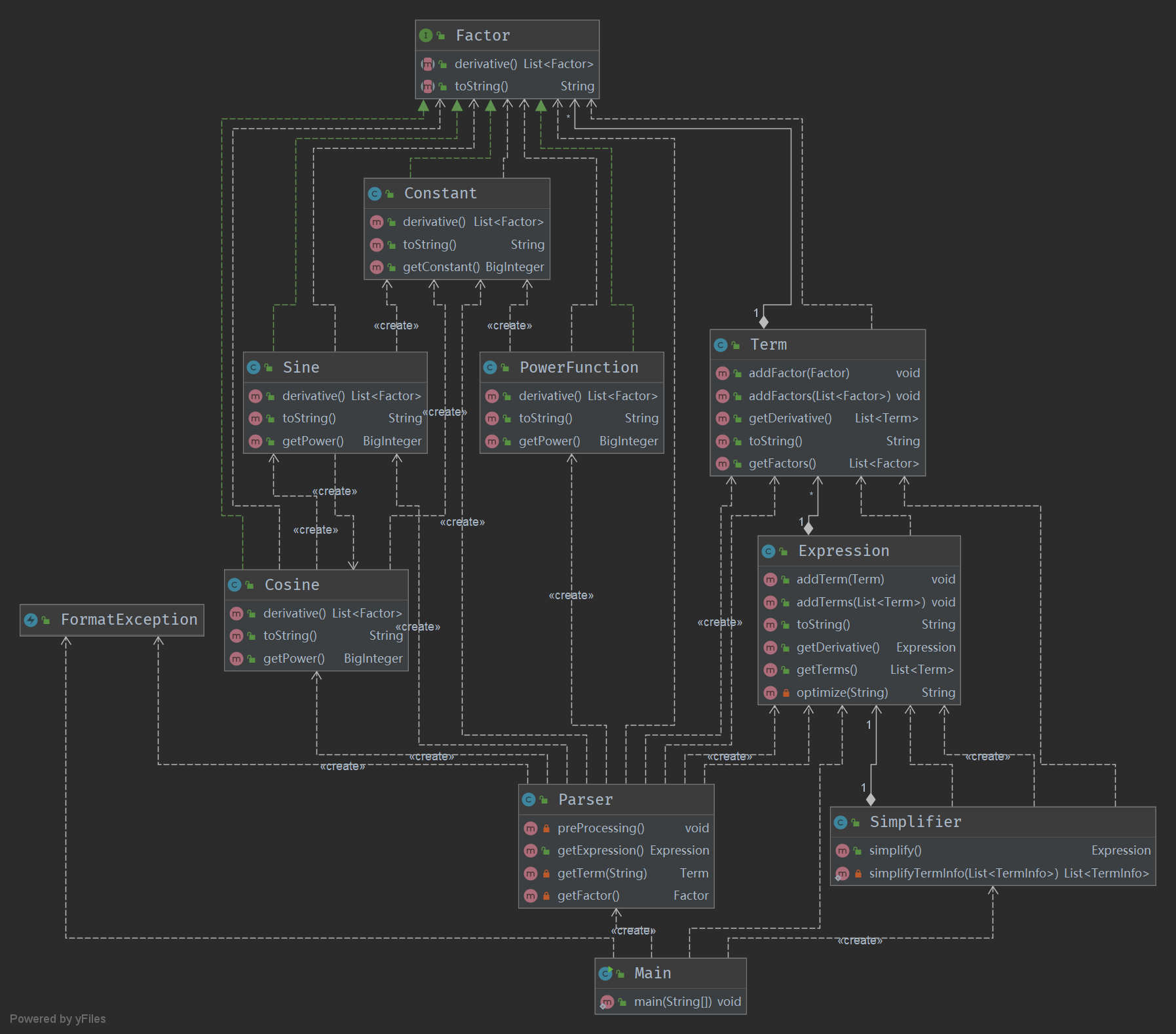
-
Homework 3:
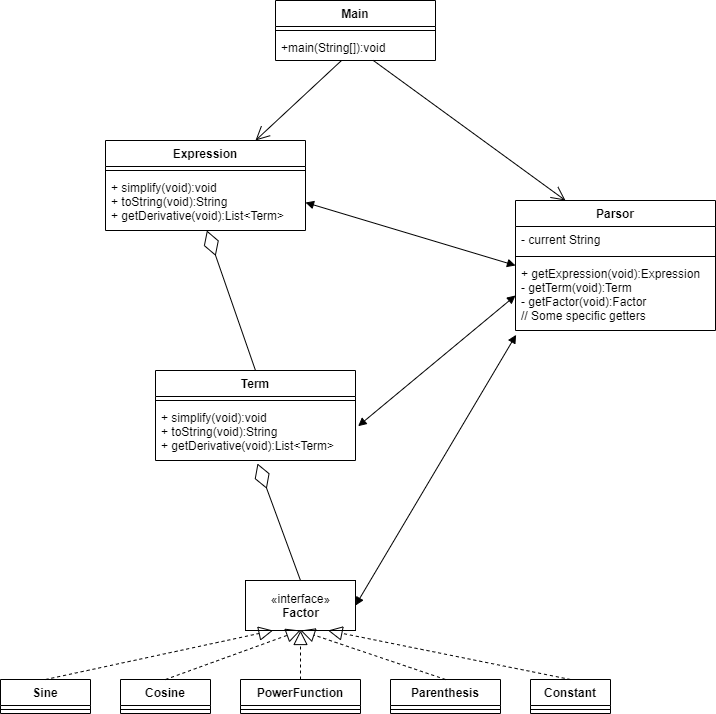
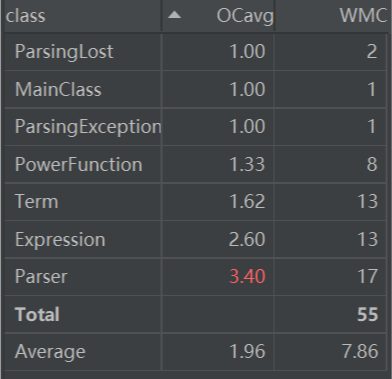
Metrics
-
Homework 1:
Counter:


Complexity:
-
Homework 2:
Counter:
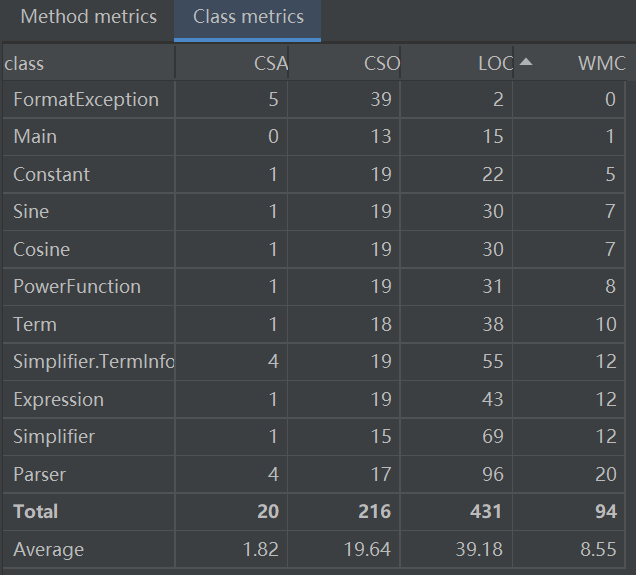
Complexity & Dependencies:


-
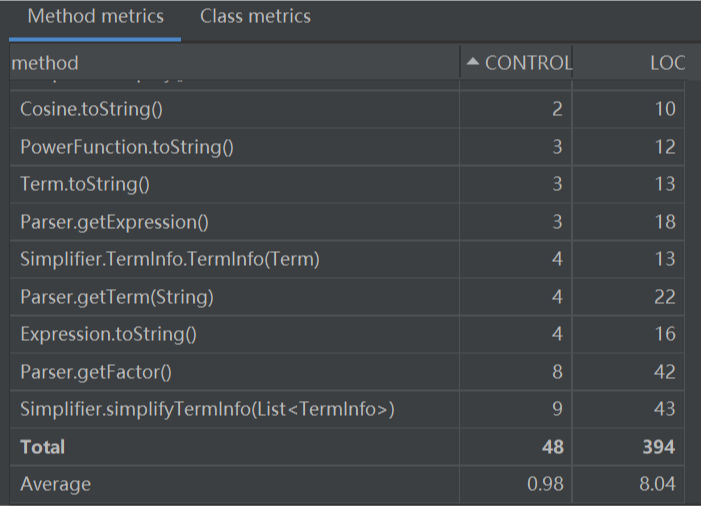
Homework 3:
Counter:


Complexity & Dependencies:
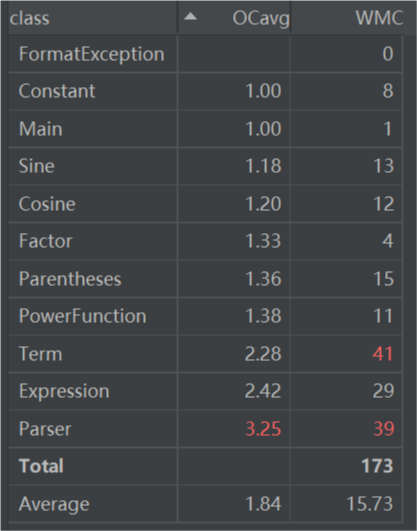


Analysis
从结构来看,这三次作业有许多不变的特征。尽管第一次作业到第二次作业经历了一次重构,但这些结构特征并没有发生显著的变化。这些结构特征包括:
- 表达式整体的SOP(Sum of Product)结构:一个表达式(expression)总是由若干项(term)相加而成;一个项总是由若干因子(factor)相乘得到。即使第三次作业出现了嵌套结构,这种层次结构并没有显著变化。在OOP中,我们用part-of关系来表达这种层次结构。
- 程序运行的基本步骤:面对一个字符串输入,我们总是先对它进行解析(parse),再求导,最后输出。在这三个步骤之间,我们按照需要可以对表达式进行化简。
另一方面,这三次作业又包括一些易变的特征,包括:
- 字符串解析的具体要求:包括是否需要判断数据合法性、数据合法性的约定。
- 具体因子的变化:如三角函数、括号表达式的加入。
