结对作业2
| 这个作业属于哪个课程 | 2021春软工实践|W班 (福州大学) |
|---|---|
| 这个作业的要求在哪里 | 结对作业二 |
| 结对学号 | 221801312、221801337 |
| 这个作业的目标 | 顶会热词统计的实现 |
| 其他参考文献 | 无 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 40 | 100 |
| • Design Spec | • 生成设计文档 | 20 | 15 |
| • Design Review | • 设计复审 | 20 | 5 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| • Design | • 具体设计 | 20 | 10 |
| • Coding | • 具体编码 | 2960 | 2780 |
| • Code Review | • 代码复审 | 20 | 25 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 40 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 30 | 90 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 15 | 20 |
| 合计 | 3225 | 3120 |
Github仓库
仓库地址
- github地址:yrc123/PairProject
- 代码规范地址:codestyle.md
目录结构
因为原本学号1&学号2的方式在我们前端使用的Vue中会出现运行BUG,经过查找发现是‘&’符号的问题,所以我们将其换成了‘_’。
.
└── 221801312_221801337
├── Java
│ ├── 后端
│ └── 数据处理
└── web
├── public
└── src
访问地址
- 部署访问地址:Paper Retrieval
- 后端接口展示地址:swagger-ui
作品展示
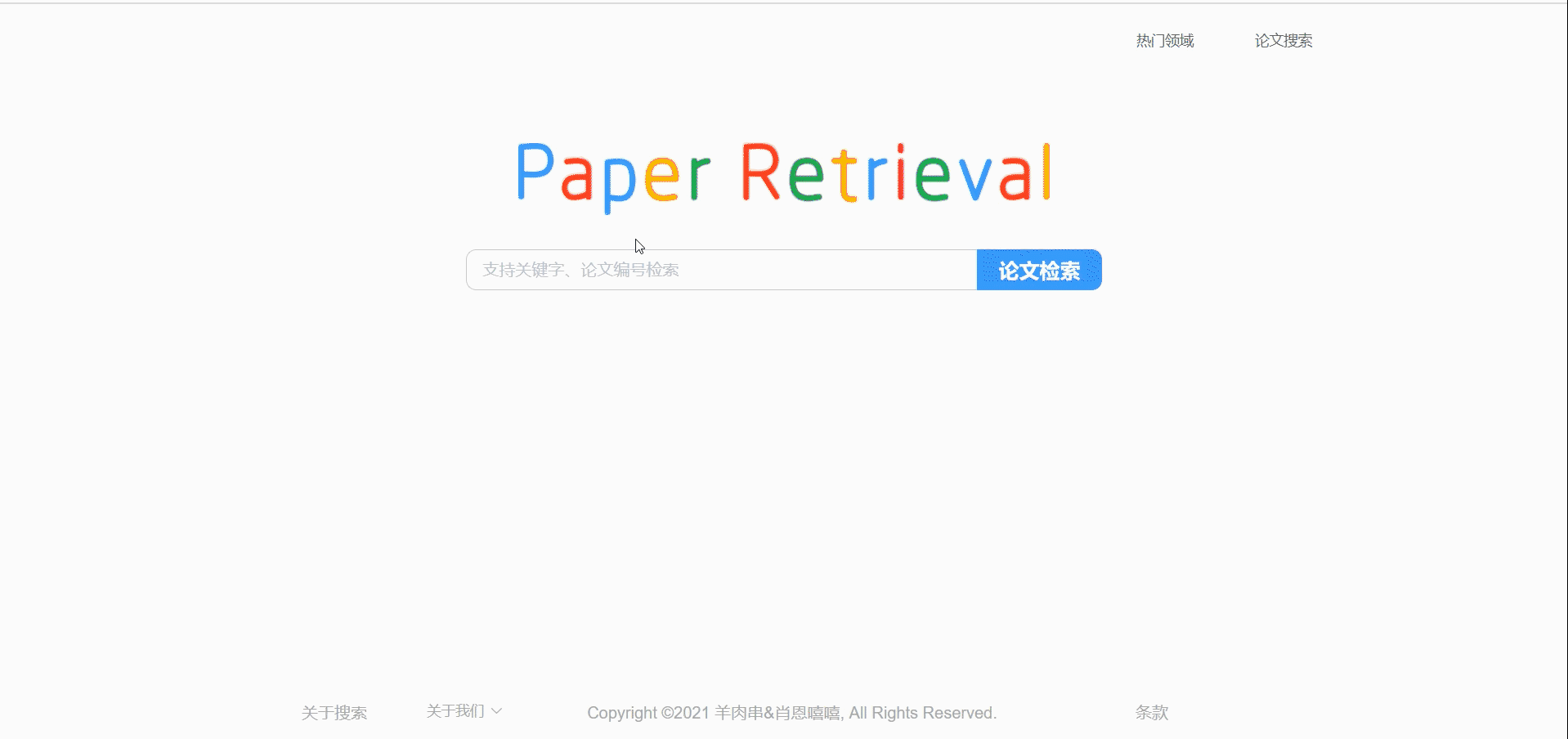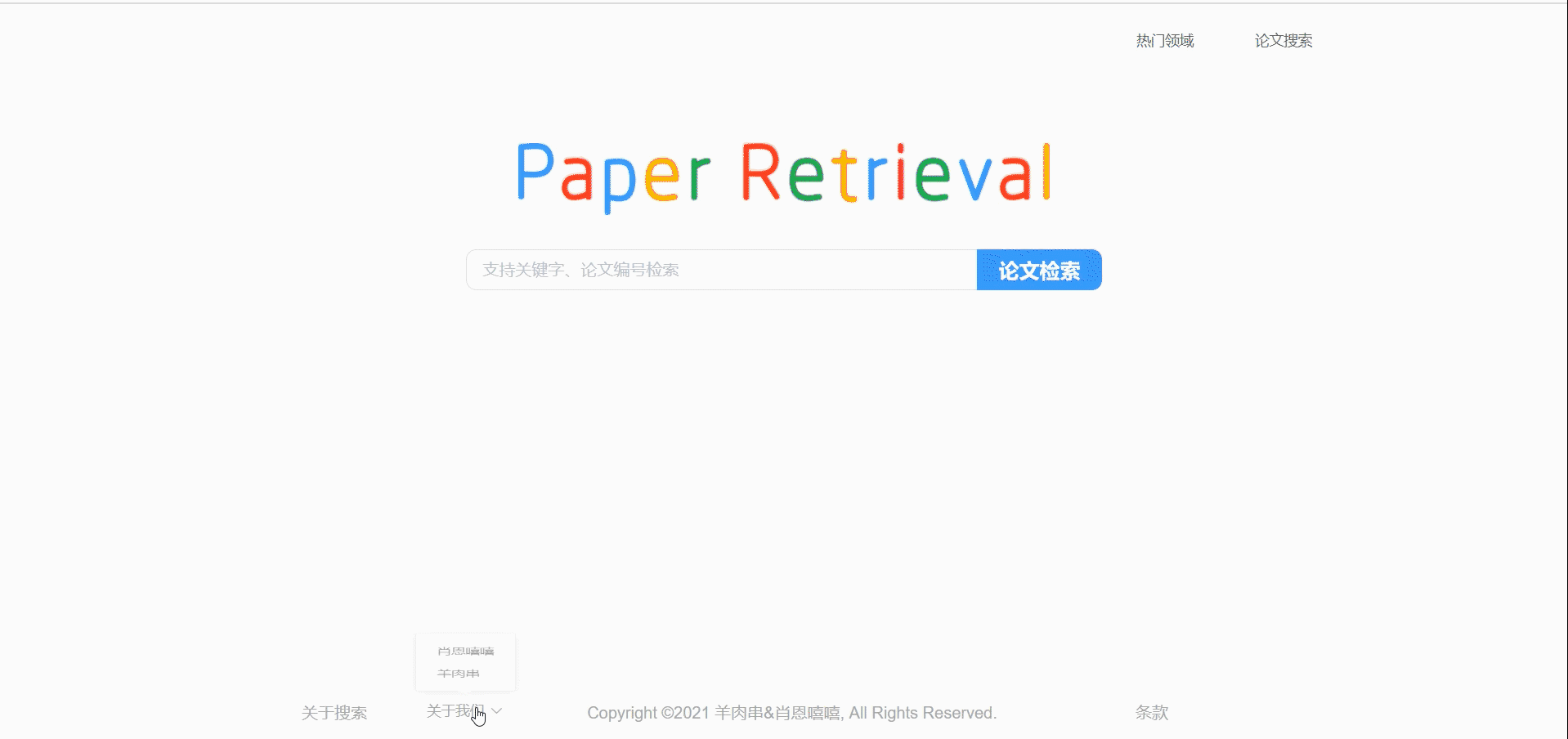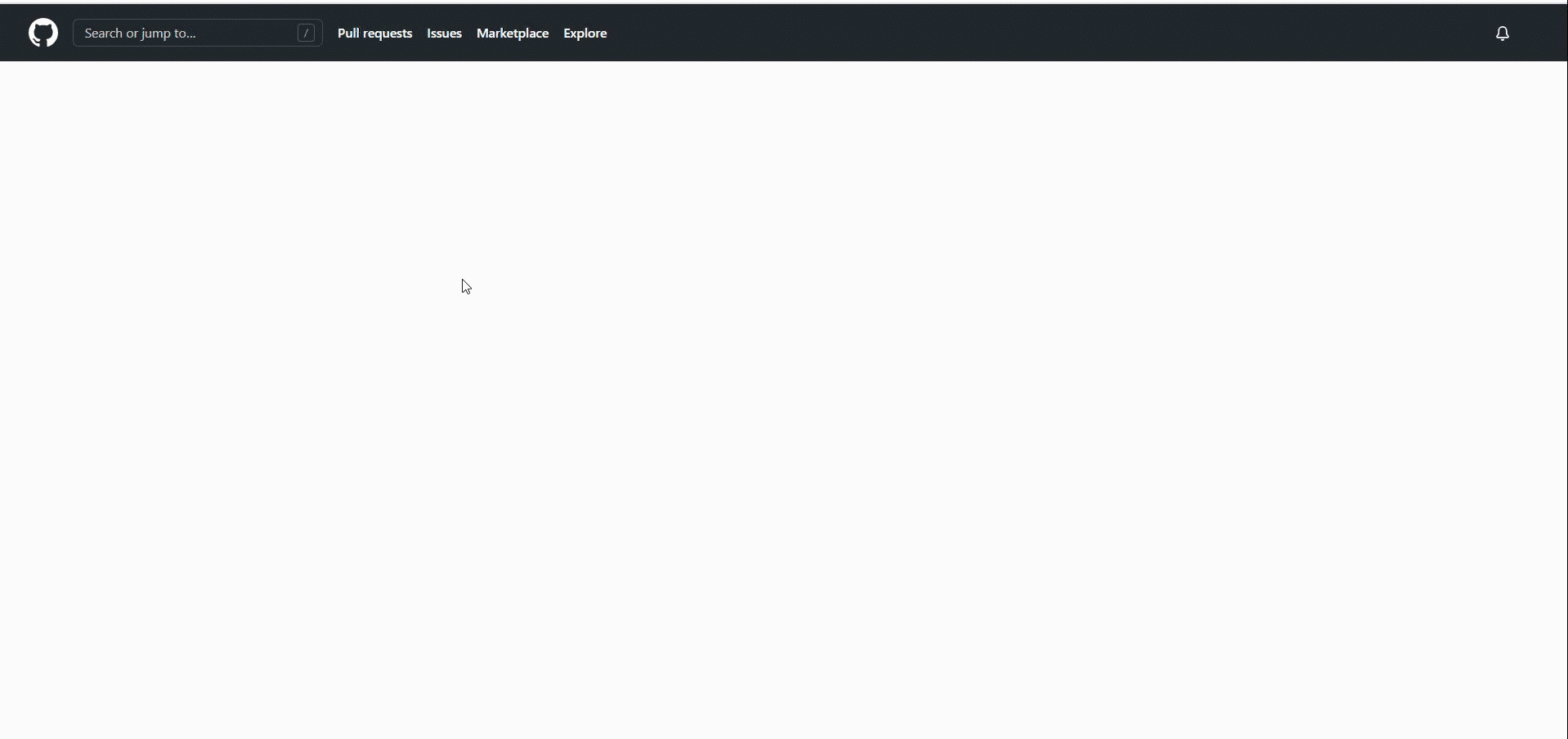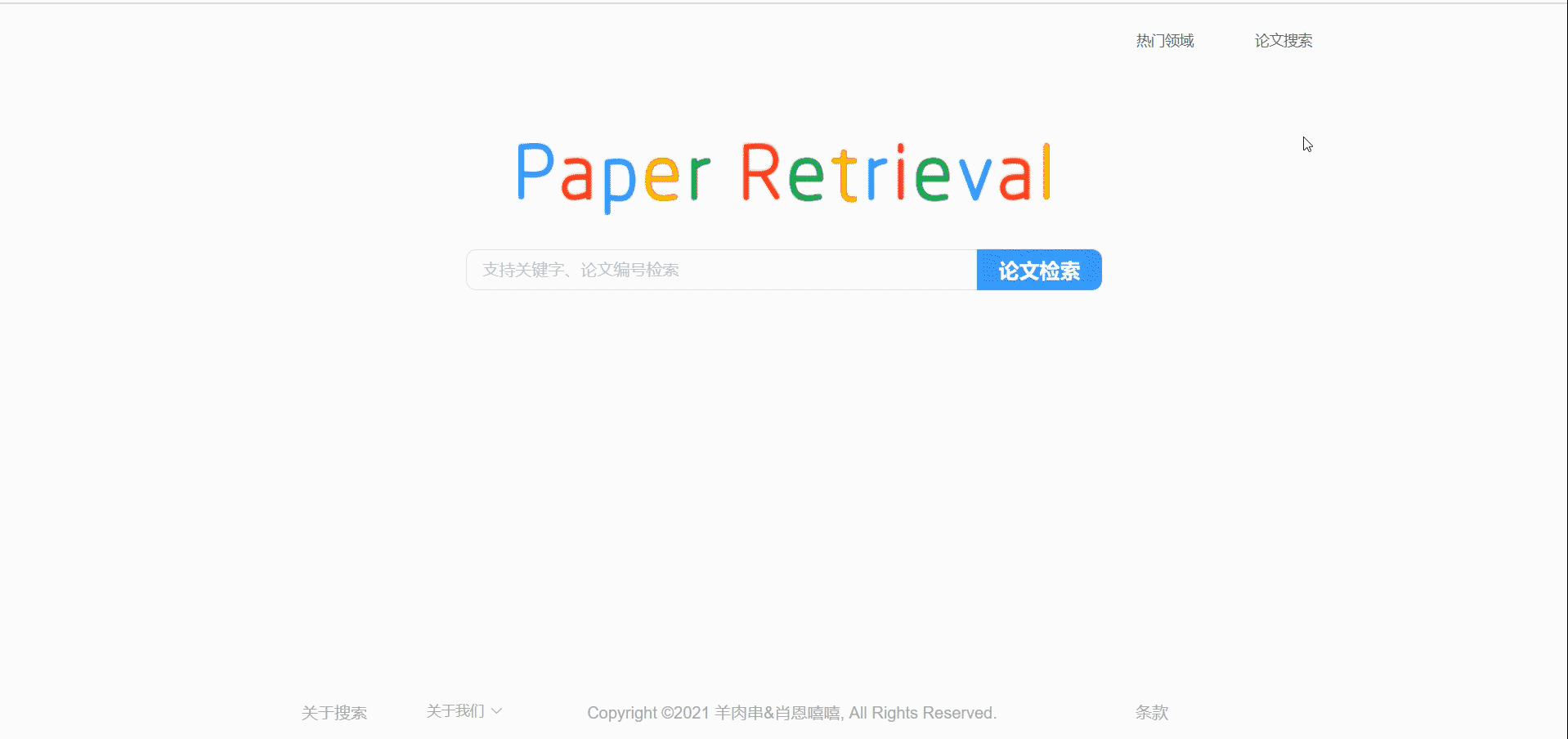
