主成分分析法 PCA
此系列笔记来源于
Coursera上吴恩达老师的机器学习课程
主成分分析法 PCA
数据压缩
对于一个多维度的特征量,我们可以进行压缩,来使得数据量减少
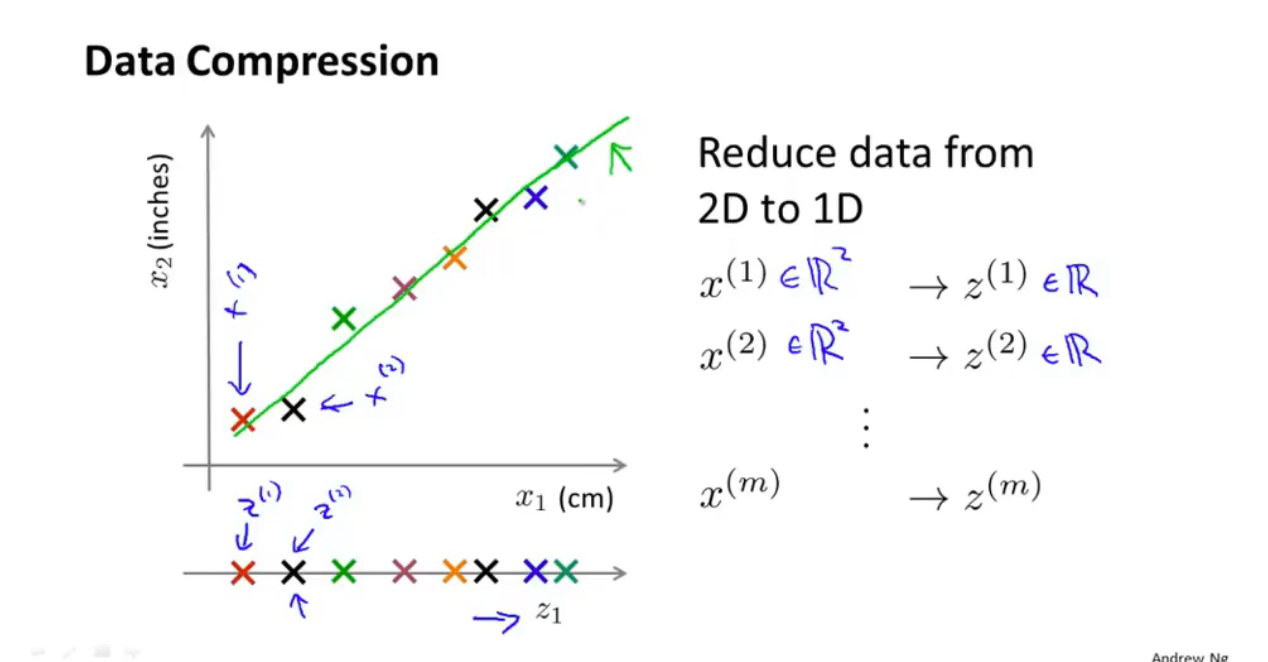
如:
数据可视化
对于下列数据,我们先将 \(\R^{50}\)变为了 \(\R^2\)
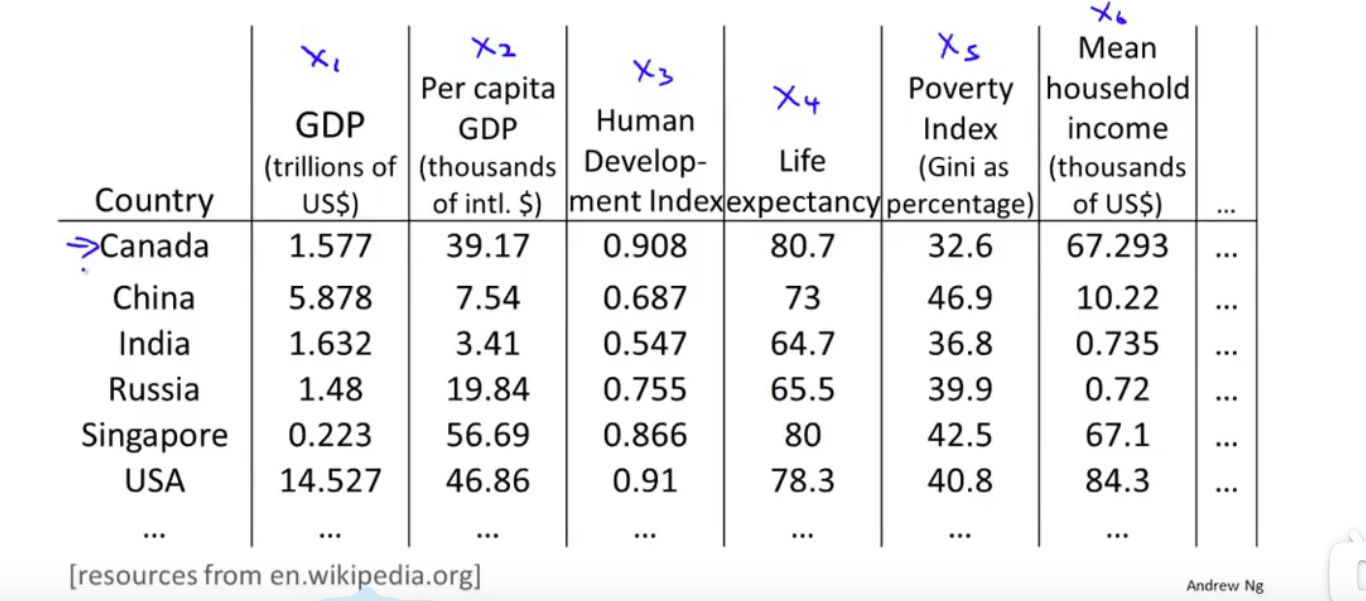
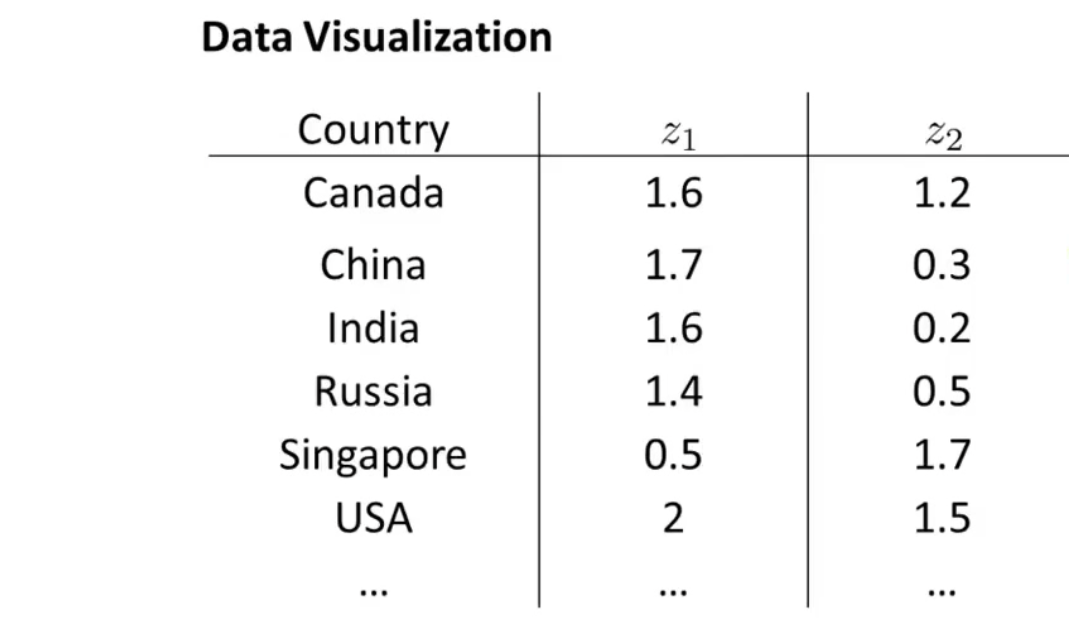
随后作图
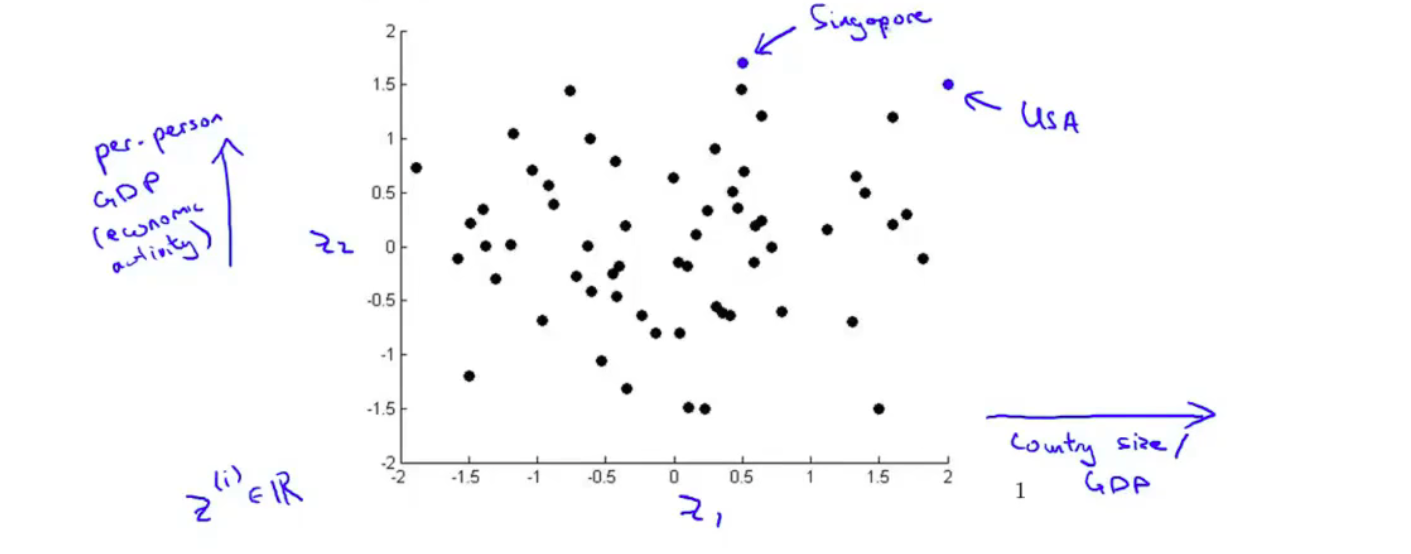
便能很清楚直观的了解到数据的一些信息
PCA
PCA的目的
PCA的目的就是去压缩数据或者可视化
在数据压缩时,如二维变为一维:
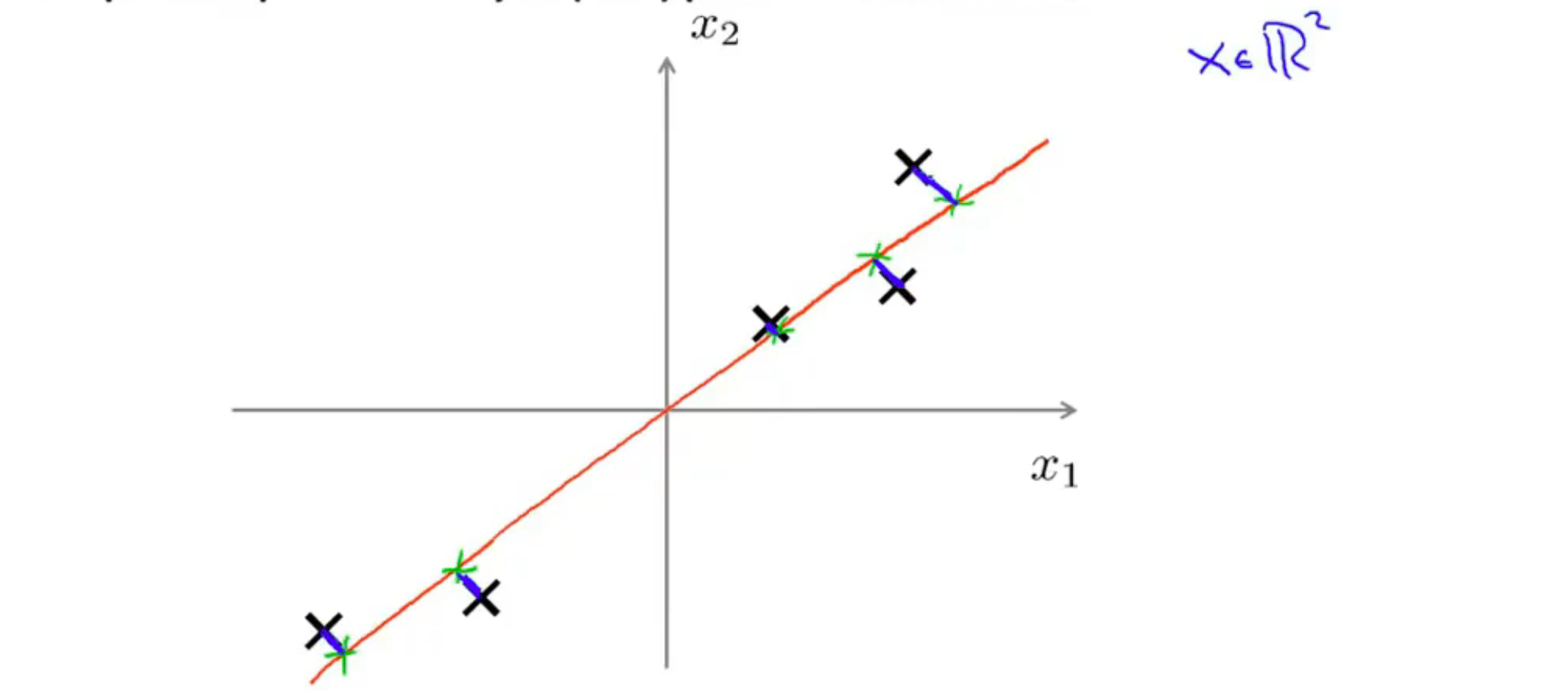 我们找到一个方向,即图中这条直线,随后将所有数据点投影到这条直线上。
