Spark内存使用分析及优化【SparkCore、Spark SQL】
一.内存检测
1.JVM自带众多内存诊断的工具,例如:JMap,JConsole等,以及第三方IBM JVM Profile Tools等。
2.在开发、测试、生产环境中最合适的就是日志,特别是Driver产生的日志!调用RDD.cache(),当进行cache()操作时,Driver上的BlockManagerMaster会记录该信息并写进日志中!
二.内存分配及管理过程
Spark执行应用程序时,Spark集群会启动Driver和Executor两种JVM进程,Driver负责创建SparkContext上下文,提交任务,task的分发等。Executor负责task的计算任务,并将结果返回给Driver。同时需要为需要持久化的RDD提供存储。Driver端的内存管理比较简单,这里所说的Spark内存管理针对Executor端的内存管理。Spark内存管理分为静态内存管理和统一内存管理,Spark1.6之前使用的是静态内存管理,Spark1.6之后引入了统一内存管理。1.6及以上版本默认使用统一内存管理。可以通过参数spark.memory.useLegacyMode设置为true使用静态内存管理【默认为false】。
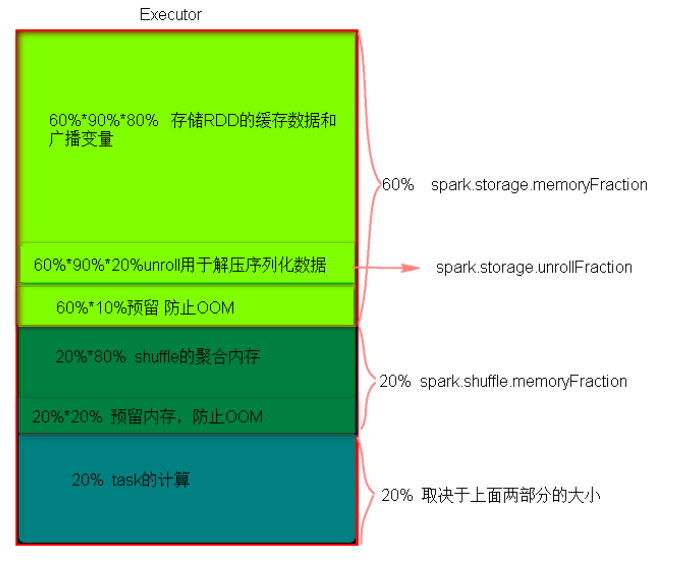
1.静态内存管理中存储内存、执行内存和其它内存的大小在Spark应用程序运行期间均为固定的,但用户可以在应用程序启动之前进行配置。
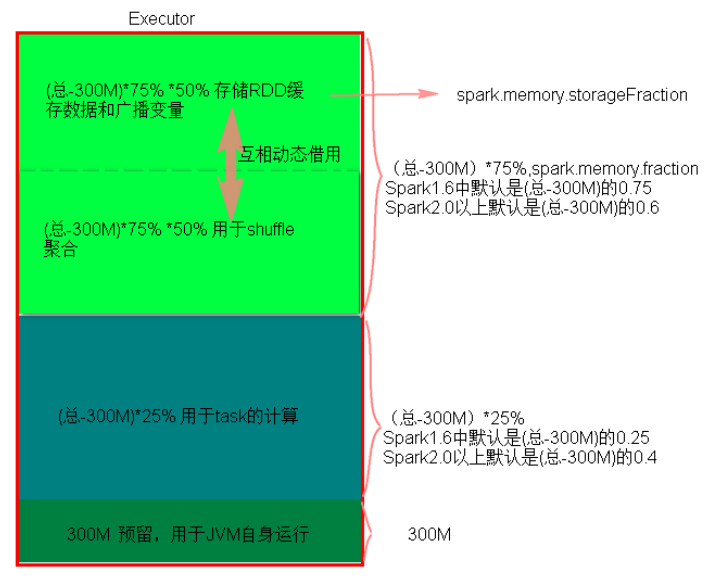
2.统一内存管理与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以互相借用对方的内存空间。
3.静态内存管理分布图
4.通一内存管理分布图
三.Reduce端OOM处理
1.减少每次拉取的数据量
2.提高shuffle聚合的内存比例
3.提高Executor的总内存
四.持久化
持久化级别类:
1 class StorageLevel private (private val _useDisk : scala.Boolean, private val _useMemory : scala.Boolean, private val _useOffHeap : scala.Boolean, private val _deserialized : scala.Boolean, private val _replication : scala.Int = {}) extends java.lang.Object with java.io.Externalizable{ 2 def this(){} 3 def useDisk : scala.Boolean = {} 4 def useMemory : scala.Boolean = {} 5 def useOffHeap : scala.Boolean = {} 6 def deserialized : scala.Boolean = {} 7 def replication : scala.Int = {} 8 override def clone() : org.apache.spark.storage.StorageLevel = {} 9 override def equals(other : scala.Any) : scala.Boolean = {} 10 def isValid : scala.Boolean = {} 11 def toInt : scala.Int = {} 12 override def writeExternal(out : java.io.ObjectOutput) : scala.Unit = {} 13 override def readExternal(in : java.io.ObjectInput) : scala.Unit = {} 14 override def toString() : scala.Predef.String = {} 15 override def hashCode() : scala.Int = {} 16 def description : scala.Predef.String = {} 17 }
伴生对象:
1 object StorageLevel extends scala.AnyRef with scala.Serializable{ 2 val NONE : org.apache.spark.storage.StorageLevel = {} 3 val DISK_ONLY : org.apache.spark.storage.StorageLevel = {} 4 val DISK_ONLY_2 : org.apache.spark.storage.StorageLevel = {} 5 val MEMORY_ONLY : org.apache.spark.storage.StorageLevel = {} 6 val MEMORY_ONLY_2 : org.apache.spark.storage.StorageLevel = {} 7 val MEMORY_ONLY_SER : org.apache.spark.storage.StorageLevel = {} 8 val MEMORY_ONLY_SER_2 : org.apache.spark.storage.StorageLevel = {} 9 val MEMORY_AND_DISK : org.apache.spark.storage.StorageLevel = {} 10 