- 具体因子的扩展所引发的化简过程的变化:前两次作业均可采用元组(tuple)化简,第三次作业化简相对复杂,难以用元组实现。
- 具体因子的扩展所引发的输出的变化:这一部分包含诸多细节,如作为项的组成部分和三角函数的组成部分的因子,在输出时可能会采取不同方案。
因此我们希望将这些易变特征与不变的特征分离开来,实现解耦(decouple),也便于后续作业的修改。在具体构造中,求导过程内嵌于SOP结构中,因为这一结构主要是为了求导而设计的。解析过程完全独立了出来。化简过程只有第二次作业完全独立出来,采用化简器和内部类的方式解决。其他两次作业都没有将化简过程独立出来,第一次主要是考虑到化简过程较为简洁,第三次主要考虑到之后没有重构压力。输出的过程也完全内嵌到SOP结构中,通过层级之间的调用解决。
问题1:在OOP中,程序运行的几个步骤需不需要从主体中独立出来呢?换句话说,解析、化简、求导、输出这些步骤是否应该从由表达式、项、因子构成的层级结构中独立出来呢?如果独立出来,服务于同一个过程的函数在空间上得以聚集,但是这些服务于某一个过程的类必然会与表达式、项、因子形成较强的耦合(如这三次作业中的Parser类)。如果将这些服务于某一个过程的函数内嵌在数据结构中,可以减少一些耦合,但是又会带来新的问题,如在化简过程中,项这个类的化简过程需要对各个因子有一定的了解,这可能会打破Factor接口的归一化,违背OOP的原则;又如在输出的过程中,一个因子的输出形式不仅取决于自身的性质,还取决于同一个项中其他因子的形式(比如常数的省略),同一层次各类的合作也会形成较强的耦合。
Bug Analysis
本部分主要讨论程序首次运行成功后出现的bug以及互测中遇到的bug,具体会选取一些有意义的错误进行讨论,主要针对第三次作业(前两次bug并不常见)。
- 程序需求理解偏差所导致的bug,不讨论。