我们找到一个方向,即图中这条直线,随后将所有数据点投影到这条直线上。
我们令这个垂直的投影距离,即蓝色线段为投影误差,而PCA所做的就是去寻找令数据压缩后投影误差最小的这个方向\向量
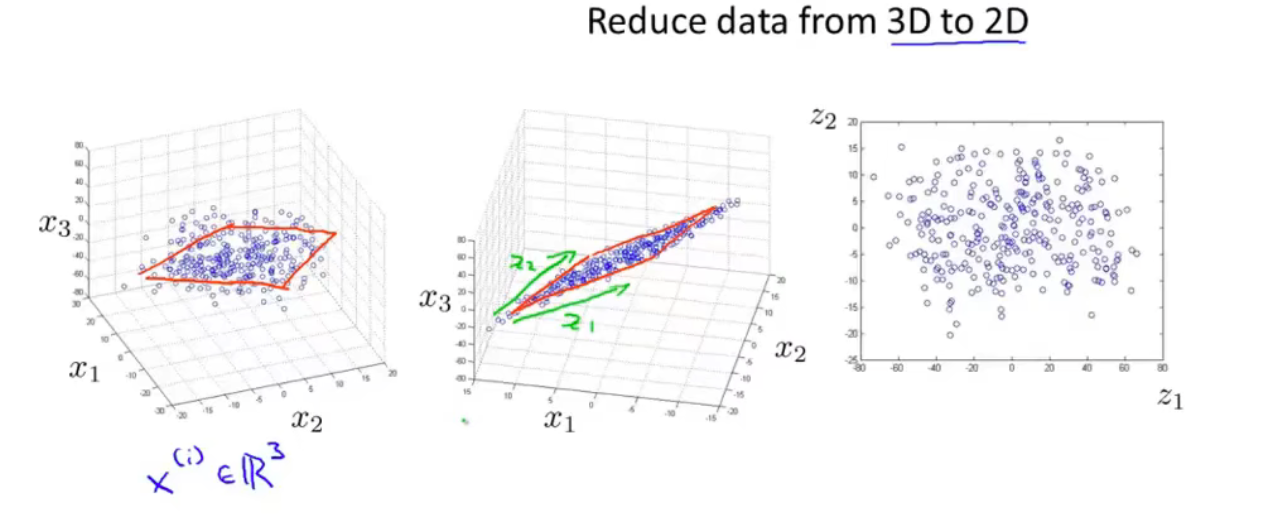
可以推广到更高维度

将n维压缩到k维,我们找到k个向量,能让数据投影到这些向量上后,整体投影误差之和最小
PCA算法过程
1、我们先计算协方差矩阵 \(\sum\)(注意与求和符号区分)
\(\sum=\frac{1}{m}X^TX\)
2、计算协方差矩阵的特征向量矩阵
这里可以调用函数 [U, S, V] = svd(Sigma); 而第一个U 即为我们所要的特征向量矩阵
假设我们要降到 k维,那么我只需选取前 k 个特征向量,并记为\(U_{reduce}\)
这 k 个向量便是我们新的特征
3、计算 z
假设原始数据为 \(x\),我们要将其变为 k维
