使用selenium抓取拉勾网职位信息
使用selenium模拟浏览器对拉勾网进行岗位信息的抓取
前排提示本人代码小白 还有许多不完善的地方,提供代码仅供参考。
一、在pycharm上安装selenium
在terminal界面输入 python pip install selenium
安装谷歌(Chrome)浏览器的驱动--chromedriver 把解压缩的浏览器驱动chromedriver 放在python解释器所在的文件夹
在网页中寻找元素的xpath路径:在网页中点击F12,

点击按钮,在网页中点击你想查找的部分,在Elements对应代码中点击右键,Copy->Copy Xpath
二、爬取岗位信息
导入库
import time
import pymysql
import requests
import matplotlib.pyplot as plt
from lxml import etree
from selenium import webdriver
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.chrome.options import Options设置无头浏览器参数 无头浏览器可以让selenium在电脑后台运行 增加运行效率
opt = Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu")进入拉勾网,关闭拉勾网地区选择弹窗,输入想抓取的岗位的名称 这里用python演示
web = Chrome(options=opt)
web.get("https://lagou.com")
el = web.find_element(By.XPATH, '//*[@id="changeCityBox"]/p[1]/a')
el.click()
time.sleep(1)
query = input("请输入你想要查找的岗位信息:")
web.find_element(By.XPATH, '//*[@id="search_input"]').send_keys(f"{query}", Keys.ENTER)
time.sleep(1)
进入岗位信息页面,准备抓取数据
web_max_page = int(web.find_element(By.XPATH, '//*[@id="jobList"]/div[3]/ul/li[8]/a').text) # 查找最大页数
i = 1 # 从第一页开始
pn = 1
div_num = 1
while i <= web_max_page:
url = f'https://www.lagou.com/wn/jobs?px=new&pn={pn}&fromSearch=true&kd={query}'
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0"
}
resp = requests.get(url, headers=headers)
page_content = resp.text
html = etree.HTML(page_content) #用request获取刷新页面的方法
div_list = html.xpath('//*[@id="jobList"]/div[1]/div')
for div in div_list:
job_name1 = div.xpath('./div[1]/div[1]/div[1]/a/text()')[0] # .split("[")[0] #获取工作名字
job_name = ''.join(job_name1) # 连接为新的字符串
job_city1 = div.xpath('./div[1]/div[1]/div[1]/a/text()')[1] # .split("[")[1].replace("]", "")
job_city = ''.join(job_city1) # 城市
job_com1 = div.xpath('./div[1]/div[2]/div[1]/a/text()')
job_com = ''.join(job_com1) #公司名称
job_exp = div.xpath('./div[1]/div[1]/div[2]/text()')[0].split("/")[0].strip() # 工作年龄
job_edu = div.xpath('./div[1]/div[1]/div[2]/text()')[0].split("/")[1].strip() # 学历
job_money1 = div.xpath('./div[1]/div[1]/div[2]/span/text()')
job_money = ''.join(job_money1) # 薪水
job_detail = ""
web.find_element(By.XPATH,f'//*[@id="jobList"]/div[1]/div[{div_num}]/div[1]/div[1]/div[1]/a').click() # 查看详情
web.switch_to.window(web.window_handles[-1]) # 切换到最右边窗口
WebDriverWait(web, 5).until(EC.presence_of_element_located((By.XPATH, '//*[@id="job_detail"]/dd[2]/div'))) # 等待页面加载完成
time.sleep(1)
job_detail = web.find_element(By.XPATH, '//*[@id="job_detail"]/dd[2]/div').text.strip()
div_num += 1
web.close() # 关掉子窗口
web.switch_to.window(web.window_handles[0]) # 变更selenium的窗口视角,回到原来的窗口中
time.sleep(1)
try:
db = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='',
port=3306,
db='python',
charset='utf8',
use_unicode=True
)
