Yarn基础组件及提交流程
下面记录下YARN的服务组件和提交流程的基础知识,主要参考文末博文,其中提交流程部分直接引用,感谢被引用的博主PeTu。
YARN介绍
YARN是在Hadoop2.0引入的,它的出现是历史的产物。在Hadoop1.0版本时,有JobTracker和TaskTracker来完成资源调度和任务执行,其中前者负责接收任务、资源调度和任务监控,后者负责任务的具体执行,并不断反馈执行情况给JobTracker,但传统的组件存在以下不足:
- JobTracker最多只能管理4000个节点,随着节点的增多,这会成为一个瓶颈。
- JobTracker存在单点故障问题,造成服务不可用。
- 随着计算模型(如MapReduce、Spark)的增多,不同的计算模型的资源调度需要统一。
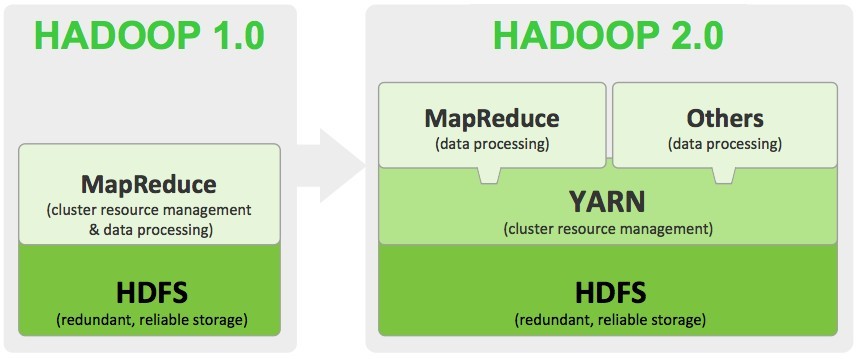
由于Hadoop1.0版本存在JobTracker和TaskTracker的不足,Hadoop2.0版本引入了YARN,Apache Hadoop YARN(Yet Another Resource Negotiator)是Hadoop的子项目,为分离Hadoop1.0资源管理和计算组件而引入,到了Hadoop2.0,资源管理单独抽出来形成了YARN,其中资源指的是CPU和内存。
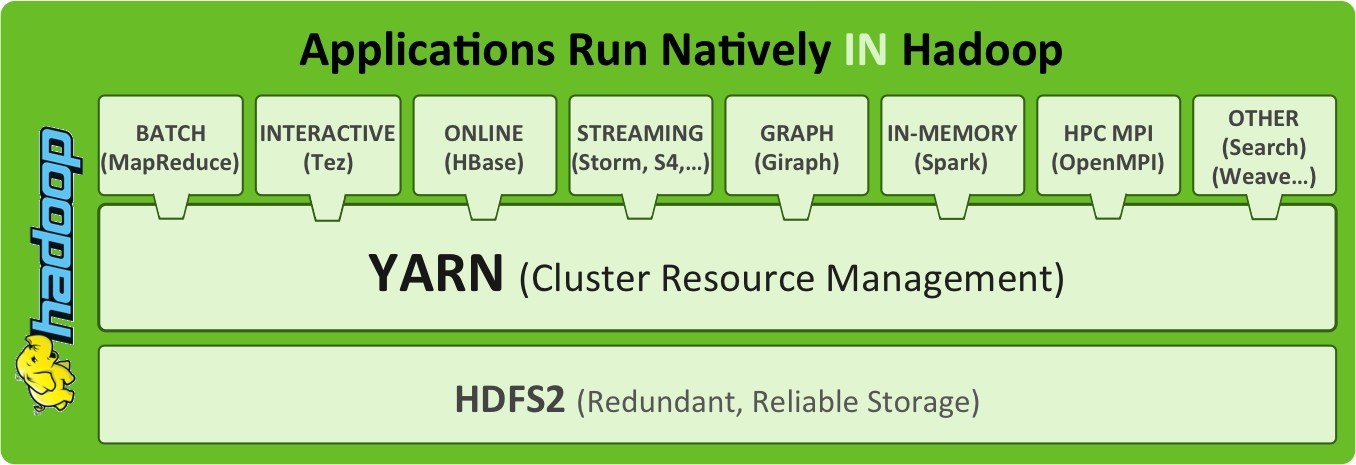
YARN具有足够的通用性,可以支持其它的分布式计算模型。YARN不仅支持MapReduce,也支持Hive、HBase、Spark、Giraph(机器学习)等。参考下图,如可以支持Spark,让资源管理交给YARN,而不是Spark默认的Cluster Manager。
