
数据采集第三次作业
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
import threading
from queue import Queue
import time
from urllib.parse import urljoin, urlparse
import re
# 基础配置
TARGET_URL = "http://www.weather.com.cn"
MAX_PAGES = 54 # 最大爬取页数
MAX_IMAGES = 154 # 最大下载图片数
IMAGE_DIR = "images" # 图片存储目录
HEADERS = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0 Safari/537.36"}
TIMEOUT = 10 # 请求超时时间
DELAY = 0.3 # 基础延迟
THREAD_NUM = 6 # 多线程数量
# 初始化图片目录
os.makedirs(IMAGE_DIR, exist_ok=True)
# 通用工具函数
def is_valid_url(url):
"""验证URL是否属于目标网站"""
parsed = urlparse(url)
return parsed.scheme in ["http", "https"] and TARGET_URL in parsed.netloc
def is_image_url(url):
"""验证是否为图片URL"""
img_exts = [".jpg", ".png", ".jpeg", ".gif", ".webp"]
return any(url.lower().endswith(ext) for ext in img_exts)
def get_soup(url):
"""获取页面解析对象"""
try:
time.sleep(DELAY / 2)
resp = requests.get(url, headers=HEADERS, timeout=TIMEOUT)
resp.encoding = resp.apparent_encoding
return BeautifulSoup(resp.text, "html.parser") if resp.status_code == 200 else None
except:
return None
def extract_resources(soup, page_set, img_set):
"""提取页面中的有效链接和图片URL"""
pages, imgs = [], []
if not soup:
return pages, imgs
# 提取页面链接
for a in soup.find_all("a", href=True):
full_url = urljoin(TARGET_URL, a["href"])
if is_valid_url(full_url) and full_url not in page_set:
pages.append(full_url)
# 提取图片URL(img标签+背景图)
for img in soup.find_all("img", src=True):
full_url = urljoin(TARGET_URL, img["src"])
if is_image_url(full_url) and full_url not in img_set:
imgs.append(full_url)
for tag in soup.find_all(style=True):
match = re.search(r'url\(["\']?(.*?)["\']?\)', tag["style"])
if match:
full_url = urljoin(TARGET_URL, match.group(1))
if is_image_url(full_url) and full_url not in img_set:
imgs.append(full_url)
return pages, imgs
def download_image(img_url, prefix):
"""下载图片并输出URL"""
try:
# 生成安全的文件名
filename = re.sub(r'[<>:"/\\|?*]', "_", os.path.basename(urlparse(img_url).path))
if not os.path.splitext(filename)[1]:
filename += ".jpg"
filepath = os.path.join(IMAGE_DIR, f"{prefix}_{filename}")
# 下载并保存
resp = requests.get(img_url, headers=HEADERS, timeout=TIMEOUT, stream=True)