\(z = U_{reduce}^Tx\)
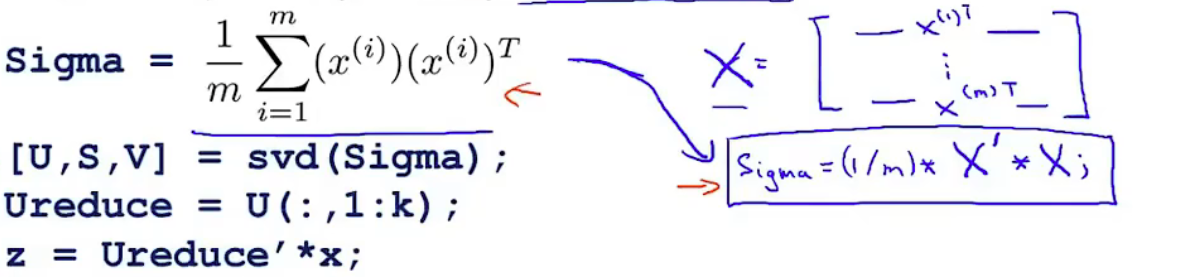
另外因为\(x\in\R^n\),所以\(x_0\ne1\)
压缩重建
在\(x\)转化为\(z\)后我们同样可以转化回去
\(x_{approx}=U_{reduce}z,\;x_{approx}\approx x\)
选择主成分的数量 k
PCA是为了最小化平均平方映射误差 \(\frac{1}{m}\sum_{i=1}^{m}||x^{(i)}-x^{(i)}_{approx}||^2\)
另外定义数据的总变差 Total variation: \(\frac{1}{m}\sum_{i=1}^m||x^{(i)}||^2\)
我们要选择 最小的一个k,能满足:
\(\frac{\frac{1}{m}\sum_{i=1}^{m}||x^{(i)}-x^{(i)}_{approx}||^2}{\frac{1}{m}\sum_{i=1}^m||x^{(i)}||^2}\le0.01\;(1\%)\)