首页
底栏可以让直接跳转到我们的git主页。
数据可视化

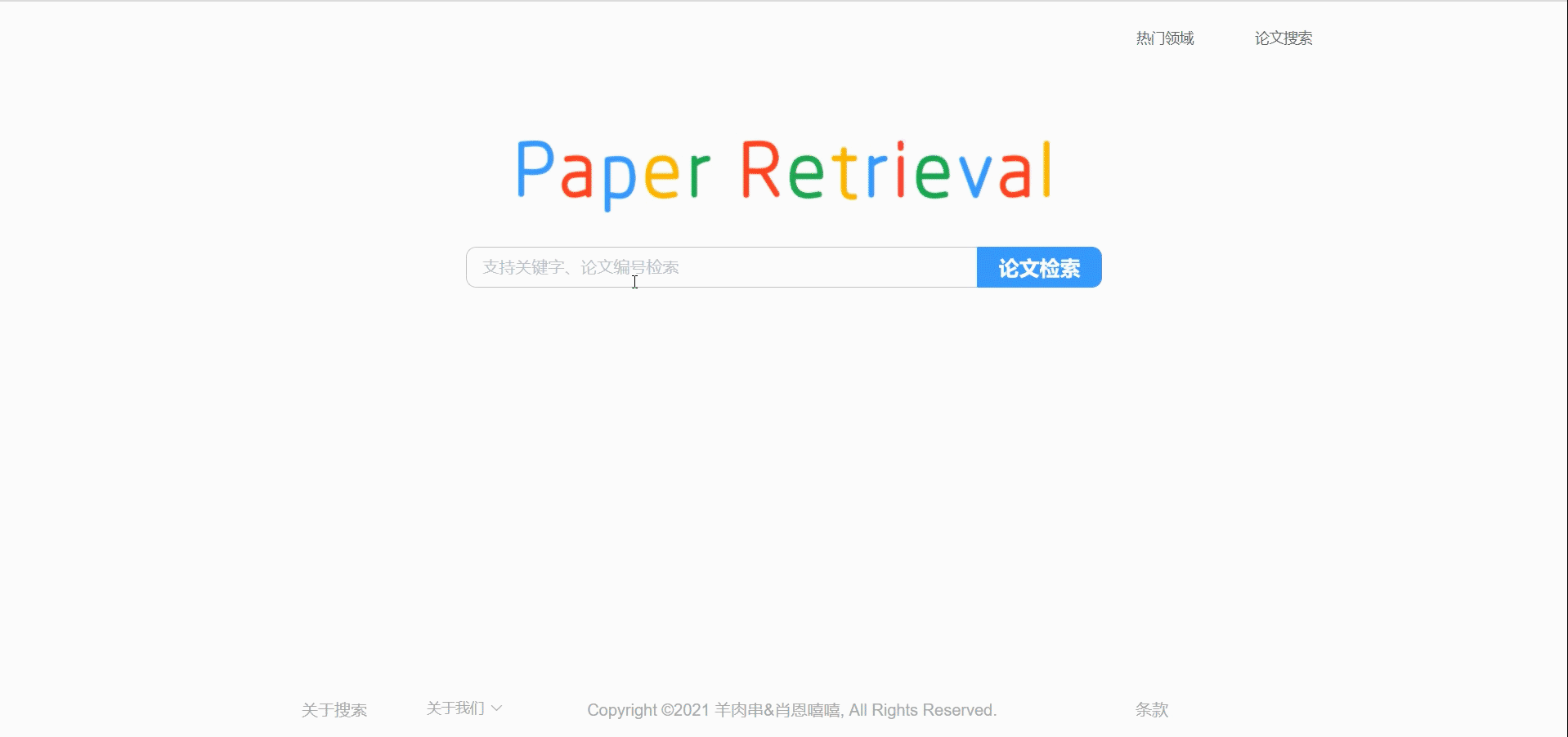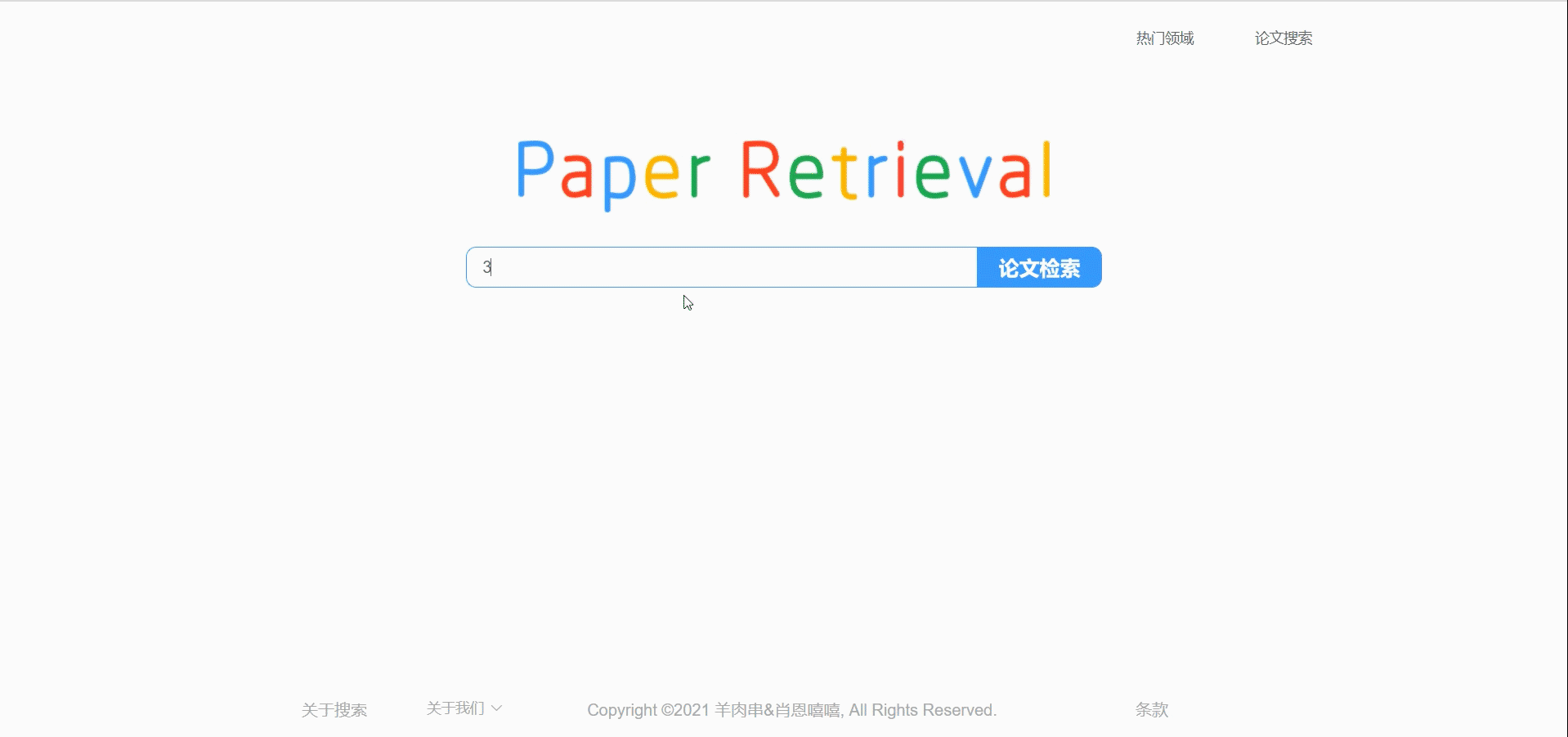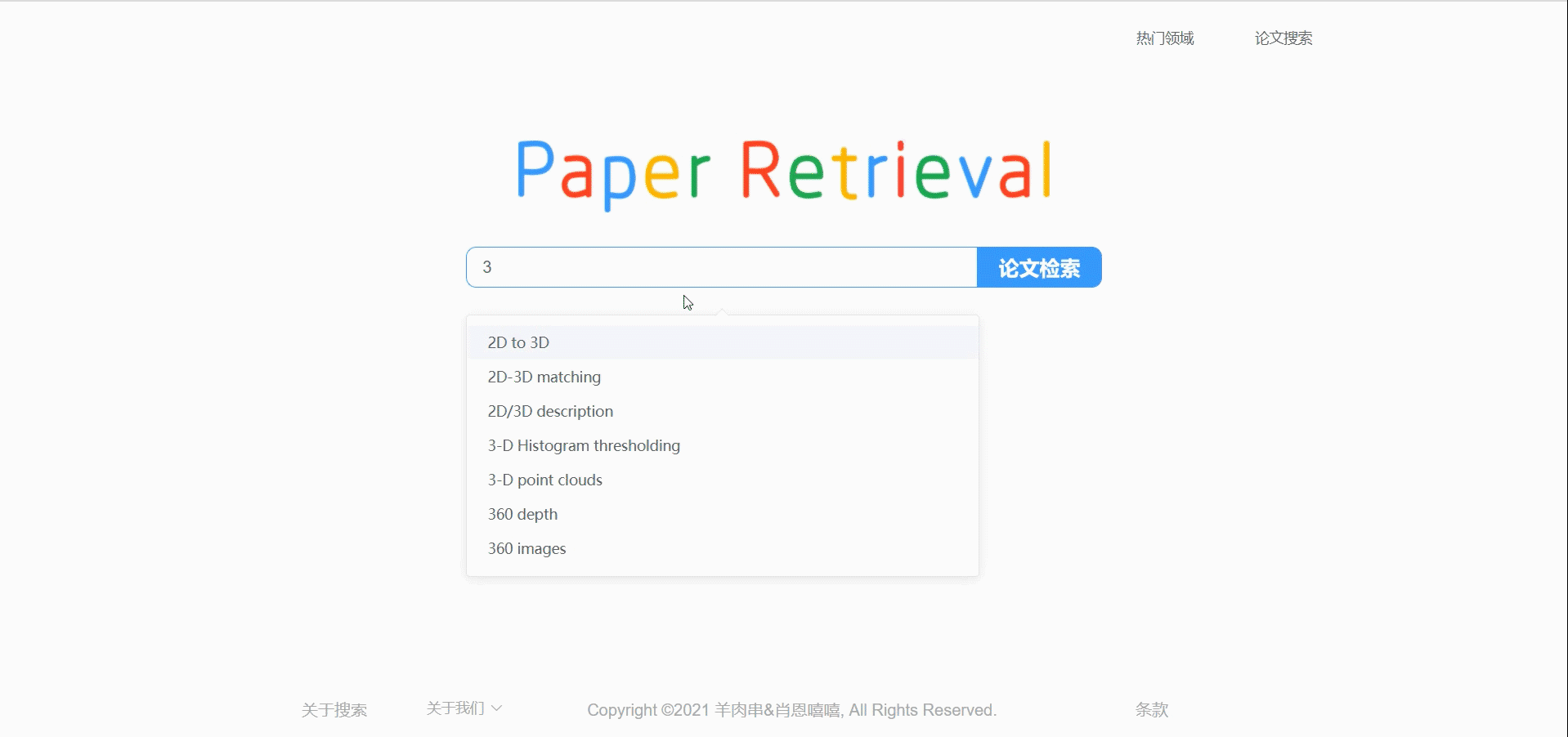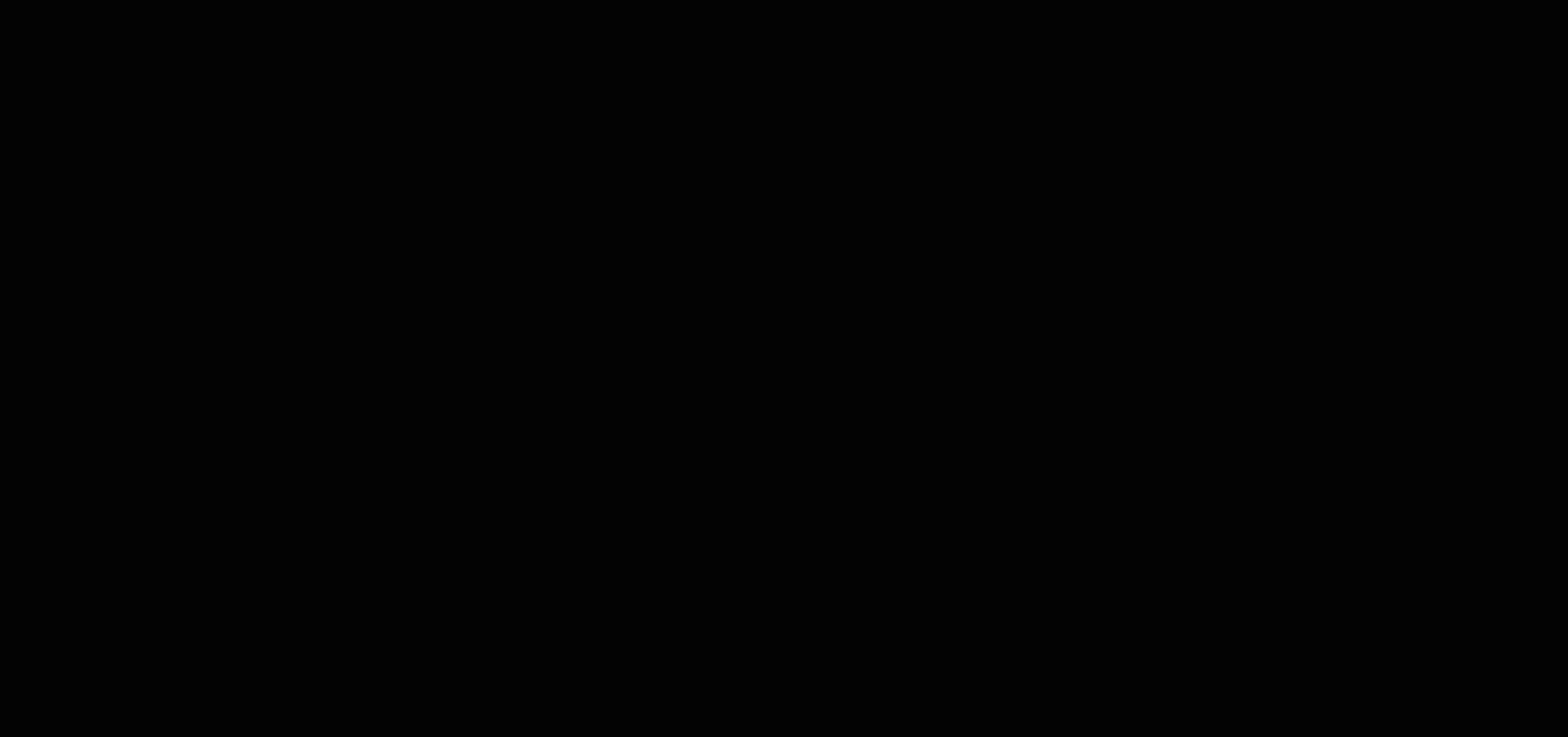
模糊搜索
可以让用户搜索时直接弹出建议输入搜索词,
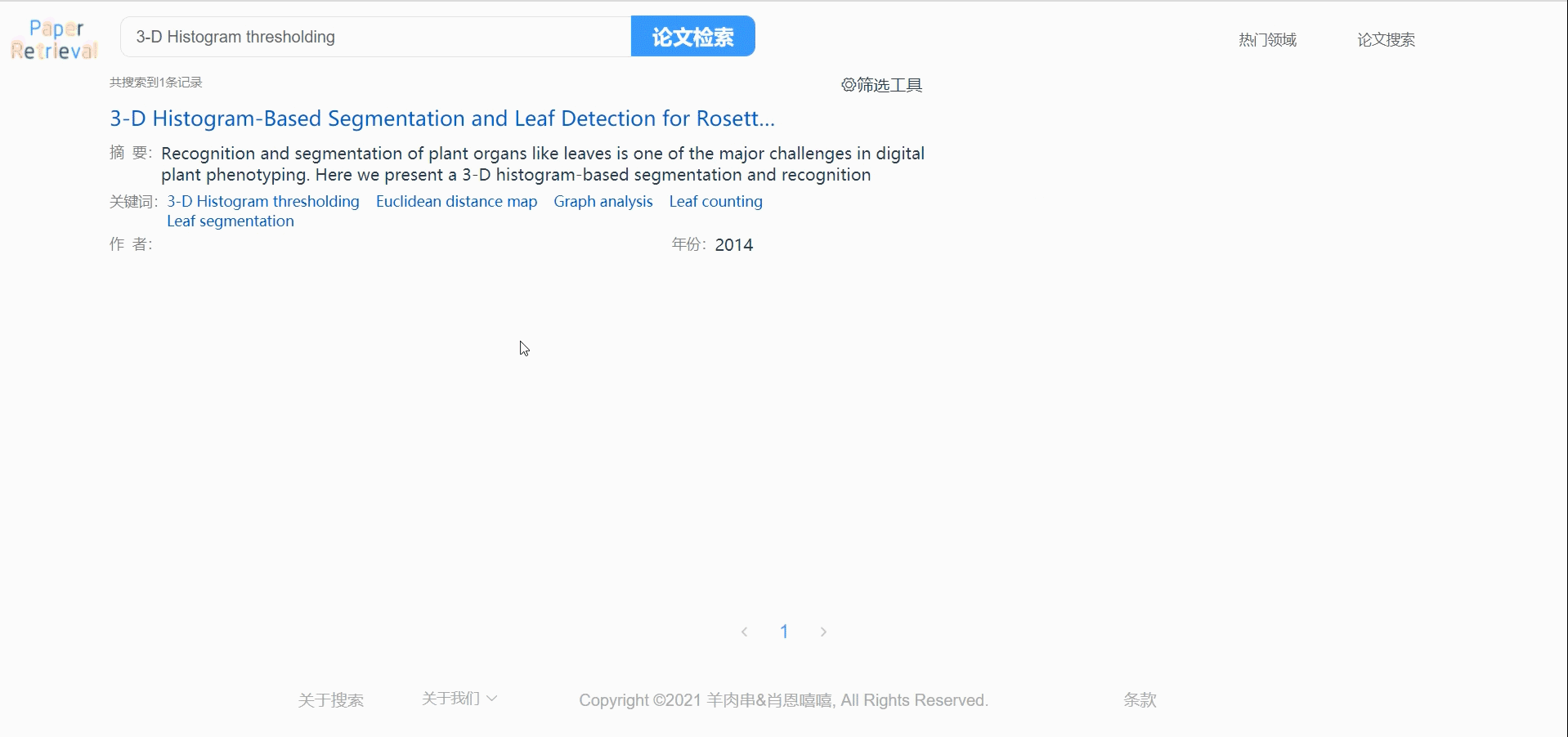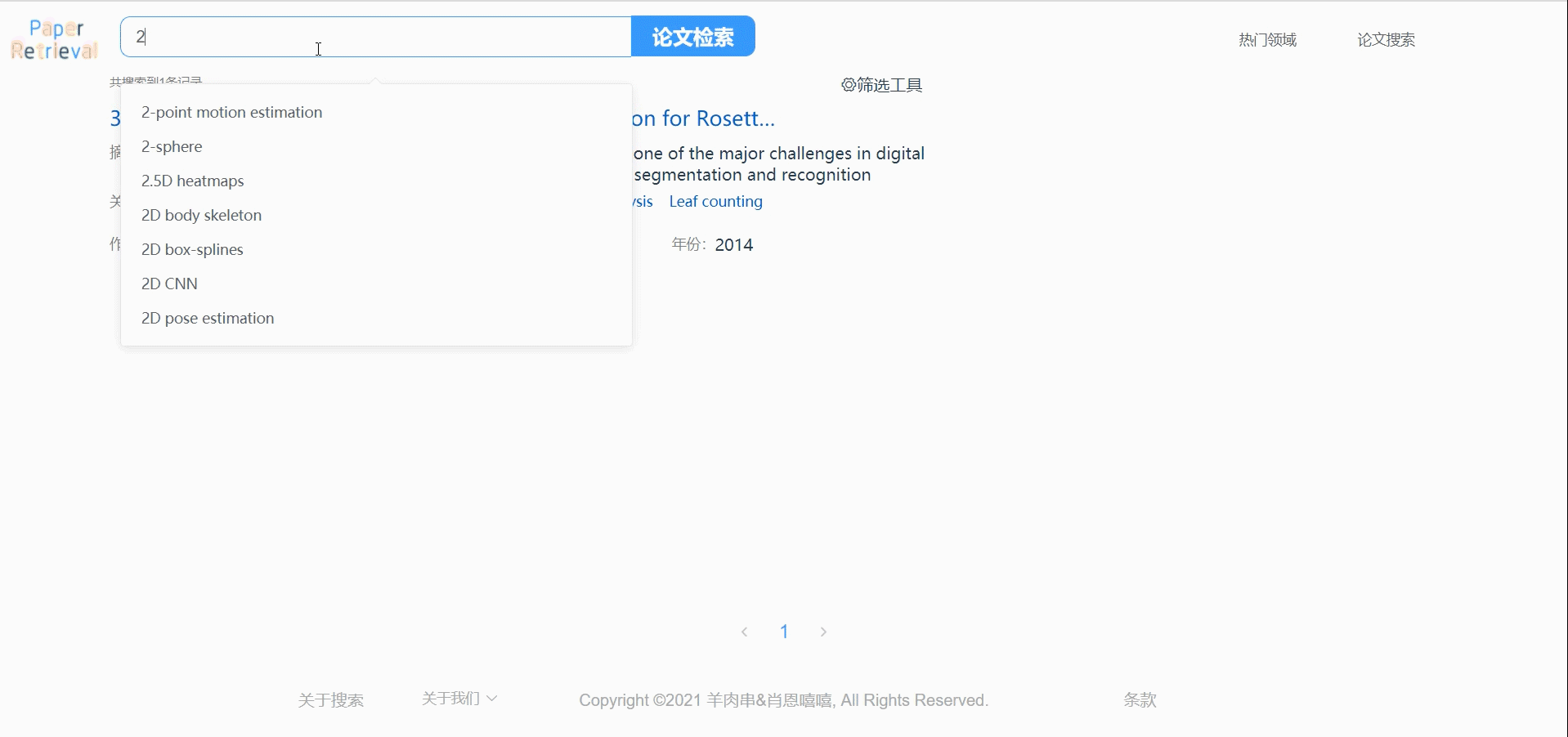