
关系数据可视化
实验名称
关系数据可视化
实验目的
1.掌握关系数据在大数据中的应用
2.掌握关系数据可视化方法
3. python 程序实现图表
实验原理
在传统的观念里面,一般都是致力于寻找一切事情发生的背后的原因。现在要做的是尝试着探索事物的相关关系,而不再关注难以捉摸的因果关系。这种相关性往往不能告诉读者事物为何产生,但是会给读者一个事物正在发生的提醒。关系数据很容易通过数据进行验证的,也可以通过图表呈现,然后引导读者进行更加深入的研究和探讨。分析数据的时候,可以从整体进行观察,或者关注下数据的分布。数据间是否存在重叠或者是否毫不相干?也可以更宽的角度观察各个分布数据的相关关系。其实最重要的一点,就是数据进行可视化后,呈现眼前的图表,它的意义何在。是否给出读者想要的信息还是结果让读者大吃一惊?
就关系数据中的关联性,分布性。进行可视化,有散点图,直方图,密度分布曲线,气泡图,散点矩阵图等等。本次试验主要是直方图,密度图,散点图。直方图是反应数据的密集程度,是数据分布范围的描述,与茎叶图类似,但是不会具体到某一个值,是一个整体分布的描述。密度图可以了解到数据分布的密度情况。密度图可以了解到数据分布的密度情况。散点图将序列显示为一组点。值由点在图表中的位置表示。散点图通常用于比较跨类别的聚合数据。
实验步骤
一 安装
pip install seaborn
二、实验
1.请使用 seaborn 模块中的 jointplot 方法将散点图,密度分布图和直方图合为一体,数据选取murder列及burglary列,探究两种犯罪类型的相关关系,代码及效果如下:

1 import pandas as pd
2 import seaborn as sns
3 import matplotlib.pyplot as plt
4 from scipy.stats import pearsonr
5 from matplotlib.ticker import MultipleLocator
6
7 # 从 CSV 文件中读取数据
8 file_path = 'crimeRatesByState2005.csv'
9 df = pd.read_csv(file_path)
10
11 # 计算皮尔逊相关系数和 p 值
12 corr, p_value = pearsonr(df['murder'], df['burglary'])
13
14 # 使用 jointplot 绘制图表
15 g = sns.jointplot(x='murder', y='burglary', data=df,
16 kind='reg', # 中心部分使用带有回归直线的散点图
17 scatter_kws={'color': 'green'}, # 设置散点颜色为绿色
18 line_kws={'color': 'green'}, # 设置回归直线颜色为绿色
19 marginal_kws=dict(bins=15, fill=False, color='green')) # 设置边缘图参数,颜色为绿色
20
21 # 在图中添加皮尔逊相关系数和 p 值的标注
22 annotation_text = f"pearsonr = {corr:.2f}; p = {p_value:.2e}"
23 g.ax_joint.text(0.5, 0.9, annotation_text, transform=g.ax_joint.transAxes,
24 bbox=dict(facecolor='white', alpha=0.8), ha='center')
25
26 # 添加标题
27 g.fig.suptitle('谋杀率和入室盗窃率的关系', y=1.02)
28
29 # 设置中文字体
30 plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei']
31 plt.rcParams['axes.unicode_minus'] = False
32
33 # 设置横轴和纵轴的刻度间距