# print("连上了!")
cursor = db.cursor() # 执行完毕返回的结果集默认以元组显示
sql = f"insert ignore into Job_information (job_name, job_city, job_com, job_exp, job_edu, job_money, job_detail) values('{job_name}','{job_city}','{job_com}','{job_exp}','{job_edu}','{job_money}','{job_detail}')"
cursor.execute(sql) # 执行SQL语句
print("插入完一条语句")
cursor.close() # 关闭光标对象
db.commit() # 执行sql语句之后提交
db.close() #关闭数据库
except:
print("跳过1次插入")
continue
web.find_element(By.XPATH, '//*[@id="jobList"]/div[3]/ul/li[9]/a').click() # 点击下一页按钮
WebDriverWait(web, 1000).until(EC.presence_of_element_located((By.XPATH, '//*[@id="jobList"]/div[1]/div'))) # 等待页面加载完成
web.refresh()
time.sleep(1)
web.switch_to.window(web.window_handles[0]) # 切换到最左边窗口
time.sleep(1)
i += 1
pn+=1
print(f"已经爬取{query}相关的职位信息")其中如果你使用的是web.find_element_by_xpath('xxxx')的话,pycharm可能会提示错误,因为使用了老版的写法,新版写法为:web.find_element(By.XPATH, 'xxxxxx')
在提取工作经验和学历的时候,它们是一个字符串,所以需要使用.split("/").strip()来将它们分开和去除左右两边的空格。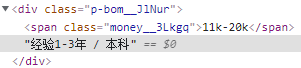
selenium打开新窗口后,它默认的窗口还是原来打开新页面前,所以要切换到新窗口使用以下代码来切换到最右边窗口,也可以使用[1]来表示
web.switch_to.window(web.window_handles[-1])当各种原因如网络问题导致网页加载速度比较慢,导致代码运行错误的情况下,可以使用time.sleep()让程序休眠数秒,但这种方法比较死板,少量使用可以,我们可以使用
WebDriverWait(web, 5).until(EC.presence_of_element_located((By.XPATH, '//*[@id="job_detail"]/dd[2]/div')))WebDriverWait():显示等待,是 webdirver 提供的方法;等待所定位的元素加载完成后才开始执行后面代码,如果超过设置时间检测不到则抛出异常
数据库使用pymysql

连接数据库时,正确写法为charset='utf8' 而不是utf-8
执行完sql语句后一定要记得写commit语句,不然的话,数据库插入操作是不会成功的。
代码不完善的地方1:
在获取岗位job_detail信息时,通过selenium循环点击进入岗位详细页面时会遇到错误
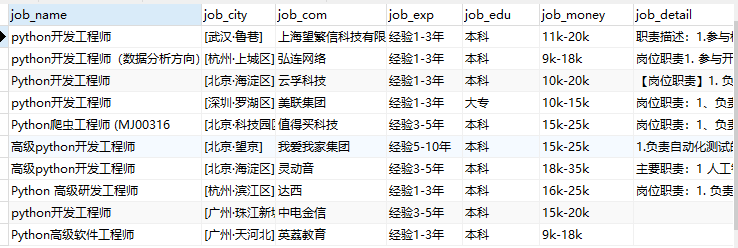
前七八个数据岗位的详细信息可以被抓取到,但后面几个数据就无法抓取到详细信息了。NoSuchElementException: Message: no such element: Unable to locate element
如果修改循环语句,又会找不到对应的div元素 selenium.common.exceptions.TimeoutException: Message 这个问题暂时无法解决。
输入公司名称,获取公司发布的招聘岗位信息
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True) # 设置不自动关闭浏览器
web = Chrome(options=option)
web.get("https://lagou.com")
el = web.find_element(By.XPATH, '//*[@id="changeCityBox"]/p[1]/a')
el.click()
time.sleep(1)
query = input("请输入你想要查找的公司信息:")
web.find_element(By.XPATH, '//*[@id="search_input"]').send_keys(f"{query}", Keys.ENTER)
WebDriverWait(web, 1000).until(EC.presence_of_element_located((By.XPATH, '//*[@id="jobsContainer"]/div[2]/div[1]/div/div[2]/div[2]/div[5]/a')))
