linux awk 使用
2014-02-10 20:20 youxin 阅读(469) 评论(0) 收藏 举报awk是linux下的一个命令,他对其他命令的输出,对文件的处理都十分强大,其实他更像一门编程语言,他可以自定义变量,有条件语句,有循环,有数组,有正则,有函数等。他读取输出,或者文件的方式是一行,一行的读,根据你给出的条件进行查找,并在找出来的行中进行操作,感觉他的设计思想,真的很简单,但是结合实际情况,具体操作起来就没有那么简单了。他有三种形势,awk,gawk,nawk,平时所说的awk其实就是gawk。
awk: gawk - pattern scanning and processing language
与sed一样,均是一行一行的读取,处理
sed作用于一整行的处理,而awk将一行分成数个字段来处理
字段:一段字符串 --》一段很多字符组成了一个字符串
Usage: awk [POSIX or GNU style options] -f progfile [--] file ...
Usage: awk [POSIX or GNU style options] [--] 'program' file ...
POSIX options: GNU long options: (standard)
-f progfile --file=progfile
-F fs --field-separator=fs
-v var=val --assign=var=val
Short options: GNU long options: (extensions)
-b --characters-as-bytes
-c --traditional
-C --copyright
-d[file] --dump-variables[=file]
-e 'program-text' --source='program-text'
-E file --exec=file
-g --gen-pot
-h --help
-L [fatal] --lint[=fatal]
-n --non-decimal-data
-N --use-lc-numeric
-O --optimize
-p[file] --profile[=file]
-P --posix
-r --re-interval
-S --sandbox
-t --lint-old
-V --version
To report bugs, see node `Bugs' in `gawk.info', which is
section `Reporting Problems and Bugs' in the printed version.
gawk is a pattern scanning and processing language.
By default it reads standard input and writes standard output.
Examples:
gawk '{ sum += $1 }; END { print sum }' file
gawk -F: '{ print $1 }' /etc/passwd
-F sepstring
Define the input field separator. This option shall be
equivalent to:
-v FS=sepstring
except that if -F sepstring and -v FS=sepstring are
both used, it is unspecified whether the FS assignment
resulting from -F sepstring is processed in command
line order or is processed after the last -v
FS=sepstring. See the description of the FS built-in
variable, and how it is used, in the EXTENDED
DESCRIPTION section.
按列求和:
在Shell中,我们可以用awk实现按列求和的功能,非常简单。看下面的例子:
1.简单的按列求和
[linux@test /tmp]$ cat test |
123.52
125.54
126.36
[linux@test /tmp]$ awk '{sum += $1};END {print sum}' test |
375.42
2.对符合某些条件的行,按列求和
[linux@test /tmp]$ cat test |
aaa 123.52
bbb 125.54