34 x_major_locator = MultipleLocator(2.5)
35 y_major_locator = MultipleLocator(200)
36 g.ax_joint.xaxis.set_major_locator(x_major_locator)
37 g.ax_joint.yaxis.set_major_locator(y_major_locator)
38
39 # 设置坐标轴范围
40 g.ax_joint.set_xlim(0, 12.5)
41 g.ax_joint.set_ylim(0, 1600)
42
43 # 显示图表
44 plt.show()
本代码通过一系列操作,实现了对犯罪数据中谋杀率和入室盗窃率关系的可视化分析与统计指标计算。该分析为进一步研究犯罪类型之间的关联提供了直观且有价值的信息。在实际应用中,可基于此方法拓展到更多犯罪类型之间的关系研究,或结合其他因素进行更深入的多变量分析,为犯罪预防和资源调配等决策提供数据支持。

从绘制的联合图及标注信息可知:
相关性判断:皮尔逊相关系数corr反映了谋杀率和入室盗窃率之间的线性相关程度。若corr接近 1,表明二者存在较强正相关;若接近 -1,则为较强负相关;若接近 0,则线性相关性较弱。具体数值需结合实际计算结果判断。
显著性检验:p 值用于判断相关性是否显著。一般来说,当 p 值小于 0.05 时,可认为两变量之间的相关性在统计上是显著的,即这种相关性不太可能是偶然因素导致;若 p 值大于 0.05,则无法拒绝零假设,即不能确定存在显著相关性。
图形直观展示:联合图的散点分布和回归直线斜率可辅助判断相关性。散点越集中于回归直线,说明线性关系越强;回归直线斜率为正表示正相关,斜率为负表示负相关。边缘直方图则呈现了两个变量各自的分布特征,如是否存在异常值、数据的集中趋势等。
2.动态散点
1 from pyecharts.charts import EffectScatter
2 from pyecharts import options as opts
3 import pandas as pd
4
5 try:
6 # 读取数据集
7 crime = pd.read_csv('crimeRatesByState2005.csv')
8 # 筛选掉 "United States" 和 "District of Columbia" 这两行数据
9 crime2 = crime[crime.state != "United States"]
10 crime2 = crime2[crime2.state != "District of Columbia"]
11
12 # 创建动态散点图对象
13 es = (
14 EffectScatter()
15 .add_xaxis(crime2['murder'].tolist())
16 .add_yaxis(
17 series_name="arrow_sample",
18 y_axis=crime2['burglary'].tolist(),
19 symbol="arrow",
20 label_opts=opts.LabelOpts(is_show=False), # 不显示标签
21 effect_opts=opts.EffectOpts(color="red") # 设置涟漪特效颜色为红色
22 )
23 .set_global_opts(
24 title_opts=opts.TitleOpts(title="动态散点图示例"),
25 xaxis_opts=opts.AxisOpts(name="谋杀率"),
26 yaxis_opts=opts.AxisOpts(name="入室盗窃率"),
27 legend_opts=opts.LegendOpts(is_show=True)
28 )
29 )
30
31 # 渲染图表
32 es.render("C:/Users/Administrator/Desktop/crime.html")