element1 = web.find_element(By.XPATH, '//*[@id="jobsContainer"]/div[2]/div[1]/div/div[2]/div[2]/div[5]/a')
web.execute_script("arguments[0].click();", element1) # 进入公司主业
web.switch_to.window(web.window_handles[-1]) # 切换到最右边窗口
WebDriverWait(web, 1000).until(EC.presence_of_element_located((By.XPATH, '//*[@id="company_navs"]/div/ul/li[2]/a'))) # 等待招聘职位加载完成
web.find_element(By.XPATH, '//*[@id="company_navs"]/div/ul/li[2]/a').click()
web.refresh()
web.switch_to.window(web.window_handles[-1]) # 切换到最右边窗口
WebDriverWait(web, 1000).until(EC.presence_of_element_located((By.XPATH, '//*[@id="posfilterlist_container"]/div/div[2]/div[2]/ul/li')))
job_number = web.find_element(By.XPATH, '//*[@id="company_navs"]/div/ul/li[2]/a').text # 获取招聘职位数量
# print(job_number)
db = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='',
port=3306,
db='python',
charset='utf8'
)
lis = web.find_elements(By.XPATH, '//*[@id="posfilterlist_container"]/div/div[2]/div[2]/ul/li')
for li in lis:
job_name = li.get_attribute('data-positionname')
print(job_name)
cursor = db.cursor()
sql = f"insert ignore into company_info (com_name,job_number,job_name) values('{query}','{job_number}','{job_name}')"
cursor.execute(sql)
db.commit()
print("插入完一条语句")
cursor.close()
db.close()大体步骤与上面相同,输入公司名称,进入公司主页,抓取公司招聘信息
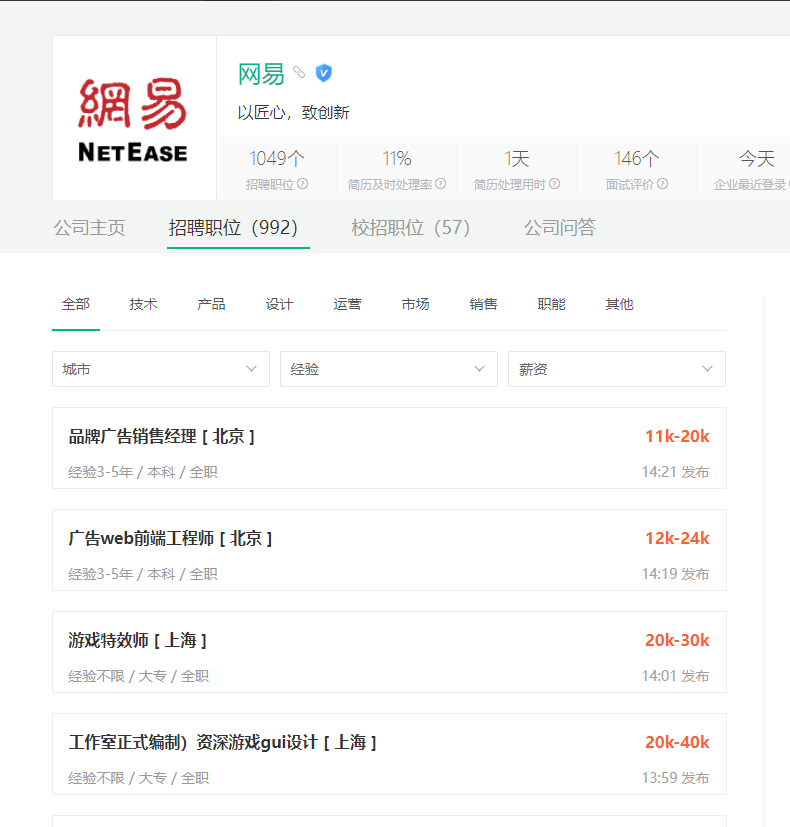
代码不完善的地方2:
获取招聘信息时,只能获取当前一页的数据。该网站的下一页为<span>标签,selenium不能点击,且下一页网页无刷新。
该网页使用了动态网页技术,由于本人水平有限,还没学习到能够抓取动态页面的程度,所以只能获取一页数据。
三、数据分析
使用matplotlib 库,我们需要注意中文编码的问题,使用以下代码解决:
plt.rcParams['font.sans-serif'] = ['SimHei']代码部分:
count_exp = {'经验不限':0,'经验在校':0,'经验1年以下':0,'经验1-3年':0,'经验3-5年':0,'经验5-10年':0,'经验10年以上':0}
total_exp = {'经验不限':0,'经验在校':0,'经验1年以下':0,'经验1-3年':0,'经验3-5年':0,'经验5-10年':0,'经验10年以上':0}
count_edu = {'不限':0,'大专':0,'应届':0,'本科':0,'硕士':0}
total_edu = {'不限': 0, '大专': 0, '应届': 0, '本科': 0, '硕士': 0}
db = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='',
port=3306,
db='python',
charset='utf8'
)
cursor = db.cursor(cursor=pymysql.cursors.DictCursor) # 以字典的形式返回操作结果
sql = "select * from Job_information_copy1"
cursor.execute(sql)
results = cursor.fetchall() # 以元组的形式返回
for row in results:
count_exp[row['job_exp']] += 1
count_edu[row['job_edu']] += 1
try:
li = [float(temp.replace('k','000')) for temp in row['job_money'].split('-')]
total_exp[row['job_exp']] += sum(li)/len(li)
total_edu[row['job_edu']] += sum(li)/len(li)
except:
pass
# 解决中文编码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
# 工作经验-职位数量
plt.title('工作经验-职位数量')
plt.xlabel('工作经验')
plt.ylabel('职位数量/单位:个')
x = ['经验不限','经验在校','经验1年以下','经验1-3年','经验3-5年','经验5-10年','经验10年以上']
y = [count_exp[item] for item in x]
plt.bar(x,y)
plt.show()
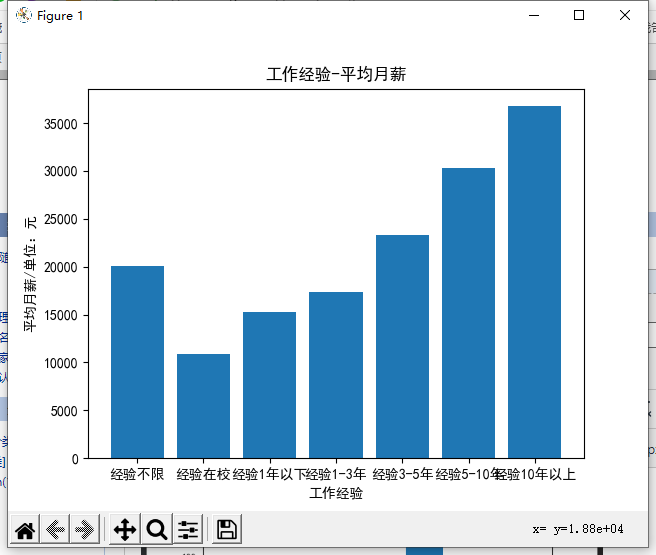
# 工作经验-平均月薪
plt.title('工作经验-平均月薪')
plt.xlabel('工作经验')
plt.ylabel('平均月薪/单位:元')
x = list()
y = list()
for row in ['经验不限','经验在校','经验1年以下','经验1-3年','经验3-5年','经验5-10年','经验10年以上']:
if count_exp != 0:
x.append(row)
y.append(total_exp[row]/count_exp[row])
plt.bar(x,y)
plt.show()
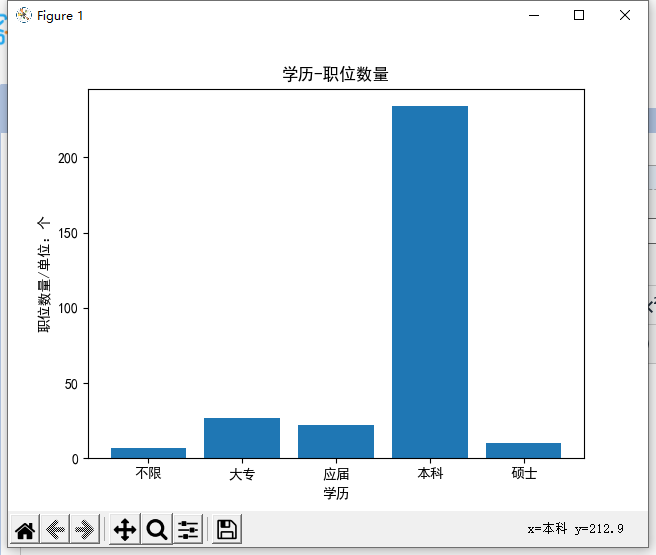
# 学历-职位数量
plt.title('学历-职位数量')
plt.xlabel('学历')
plt.ylabel('职位数量/单位:个')
x = ['不限','大专','应届','本科','硕士']
y = [count_edu[row] for row in x]
plt.bar(x,y)
plt.show()
# 学历-平均月薪
plt.title('学历-平均月薪')
plt.xlabel('学历')
plt.ylabel('平均月薪/单位:元')
x = list()
y = list()
for row in ['不限','大专','应届','本科','硕士']:
if count_edu[row] != 0:
x.append(row)
y.append(total_edu[row]/count_edu[row])
plt.bar(x,y)
plt.show()其中

count_exp和cont_edu代表了各个阶段对应的人数,通过
 来统计所有数据中的人数。
来统计所有数据中的人数。
total_exp和total_edu代表了对应阶段的所有薪资,通过
 li来存储平均薪资。
li来存储平均薪资。
运行效果:
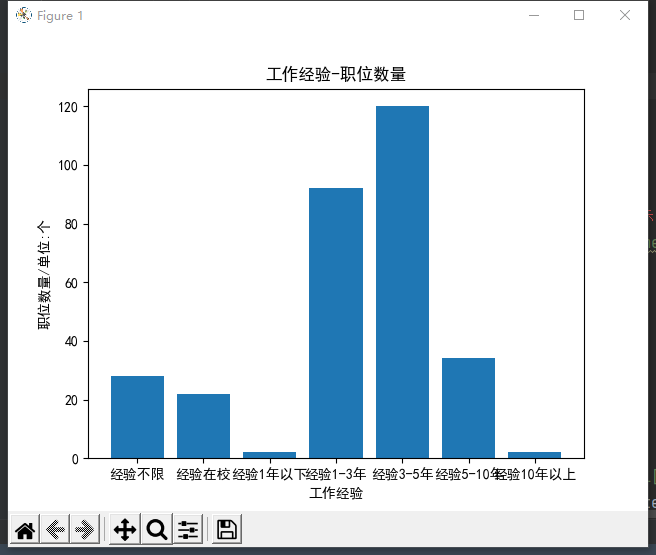

数据可视化参考文章:https://www.cnblogs.com/wsmrzx/p/10993640.html
四、完整代码
# -*- coding:utf-8 -*-
"""
作者:TXY
日期:2021年12月08日
"""
import time
import pymysql
import requests
import matplotlib.pyplot as plt
from lxml import etree
from selenium import webdriver
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.chrome.options import Options
def fun1():
# 准备好无头浏览器参数配置
opt = Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu")
web = Chrome(options=opt)
web.get("https://lagou.com")
el = web.find_element(By.XPATH, '//*[@id="changeCityBox"]/p[1]/a')
el.click()
time.sleep(1)
query = input("请输入你想要查找的岗位信息:")
web.find_element(By.XPATH, '//*[@id="search_input"]').send_keys(f"{query}", Keys.ENTER)
time.sleep(1)
web_max_page = int(web.find_element(By.XPATH, '//*[@id="jobList"]/div[3]/ul/li[8]/a').text) # 查找最大页数