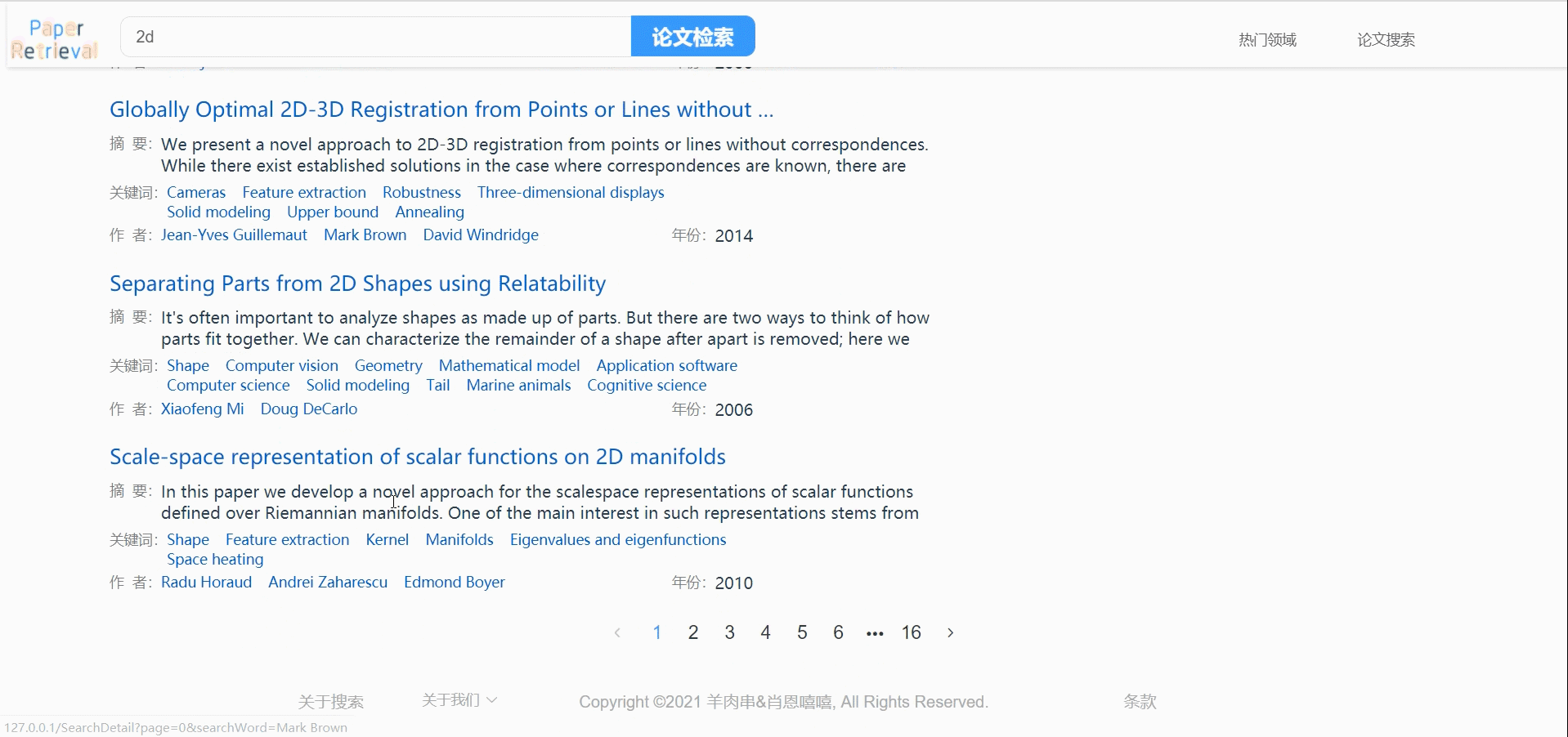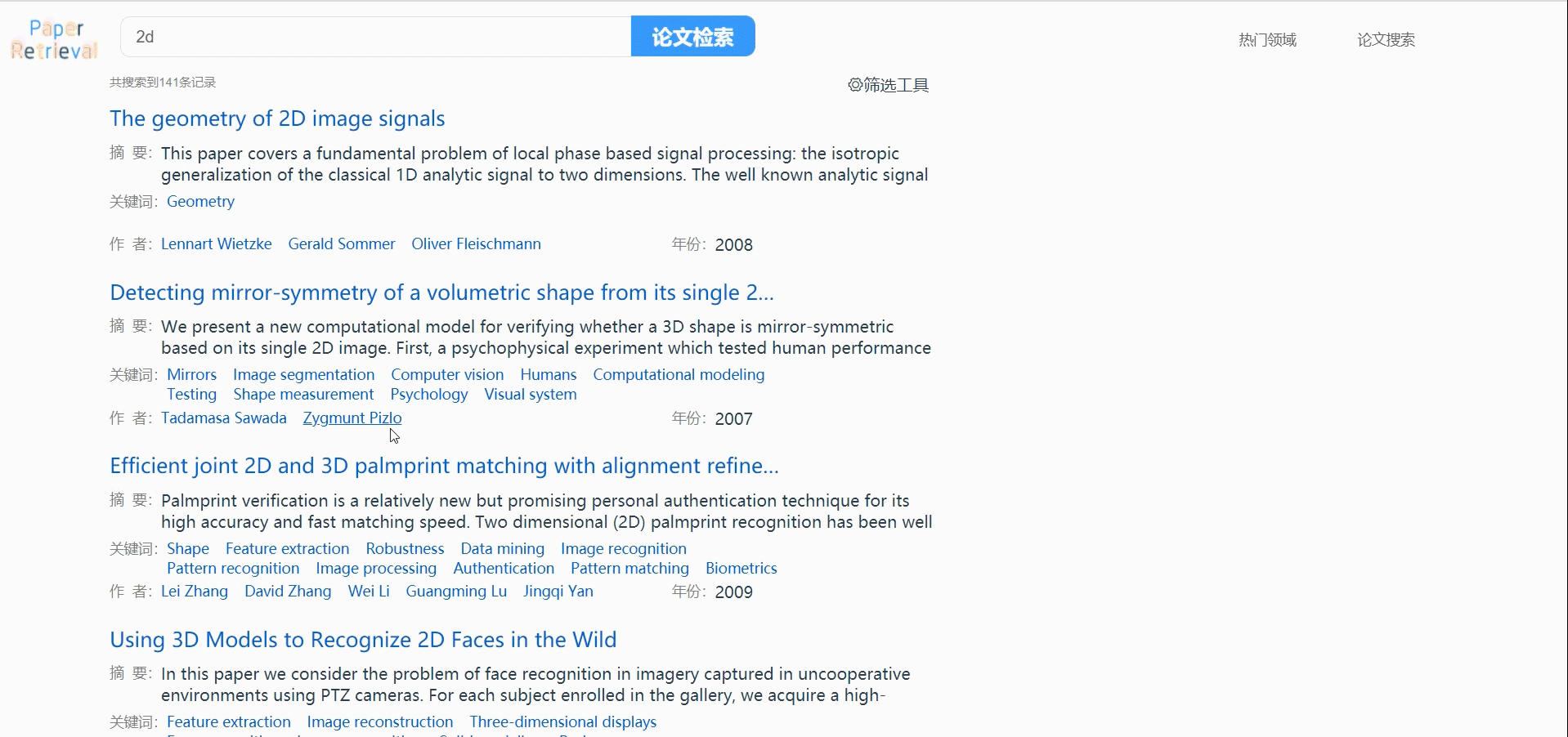
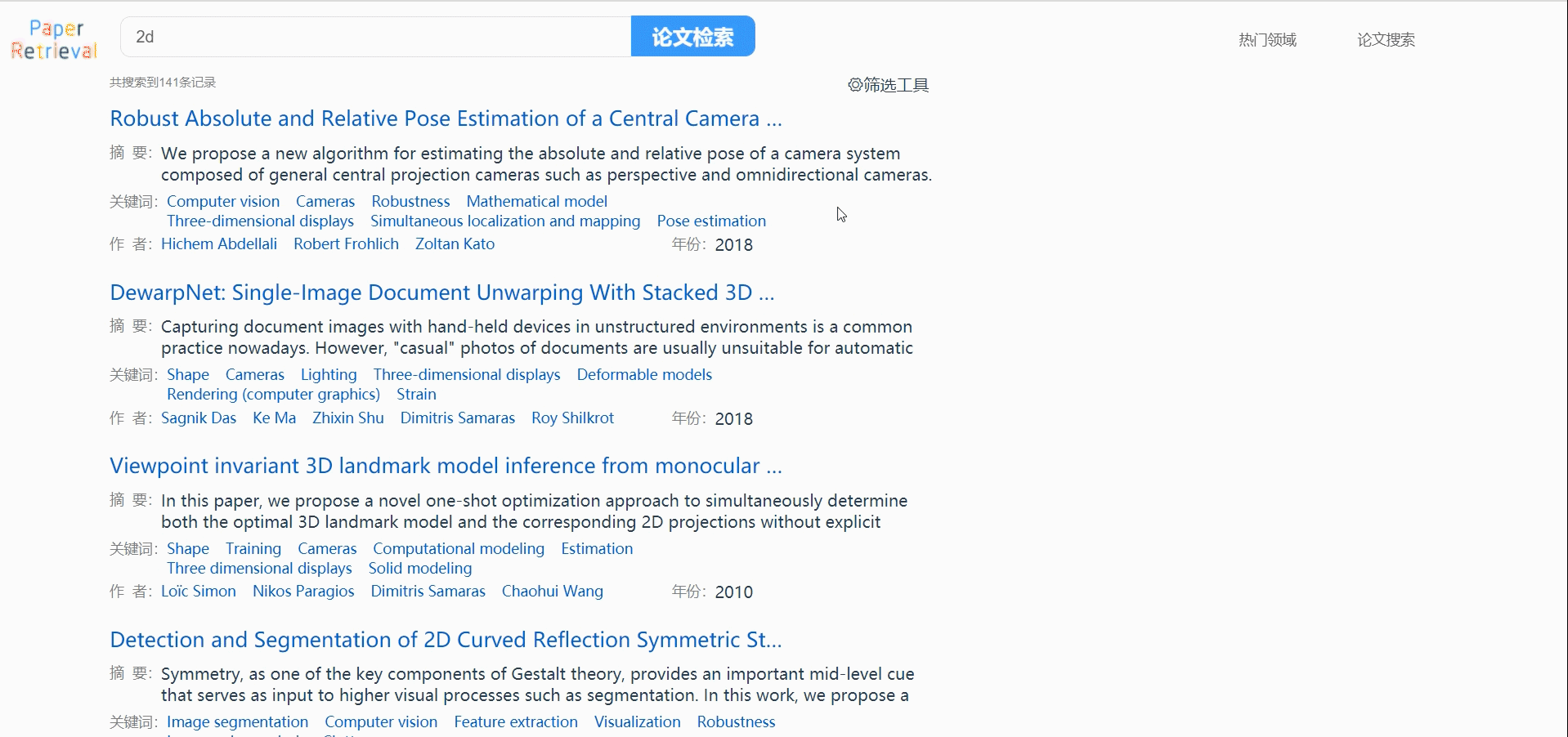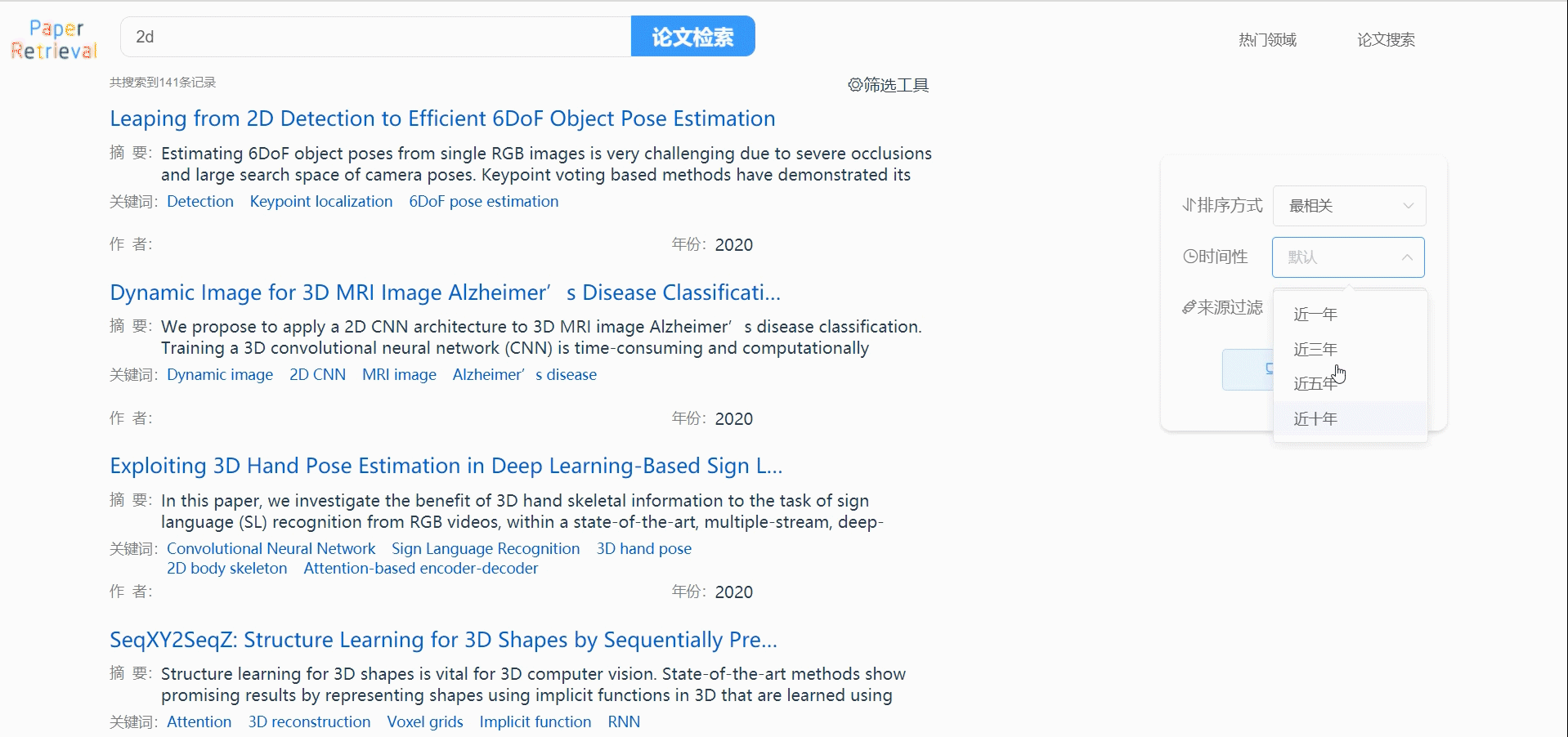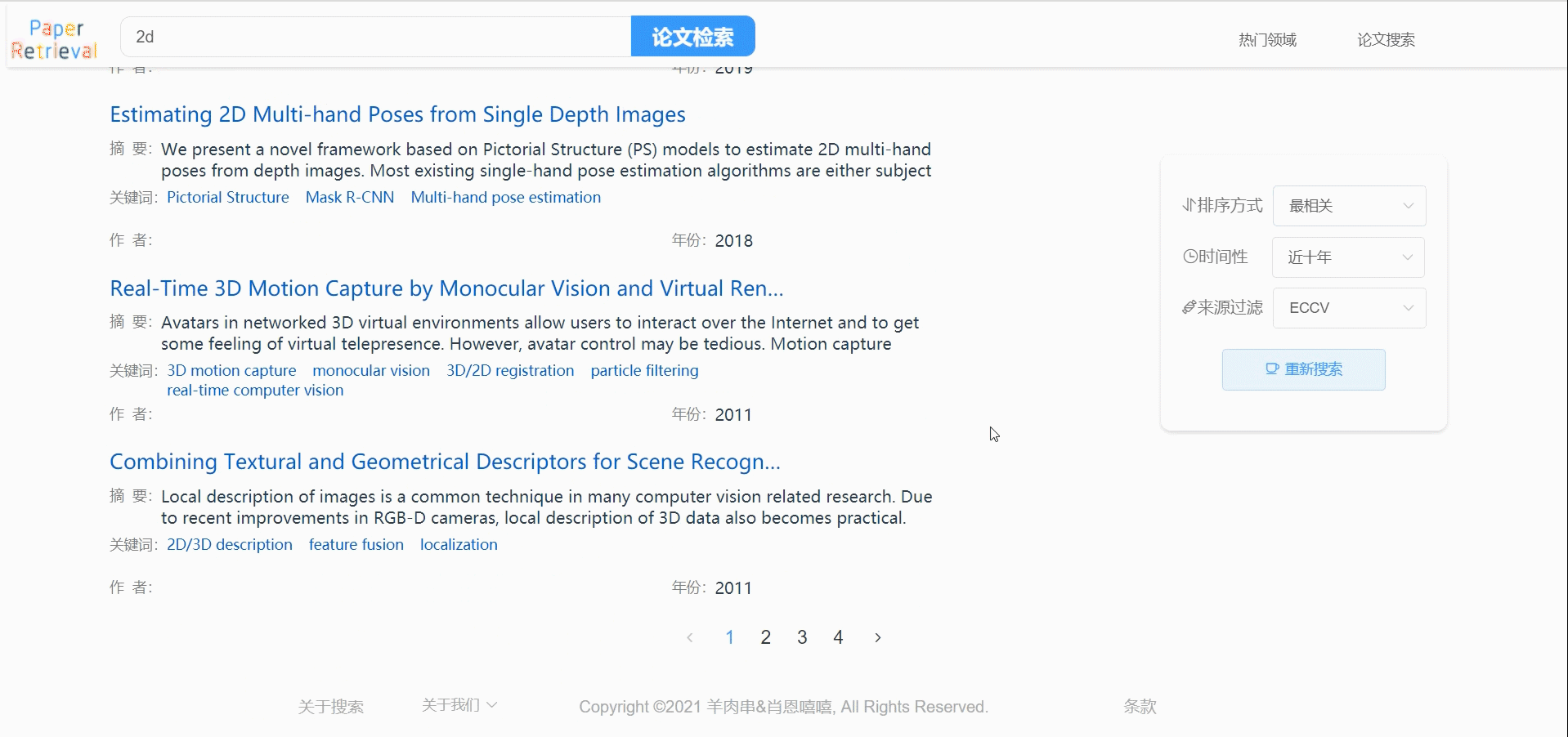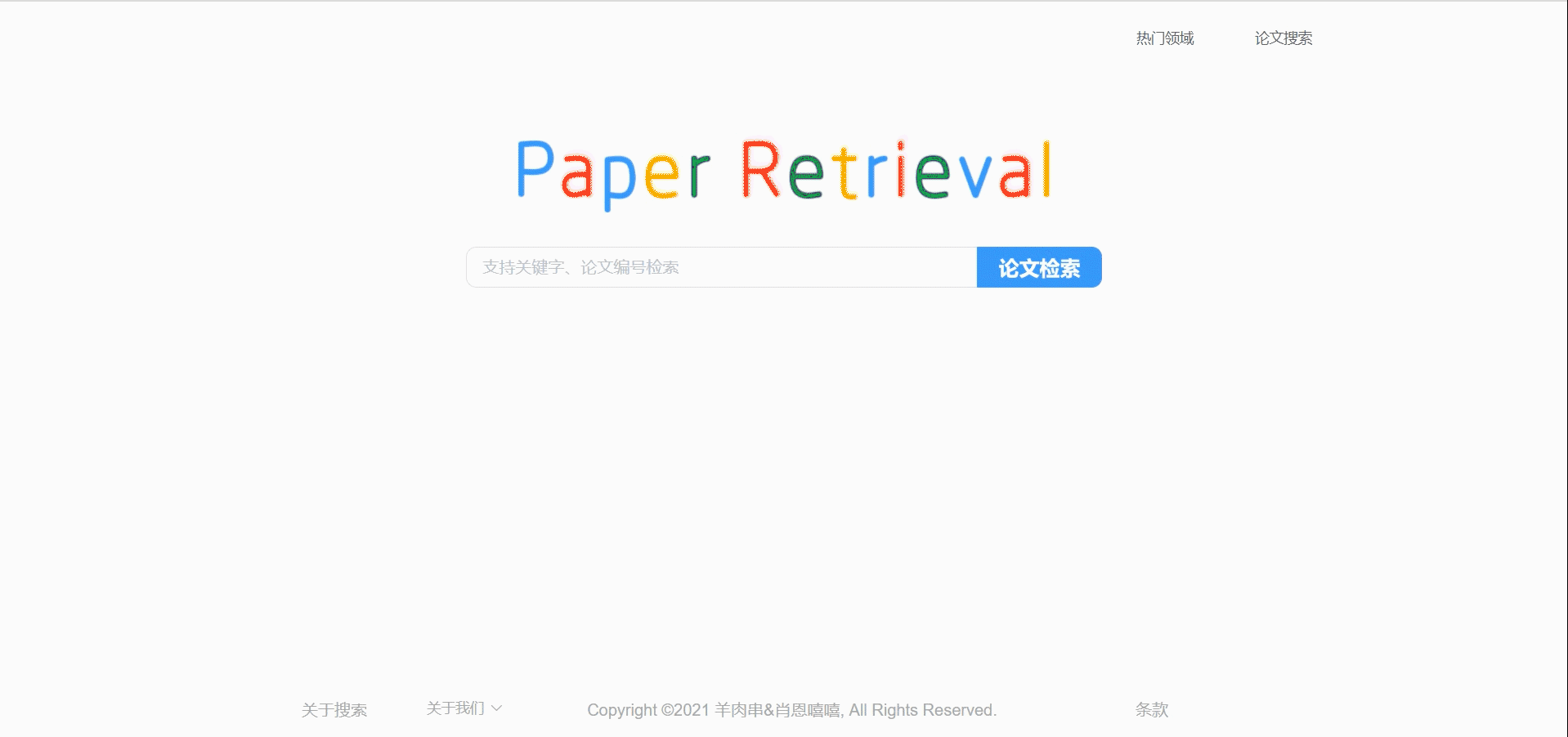
论文搜索
支持作者、标题、关键词同步搜索。
论文筛选
支持用户通过会议来源、时间性和相关性过滤论文列表。
接口展示

结对讨论过程
与之前线上不同,现在回到了学校,我们的讨论也从线上交流转换到了线下讨论,可以一起debug,效率提高了不少


设计实现过程
数据导入程序
结构图

代码说明
- 使用FastJson来转换json文件
- 使用mybatis来把数据存入数据库
PaperDao
- Dao层,有保存查询数据库的方法
PaperHandler
- 因为给出的paper数据格式有两种,所以我定义了一个PaperHandler接口
- 这个接口要求实现一个将
JSONObject转换成Paper类的toPaper方法 - 这样可以更好的复用其他的方法,把不同数据格式的差异给隐藏起来
Paper
- 论文类型的实体类
- 其中提供了两个方法,可以返回两种实现了
PaperHandler接口的匿名类,分别对应两种不同格式的json文件
public class Paper {
...