YARN结构
类似HDFS,YARN也是经典的主从(master/slave)结构,YARN由一个ResourceManager(RM)和多个NodeManager(NM)构成,ResourceManager为主节点,NodeManager为从节点,此外Application Master(AM)和Container也是YARN的组成部分。
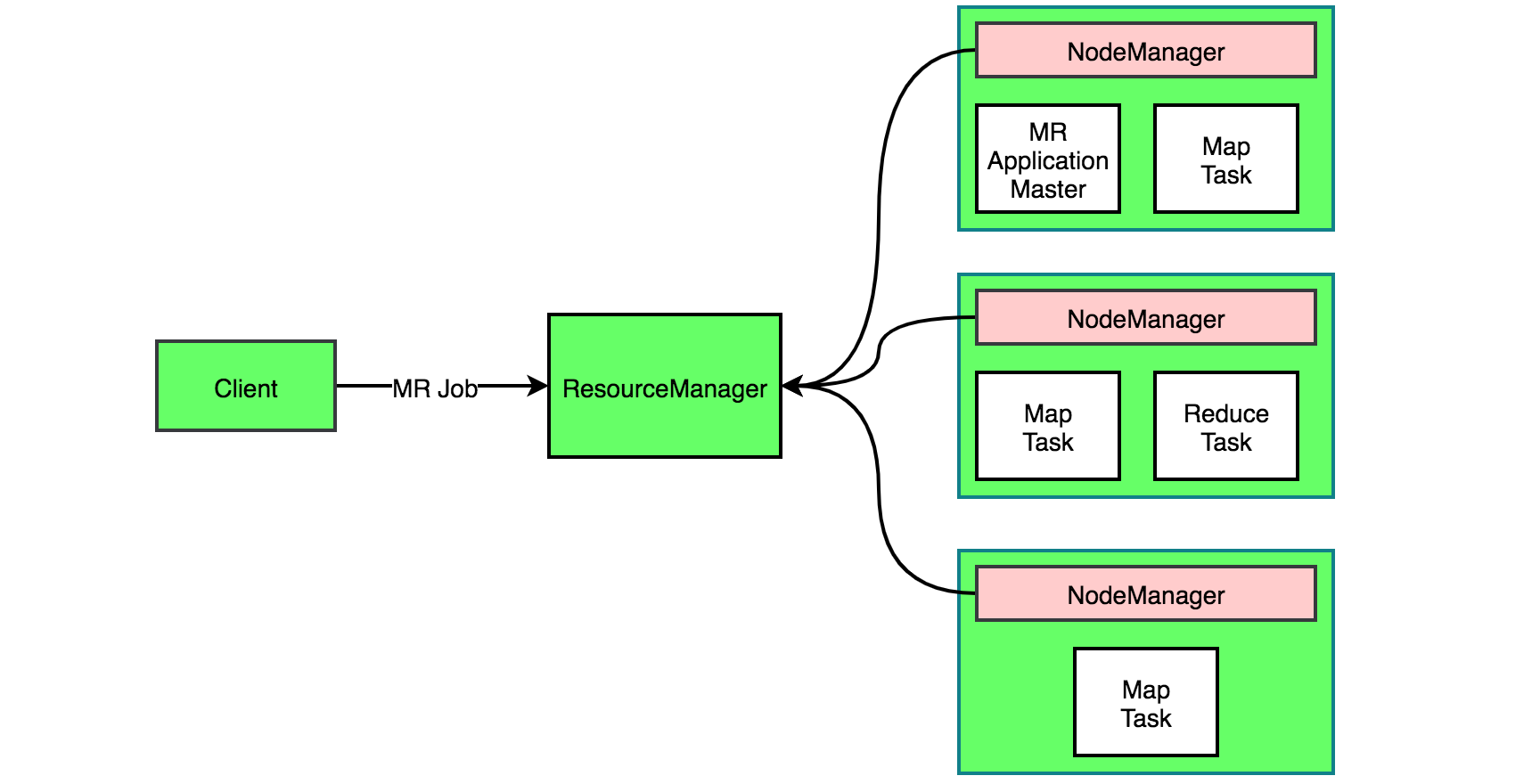
Client:可以提交任何YARN支持的application job,job会被拆分为一个个的task。
RM:追踪可用的NM和资源、分配合适的资源并且监控Application Master。
NM:以Container的形式提供可供计算的资源,并且在里面执行application。
AM:请求合适的资源运行task,协调application里所有task的执行。
Container:在这里指内存(默认1G)和CPU(默认1个核),可以在里面运行不同类型的task,包括AM也是在某个Container中启动执行。
如上图是Client提交一个MR任务的例子,MR AM启动后会专门负责这个MR任务并向RM申请资源,如果job被划分为3个Map Task和1个Reduce Task,AM会尽量多的向RM申请资源,三副本情况下这里会申请3*3+1=10份资源,但是实际上RM只会返回4份资源。申请到资源就开始执行task,AM会监控每一个子task的执行情况,AM管理task,RM管理AM,这样RM不需要直接去管理每个具体task。