# div_list = web.find_elements(By.XPATH, '//*[@id="jobList"]/div[1]/div')
i = 1 # 从第一页开始
pn = 1
div_num = 1
while i <= web_max_page:
# div_num = 1
url = f'https://www.lagou.com/wn/jobs?px=new&pn={pn}&fromSearch=true&kd={query}'
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0"
}
resp = requests.get(url, headers=headers)
page_content = resp.text
html = etree.HTML(page_content) #用request获取刷新页面的方法
div_list = html.xpath('//*[@id="jobList"]/div[1]/div')
# div_list_sel = web.find_elements(By.XPATH, '//*[@id="jobList"]/div[1]/div')
for div in div_list:
job_name1 = div.xpath('./div[1]/div[1]/div[1]/a/text()')[0] # .split("[")[0] #获取工作名字
job_name = ''.join(job_name1) # 连接为新的字符串
job_city1 = div.xpath('./div[1]/div[1]/div[1]/a/text()')[1] # .split("[")[1].replace("]", "")
job_city = ''.join(job_city1) # 城市
job_com1 = div.xpath('./div[1]/div[2]/div[1]/a/text()')
job_com = ''.join(job_com1) #公司名称
job_exp = div.xpath('./div[1]/div[1]/div[2]/text()')[0].split("/")[0].strip() # 工作年龄
job_edu = div.xpath('./div[1]/div[1]/div[2]/text()')[0].split("/")[1].strip() # 学历
job_money1 = div.xpath('./div[1]/div[1]/div[2]/span/text()')
job_money = ''.join(job_money1) # 薪水
# print(job_name,job_city,job_com,job_money,job_exp,job_edu)
##以下代码还存在修改的空间,谨慎使用
try:
job_detail = ""
web.find_element(By.XPATH,f'//*[@id="jobList"]/div[1]/div[{div_num}]/div[1]/div[1]/div[1]/a').click() # 查看详情
web.switch_to.window(web.window_handles[-1]) # 切换到最右边窗口
WebDriverWait(web, 5).until(EC.presence_of_element_located((By.XPATH, '//*[@id="job_detail"]/dd[2]/div'))) # 等待页面加载完成
time.sleep(1)
job_detail = web.find_element(By.XPATH, '//*[@id="job_detail"]/dd[2]/div').text.strip()
# print(job_detail)
div_num += 1
web.close() # 关掉子窗口
web.switch_to.window(web.window_handles[0]) # 变更selenium的窗口视角,回到原来的窗口中
time.sleep(1)
except:
div_num += 1
web.close() # 关掉子窗口
web.switch_to.window(web.window_handles[0]) # 变更selenium的窗口视角,回到原来的窗口中
time.sleep(1)
###以上代码还存在修改的空间,谨慎使用
try:
db = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='',
port=3306,
db='python',
charset='utf8',
use_unicode=True
)
# print("连上了!")
cursor = db.cursor() # 执行完毕返回的结果集默认以元组显示