- 函数传参、返回值约定偏差所导致的bug:在第三次作业中,括号因子不能写成幂次形式,而幂函数、三角函数可以,为了进行归一化调用,这些因子都有负责合并两个因子的方法,但是括号因子合并结果总是
null,以防止合并,但是在Term类调用归一化方法后,没有对返回值进行检查,出现了NullPointerException的错误。 - 对化简规模预判有误导致的bug:虽然输入保证了60字符的限制,但是求导之后可能会远超这一规模,达到500字符左右,如果采用有缺陷的化简模型,可能会出现严重的问题。
- 循环调用相关的bug:循环调用不一定会出现问题,但是没有终止节点的循环调用一定会出现问题。如第三次作业中,括号表达式在创建时进行化简(即调用
Expression类的simplify方法),看似没有问题,但是表达式的化简部分在合并同类项的时候会调用括号表达式的构造方法,形成没有终止的循环调用,便会出现问题。
以下逐个讨论这些问题:对于第二个问题,可以通过Java的一些技术手段解决,比如注释、注解(annotation)、断言、try...catch机制等,也可以采用条件语句直接在调用双方进行判断。第三个问题主要是一个算法问题,可做两方面考虑:限制准入,即表达式复杂度超过一定程度后不做化简;基于运行时间的熔断机制,运行超过一定时限后直接退出。第四个问题主要是结构问题,问题结构将构造和化简两个过程耦合在一起,导致循环调用。
Testing
这三次测试主要采用枚举测试数据、批量验证测试的方法。枚举测试数据,主要通过手动枚举,考虑不同的情况并选取有代表性的情况,主要是边界数据。在自测的过程中会考虑一些自己代码实现中的可能的弱点,在互测中,考虑到时间成本,并没有针对他人代码构造特殊的测试用例。批量验证测试,主要通过模拟测评机的测试流程和测试规则来进行测试。以下是测试方法的讨论:
- 完全随机的大量测试是效率低下的,这一点已经得到广泛的认同。测试数据的价值在于其代表性。