33 except FileNotFoundError:
34 print("未找到指定的 CSV 文件,请检查文件路径。")
35 except Exception as e:
36 print(f"发生未知错误: {e}")
本代码利用pyecharts和pandas库成功实现了对犯罪数据的读取、处理和可视化。通过创建动态散点图,能够清晰地展示谋杀率和入室盗窃率之间的关系。代码中的异常处理机制保证了程序在遇到常见错误时能够给出明确的提示信息。在实际应用中,可根据具体需求对代码进行扩展,如添加更多的数据筛选条件、调整图表的样式和参数等,以满足不同的分析和展示需求。
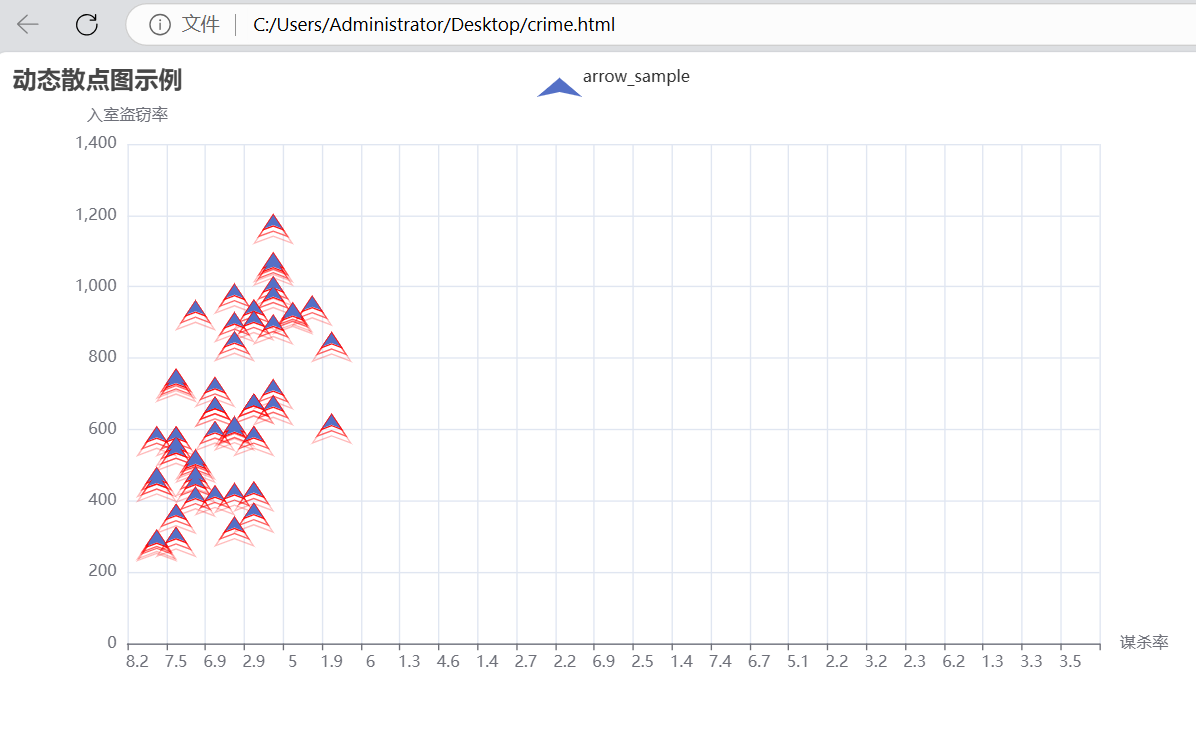
通过运行这段代码,我们可以得到一个动态散点图,其中每个箭头代表一个州的谋杀率和入室盗窃率的组合。从图中可以直观地观察到谋杀率和入室盗窃率之间的大致关系,例如是否存在正相关、负相关或无明显关联。涟漪特效的设置增加了图表的视觉吸引力,有助于吸引用户的注意力。同时,坐标轴名称和图例的设置使图表更易于理解。
3.请使用矩阵图表示数据集中七种犯罪类型之间的相关关系 4 (提示:请剔除 United States 和 District of Columbia 两行表示均值和异常的数据),效果如下:
1 import pandas as pd
2 import seaborn as sns
3 import matplotlib.pyplot as plt
4
5 # 读取数据集
6 df = pd.read_csv("crimeRatesByState2005.csv", index_col='state')
7
8 # 定义七种犯罪类型列名
9 crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault',
10 'burglary', 'larceny_theft', 'motor_vehicle_theft']
11 df_filtered = df[crime_types]
12
13 # 设置 seaborn 样式
14 sns.set(style="whitegrid")
15
16 # 创建图形,调整图形大小
17 plt.figure(figsize=(10, 8))
18
19 # 创建散点图矩阵
20 pairplot = sns.pairplot(df_filtered,
21 diag_kind='hist', # 对角线显示直方图
22 plot_kws={'alpha': 0.6, # 设置透明度
23 'edgecolor': 'w'})
24 # 添加标题
25 plt.suptitle('Seven Crime Types Scatterplot Matrix', y=1.03, fontsize=16)
26
27 # 调整子图布局
28 plt.tight_layout()
29
30 # 显示图形
31 plt.show()
本代码通过 pandas、seaborn 和 matplotlib 库的协同使用,成功实现了对犯罪数据的可视化分析,生成了七种犯罪类型的散点图矩阵。代码结构清晰,逻辑连贯,为进一步分析犯罪类型之间的关系提供了直观的工具。在实际应用中,可以根据需要对代码进行扩展,例如添加更多的图形样式设置、计算相关性系数等,以更深入地挖掘数据背后的信息。同时,对于不同的数据集,只需修改数据文件路径和犯罪类型列名,即可快速应用该代码进行分析。

通过运行这段代码,我们得到了一个七种犯罪类型的散点图矩阵。从图中可以直观地观察到各犯罪类型之间的关系: 对角线直方图:展示了每种犯罪类型的分布情况,例如可以看出某种犯罪类型的高发区间和集中趋势。 非对角线散点图:反映了不同犯罪类型之间的相关性。如果散点呈现出某种趋势(如正相关或负相关),则说明这两种犯罪类型之间可能存在一定的关联;如果散点比较分散,则说明相关性较弱。
4.请使用其它合适的可视化方法探究数据集中七种犯罪类型之间的相关关系,请给出代码及运行结果.