sql = f"insert ignore into Job_information (job_name, job_city, job_com, job_exp, job_edu, job_money, job_detail) values('{job_name}','{job_city}','{job_com}','{job_exp}','{job_edu}','{job_money}','{job_detail}')"
cursor.execute(sql) # 执行SQL语句
print("插入完一条语句")
cursor.close() # 关闭光标对象
db.commit() # 执行sql语句之后提交
db.close() #关闭数据库
except:
print("跳过1次插入")
continue
web.find_element(By.XPATH, '//*[@id="jobList"]/div[3]/ul/li[9]/a').click() # 点击下一页按钮
WebDriverWait(web, 1000).until(EC.presence_of_element_located((By.XPATH, '//*[@id="jobList"]/div[1]/div'))) # 等待页面加载完成
web.refresh()
time.sleep(1)
web.switch_to.window(web.window_handles[0]) # 切换到最左边窗口
time.sleep(1)
i += 1
pn+=1
print(f"已经爬取{query}相关的职位信息")
def fun2():
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True) # 设置不自动关闭浏览器
web = Chrome(options=option)
web.get("https://lagou.com")
el = web.find_element(By.XPATH, '//*[@id="changeCityBox"]/p[1]/a')
el.click()
time.sleep(1)
query = input("请输入你想要查找的公司信息:")
web.find_element(By.XPATH, '//*[@id="search_input"]').send_keys(f"{query}", Keys.ENTER)
WebDriverWait(web, 1000).until(EC.presence_of_element_located((By.XPATH, '//*[@id="jobsContainer"]/div[2]/div[1]/div/div[2]/div[2]/div[5]/a')))
element1 = web.find_element(By.XPATH, '//*[@id="jobsContainer"]/div[2]/div[1]/div/div[2]/div[2]/div[5]/a')
web.execute_script("arguments[0].click();", element1) # 进入公司主业
web.switch_to.window(web.window_handles[-1]) # 切换到最右边窗口
WebDriverWait(web, 1000).until(EC.presence_of_element_located((By.XPATH, '//*[@id="company_navs"]/div/ul/li[2]/a'))) # 等待招聘职位加载完成
web.find_element(By.XPATH, '//*[@id="company_navs"]/div/ul/li[2]/a').click()
web.refresh()
web.switch_to.window(web.window_handles[-1]) # 切换到最右边窗口
WebDriverWait(web, 1000).until(EC.presence_of_element_located((By.XPATH, '//*[@id="posfilterlist_container"]/div/div[2]/div[2]/ul/li')))
job_number = web.find_element(By.XPATH, '//*[@id="company_navs"]/div/ul/li[2]/a').text # 获取招聘职位数量
# print(job_number)
db = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='',
port=3306,
db='python',
charset='utf8'
)
lis = web.find_elements(By.XPATH, '//*[@id="posfilterlist_container"]/div/div[2]/div[2]/ul/li')
for li in lis:
job_name = li.get_attribute('data-positionname')
print(job_name)