if resp.status_code == 200:
with open(filepath, "wb") as f:
for chunk in resp.iter_content(1024):
if chunk:
f.write(chunk)
print(f"✅ 下载成功:{img_url}")
return True
print(f"❌ 下载失败(状态码:{resp.status_code}):{img_url}")
return False
except Exception as e:
print(f"❌ 下载异常({str(e)}):{img_url}")
return False
# ------------------------------ 单线程爬取 ------------------------------
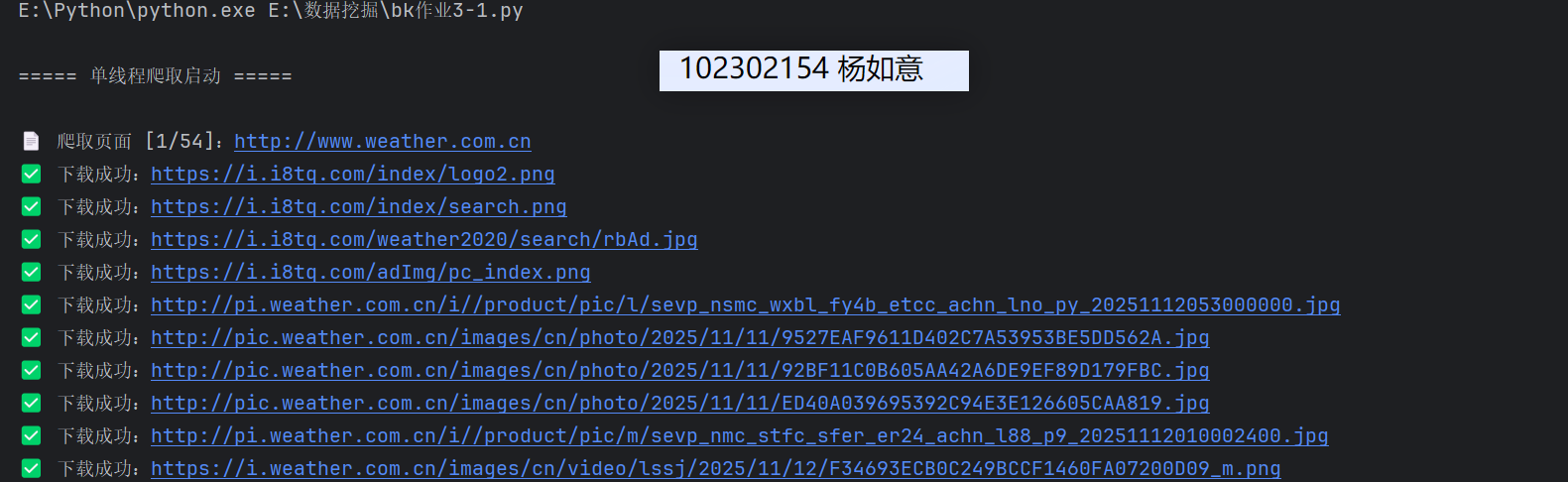
def single_thread_crawl():
print("\n===== 单线程爬取启动 =====")
start_time = time.time()
page_count, img_count = 0, 0
page_set, img_set = set(), set()
page_queue = [TARGET_URL]
page_set.add(TARGET_URL)
while page_queue and page_count < MAX_PAGES and img_count < MAX_IMAGES:
current_url = page_queue.pop(0)
page_count += 1
print(f"\n📄 爬取页面 [{page_count}/{MAX_PAGES}]:{current_url}")
soup = get_soup(current_url)
if not soup:
continue
# 提取资源
new_pages, new_imgs = extract_resources(soup, page_set, img_set)
# 添加新页面到队列
for page in new_pages:
if page_count < MAX_PAGES and page not in page_set:
page_set.add(page)
page_queue.append(page)
# 下载图片
for img_url in new_imgs:
if img_count < MAX_IMAGES and img_url not in img_set:
if download_image(img_url, "st"):
img_count += 1
img_set.add(img_url)
print(f"\n===== 单线程爬取完成 =====")
print(f"统计:爬取{page_count}页 | 下载{img_count}张图片 | 耗时{time.time() - start_time:.2f}秒")
# ------------------------------ 多线程爬取 ------------------------------
class MultiThreadCrawler:
def __init__(self):
self.page_count = 0
self.img_count = 0
self.page_set = set()
self.img_set = set()
self.page_queue = Queue()
self.img_queue = Queue()
self.lock = threading.Lock()
def page_crawler(self):
"""页面爬取线程"""
while True:
with self.lock:
if (self.page_count >= MAX_PAGES or self.img_count >= MAX_IMAGES) and self.page_queue.empty():
break
try:
current_url = self.page_queue.get(timeout=3)
with self.lock:
if self.page_count >= MAX_PAGES:
break
self.page_count += 1
print(
f"\n📄 线程{threading.current_thread().name} 爬取页面 [{self.page_count}/{MAX_PAGES}]:{current_url}")
soup = get_soup(current_url)
if not soup:
continue
# 提取资源并添加到队列
new_pages, new_imgs = extract_resources(soup, self.page_set, self.img_set)
