

一、快速理解GNN
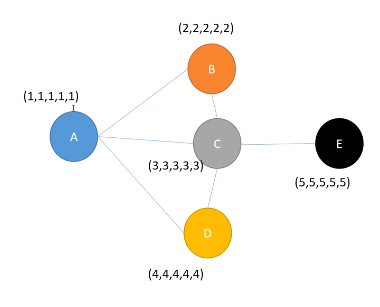
{1,1,1,1,1}代表特征
GNN有三种操作:
1 聚合:BCD的特征可以在一定程度上决定A的类别。经过一次聚合后,邻居信息N=b*{2,2,2,2,2}+c*{3,3,3,3,3}+d*{4,4,4,4,4},bcd是训练出的或者手动设置的(常作为文章的改进点,比如B很重要就设置的高一点)
2 更新:A的信息=σ(W*{1,1,1,1,1}+α*N),就是一次GNN操作得到的A的信息。
3 循环:多层:第二次聚合时,C中包含了E的信息,所以更新A时也会包含到E的信息。
得到结点特征后,可以做结点分类,直接拿去分类,算loss,优化W和其他权重
还可以做关联预测,两个节点的特征一拼,拿去做分类,一样算loss,优化。
归根结底,GNN就是个提取结点特征的方法,可以得到graph的结构信息。输入A的特征和graph的结构,得到A的最终特征。
二、快速理解GCN
GCN就是用来解决bcd值如何设定的问题。
平均法:
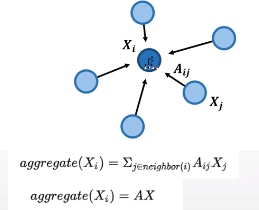 邻居的特征加起来权重平均,但是忽略了自身的特征
邻居的特征加起来权重平均,但是忽略了自身的特征
一般会添加一个自环把结点自身特征加回来。
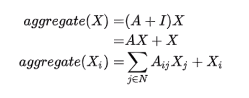
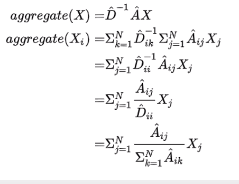
但是平均法存在问题,A只有B一个邻居
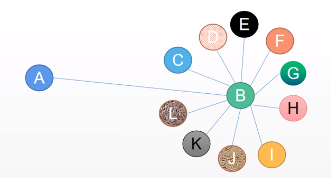
代进公式计算A特征时,B的所有特征聚合过来都会加到A上,GCN就用来解决这个问题。
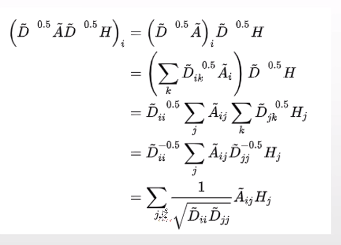
D为度矩阵

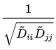 通过这个操作,使得如果Djj很大,开根号再取倒数,整个值就很小了。
通过这个操作,使得如果Djj很大,开根号再取倒数,整个值就很小了。
这个式子称为对称规划拉普拉斯矩阵
GCN就是在平均法的基础上,对每个结点的度做了一个对称归一化。
三、R-GCN
Modeling Relational Data with Graph Convolutional Networks

这样学出来的A和B也会很像。
relational-GCN
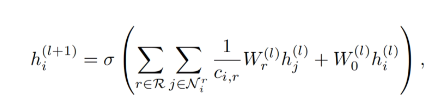
Nri表示i结点在r关系下的邻居j,c是人为设定或通过邻居节点数来算的常数,W0hi是节点自己在上一层的特征,W是权重。
不同关系的是分开算的,不同的关联会聚合不同的信息,有不同的W。
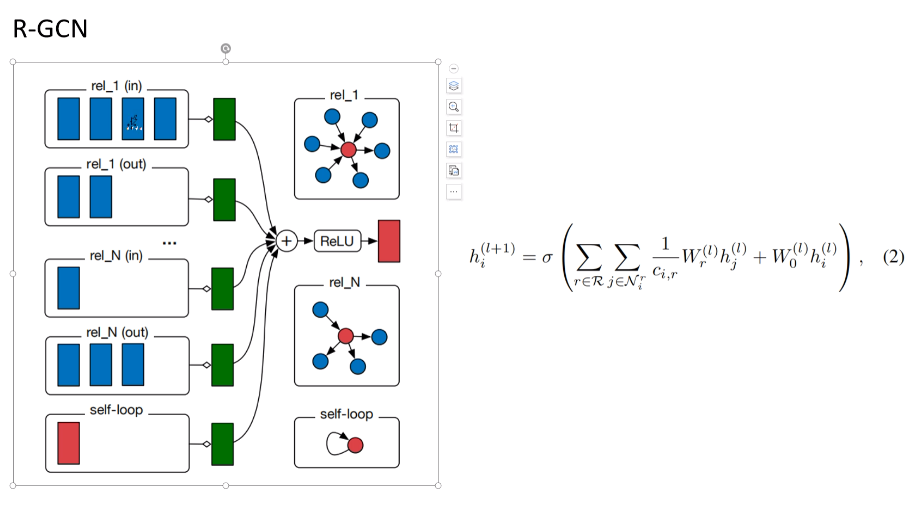
无向图变成有向图,把in和out看成不同的关系。
GCN和R-GCN的任务:
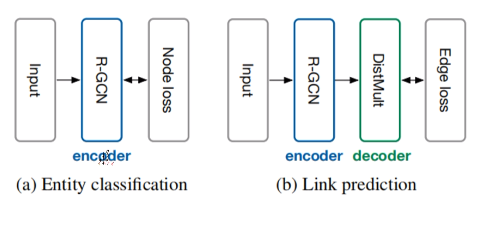
a 对未知的节点进行分类。
b 对两个未知关系的节点预测它们是什么关系。(如B和E的特征直接拼起来或向量乘(DistMult),再做分类,看有没有关系)
四、Should Graph Convolution Trust Neighbors? A Simple Causal Inference Method

 浙公网安备 33010602011771号
浙公网安备 33010602011771号