cursor = db.cursor()
sql = f"insert ignore into company_info (com_name,job_number,job_name) values('{query}','{job_number}','{job_name}')"
cursor.execute(sql)
db.commit()
print("插入完一条语句")
cursor.close()
db.close()
def fun3():
count_exp = {'经验不限':0,'经验在校':0,'经验1年以下':0,'经验1-3年':0,'经验3-5年':0,'经验5-10年':0,'经验10年以上':0}
total_exp = {'经验不限':0,'经验在校':0,'经验1年以下':0,'经验1-3年':0,'经验3-5年':0,'经验5-10年':0,'经验10年以上':0}
count_edu = {'不限':0,'大专':0,'应届':0,'本科':0,'硕士':0}
total_edu = {'不限': 0, '大专': 0, '应届': 0, '本科': 0, '硕士': 0}
db = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='',
port=3306,
db='python',
charset='utf8'
)
cursor = db.cursor(cursor=pymysql.cursors.DictCursor) # 以字典的形式返回操作结果
sql = "select * from Job_information_copy1"
cursor.execute(sql)
results = cursor.fetchall() # 以元组的形式返回
for row in results:
count_exp[row['job_exp']] += 1
count_edu[row['job_edu']] += 1
try:
li = [float(temp.replace('k','000')) for temp in row['job_money'].split('-')]
total_exp[row['job_exp']] += sum(li)/len(li)
total_edu[row['job_edu']] += sum(li)/len(li)
except:
pass
# 解决中文编码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
# 工作经验-职位数量
plt.title('工作经验-职位数量')
plt.xlabel('工作经验')
plt.ylabel('职位数量/单位:个')
x = ['经验不限','经验在校','经验1年以下','经验1-3年','经验3-5年','经验5-10年','经验10年以上']
y = [count_exp[item] for item in x]
plt.bar(x,y)
plt.show()
# 工作经验-平均月薪
plt.title('工作经验-平均月薪')
plt.xlabel('工作经验')
plt.ylabel('平均月薪/单位:元')
x = list()
y = list()
for row in ['经验不限','经验在校','经验1年以下','经验1-3年','经验3-5年','经验5-10年','经验10年以上']:
if count_exp != 0:
x.append(row)
y.append(total_exp[row]/count_exp[row])
plt.bar(x,y)
plt.show()
# 学历-职位数量
plt.title('学历-职位数量')
plt.xlabel('学历')
plt.ylabel('职位数量/单位:个')
x = ['不限','大专','应届','本科','硕士']
y = [count_edu[row] for row in x]
plt.bar(x,y)
plt.show()
# 学历-平均月薪
plt.title('学历-平均月薪')
plt.xlabel('学历')
plt.ylabel('平均月薪/单位:元')
x = list()
y = list()
for row in ['不限','大专','应届','本科','硕士']:
if count_edu[row] != 0:
x.append(row)
y.append(total_edu[row]/count_edu[row])
plt.bar(x,y)
plt.show()
if __name__ == '__main__':
t = int(input("岗位(1)、公司(2)或者岗位数据分析(3),请输入代表数字:"))
if (t == 1):
fun1()
else:
if(t == 2):
fun2()
else:
if(t == 3):
fun3()
else:
print("输入错误,请重新输入!")
 浙公网安备 33010602011771号
浙公网安备 33010602011771号