服务组件
YARN的服务组件,主要是RM、NM、AM、Container。
ResourceManager
RM是Master上一个独立运行的进程,负责集群统一的资源管理、调度、分配等,是一个全局的资源管理器,集群只有一个,它由应用程序管理器(Applications Manager,简称ASM)和资源调度器(Resource Scheduler)组成。
调度器根据各个应用程序的资源需求进行资源分配,以Container集成的方式返回给AM,其中调度器Scheduler是一个“纯调度器”,它不从事任何与具体应用程序相关的工作,只做资源的调度。它是一个可插拔的组件,有三种常见的调度器可供使用,分别是FIFO Scheduler,Capacity Scheduler和Fair Scheduler,可以通过yarn-site.xml配置。
应用程序管理器ASM,主要负责管理整个系统中所有AM,RM接收job的提交,其实是先提交给了RM的ASM。它为应用分配第一个 Container 来启动运行AM,这个AM是一个pre-application ApplicationMaster,需要提前执行包括应用程序提交、与调度器Scheduler协商资源以启动 AM、监控 AM 运行状态并在失败时重新启动它、监控task执行的进度等工作。
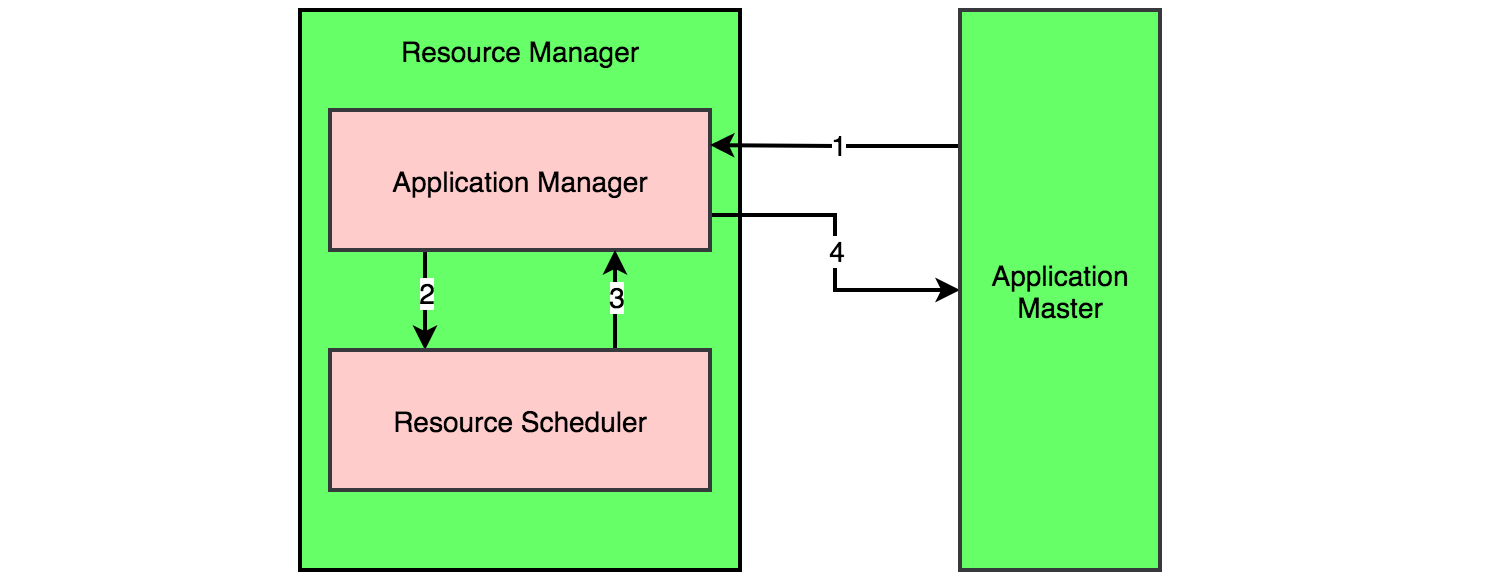
如下图所示,AM向RM请求资源,其实是向ASM请求,ASM然后向配置的调度器询问进行资源调度,最后将资源以Container的形式返回给AM。
NodeManager
