
第一次个人编程作业
| 这个作业属于哪个课程 | 2021软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 明确自己的目标,规划未来 |
| 其他参考文献 | 无 |
作业基本信息...
第一次个人编程作业
作业gitcode链接:[https://gitcode.net/2302_78125335/3121008942]
一.psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 15 |
| Estimate | 估计这个任务需要多少时间 | 16 | 23 |
| Development | 开发 | 60 | 67 |
| Analysis | 需求分析 (包括学习新技术) | 90 | 125 |
| Design Spec | 生成设计文档 | 10 | 25 |
| Design Review | 设计复审 | 20 | 47 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 74 |
| Design | 具体设计 | 180 | 205 |
| Coding | 具体编码 | 50 | 65 |
| Code Review | 代码复审 | 60 | 78 |
| Test | 测试(自我测试,修改代码,提交修改) | 70 | 108 |
| Reporting | 报告 | 15 | 25 |
| Test Repor | 测试报告 | 10 | 20 |
| Size Measurement | 计算工作量 | 1600 | 2545 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 56 |
| 合计 | 2,251 | 3,478 |
二.计算模块接口的设计与实现过程
设计理念:
1.utf-8是不定长编码,当文本遇到不是3个字节的字符时,将这个字符作为3个字符存入char数组,少的字节补0。(由get_scentce()函数实现)
例如:*的utf8编码为42,只占一个字节。写入数组写成:42,0,0
2.实现比对一句,因为发现盗文的句子与原文的句子是一一对应的,只要能定位到相同的句子进行比对,就能避免检测出界的情况。
并且,盗文中不存在有语义,而是由乱的字拼凑出的句子,不用考虑语义重复和单词分割的问题。能将相似度转为相同句子的重复字数/盗文的总字数。(由chinese_compare()函数实现)
算法流程图: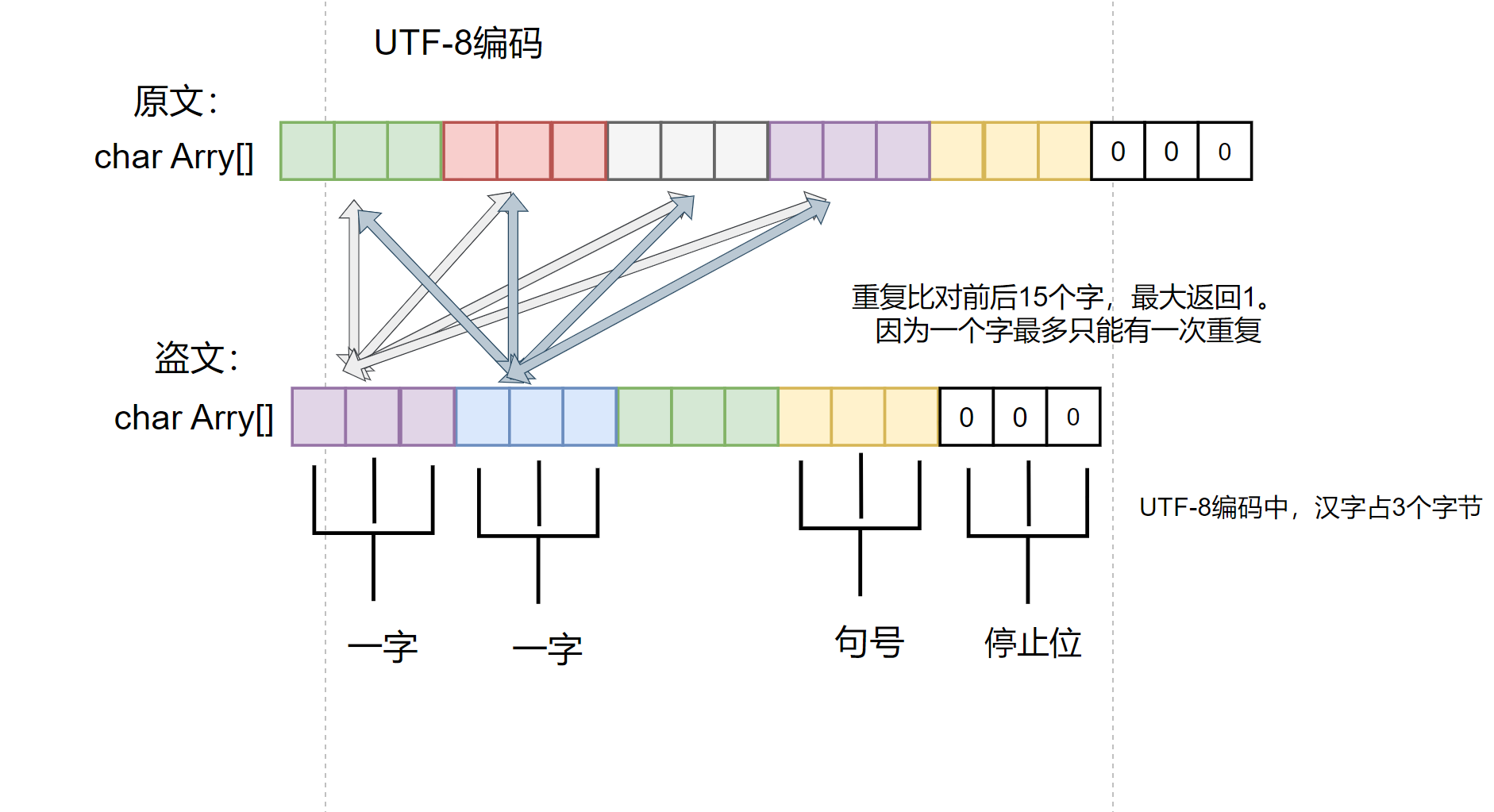
三.计算模块接口部分的性能改进