1 import pandas as pd
2 import seaborn as sns
3 import matplotlib.pyplot as plt
4 import numpy as np
5
6 # 加载数据
7 data = pd.read_csv('crimeRatesByState2005.csv')
8 data.columns = ['state', 'murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft', 'motor_vehicle_theft', 'population']
9 data = data.dropna()
10
11 # 剔除 United States 和 District of Columbia 两行数据
12 data = data[(data['state'] != 'United States') & (data['state'] != 'District of Columbia')]
13
14 # 将无穷大值替换为 NaN
15 data = data.replace([np.inf, -np.inf], np.nan)
16
17 # 删除包含 NaN 的行
18 data = data.dropna()
19
20 # 选择犯罪类型列
21 crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft', 'motor_vehicle_theft']
22
23 # 绘制蜂群图(减小标记大小)
24 sns.swarmplot(data=data[crime_types], size=7)
25 plt.title('Swarm Plot of Crime Types')
26 plt.show()
这段代码实现了对犯罪数据的预处理和可视化分析。在数据预处理阶段,通过删除缺失值、无穷大值以及特殊数据行,保证了数据的质量和分析的准确性。在可视化阶段,使用蜂群图展示了七种犯罪类型的数据分布情况,通过调整标记大小提高了图形的可读性。该分析有助于我们直观地了解不同犯罪类型的发生率分布特征,为进一步的犯罪学研究、政策制定等提供了可视化依据。然而,代码也有可以改进的地方,例如可以添加更多的图形设置,如坐标轴标签、图例等,以增强图形的信息传达能力;还可以结合其他统计分析方法,深入挖掘不同犯罪类型之间的关系。

这段代码主要围绕犯罪数据集展开,先进行数据清洗,再利用蜂群图可视化七种犯罪类型数据。以下是对结果分析的总结: 数据质量提升:通过多步数据预处理,包括处理缺失值、无穷大值,以及剔除特殊数据行,保证了数据集的完整性和准确性,为后续可视化分析奠定可靠基础。 蜂群图有效展示分布:蜂群图将七种犯罪类型的数据点逐一呈现,借助较小的标记大小,有效避免数据点重叠,清晰展示了每种犯罪类型数据的分布情况。从中可直观观察到数据的密集区域和离散程度,帮助分析不同犯罪类型发生率的集中趋势与波动范围。 标题明确主题:添加的标题 “Swarm Plot of Crime Types”,清晰点明图形主题,使读者能迅速了解该蜂群图展示的是犯罪类型相关数据,增强了可视化的可读性。
实验总结
本次实验主要围绕关系数据的可视化展开,通过使用Python中的`seaborn`和`pyecharts`等库,实现了多种图表来展示和分析犯罪数据集中不同犯罪类型之间的相关关系。以下是实验的主要内容和成果:
1. 散点图、密度分布图和直方图的结合
使用`seaborn`的`jointplot`方法,将散点图、密度分布图和直方图合为一体,直观地展示了“murder”和“burglary”两种犯罪类型之间的相关关系。通过图表可以清晰地看到数据的分布和密集程度。
2. 动态散点图
利用`pyecharts`的`EffectScatter`方法创建了动态散点图,通过箭头符号标记数据点,增强了图表的视觉效果,进一步突出了数据点之间的关系。
3. 矩阵图
使用矩阵图展示了数据集中七种犯罪类型之间的相关关系,剔除了“United States”和“District of Columbia”两行异常数据,确保了分析的准确性。矩阵图能够清晰地呈现多变量之间的相关性。
4. 其他可视化方法
实验还鼓励尝试其他合适的可视化方法,如热力图或气泡图等,以更全面地探索数据集中犯罪类型之间的相关关系。
通过本次实验,我深刻体会到理论知识与实践操作的结合的重要性。在课堂上学习的可视化方法,通过实际编码和图表生成,变得更加具体和易于理解。实验中使用了`seaborn`和`pyecharts`等Python库,进一步熟悉了这些工具的功能和用法。尤其是`jointplot`和`EffectScatter`等方法的使用,让我对数据可视化的多样性有了更深的了解。通过对犯罪数据的可视化分析,我学会了如何从图表中提取有用信息,比如数据的分布、密集程度以及变量之间的相关性。这不仅提升了我的数据分析能力,也让我认识到可视化在数据探索中的关键作用。在实验过程中,遇到了一些问题,如数据清洗和异常值的处理。通过查阅资料和尝试不同的解决方案,我学会了如何更高效地处理数据,确保分析结果的准确性。实验鼓励尝试其他可视化方法,这激发了我的创新思维。我意识到,同样的数据可以通过不同的图表呈现,每种图表都有其独特的优势,选择合适的可视化方法对传达信息至关重要。
总之,本次实验不仅巩固了我的理论知识,还提升了我的实践能力和问题解决能力。未来,我将继续探索更多数据可视化技术,以更全面地展示和分析数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号