NM是Slave上一个独立运行的进程,通过心跳机制上报节点的状态(磁盘,内存,CPU等使用信息)给RM,它是真正提供计算资源的,除了节点的状态还会上报节点上Container的使用信息,其主要功能如下。
- 接收及处理来自RM和AM的请求,前者接受Client提交的job,后者会将job进行分解变成task,最后资源分配到task。
- NM定时地向RM发送心跳上报信息,RM 通过收集每个NM的上报信息,来追踪整个集群健康状态。
- 管理着所在节点每个Container的生命周期。
- 管理每个节点上的日志信息。
- 执行YARN上面应用的一些额外的服务,如 MapReduce 的shuffle过程。
ApplicationMaster
AM是Application的监护人和管理者,负责监控,管理这个Application的所有Attempt(task)在集群中各个节点上的运行情况,同时负责向RM申请资源运行task,task执行完成后返还资源。AM只有在集群运行job时,有任务在执行时,才会出现这个进程,其主要功能如下。
- 任务的监控与容错。
- 为应用程序申请资源并二次分配给内部task。
- 负责协调来自RM的资源,并通过NM监视程序的执行和资源使用情况。
不同的application都有单独对应的AM,它们互不干扰,AM和RM之间通信,不断的申请资源,释放资源,再申请资源,释放资源,如此反复完成一个个application的执行,它们之间的沟通是YARN中至关重要的一环。
Container
Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。目前为止,YARN 仅支持 CPU 和内存两种资源,且使用了Linux中轻量级资源隔离机制 Cgroups 进行资源隔离。Container 是一个动态资源划分单位,是根据应用程序的需求动态生成的,默认是1G内存+1核CPU。