计算模块对于不是句子的文本,或者是没有句子的,句子超过200个字的会计算错误。对于这部分可以采用python高级语言处理,底层再用C写,能让程序适应性更强。
四.计算模块部分单元测试展示
(1)used层调试 取句子测试
点击查看代码
#include<stdio.h>
#include<stdlib.h>
#include <string.h>
#include"block.h"
#include"used.h"
#include"math.h"
int i;
int num;
char buffer[600];
int main(int arg,char*argv[])
{
//前面的模块已验证
checkinit();
num=get_filesize(argv[1]);
//Test测试
for(i=0;i<10;i++)
{
memset(buffer, 0, sizeof(buffer));
Test_used(argv[1],num,buffer);
Test_printf(buffer);
}
return 0;
}
结果:
十个测试句子都能打印,经测试文章能覆盖到最后一句,但是对于某些没有中文句号或者换行号的文章会无法读出,因为不是一个完整的句子。
异常处理:在函数中已经设置了读取超过文件大小会自动停止
(2)math层调试 对每个句子进行重复字查询
由于math是最顶层的模块,下层的模块已测试。故测试最顶层的模块就是对整个程序进行测试。直接使用main.c
点击查看代码
//命令行格式
path>论文查重.exe D:\\Orig.txt D:\\orig_0.8_add.txt D:\\ans.txt
#include<stdio.h>
#include<stdlib.h>
#include <string.h>
#include"block.h" //初始化层
#include"used.h" //底层封装层
#include"math.h" //算法层
#include"write.h" //写入层
#define Path1 "D:\\Orig.txt"
#define Path2 "D:\\360Downloads\\orig_0.8_add.txt"
#define Path3 "D:\\ans.txt"
int i;
char buffers1[600]; //存放原文一个句子的数组,默认没有超200字的一句
char buffers2[600]; //存放盗文一个句子的数组,默认没有超200字的一句
int sec1; //原文每一个句子长度 ,包括句号
int sec2; //盗版每一个句子长度 ,包括句号
int rec; //重复字数,包括句号
int total_1; // 原文总字数, 包括句号
int total_2; // 盗文总字数 ,包括句号