val MEMORY_AND_DISK_2 : org.apache.spark.storage.StorageLevel = {} 11 val MEMORY_AND_DISK_SER_2 : org.apache.spark.storage.StorageLevel = {} 12 val OFF_HEAP : org.apache.spark.storage.StorageLevel = {} 13 def fromString(s : scala.Predef.String) : org.apache.spark.storage.StorageLevel = {} 14 def apply(useDisk : scala.Boolean, userMemory : scala.Boolean, useOffHeap : scala.Boolean, deserialized : scala.Boolean, replication : scala.Int) : org.apache.spark.storage.StorageLevel = {} 15 def apply(useDisk : scala.Boolean, userMemory : scala.Boolean, deserialized : scala.Boolean, replication : scala.Int) : org.apache.spark.storage.StorageLevel = {} 16 def apply(flage : scala.Int, replication : scala.Int) : org.apache.spark.stoarge.StorageLevel = {} 17 def apply(in : java.io.ObjectInput) : org.apache.spark.storage.StorageLevel = {} 18 private[spark] val storageLevelCache : java.util.concurrent.ConcurrentHashMap[org.apache.spark.storage.StorageLevel, org.apache.spark.storage.StorageLevel] = {} 19 private[spark] def getCachedStorageLevel(level : org.apache.spark.storage.StorageLevel) : org.apache.spark.storage.StorageLevel = {} 20 }
备注:
MEMORY_ONLY:默认的持久化级别,只以原始对象的形式保存到内存中,需要时直接访问,不需要反序列化操作。内存不足时,多余的部分不会被持久化,访问时需要重新计算。
MEMORY_AND_DISK:持久化到内存中,内存不足时多余的部分保存到磁盘中。
MEMORY_ONLY_SER:类似MEMORY_ONLY,但会先序列化【每个分区一个字节数组】后再持久化到内存中,优点是节省内存,缺点是消耗CPU反序列化。
MEMORY_AND_DISK_SER:类似于MEMORY_ONLY_SER,但在内存不足时会保存到磁盘中。
DISK_ONLY:只使用磁盘。
OFF_HEAP:使用Tachyon内存文件系统。
*_2:2备份,提升可用性。
注意:rdd.unpersist()方法可以删除持久化。
五.Spark SQL内存优化
Spark SQL可以通过调用spark.catalog.cacheTable("tableName")或者使用内存列式格式缓存表dataFrame.cache()。然后,Spark SQL将仅扫描必需的列,并将自动调整压缩以最小化内存使用和GC压力。在使用完成后,可以使用spark.catalog.uncacheTable("tableName")【spark2.x,spark1.x使用sqlContext.uncacheTable("tableName")或hiveContext.uncacheTable("tableName")】从内存中删除表。
可以使用setConf在sparkSession上设置或者在运行时使用SET key=value来完成内存中缓存的设置。
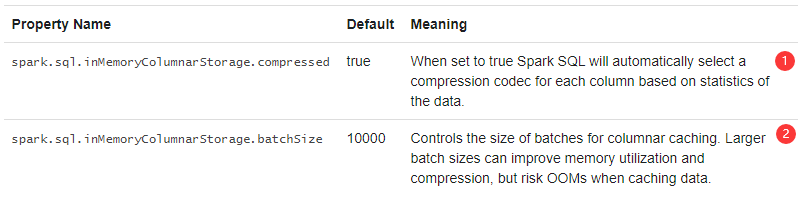
1.设置为true时,Spark SQL将根据数据统计信息自动为每一列选择一个压缩编码解释器。
2.控制用于列式缓存的批处理大小。较大的批处理大小可以提高内存利用率和压缩率,但可能在缓存数据时出现OOM。
其它配置选项
以下选项也可以用于调整查询执行的性能,随着自动执行更多优化,这些选项可能会在将来的版本中弃用。

SQL查询的广播提示
当一个表或视图与另一个表或者视图进行关联时broadcast会提示spark进行导向。当spark确定连接方式时,即使统计数据高于配置,还是首选广播哈希连接【即BHJ】spark.sql.autoBroadcastJoinThreshold。当指定了连接的两端时,spark广播统计信息较少的一方。注意,spark不能保证始终选择BHJ,因为并非所有情况【例如全外连接】都支持BHJ。当选择广播嵌套循环链接时,仍然遵守提示。
import org.apache.spark.sql.functions.broadcast broadcast(spark.table("tableName").join(spark.table("anotherTableName"), "key"))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号