当 AM 向 RM 申请资源时,RM 为 AM 返回的资源用 Container 表示的。RM 只负责告诉AM哪些 Containers是可以用的,实际上AM还需要去找NM请求分配具体的 Container。
如下图所示,YARN 会为每个任务分配一个 Container,且该任务只能使用分配的Container中描述的资源。一个 job 或 application 需运行在一个或多个 Container 中。一个节点会运行多个 Container,但一个 Container 不会跨节点。
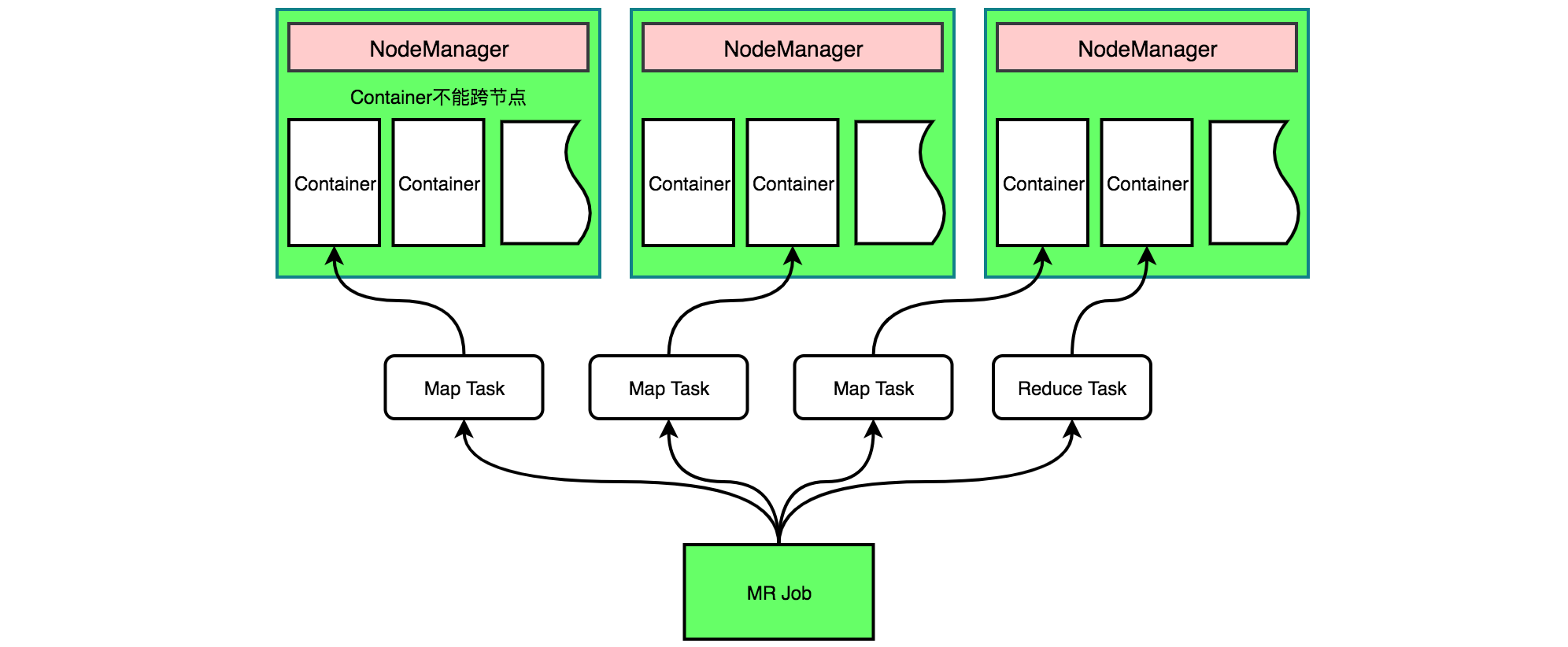
提交流程
YARN的基本理念是将JobTracker和TaskTracker两大职能分割为以下几个实体。
- 一个全局的资源管理ResourceManager
- 每个应用程序一个ApplicationMaster
- 每个从节点一个NodeManager
- 每个应用程序一个运行在NodeManager上的Container
RM 和NM组成了一个新的、通用的、用分布式管理应用程序的系统。RM对系统中的应用程序资源有终极仲裁的权限。AM的工作是同RM谈判资源 ,同时在NM执行和监控任务。RM有一个调度器,根据调度器类型和特点,将资源进行分配给各个运行着的应用程序。NM负责发布应用程序所需的资源,监控资源的使用并向RM进行汇报。每个AM都有职责从调度器那得到适当的资源,追踪它们的状态,并监控它们的进程。从系统的视图看,AM作为一个普通的application运行着。