aaa 123.52
aaa 123.52
ccc 126.36
对文件test中 第一列为aaa的行求和
[linux@test /tmp]$ awk '/aaa/ {sum += $2};END {print sum}' test |
370.56
更多:
http://heikezhi.com/yuanyi/why-you-should-know-just-little-awk
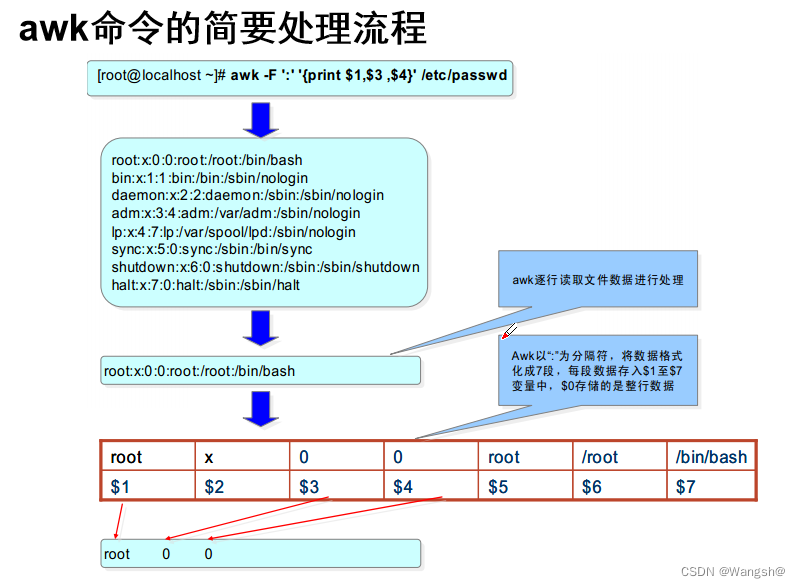
awk完整语法
awk ‘BEGIN {commands} pattern {commands}END{commands}' file1
BEGIN:处理数据前执行的命令
END:处理数据后执行的命令
pattern:模式,每一行都执行的命令
BEGIN和END里的命令只是执行一次
pattern里的命令会匹配每一行去处理
————————————————
原文链接:https://blog.csdn.net/qq_48391148/article/details/125602640
grep -e 适用于简单的正则表达式,比如搜索一个字符串中是否包含特定的关键词。例如:
grep -e 'hello' file.txt
# 将会在文件file.txt中搜索出所有包含“hello”这个关键词的行。
grep -E 则适用于复杂的正则表达式,可以使用多项选择、重复和子表达式来匹配文本。例如:
grep -E '(foo|bar)baz' file.txt
#会在文件file.txt中搜索出所有包含“foobaz”或者 “barbaz” 的行。
链接:https://blog.csdn.net/dgwxligg/article/details/129189848
awk常用命令
3.1 awk查看某个时间段的日志
awk ‘/^开始时间日期/,/^结束时间日期/’ nginx.log
awk支持正则表达式,比如,查询时间段2021-03-24 10:12:12 到 2021-09-24 10:12:12,
可以用awk ‘/^2021-03-24 10:12:*/,/^2021-09-24 10:12:*/’ nginx.log查询。awk 中 分号 和 逗号的区别:
话不多说,直接举例:
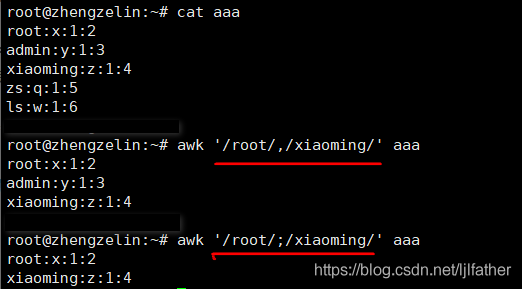
由图可知:
,(逗号) 表示的是一个范围,就是逗号前到逗号后作为一个范围。
;(分号) 表示的是隔开,分号前 和 分号后 没有联系。
统计命令
# 求和
cat data|awk '{sum+=$1} END {print "Sum = ", sum}'
# 求平均
cat data|awk '{sum+=$1} END {print "Average = ", sum/NR}'
# 求最大值
cat data|awk 'BEGIN {max = 0} {if ($1>max) max=$1 fi} END {print "Max=", max}'
# 求最小值(min的初始值设置一个超大数即可)
awk 'BEGIN {min = 1999999} {if ($1<min) min=$1 fi} END {print "Min=", min}'awk 内置变量表

5.3.3 [...]
中的
\ 转义(awk中使用)
- 表示范围。例如[0-9]包含任何数字
^ 取反。例如[^0-9]不匹配数字。注意在grep中是使用grep –v来取反
grep ‘^[0-9]‘ /etc/inittab 查出以数字开头的行
grep ‘[a-Z]‘ /etc/inittab 查出有字母(大小通用)的行
grep ‘^[^0-9]‘ /etc/inittab ^[^ ]取反的
grep ‘x:[0-9][0-9]:’ /etc/passwd 取出UID为0-99的用户
ls -l /dev |grep ‘tty[0-9]*$’ (*多个或0个前面的字符)
5.3.4 ^
^n - 以n开头的行
5.3.5 $
从行尾开始任务。
注意:在sed和grep中^和$并不一定总保持着自己的个性。当使用ab^c 或者是ab$c匹配时它们就确实代表着字面意思,没有任何别的含义。但在awk中则不同,^和$永远保持着自己的个性,所以在awk中如果要匹配它俩时都需要使用\来转义。
5.3.6 \{n,m\}
101
1001
10001
100001
10000001
100000001
这时候想把1001,10001,100001过滤出来。
# grep “10\{2,4\}1″ file
1001
10001
100001
1001中有2个0,100001中有4个0,所以这个大家应该明白了吧?