public static PaperHandler getDefultPaperHandler(){
//函数式接口,返回一个匿名类,对应CVPR和ICCV会议的json格式
return new PaperHandler() {
@Override
public Paper toPaper(JSONObject jo, String meetName, File file){
Paper paper = new Paper();
//使用FastJson解析数据,并放入Paper实体类中
paper.setTitle(jo.getString("title"));
paper.setAbstract(jo.getString("abstract"));
if(paper.getAbstract()==null)paper.setAbstract("");
List<String> authors=new ArrayList<>();
final JSONArray ja = jo.getJSONArray("authors");
for (int i = 0; i < ja.size(); i++) {
authors.add(ja.getJSONObject(i).getString("name"));
}
paper.setAuthors(authors);
if(jo.getJSONArray("keywords")!=null)
paper.setKeywords(
jo.getJSONArray("keywords")
.getJSONObject(0).getJSONArray("kwd").toJavaList(String.class)
);
else
paper.setKeywords(new ArrayList<>());
paper.setMeet(meetName);
final SimpleDateFormat year = new SimpleDateFormat("yyyy");
Date date = null;
try {
date = year.parse(jo.getString("publicationYear"));
} catch (ParseException e) {
e.printStackTrace();
}
paper.setPublicationYear(date);
paper.setUrl(jo.getString("pdfUrl"));
return paper;
}
};
}
//同上,对应ECCV会议的json格式,这里不再赘述
public static PaperHandler getECCVPaperHandler(){
...
}
}
Core
- 需要会议的文件夹路径(path)、会议名(meetName)和会议对应的PaperHandler实现类来构造。
- 在PapersearchApplicaiton中分别注入三个Core,之后分别执行Core的start()方法来导入json文件到数据库
@SpringBootApplication()
public class PapersearchApplication {
...
//注入三个Core对象
@Bean(name = "iccv")
public Core getIccv(){
return new Core("./论文数据/ICCV", "ICCV", Paper.getDefultPaperHandler());
}
@Bean(name = "cvpr")
public Core getCvpr(){
return new Core("./论文数据/CVPR", "CVPR", Paper.getDefultPaperHandler());
}
@Bean(name = "eccv")
public Core getEccv(){
return new Core("./论文数据/ECCV", "ECCV", Paper.getECCVPaperHandler());
}
...
}
前端设计
技术栈
- 前端框架使用Vue3
- UI框架使用ElementUI plus
- 使用axios进行前后端交互
- 数据可视化使用ECharts
页面设计
首页
因为是模仿Google和百度的搜索引擎式的简约风格,所以首页主体就是LOGO和搜索框,其中的难点应该是在于通过搜索框输入的内容进行模糊搜索,弹出建议搜索内容。这部分我通过ElementUI库的’建议搜索框‘组件实现,当用户输入内容时从后端请求数据,弹出建议选项。用户可以直接用键盘选择建议选项,回车查询。
//模糊搜索
const querySearch = (queryString, cb) => {
var data={
data:{searchWord:queryString,limit:7}
};
//console.log(data.data.searchWord);
cb([]);
var list= postHeader(data,true);
list.then(
function(value){
keywordList=value.data.searchWord;
for(var i=0;i<keywordList.length;i++){
keywordList[i].value=keywordList[i].keyword;
}
cb(keywordList);
//restaurants.value=keywordList;
})
};
近年热词
这部分数据可视化因为在原型设计时,是通过直接向Axure中导入JS代码实现,所以我们的代码基本不需要什么改动,主要是数据的请求和填入;但是当我们填入数据之后,发现大部分的关键词和论文名都太长,如果只是原本的旭日图会出现信息显示错位的问题,所以我们使用了其他类型的旭日图,当关键词超出一定长度时使用省略号表示,最外圈用论文标题向外显示,可以让我们的图表更加具有视觉冲击力。
Top10热词
与近年热词相同,这部分的JS代码我们在原型设计时就已经实现,这部分的难点主要是将每个关键词的相关论文链接写入图表,让用户可以直接点击相关论文的标题进入论文页,我们通过慢慢拼接html代码和链接实现,这部分页出现的标题名称太长的问题,我们的解决办法还是超出部分用省略号表示,同时利用a标签的titile属性,可以让用户把鼠标放在标题上时提示出标题的全称。
底部栏
这部分主要是设计了一些版权信息还有我们两人的github地址等等,并没有什么难点,但是因为这是我最先开始做的一部分,那时对Vue和ElementUI都还相当生疏,所以还是花费了部分时间。
论文列表
因为我们是搜索引擎式的风格,所以我们加入的“共搜索到XX条记录”、蓝色标题等元素,让我们的页面开起来更像百度。这部分是整个项目最复杂的地方,所以也是最耗时的一部分。
- 首先关于论文列表删除,在原型设计时我们也有谈到,因为我们是搜索引擎式的风格,我们认为让用户删除论文是不合理且很危险,所以我们没有制作可以删除论文列表的功能。
- 这部分第一个问题就是数据请求问题,最初我们还是打算用POST来请求数据,但是这样就会出现用户刷新页面之后数据全部丢失的情况,我们观察的百度的请求方式,利用GET请求,把搜索词、页码、排序方式、来源、时间性等数据记录在GET中,能够让页面数据不丢失。
- 还有就是分页的问题,我们为了更快地加载页面,所以每次只请求一页的9条数据,当用户点击页数的时候重新请求数据,起初我们出现了页面能够成功请求但底部的页码按钮因为刷新页面被重置为1的问题,这部分我们的解决办法是通过当前页面的URL中的’page‘字段的值来重新设定页码数。
- 我在每项论文的排版也出现了不小的问题,主要还是因为我前端的基础较为薄弱,导致很多布局、属性等都要一边搜一边写;这里出现的问题就是论文名字太长,关键词、作者数量不定的问题,论文名字还是使用超出长度省略号,鼠标悬停提示完整标题的形式。关键词和作者部分,我通过限定好宽度和高度,超出部分自动隐藏,在填入数据时,利用v-for直接把取到的所有数据填入,超出部分即可自动隐藏。
- 在整个项目中,最大的问题就是异步请求的问题了,因为axios的请求只能异步实现,但当页面渲染好时数据还没有请求到,出现的数据无法渲染的问题,在这个地方我卡了很长时间,试过让Axios同步实现、用AJAX等方式,但因为我们的项目是通过Vue3编写的,所以很多信息都比较少,都没有找到比较好的解决办法。后来在我的对友的帮助下,还是采用比较简单粗暴的形式解决了(把数据处理都放进请求的回调函数中);再后来,我们使用Vue2的语言,才成功将数据双向绑定,解决的异步的问题。
- 这部分主要的问题还是我个人对VUE的不熟练,导致花费了大量的时间在“怎么实现”和“怎么会这样”中切换,非常感谢我的对友陪我解决了很多问题。
//高级搜索,筛选论文列表,通过拼接URL重新加载页面
searchAgain(){
var newURL=window.location.pathname;
newURL+="?searchWord=";
newURL+=window.location.search.match('((?<=searchWord=).*?(?=&|$))')[0];
if(this.orderBy!=null)
newURL+="&orderBy="+this.orderBy;
if(this.time!=null)
newURL+="&time="+this.time;
if(this.from!=null)
newURL+="&meetId="+this.from
newURL+="&page=0";
//console.log(newURL);
window.location.href=newURL;
}
//页面加载时通过URL请求输入,通过正则表达式查询URL参数来实现用户通过筛选工具刷新后筛选工具窗口继续
//存在
created(){
this.getData();
this.currentPage=parseInt(window.location.search.match('((?<=page=).*?(?=&|$))')[0])+1 + "";
console.log(this.currentPage);
if(window.location.search.match('((?<=time=).*?(?=&|$))')!=null)
this.time=window.location.search.match('((?<=time=).*?(?=&|$))')[0];
if(window.location.search.match('((?<=orderBy=).*?(?=&|$))')!=null)
this.orderBy=window.location.search.match('((?<=orderBy=).*?(?=&|$))')[0];
if(window.location.search.match('((?<=meetId=).*?(?=&|$))')!=null)
this.from=window.location.search.match('((?<=meetId=).*?(?=&|$))')[0];
if(this.time!=null || this.from!=null || this.orderBy!=null)
this.showTool=true;
},
后端设计
技术栈
- 项目使用了spring boot为项目框架
- dao层用了mybatis
- 使用redis来缓存历史查询和图表数据,其中查询缓存时间为5分钟,图标信息缓存时间为1天
- 使用swagger来生成接口文档,方便前端调试
结构图
- Spring Bean关系依赖图


数据库设计

代码说明
使用Redis来缓存数据
问题描述
由于类似旭日图、柱状图的图表展示需要的数据查询量大,需要的查询时间较长,但是同时图表展示对数据的时效性要求并不高,所以应该使用缓存来提升查询速度、降低对数据库的压力。
RedisConfigure类
/**
* 通过注入自定义的CacheManager类来配置缓存
*/
@Configuration
public class RedisConfigure {
@Autowired
private RedisConnectionFactory connectionFactory;
@Bean(name="cacheManger")
public CacheManager initRedisCacheManager(){
HashMap<String ,RedisCacheConfiguration> configMap = new HashMap<>();
//为不同的数据设置不同的ttl,在性能和数据时效性之间保持一个平衡
configMap.put("similarWord",getMyConfigure().entryTtl(Duration.ofMinutes(20)));
configMap.put("searchPaper",getMyConfigure().entryTtl(Duration.ofMinutes(20)));
configMap.put("top10",getMyConfigure().entryTtl(Duration.ofDays(1)));
configMap.put("sunburst",getMyConfigure().entryTtl(Duration.ofDays(1)));
//用构造器构造CacheManager
RedisCacheManager redisCacheManager = RedisCacheManager.builder(connectionFactory)
.cacheDefaults(getMyConfigure())
.withInitialCacheConfigurations(configMap)
.build();
return redisCacheManager;
}
//返回一个自定义的默认配置
private RedisCacheConfiguration getMyConfigure(){
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
//将存入redis缓存时使用的序列化器改为支持json的序列化器,提升缓存数据的可读性
config=config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(RedisSerializer.json()));
config=config.entryTtl(Duration.ofMinutes(5));
return config;
}
}
关于自调用缓存失效
由于spring boot的缓存注解是通过AOP织入的,所以在类内的自调用不是调用代理对象,如:
public class MyService{
@Cacheable
public Map<String,Object> searchPaperCount(...){...}
@Cacheable
public Map<String,Object> searchPaper(...){
...
res.put(this.searchPaperCount(...));//自调用,缓存失效
...