用PCA的语言来说就是保留了99%的差异性
如果是 \(\le0.05\;(5\%)\)
那么就是保留了95%的差异性
算法过程:

也就是遍历 k 从1开始,对于每个k 计算对应的数值然后看看是否满足下面的式子。但是这样的效率是十分低的。
我们用其他方法做:
1、[U, S, V] = svd(sigma)
2、这里的 S 是一个对角矩阵 \(diag(S_{11},\;S_{22},\;\cdots,\;S_{nn})\)
Check的式子可以等价为 \(1-\frac{\sum_{i=1}^kS_{ii}}{\sum_{i=1}^nS_{ii}}\le0.01\)
因此只需要逐渐增加k,并检查是否满足 \(\frac{\sum_{i=1}^kS_{ii}}{\sum_{i=1}^nS_{ii}}\ge0.99\)
加速学习算法
我们可以利用PCA 通过压缩数据的方法来加速算法
已知训练集 training set
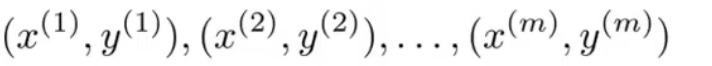
我们先使用PCA来对训练集降维(不能对cv集 和 test集使用)

得到新训练集
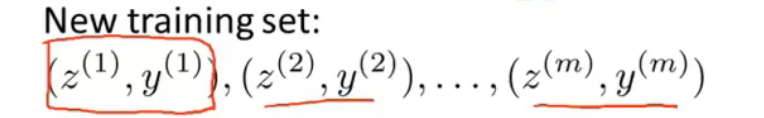
训练集上的\(x^{(i)} \rightarrow z^{(i)}\)的映射关系 可以再用于cv集 和 test集
完成降维后,对新的数据集再运行原来的学习算法即可
PCA的应用

PCA的不恰当使用
1、用PCA去解决 过度拟合overfitting问题,更合适的方法是正则化
2、在设计一个机器学习系统前,我们不应该直接就将PCA列入步骤,如果不使用PCA,系统也能运行的话,那么PCA根本没有必要。而应当在运行速率较慢等问题下,再去运用PCA解决问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号