5.3.7 \
转义符。取消字符的特殊效果。比如我要匹配文件中的5.6。这时候我需要这样写
# grep ’5\.6′ file
5.6
如果写成
grep ’5.6′ file
5.6
506
则列出了5.6和506。
shell除法:
A=expr $num1 / $num2
这个时候num3=0 ,是因为是因为expr不支持浮点除法
小数点标识的方法:
num3=`echo "scale=2; $num1/$num2" | bc`
echo "num1/num2=$num3"
1
2
使用bc工具,scale控制小数点后保留几位
另一种方法
awk 'BEGIN{printf "%.2f\n",’$num1‘/’$num2‘}'
https://zhuanlan.zhihu.com/p/518549290
https://zhuanlan.zhihu.com/p/518549290
https://blog.csdn.net/ljlfather/article/details/104530474/
*awk命令
1、例如查询今天14:10:10 到14:12:59区间的日志,注意时间要用引号
|
1
|
awk '$2>"14:10:10" && $2<"14:12:59"' dubbo-elastic-job.log |
注意参数$1和$2的取值,我这里$1是指年月日,$2是指时分秒。
awk用法之:文本替换
awk的sub/gsub函数用来替换字符串,其语法格式是:
sub(/regexp/, replacement, target)
注意第三个参数target,如果忽略则使用$0作为参数,即整行文本。
- 例子1:替换单个串
只把每行的第一个AAAA替换为BBBB
awk '{ sub(/AAAA/,"BBBB"); print $0 }' t.txt
- 例子2:替换所有的串
把每一行的所有AAAA替换为BBBB
awk '{ gsub(/AAAA/,"BBBB"); print $0 }' t.txt
- 例子3:替换满足条件的行的串
只在出现字符串CCCC的前提下,将行中所有AAAA替换为BBBB
awk '/CCCC/ { gsub(/AAAA/,"BBBB"); print $0; next }
{ print $0 }
' t.txt
- 例子4:替换多个可选串
不管是AAAA,还是CCCC,全部替换为BBBB
awk '{ gsub(/AAAA|aaaa/,"BBBB"); print $0 }' t.txt
- 例子5:全字匹配替换
全字匹配AAAA;即不匹配AAA,以及AAAAA,也就是说完整的四个字符串AAAA。
awk '{ sub(/\<AAAA\>/,"BBBB"); print $0 }' t.txt
- 例子6:规则表达式匹配
把所有以A开头,不管后面连续包含几个A的串替换成一个字符B。
awk '{ gsub(/^A*/,"B"); print $0 }' t.txt作者:CodingCode
链接:https://www.jianshu.com/p/d90f8a2ecd62
gsub函数则使得在所有正则表达式被匹配的时候都发生替换
gsub(regular expression, subsitution string, target string);简称 gsub(r,s,t)
sub匹配第一次出现的符合模式的字符串,相当于 sed ‘s//’ 。
gsub匹配所有的符合模式的字符串,相当于 sed ‘s//g’
实例一
将|分割第二个域中的数字去掉
$ awk '{ gsub(/test/, "mytest"); print }' testfile
$ awk '{ gsub(/test/, "mytest", $1); print }' testfile
0001|efskjfdj|EREADFASDLKJCV
实例二
/分割,取出snapshots后面知道倒数第四个之间的域(其中/的数不确定,所以不大方便直接使用awk 6,
6
,
7,$8来直接取,使用字段截取),.隔开 com.netfinworks.authorize
示例
/Users/yfan/Downloads/dsc20170801_jar/snapshots/com/netfinworks/authorize/authorize-service/1.0.0-SNAPSHOT/authorize-service-1.0.0-SNAPSHOT.jar
1
先设置一个变量
yfandeMacBook-Pro:pbs yfan$ test=/Users/yfan/Downloads/dsc20170801_jar/snapshots/com/netfinworks/authorize/authorize-service/1.0.0-SNAPSHOT/authorize-service-1.0.0-SNAPSHOT.jar
1
用Linux中的符号截断(##)去掉com前面的部分
yfandeMacBook-Pro:pbs yfan$ echo ${test##*snapshots/}
1
结果
com/netfinworks/authorize/authorize-service/1.0.0-SNAPSHOT/authorize-service-1.0.0-SNAPSHOT.jar
1
在用awk结合gsub去掉后面的部分(倒数第一、第二、第三域)
yfandeMacBook-Pro:pbs yfan$ echo ${test##*snapshots/}|awk -F'/' '{gsub("/"$(NF-2)"/"$(NF-1)"/"$NF,"");print}'
1
结果
com/netfinworks/authorize
1
最后再用sed用.替换/,完成目标
yfandeMacBook-Pro:pbs yfan$ echo ${test##*snapshots/}|awk -F'/' '{gsub("/"$(NF-2)"/"$(NF-1)"/"$NF,"");print}'|sed 's/\//./g'
1
结果
com.netfinworks.authorize
1
gsub说明参考:
http://blog.sina.com.cn/s/blog_67e34ceb0100ybvg.html
原文链接:https://blog.csdn.net/fyl_1024/article/details/78105597

 浙公网安备 33010602011771号
浙公网安备 33010602011771号