}
}
解决方法则是在类内注入当前类的接口或者直接注入当前类,然后调用注入的对象即可。
public class MyService{
@Autowired
MyService service;
@Cacheable
public Map<String,Object> searchPaperCount(...){...}
@Cacheable
public Map<String,Object> searchPaper(...){
...
res.put(service.searchPaperCount(...));//调用了代理类,缓存生效
...
}
}
结果



这里测试了sunburst接口,虽然这个接口的查询量大但是对数据的时效性要求不高,所有可以使用缓存。由上面的两次查询可以看到,由于第二次查询是从redis读取缓存,相比于从数据库查询,查询时间从477ms下降到了83ms,时间只有原来的\(\frac{1}{5}\),极大提升了用户体验。
预查询
问题描述
由于我们是标题、作者和关键词联表查询,导致查询速度比较慢,在没有缓存的情况下查询要800ms左右。为了提升用户体验,加入了预查询功能:在用户查询一页后,后端自动在新线程中查询下一页并放入缓存。
关键代码
public class PaperSearchController {
...
@GetMapping("search_paper")
@Operation(summary = "搜索文章接口")
@ResponseBody
public Map<String,Object> searchPaper(@Schema(defaultValue = "3D") String searchWord,
@Nullable Integer orderBy,
@Nullable @Schema(defaultValue = "5") Integer time,
@Nullable Integer meetId,
@Schema(defaultValue = "0") Integer page,
HttpServletRequest http){
if(page==null)page=0;
//用户当前查询项
Map<String,Object>resp=
searchService.searchPaper(searchWord,orderBy,time,meetId,9,page);
Integer finalPage = page;
//将下一页放入线程池中查询,并将结果放入缓存
threadPoolExecutor.execute(new Runnable() {
@Override
public void run() {
searchService.searchPaper(searchWord,orderBy,time,meetId,9,finalPage +1);
}
});
//返回用户当前查询结果
return resp;
}
}
结果


通过预查询,通过预测用户查询下一页的需求,降低了查询时间,提升了用户体验。
使用Aspect来包装数据
问题描述
请求和响应的数据都有统一的格式,下面是一个响应的数据格式
{
timestamp:"当前时间戳",
staus:"状态码",
data:"实际返回的数据",
message:"消息",
path:"请求的URI"
}
如果在每个Controller中都对数据的格式进行解析和封装,会造成代码的冗余,并且不便于后续维护。所以使用Aop来处理数据格式
ControllerAspect类
@Component
@Aspect
public class ControllerAspect {
//设置切点
@Pointcut("execution( * com.jdzy.papersearch.controller.*.*(..))")
public void pointCut(){}
//定义切面
@Around("pointCut()")
public Map<String,Object> getData(ProceedingJoinPoint jp){
//获取被代理函数的传入参数
Object[] args = jp.getArgs();
HttpServletRequest httpReq = (HttpServletRequest) args[args.length-1];
if(args[0]!=null&&args[0].getClass().getInterfaces()[0]==Map.class){
Map<String,Object> data = (Map<String, Object>) args[0];
data= (Map<String, Object>) data.get("data");
args[0]=data;
}
Object resp = null;
try {
//执行连接点,并获取返回值
resp = jp.proceed(args);
} catch (Throwable throwable) {
log.error("Around失败");
throwable.printStackTrace();
}
//通过自己实现的HttpTools来包装返回值
return HttpTools.buildSuccessResp(resp, httpReq.getRequestURI());
}
}
结果
- 织入前返回的数据

- 织入后返回的数据

关键词补全和文章搜索的接口实现
关键代码
PaperSearchService
@Service
public class PaperSearchService {
//各种dao层注入
@Autowired
KeywordDao kDao;
@Autowired
PaperDao pDao;
@Autowired
AuthorDao aDao;
@Autowired
PaperSearchService service;
/**
* 关键词补全接口
* @param word:用户已输入的关键词
* @param limit:限制返回的条数
*/
@Cacheable(value = "similarWord",
key="'word_'+#word+'_'+#limit")
public List<Keyword> searchSimilarWord(String word,Integer limit){
//通过' '和'+'来分割输入的关键词
String[] split = word.split(" |\\+");
//通过LinkedHashSet来保证在去重的同时保证插入的优先级
HashSet<Keyword> set = new LinkedHashSet<>();
//优先搜索分割之前的关键字,以求最大匹配
List<Keyword> similarKeyword = kDao.findSimilarKeyword(word,limit);
set.addAll(kDao.findSimilarKeyword(word,limit));
//循环查找分割后的单词,直到超出返回条数的限制
for (String s : split) {
if(set.size()>=limit){
break;
}
set.addAll(kDao.findSimilarKeyword(s,limit));
}
List<Keyword> strings = new ArrayList<>(set);
limit=Math.min(limit,strings.size());
//由于subString无法序列化,所以构造一个新List来返回
ArrayList<Keyword> res = new ArrayList<>(strings.subList(0, limit));
return res;
}
/**
* 文章搜索接口,可同时查询标题和作者
* @param searchWord 关键词
* @param orderBy 排序方式,最相关或最新发布
* @param time 近n年文章
* @param meetId 会议id
* @param limit 返回条数限制
* @param page 分页时当前的页数
*/
@Cacheable(value = "searchPaper",
key="'paper_'+#searchWord+'_'+#orderBy+'_'+#time+'_'+#meetId+'_'+#page")
public Map<String,Object> searchPaper(String searchWord,Integer orderBy,Integer time,Integer meetId,Integer limit,Integer page){
Map<String, Object> resp = new HashMap<>();
List<Map<String,Object>> paperList= new ArrayList<>();
Date years = null;
//通过传入的time来生成查询的时间条件
if(time!=null){
int year = Calendar.getInstance().get(Calendar.YEAR);
year-=time;
try {
years = new SimpleDateFormat("yyyy").parse(String.valueOf(year));
} catch (ParseException e) {
e.printStackTrace();
}
}
//如果页数和限制条数不为空,就处理
Integer pages=null;
if(limit!=null&&page!=null){
pages=limit*page;
}
//传入dao查询
List<Paper> papers = pDao.findPaperByWord(searchWord, orderBy, years, meetId, limit, pages);
for (Paper paper : papers) {
Map<String, Object> node = new HashMap<>();
//通过文章id查对应的所有作者
List<Author> authors = new ArrayList<>(aDao.findAuthorByPaperId(paper.getId(),15));
//通过文章id查对应的关键词
List<Keyword> keywords = new ArrayList<>(kDao.findKeywordByPaperId(paper.getId(),null));
//封装数据
...
}
resp.put("paperList",paperList);
//获取当前查询结果的总条数
resp.put("count",service.searchPaperCount(searchWord,years,meetId));
return resp;
}
/**
* 用来统计当前搜索条件的总数据条数,方便前端分页
* 同样使用redis缓存,保证对应关键字的第一次请求会查询数据库
*/
@Cacheable(value = "searchPaper",
key="'paper_'+#searchWord+'_'+#publicationYears+'_'+#meetId")
public Integer searchPaperCount(String searchWord,Date publicationYears,Integer meetId){
return pDao.findPaperCountByWord(searchWord,publicationYears,meetId);
}
}
- mybatis配置文件
PaperMapper.xml
...
<mapper namespace="com.jdzy.papersearch.dao.PaperDao">
...
<!--searchPaper中调用的寻找文章的sql语句-->
<select id="findPaperByWord" resultType="com.jdzy.papersearch.pojo.Paper">
select * from paper
where (title like concat("%",concat(#{searchWord},"%"))
or paper.id in (<!--作者联表查询-->
select paper_id
from author,paper_author
where author.name like concat("%",concat(#{searchWord},"%"))
and author.id=paper_author.author_id
)
or paper.id in (<!--关键词联表查询-->
select paper_id
from keyword,paper_keyword
where keyword.keyword like concat("%",concat(#{searchWord},"%"))
and keyword.id=paper_keyword.keyword_id
))
<if test="publicationYears!=null">
and publication_year>=#{publicationYears}
</if>
<if test="meetId!=null">
and meet_id=#{meetId}
</if>
<if test="orderBy==1">
order by publication_year desc
</if>
<if test="page!=null and limit!=null">
limit #{page},#{limit}
</if>
</select>
...
</mapper>
部署方式
- 前端通过nodejs打包成。。。
- 后端通过maven打包成jar后直接在服务器上运行
- 通过nginx反向代理来解决跨域问题并启用负载均衡
nginx配置文件

- redis部署方式为主从模式,提升读写性能
master服务器

slave服务器

心路历程及收获
- 221801312
因为寒假学习了一点Vue,但是并没有经过项目实战,所以打算经过这次尝试一下,但还是不出所料的漏洞百出,甚至还出现了让我做后端的对友来帮助我解决前端的问题。在这次项目之前,我还没有经历过前后端交互的过程,通过这次结对,我大概了解了一些前后端交互的问题。最大的收获应该就是我自认为我正式入门了VUE,希望以后能够更加精进自己的技术。
- 221801337
这次作业是第一次把我寒假学习的知识运用到实战中。但是因为寒假学习中,我都是有照着书一步步实现的,所以这次基本上没有遇到什么问题。这次的收获就是对零散的知识的一次整合运用。
评价结对队友
- 221801312
正如我在心路历程写的一样,我的后端队友帮助我解决了一部分前端的问题,尽管他并没有学过Vue;我的对友是一个行动力很强的人,遇到的问题总是会第一时间去解决,他在各种问题的处理、学习方式以及面对BUG的态度等等等都有很多我要学习的地方。除了这些,最重要的还是他在技术的方面的强大,我完全不需要担心在后端数据库请求时的效率问题,因为他就是一个精益求精的人。
- 221801337
得益于回到了学校,我们可以一起线下讨论、debug,在讨论的过程中,感受到队友是一个行动力很强的人

 浙公网安备 33010602011771号
浙公网安备 33010602011771号