with self.lock:
for page in new_pages:
if self.page_count < MAX_PAGES and page not in self.page_set:
self.page_set.add(page)
self.page_queue.put(page)
for img_url in new_imgs:
if self.img_count < MAX_IMAGES and img_url not in self.img_set:
self.img_set.add(img_url)
self.img_queue.put(img_url)
except:
break
def img_downloader(self):
"""图片下载线程"""
while True:
with self.lock:
if self.img_count >= MAX_IMAGES or (self.page_queue.empty() and self.img_queue.empty()):
break
try:
img_url = self.img_queue.get(timeout=3)
with self.lock:
if self.img_count >= MAX_IMAGES:
break
if download_image(img_url, "mt"):
with self.lock:
self.img_count += 1
except:
break
def run(self):
print("\n===== 多线程爬取启动 =====")
start_time = time.time()
self.page_queue.put(TARGET_URL)
self.page_set.add(TARGET_URL)
# 创建并启动线程
threads = []
# 一半线程爬取页面,一半下载图片
for i in range(THREAD_NUM // 2):
threads.append(threading.Thread(target=self.page_crawler, name=f"Page-{i + 1}"))
for i in range(THREAD_NUM - THREAD_NUM // 2):
threads.append(threading.Thread(target=self.img_downloader, name=f"Img-{i + 1}"))
for t in threads:
t.start()
for t in threads:
t.join()
print(f"\n===== 多线程爬取完成 =====")
print(f"统计:爬取{self.page_count}页 | 下载{self.img_count}张图片 | 耗时{time.time() - start_time:.2f}秒")
# ------------------------------ 主执行入口 ------------------------------
if __name__ == "__main__":
# 依赖检查
try:
import requests
from bs4 import BeautifulSoup
except ImportError:
print("请先安装依赖:pip install requests beautifulsoup4")
exit(1)
# 执行单线程爬取
single_thread_crawl()
# 执行多线程爬取
mt_crawler = MultiThreadCrawler()
mt_crawler.run()
# 最终汇总
print("\n===== 所有爬取任务完成 =====")
print(f"图片存储目录:{os.path.abspath(IMAGE_DIR)}")
心得体会
这次作业让我明白,不是多线程就一定好,得根据需求选,而且不管哪种方式,控制爬取量、做好异常处理都特别重要,不然很容易出问题。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
点击查看eastmoney代码
import scrapy
import json
import re
from ..items import StockItem
class EastmoneySpider(scrapy.Spider):
name = "eastmoney"
start_urls = [
"https://98.push2.eastmoney.com/api/qt/clist/get?cb=jQuery&pn=1&pz=20&po=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=%7C0%7C0%7C0%7Cweb&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18"