- 面向设计要求遍历各种可能的基本情况,每一种基本情况中随机选出若干数据进行测试。这种策略有时是有效的,它可以看作对随机数据的一种抽象。同时设计要求的复杂性也在一定程度上反应了代码的复杂性:在设计要求中较为复杂的模块在代码实现时往往也较为复杂。但是问题在于如何确定一个数据点的代表性,即这种抽象的合理性。此外,当设计要求较为复杂时,如何确定抽象的层次,即如何划分基本情况,也是一个问题。
- 面向程序代码进行测试,即根据代码的结构和内容,判断可能出现错误的位置,有针对性的进行测试。这种测试方式在准确性方面相比于随机性的测试有了很大的提升,但代价是成本较为高昂:测试者需要对代码本身较为熟悉,同时如果每个人设计结构差异较大,测试数据也不易推广。比如本次作业中,一份进行了化简的代码和没有进行化简的代码的测试数据,其偏重一般会有所不同。
- 进行单元测试,化整为零地测试,这也是一种常见的方案。这是一种比较好的思路,因为一个较小的模块所遇到的情况往往比整个程序遇到的情况更加简洁。
问题2:单元测试是一种测试的思路,但也有一些需要解决的问题,比如:如何划分一个单元?如果单元适合以功能划分,那么怎么决定单元的大小?在设计程序结构时,是否应该考虑到单元测试?如果需要考虑,会不会与其他的功能需求产生冲突?此外,单元测试暗含了这样一个假设,如果每一个单元的行为是正确的,它们组合起来很有可能也是正确的。这种假设是合理的吗?或者从另一个角度说,什么样的程序能够使这种假设更加合理?
问题3:在自测中,面向被测代码的测试往往针对性强,但容易产生偏见:自己在编写代码时没有考虑到的边界条件往往在自己构造数据时也不会考虑到。面向设计需求的测试不容易产生偏见,但缺点在于难以划分基本情况:基本情况过多,难以列举;基本情况过少,容易遗漏;划分基本情况的依据也是一个问题。另外,难以说明一个数据点的代表性。在实际应用中,如何实现两者的trade off?
