强化学习代码实战
一.概述
强化学习是根据奖励信号以改进策略的机器学习方法。策略和奖励是强化学习的核心元素。强化学习试图找到最大化总奖励的策略。强化学习不是监督学习,因为强化学习的学习过程中没有参考答案;强化学习也不是非监督学习,因为强化学习需要利用奖励信号来学习。
强化学习任务常用“智能体/环境”接口建模。学习和决策的部分称为智能体,其它部分称为环境。智能体向环境执行动作,并从环境中得到奖励和反馈。
Python扩展库Gym是OpenAI推出的免费的强化学习试验环境。Gym库的使用方法是:用env=gym.make(环境名)取出环境,用env.reset()初始化环境,用env.step(动作)执行一步环境,用env.render()显示环境,用env.close()关闭环境。

大狗机器人的姿态自适应就是基于深度学习算法,根据环境反馈进行自动姿态调整,以保障能稳定站立并行走。
二.安装
使用Anaconda的小伙伴在联网的情况下可以直接在Anaconda Prompt上执行pip install gym即可安装Gym库。
其它安装的细节可以参考官网:http://gym.openai.com/docs/#getting-started-with-gym
三.案例【基本信息输出】
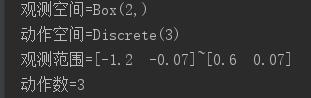
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Mon Nov 4 20:05:03 2019 4 5 @author: Administrator 6 """ 7 8 import gym 9 10 env = gym.make('MountainCar-v0') 11 print('观测空间={}'.format(env.observation_space)) 12 print('动作空间={}'.format(env.action_space)) 13 print('观测范围={}~{}'.format(env.observation_space.low, env.observation_space.high)) 14 print('动作数={}'.format(env.action_space.n))
四.执行结果
五.案例【小车自适应翻越小沟】
1 # -*- coding: utf-8 -*- 2 import gym 3 import time 4 5 ''' 6 基于强化学习实现小车自适应翻越小沟 7 ''' 8 class BespokeAgent: 9 def __init__(self, env): 10 pass 11 12 def decide(self, observation): 13 position, velocity = observation 14 lb = min(-0.09 * (position + 0.25) ** 2 + 0.03, 0.3 * (position + 0.9) ** 4 - 0.008) 15 ub = -0.07 * (position + 0.38) ** 2 + 0.06 16 if lb < velocity < ub: 17 action = 2 18 else: 19 action = 0 20 return action # 返回动作 21 22 def learn(self, *args): # 学习 23 pass 24 25 def play_ones(self, env, agent, render=False, train=False): 26 episode_reward = 0 # 记录回合总奖励,初始值为0 27 observation = env.reset() # 重置游戏环境,开始新回合 28 while True: # 不断循环,直到回合结束 29 if render: # 判断是否显示 30 env.render() # 显示图形界面,可以用env.close()关闭 31 action = agent.decide(observation) 32 next_observation, reward, done, _ = env.step(action) # 执行动作 33 episode_reward += reward # 搜集回合奖励 34 if train: # 判断是否训练智能体 35 break 36 observation = next_observation 37 return episode_reward # 返回回合总奖励 38 39 if __name__ == '__main__': 40 env = gym.make('MountainCar-v0') 41 env.seed(0) # 设置随机数种子,只是为了让结果可以精确复现,一般情况下可以删除 42 43 agent = BespokeAgent(env) 44 for _ in range(100): 45 episode_reward = agent.play_ones(env, agent, render=True) 46 print('回合奖励={}'.format(episode_reward)) 47 48 time.sleep(10) # 停顿10s 49 env.close() # 关闭图形化界面
这是经典的“代理程序-环境循环”的实现。每个时间步,代理都选择一个action,并且环境返回一个observation和一个reward。

六.执行结果

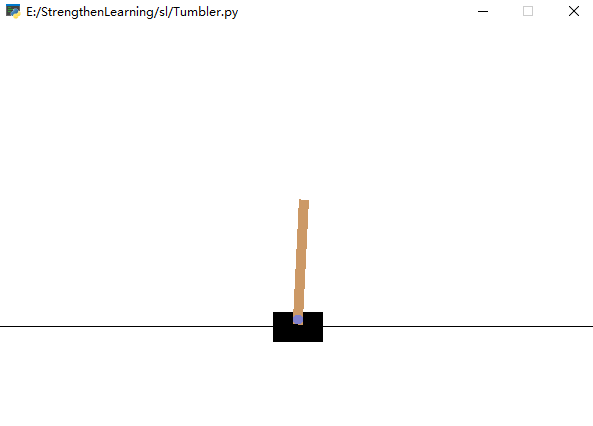
七.案例【不倒翁】
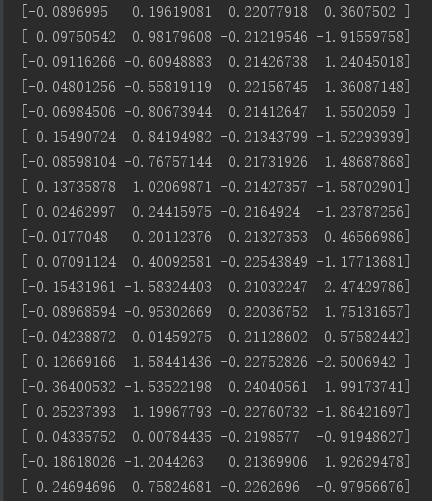
1 import gym 2 import time 3 4 ''' 5 基于强化学习实现不倒翁特性:自动平衡恢复 6 ''' 7 if __name__ == "__main__": 8 env = gym.make('CartPole-v0') 9 for i_episode in range(20): 10 observation = env.reset() 11 for t in range(100): 12 env.render() 13 # print(observation) 14 action = env.action_space.sample() 15 observation, reward, done, info = env.step(action) 16 if done: 17 # print("Episode finished after {} timesteps".format(t + 1)) 18 print(observation) 19 time.sleep(1) # 暂停以下,便于观察 20 break 21 22 time.sleep(10) # 停顿10s 23 env.close() # 关闭图形化界面
如果我们想做的比在每个步骤中都采取随机action更好的话,那么最好是真正了解我们的action对环境影响。环境的step功能恰好返回了我们需要的。实际上,step返回四个值,包括:
>observation【对象】:特定于环境的对象,代表对环境的一次观察。例如,机器人的关节角度或者棋盘的状态。
>reward【奖励】:上一个动作获得的奖励。规模因环境而异,但目标始终是增加总奖励。
>done【执行状态】:是否需要重新再次进入环境。当done等于True时表示停止。
>info【结果】:对调试有用的诊断信息。
八.执行结果
图示:
九.可用环境
Gym拥有各种环境,从 简单到复杂,涉及许多不同种类的数据。包括:
>经典控制和玩具文字:完成小规模的任务,大部分来自RL文献。用于入门。
>算法化:执行计算,例如添加多位数和反转顺序。
>Atari:经典的Atari游戏。使用易于安装的Arcade学习环境。
>2D和3D机器人:在仿真中控制机器人。这些任务使用了MuJoCo物理引擎,该引擎设计用于快速而准确的机器人仿真。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号