]
def parse(self, response):
try:
jsonp_data = response.text
# 1. 正则提取 JSON 字符串
match = re.search(r'jQuery.*?\((\{.*?\})\);?', jsonp_data, re.DOTALL)
if not match:
print("❌ 未匹配到 JSON 数据")
return
json_str = match.group(1)
data = json.loads(json_str)
if not isinstance(data, dict):
print(f"❌ JSON 解析后不是字典:{type(data)}")
return
# 2. 关键修正:解析 diff 字段(可能是字符串,需转 JSON)
data_dict = data.get("data", {})
diff_str = data_dict.get("diff", "") # diff 是字符串,不是列表
# 若 diff 是字符串,尝试解析为字典(接口返回的 diff 格式是 {"0": {...}, "1": {...}})
if isinstance(diff_str, str) and diff_str:
try:
diff_dict = json.loads(diff_str) # 字符串转字典
stock_list = list(diff_dict.values()) # 字典转列表(取所有股票数据)
except:
print("❌ diff 字符串解析失败")
stock_list = []
else:
# 若 diff 是列表/字典,直接处理
stock_list = list(diff_str.values()) if isinstance(diff_str, dict) else diff_str
if not stock_list:
print(f"❌ 未获取到股票数据,diff 内容:{diff_str[:200]}")
return
# 3. 遍历股票数据(正常封装)
for stock in stock_list:
item = StockItem()
item["stock_no"] = str(stock.get("f12", ""))
item["stock_name"] = stock.get("f14", "")
item["latest_price"] = stock.get("f2", 0)
item["change_rate"] = f"{stock.get('f3', 0)}%" # 补充 % 符号,格式统一
item["change_amount"] = stock.get("f4", 0)
item["volume"] = stock.get("f5", 0)
item["turnover"] = stock.get("f6", 0) # 成交额转为万元(接口返回单位是元)
item["amplitude"] = f"{stock.get('f7', 0)}%" # 补充 % 符号
item["highest_price"] = stock.get("f15", 0)
item["lowest_price"] = stock.get("f16", 0)
item["opening_price"] = stock.get("f17", 0)
item["closing_price"] = stock.get("f18", 0)
if item["stock_no"]:
print(f"✅ 爬取到股票:{item['stock_no']} {item['stock_name']} 最新价:{item['latest_price']}")
yield item
except json.JSONDecodeError as e:
print(f"❌ JSON 解析失败:{str(e)}")
except Exception as e:
print(f"❌ 解析出错:{str(e)}")
return
点击查看pipelines代码
import sqlite3
from itemadapter import ItemAdapter
import pymysql
from scrapy.utils.project import get_project_settings
import scrapy.exceptions
class StockSpiderPipeline:
def __init__(self):
# 读取 settings 中的 MySQL 配置(之前已配置 root/123456)
settings = get_project_settings()
self.host = settings["MYSQL_HOST"]
self.port = settings["MYSQL_PORT"]
self.user = settings["MYSQL_USER"]