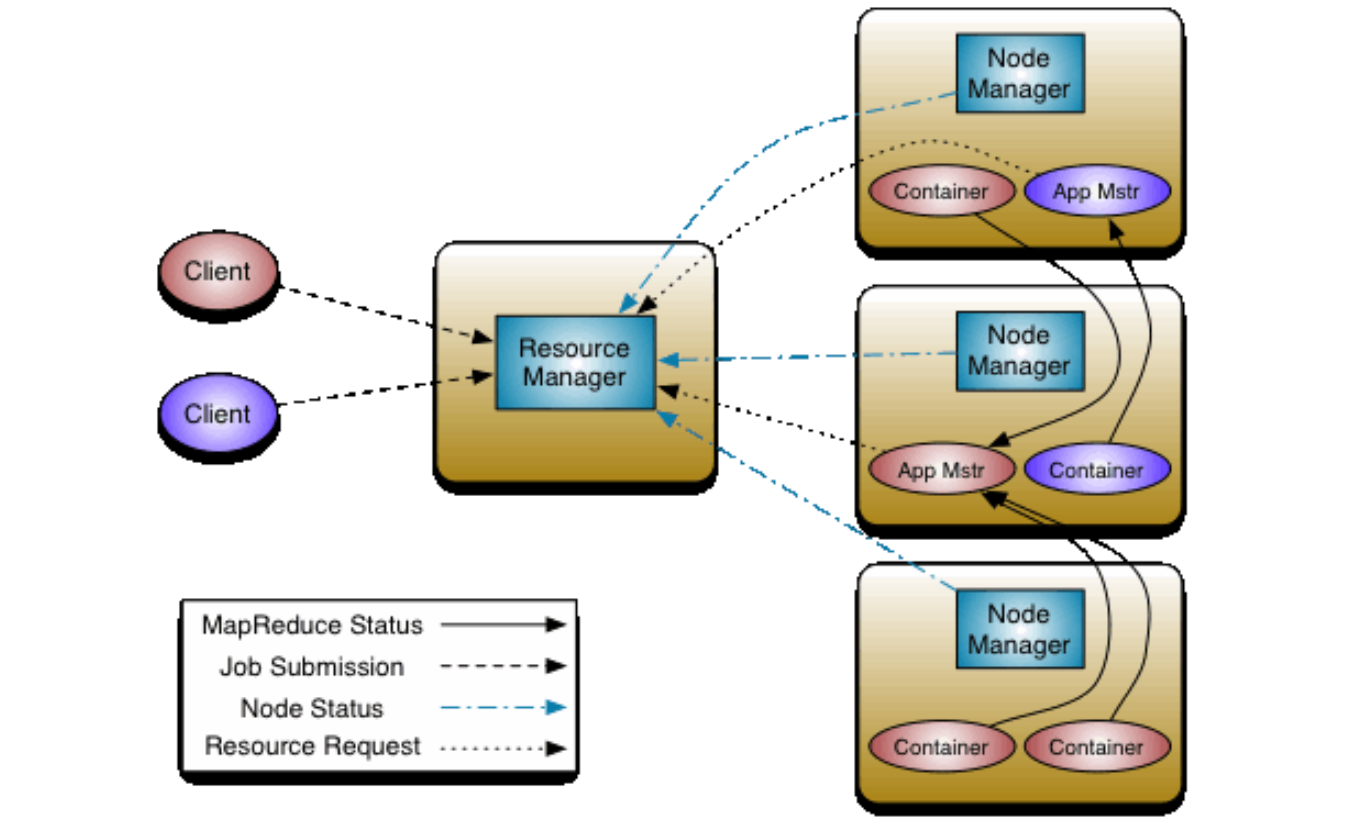
YARN应用提交大致过程
Application在YARN中的执行过程,整体执行过程可以分为三步。
- 应用程序提交。
- 启动应用的AM实例。
- AM实例管理应用程序的执行。
YARN应用提交具体过程
应用(如MapReduce、Spark on yarn、Flink on yarn)提交的通用流程参考下图,其中需要先使用资源调度算法(确定了在哪个节点启动Container,以及Container包含的CPU和内存)先找一个可以启动AM的节点,找到节点启动AM后,AM会向RM请求资源,在对应的节点上进行分解后Task的启动和执行工作,如MapReduce任务,Map Task分配到哪个节点执行会采用本地策略,即移动运算不移动资源,将任务分配到合适的节点。
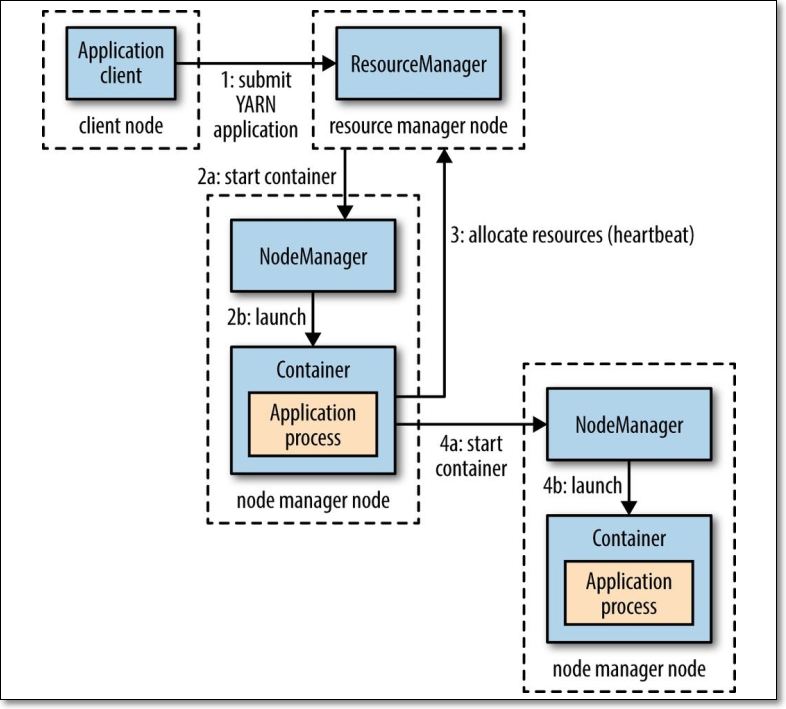
- 客户端程序向RM提交应用并请求一个AM实例;
- RM找到一个可以运行一个Container的NM,并在这个Container中先启动AM实例;
- AM向RM进行注册,注册之后客户端就可以查询RM获得自己的AM详细信息,以后就可以和自己对应的AM直接交互了(这个时候,客户端主动和AM交流,应用先向AM发送一个满足自己需求的资源请求);
- 在平常的操作过程中,AM根据resource-request协议向RM发送resource-request请求;