float recs; //重复度 = 重复字数/盗文总字数 ,句号也算重复,纳入计算。
int get_scentces1(const char* Filename,int size,char*buffer1)
{
int num;
memset(buffers1, 0, sizeof(buffers1));
num = get_scentce_1(Filename,size,buffer1);
return num;
}
int get_scentces2(const char* Filename,int size,char*buffer2)
{
int num;
memset(buffers2, 0, sizeof(buffers2));
num = get_scentce_2(Filename,size,buffer2);
return num;
}
int main(int argc, char *argv[])
{
unsigned int num1,num2;
checkinit(); //初始化终端为UTF-8编码
num1 = get_filesize(argv[1]);
num2 = get_filesize(argv[2]);
//char Datarry1[num1]; //Datarry1存放原txt
//char Datarry2[num2]; //Datarry2存放盗txt
// while(Bytecount2<num2) //判断是否到达文档结尾
// {
sec1=get_scentces1(argv[1],num1,buffers1);
total_1 = total_1+sec1;
sec2=get_scentces2(argv[2],num2,buffers2);
total_2 = total_2+sec2;
rec = chinese_compare(buffers1,buffers2,sec2) + rec;
// }
recs = (float)rec/(float)total_2; //重复度%
printf("txt1_total_china: %d\n",total_1); //txt原文的总字数,包括句号
printf("txt2_total_china: %d\n",total_2); //txt盗文的总字数,包括句号
printf("The same_char: %d\n",rec);
printf("The precent same_char: %.2f\n",recs);
wirte_txt(argv[3],total_1,total_2,rec,recs);
return 0;
}
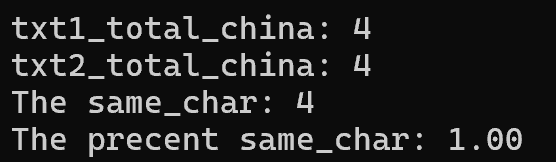