self.password = settings["MYSQL_PASSWORD"]
self.db = settings["MYSQL_DB"]
self.connect() # 初始化时连接数据库
# 连接 MySQL 数据库
def connect(self):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.db,
charset="utf8mb4" # 支持中文
)
self.cursor = self.conn.cursor()
# 爬虫启动时创建表(如果不存在)
def open_spider(self, spider):
create_table_sql = """
CREATE TABLE IF NOT EXISTS stock_info (
id INT AUTO_INCREMENT PRIMARY KEY,
stock_no VARCHAR(20) NOT NULL COMMENT '股票代码',
stock_name VARCHAR(50) NOT NULL COMMENT '股票名称',
latest_price FLOAT COMMENT '最新价格',
change_rate VARCHAR(20) COMMENT '涨跌幅',
change_amount VARCHAR(20) COMMENT '涨跌额',
volume INT COMMENT '成交量(手)',
turnover FLOAT COMMENT '成交额(万)',
amplitude VARCHAR(20) COMMENT '振幅',
highest_price FLOAT COMMENT '最高价',
lowest_price FLOAT COMMENT '最低价',
opening_price FLOAT COMMENT '开盘价',
closing_price FLOAT COMMENT '昨收价'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
self.cursor.execute(create_table_sql)
self.conn.commit()
# 处理爬取到的 item,存入 MySQL
def process_item(self, item, spider):
insert_sql = """
INSERT INTO stock_info (
stock_no, stock_name, latest_price, change_rate, change_amount,
volume, turnover, amplitude, highest_price, lowest_price,
opening_price, closing_price
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
# 插入数据(字段顺序和上面的 SQL 对应)
self.cursor.execute(insert_sql, (
item.get("stock_no", ""),
item.get("stock_name", ""),
item.get("latest_price", 0),
item.get("change_rate", ""),
item.get("change_amount", ""),
item.get("volume", 0),
item.get("turnover", 0),
item.get("amplitude", ""),
item.get("highest_price", 0),
item.get("lowest_price", 0),
item.get("opening_price", 0),
item.get("closing_price", 0)
))
self.conn.commit() # 提交事务
return item # 必须返回 item,让后续中间件处理
# 爬虫结束时关闭数据库连接
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
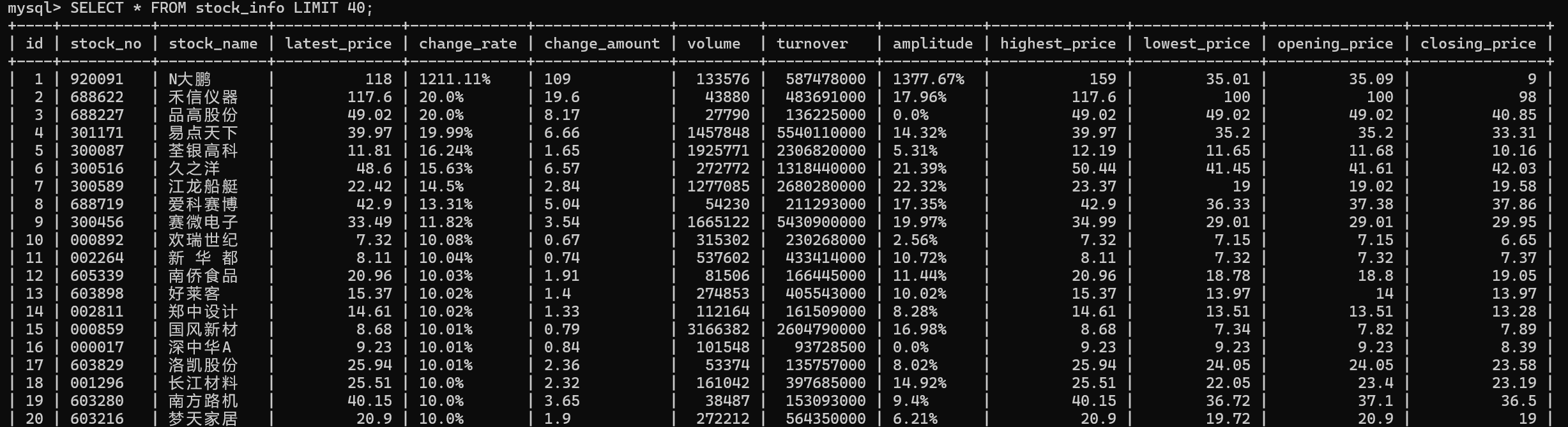
心得体会
通过这次作业,我发现 Scrapy 框架的自动化程度真高,配合 Xpath 解析和 MySQL 存储,一套流程下来特别顺畅。同时也明白,爬取动态网站要先分析接口结构,数据存储前得做好格式校验,这些细节直接影响作业能不能成。
作业③
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
点击查看items代码
import scrapy
class BocExchangeItem(scrapy.Item):
currency = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