- 当Container被成功分配后,AM通过向NM发送container-launch-specification信息来启动Container,container-launch-specification信息包含了能够让Container和AM通信所需要的资料;
- 应用程序的代码以task形式在启动的Container中运行,并把运行的进度、状态等信息通过application-specific协议发送给AM;
- 在应用程序运行期间,提交应用的客户端主动和AM交流获得应用的运行状态、进度更新等信息,使用也是application-specific协议;
- 最后应用程序执行完成并且所有相关工作也已经结束,AM向RM取消注册然后关闭,用到所有的Container也返还给系统。
去年今日,还真是伤心的日子,火车站一下午的煎熬,无助又失落,但是依然要挺过去,加油吧。
以上,理解不一定正确,学习就是一个不断认识和纠错的过程。
参考博文:
(1)https://www.jianshu.com/p/f50e85bdb9ce YARN详细解析
(2)http://hadoop.apache.org/docs/r2.6.5/hadoop-YARN/hadoop-YARN-site/YARN.html YARN的架构
(3)https://www.cnblogs.com/ryanyangcs/p/11198140.html linux的Cgroups
(4)https://www.cnblogs.com/youngchaolin/p/11631892.html scheduler
(5)《Hadoop权威指南》第四版

 浙公网安备 33010602011771号
浙公网安备 33010602011771号