Factory Pattern
这三次作业在设计和构造中也参考了工厂模式的一些思想和方法:这三次作业均采用Parser类解析字符串,并返回Expression类,将各种表达式组件的构造尽可能地封装在Parser内部。在解析的过程中并没有采用更复杂的工厂模式,即为每一个组件设立工厂类,这主要考虑了以下几点:一是更多的类会增加类之间的耦合,同时互相调用还需要不断传递字符串,二是如果为每一个类建立一个工厂,每一个具体的工厂对应的方法很少(一般只有一个)单独建一个类没什么意义。因此这三次作业均采用一个读入处理类,在这一个类中共享字符串信息,用不同的方法实现表达式的分层构建。具体如下:
def getExpression(self):
getExpressionHead() # read +-
expression.addTerm(getTerm())
while has_next_pm: # pm: plus(+) and minus(-)
getInteval() # read +- between two terms
expression.addTerm(getTerm())
def getTerm(self):
term.add(getFactor())
while has_next_factor:# judging from the existence of *
term.add(getFactor())
def getFactor(self):
if string.startswith('s'):
return getSine()
#...
def getSine(self):
pass
# ...
Others
关于重构:本人在第一单元中进行了一次重构,是作业一到作业二时进行的一次重构。并不是说作业一没有考虑到作业二的需求,而是考虑到在作业一的基础上扩展写作业二之后的程序的可扩展性可能会降低,可能导致作业三需要重构。这次重构主要是把Expression-Term-Factor结构表达的更完善,并增加了Factor的接口,明确地将优化部分独立出来成为一个可插拔的结构。仅对于作业二而言,重构意义不大,但对于作业三而言有较大的帮助。
关于设计与构造:在写代码之前,提前的规划往往是有必要的,提前规划、论证合理性可以有效避免之后出现的问题,尽早放弃不合理的结构。以下讨论规划相关的一些问题:
- 规划应该多详细?粗略的规划可以节省规划时间,也便于论证,但是在实现的过程中可能会遇到许多技术上的细节需要修改规划;过于细致的规划又无法达到规划本身的目的(无异于直接写代码)。具体而言,在写代码之前应该规划到类的功能这个层次还是每个类的方法的功能层次?
- 就本次作业而言,读入解析、化简、求导、输出这些步骤分别对Expression-Term-Factor结构提出了不同的要求,这些要求可能是冲突的(比如化简这一步骤希望每一个项里的各因子按照不同的类别存放,以便于调用Factor的方法合并;而求导这一过程希望所有因子存放在一起,以便于直接求导),在设计这些类的时候,如何平衡不同步骤所提出的要求?本人在实现的时候,遇到不可调和的矛盾时,只能建立新的数据结构,把原来的数据结构转化成新的形式。是否有更简洁的做法?
关于写代码:写代码的顺序也是一个问题。因为即使规划做的很好,在具体写代码时也会发现各种规划不周的情况,写代码的顺序不好,可能会需要前前后后反复修改。
问题4:写代码的时候应该采用什么样的顺序呢?如果用类来管理数据和行为,而写代码的时候却按照读入、求导、化简、输出的顺序先给每一个类编写读入方法,再给每一个类编写求导方法,再编写化简、输出方法,这是否符合OOP的基本思想呢?写代码的顺序(也可以包含规划的顺序)反映了思维的顺序,那么我们应该用什么样的思维顺序来构造程序呢?
关于算法:算法主要出现在化简部分。第一次是容易找到最优解的;第二次的最优化比较困难;第三次最优化就更困难了。以下简要讨论优化的策略,也包括设想的、未实现的策略:
- 尽可能合并同类项。这应该是最容易想到的。
- 模式嵌套。尽可能寻找可供化简的模式,如 \(\sin^2x+\cos^2x\) 等,再尝试对两项使用这一公式。
- 贪心策略。每次合并两项,如果长度减小了,保留合并结果。
- 在上面的方法的基础上增加动量(momentum)机制,防止陷入局部最优解。
- 随机化简结合多次尝试,在多个结果中找最优的解。
- 在展开与合并中找到一个平衡。
其实最重要的可能还是构造代码时为优化留出空间,毕竟具体算法也已经超出了OOP课程的研究范围了。
借鉴他人代码:好好分包,package管理好;类之间层次划分可以更加细致,提高复用度;好好利用断言;不要怕代码行数多……
最后再写一些感想吧,一个单元下来,还是有许多疑惑,系统能力是什么?计算机科学到底要干什么?OOP的基本思想怎么指导我们写代码?怎么写大规模(可能对我而言超过200行就算“大规模”了吧[捂脸]……)的代码?(什么时候才能像hdl一样厉害?怎么才能不失学?[手动捂脸])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号