mid_rate = scrapy.Field() # 新增中行折算价字段
time = scrapy.Field()
点击查看settings代码
OT_NAME = "boc_exchange"
SPIDER_MODULES = ["boc_exchange.spiders"]
NEWSPIDER_MODULE = "boc_exchange.spiders"
ADDONS = {}
ITEM_PIPELINES = {
"boc_exchange.pipelines.BocExchangePipeline": 300,
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "boc_exchange (+http://www.yourdomain.com)"
# Obey robots.txt rules
USER_AGENT = "Mozilla/5.0 (Windows NT 11.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
ROBOTSTXT_OBEY = False # 不遵守robots.txt
DOWNLOAD_DELAY = 2
MYSQL_HOST = "localhost"
MYSQL_PORT = 3306
MYSQL_USER = "root"
MYSQL_PASSWORD = "123456" # 你的MySQL密码
MYSQL_DB = "boc_exchange"
点击查看pipelines代码
import mysql.connector
from scrapy.utils.project import get_project_settings
class BocExchangePipeline:
def __init__(self):
# 读取 settings 配置
self.settings = get_project_settings()
self.conn = None
self.cursor = None
def open_spider(self, spider):
# 连接 MySQL 数据库
try:
self.conn = mysql.connector.connect(
host=self.settings.get("MYSQL_HOST", "localhost"),
port=self.settings.get("MYSQL_PORT", 3306),
user=self.settings.get("MYSQL_USER", "root"),
password=self.settings.get("MYSQL_PASSWORD", "123456"),
database=self.settings.get("MYSQL_DB", "boc_exchange"),
charset="utf8mb4"
)
self.cursor = self.conn.cursor()
spider.logger.info("✅ 数据库连接成功")
self.create_table() # 创建数据表
except Exception as e:
spider.logger.error(f"❌ 数据库连接失败:{str(e)}")
raise e # 连接失败终止爬虫
def create_table(self):
# 创建外汇数据表(适配 mysql.connector)
create_sql = """
CREATE TABLE IF NOT EXISTS boc_exchange (
id INT AUTO_INCREMENT PRIMARY KEY,
currency VARCHAR(50) NOT NULL COMMENT '货币名称',
tbp DECIMAL(10,2) COMMENT '现汇买入价',
cbp DECIMAL(10,2) COMMENT '现钞买入价',
tsp DECIMAL(10,2) COMMENT '现汇卖出价',
csp DECIMAL(10,2) COMMENT '现钞卖出价',
time VARCHAR(20) COMMENT '更新时间',
UNIQUE KEY unique_currency_time (currency, time) # 避免重复数据
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='中国银行外汇数据';
"""
try:
self.cursor.execute(create_sql)
self.conn.commit()
except Exception as e:
self.conn.rollback()
raise e
def process_item(self, item, spider):
# 插入/更新数据
insert_sql = """