在去掉while只运行一次的情况下(只取文章的一句),可以得到结果:重复的字数4个,重复度为1(符合预期的结果)。
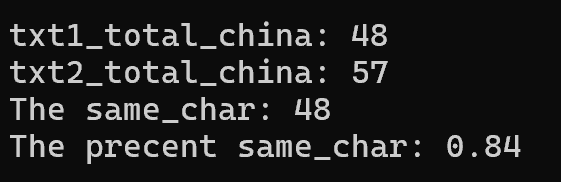
让其运行两次后,得到结果:重复字数为48,重复度为0.84(符合预期的结果),让其运行到10次或以后,数据仍然统计正确,测试比较完成。
五.计算模块部分异常处理说明
异常说明:计算模块在收到停止位的位数不正确的句子或句子不对应时会计算错误。
比如:原文的第一句对应是盗文的第二句的话,这样同时取出的句子错位会使得重复字判别错误。
因为已给的测试文件中句子是一一对应的,测试文件能通过。
但是对于一些没有任何符号规律文本而言,这会使得get_scentce()函数无法正确判别一个句子的停止位,计算模块会有计算偏差。
比如以下句子:“你好。今..天。。..shi”。
而且有一种情况也会导致计算错误:“今天是星期天”,“天是今期星天” 这个句子会被认为完全重复,但如果不从句子的意义上来说,只是光看字面,的确是完全重复。
算法性能:
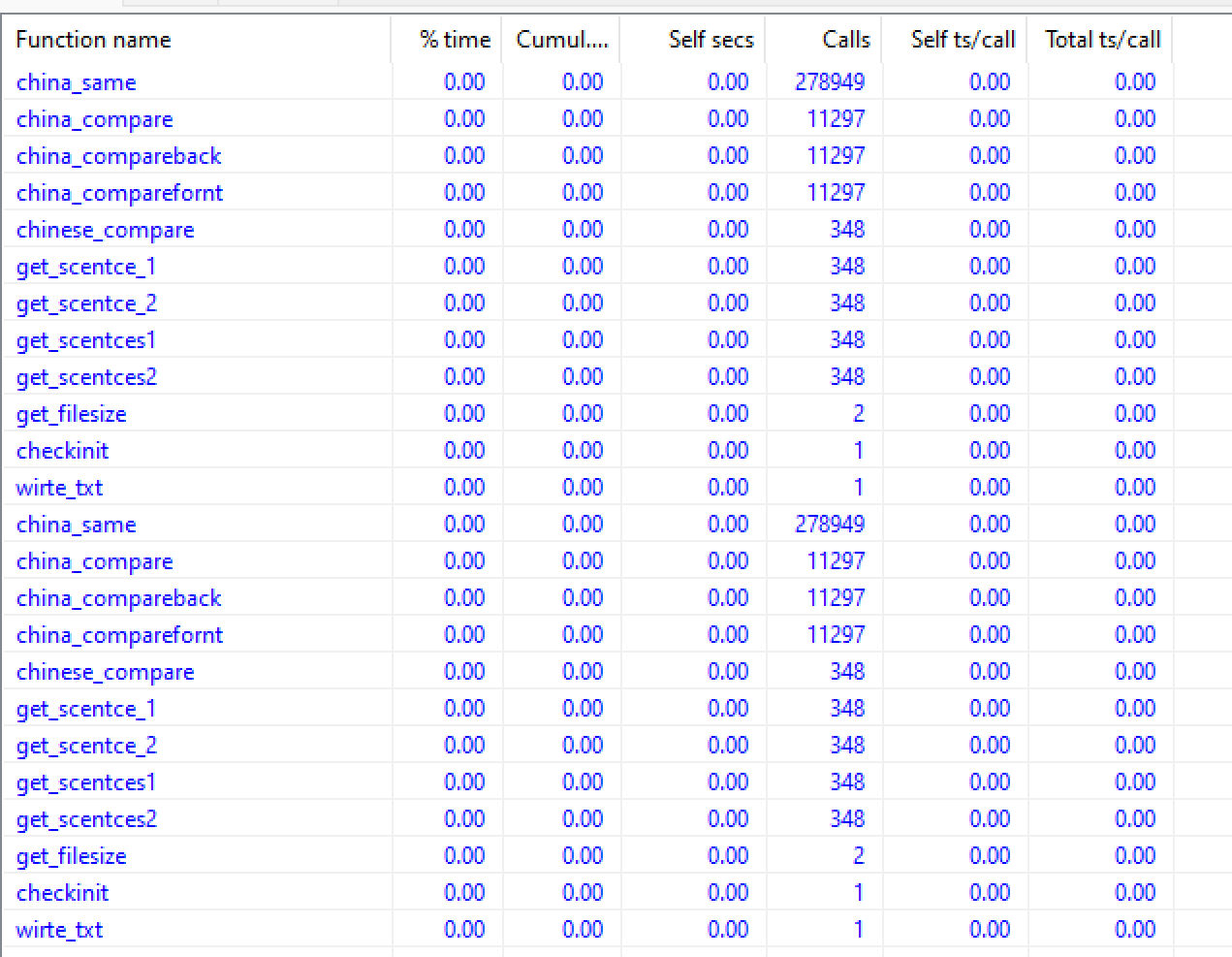
其中china—same被调用的次数最多,是最底层的操作,但是整个文件运行的时间非常短几乎看不到占用的时间。
1.文件编译时间:0.11秒
2.文件运行时间:0.0917秒
3.占用系统资源:

4.具体代码可查gitcode仓库
5.准确度:
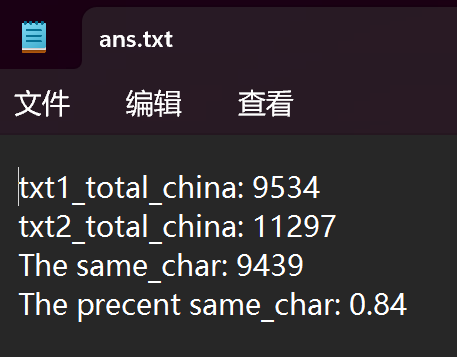
得出重复度结果为0.84
字符数量准确性:
原文计算一共9534个字,实际word统计一共9530个字,多4字。
盗文计算一共11297个字,实际word统计一共11293个字,多4字。
多出的4字对重复度的结果几乎无太大的影响。
六.代码功能模块
1.bock.c 初始化层:
终端编码格式改为utf8。负责读入文件,返回文件大小,单位是字节。
2.used.c 底层操作封装层:
负责从文本流中读入一个句子,将其放到数组中。
对于某些乱码,没有语义的文本,会导致读不到一个正确的句子
3.math.c 算法层:
将句子数组读入并进行比较,比较同一句的文本差异,返回重复字数。每调用一次取文本中的一个句子,比对这个字在原文±15字的范围内是否重复,有重复无论多少次都只返回1,到最后一句会停止。
具体算法:
1.从句子中取一个字,比对原文相似句的+/-15字是否相同(到达句头句会停止),重复则返回1,最大为1。循环直到取出完整个句子的字,最后返回一个句子的重复字数。
2.主程序中不断调用used层,将得到的句子给math层处理,然后累计变量。
4.wirte.c 输出层:
负责输出结果文件,包括总字数,重复字数和重复度。
这个结果文件必须是先前已经存在的*