INSERT INTO boc_exchange (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
tbp=%s, cbp=%s, tsp=%s, csp=%s
"""
try:
# 转换数据类型(避免字符串转小数失败)
tbp = float(item["tbp"]) if item["tbp"].replace(".", "").isdigit() else 0.00
cbp = float(item["cbp"]) if item["cbp"].replace(".", "").isdigit() else 0.00
tsp = float(item["tsp"]) if item["tsp"].replace(".", "").isdigit() else 0.00
csp = float(item["csp"]) if item["csp"].replace(".", "").isdigit() else 0.00
self.cursor.execute(insert_sql, (
item["currency"], tbp, cbp, tsp, csp, item["time"],
tbp, cbp, tsp, csp # 更新字段
))
self.conn.commit()
spider.logger.info(f"✅ 数据插入成功:{item['currency']}")
return item
except Exception as e:
self.conn.rollback()
spider.logger.error(f"❌ 数据插入失败:{str(e)},数据:{item}")
return item
def close_spider(self, spider):
# 关闭数据库连接
if self.cursor:
self.cursor.close()
if self.conn and self.conn.is_connected():
self.conn.close()
spider.logger.info("✅ 数据库连接已关闭")
点击查看boc_spider代码
import scrapy
from ..items import BocExchangeItem
class BocSpider(scrapy.Spider):
name = 'boc_spider'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
# 精准定位表格行
rows = response.xpath('//div[@class="BOC_main"]//table[@cellpadding="0"]//tr[position() > 1]')
print(f"匹配到{len(rows)}条数据行")
for row in rows:
item = BocExchangeItem()
# 提取货币名称(注意去除多余空格)
item['currency'] = row.xpath('td[1]/text()').get().strip()
# 现汇买入价
item['tbp'] = row.xpath('td[2]/text()').get(default='').strip()
# 现钞买入价
item['cbp'] = row.xpath('td[3]/text()').get(default='').strip()
# 现汇卖出价
item['tsp'] = row.xpath('td[4]/text()').get(default='').strip()
# 现钞卖出价
item['csp'] = row.xpath('td[5]/text()').get(default='').strip()
# 中行折算价
item['mid_rate'] = row.xpath('td[6]/text()').get(default='').strip()
# 发布日期
item['time'] = row.xpath('td[7]/text()').get().strip()
yield item
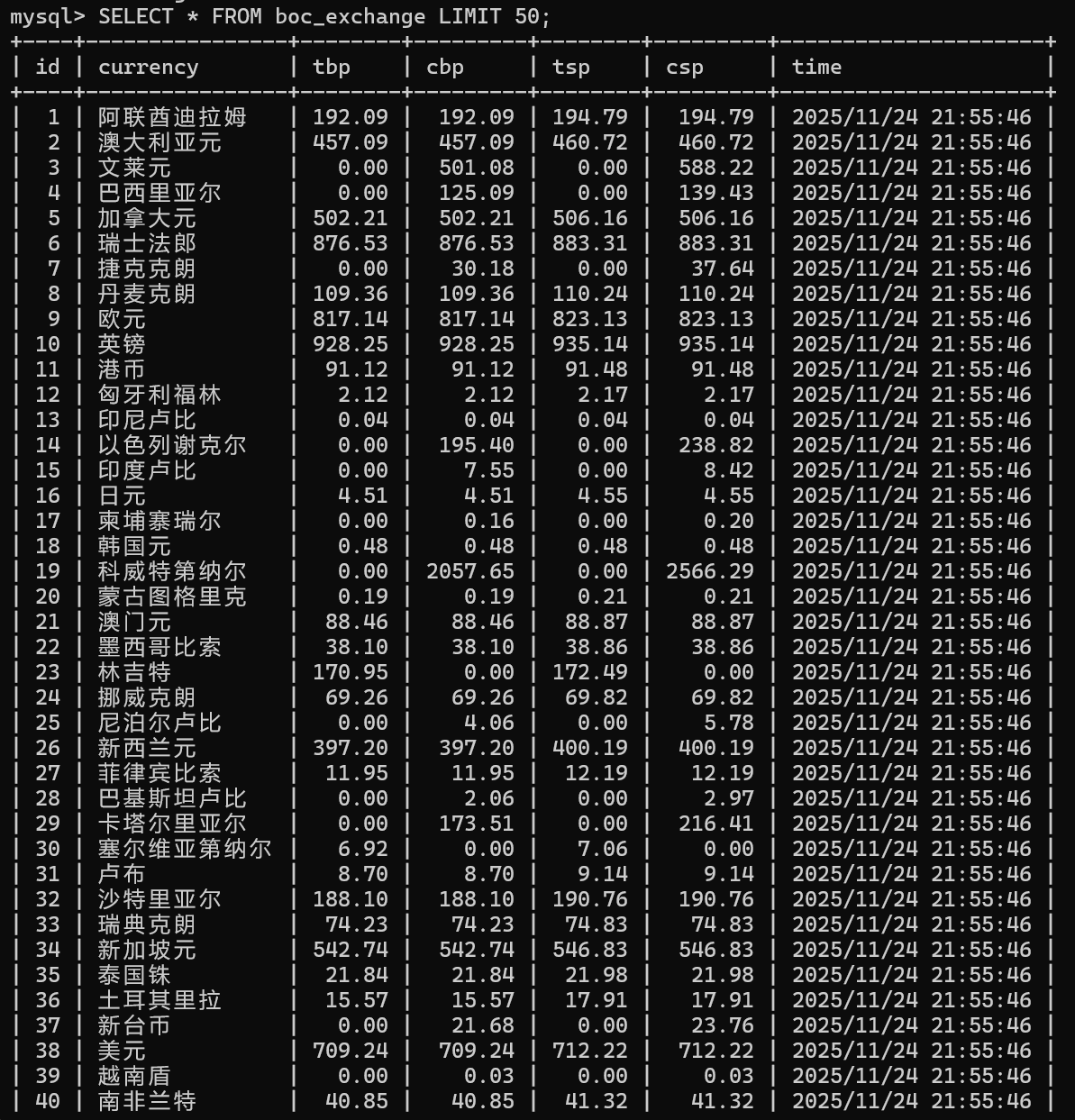
心得体会
一开始 Xpath 老是定位不到表格数据,后来发现是没找准页面结构,调整路径后才成功提取到货币名称、现汇买入价这些字段。Pipeline 则帮我自动完成了数据库存储,还能处理重复数据,不用手动写一堆 SQL 语句。不过中间也踩了坑,比如忘记提前创建数据库导致连接失败,还有部分货币的价格字段为空,得在代码里加默认值处理。
gitee链接
https://gitee.com/yang-ruyi777/2025_crawl_project/tree/homework3/boc_exchange/boc_exchange

 浙公网安备 33010602011771号
浙公网安备 33010602011771号