
基于PaddlePaddle框架实现桃子分类
众所周知,图像相比文字能够提供更加生动,容易理解及更具艺术感的信息,是人们转递与交换信息的重要来源。
谈到图像分类,图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉中重要的基础问题,也是图像检测、图像分割、物体跟踪、行为分析等其他高层视觉任务的基础,在许多领域都有着广泛的应用。如:安防领域的人脸识别和智能视频分析等,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。在本项目里,你将了解使用深度学习进行图片分类的原理、图片数据的一些处理技巧、深度神经网络模型搭建以及训练过程等,除此之外,还会加深你对Paddlepaddle深度学习框架的了解。
1.背景知识
图像分类包括通用图像分类,细粒度图像分类等。
图1展示了通用图像分类效果,即模型可以正确识别图像上的主要物体。

图1 通用图像分类展示
图2展示了细粒度图像分类 - 花卉识别的效果,要求模型可以正确识别花的类别。
![]()

图2 细粒度图像分类展示
一个好的模型既要对不同类别识别正确,同时也应该能够对不同视角,光照,背景,变形或部分遮挡的图像正确识别(这里我们统一称作图像扰动)。
图3展示了一些图像的扰动,较好的模型会像聪明的人类一样能够正确识别。
![]()

图3 扰动图片展示
2.项目说明
在本项目中,我们实现的是基于PaddlePaddle框架利用深度神经网络进行桃子图片的分类。
本项目使用数据集下载地址为:https://pan.baidu.com/s/17i8yYDVNqDDrO6qc4jjaxQ
关于数据集的补充说明:下载下来的数据集data文件里包括train与test两个文件夹,需要进行以下操作:对于命名为train的文件夹 ,train下面有4个文件夹,将文件夹名分别
改为class0,class1,class2,class3。 class0下再建立一个文件夹命名为0,第一类训练图片放在这里,class1下再建立个命名为1的文件夹,class2下建个2,class3下建个3 。
test 文件夹 以此类推操作。然后就可以进行训练测试了。
![]()
本实验使用的桃子数据集展示
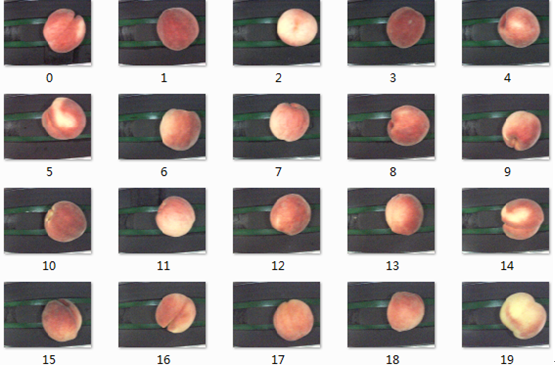
3.项目实现过程:3.1 导入相关库
1 import numpy as np 2 import sys 3 from PIL import Image 4 5 import paddle.v2 as paddle
3.2 数据预处理以及reader的构造
数据集中6400 张大桃照片按照红、大、中、小等元素按照分档建立图片数据集合,实验思路是将图片数据集放入卷积神经网络(CNN)中进行训练,自动提取用于分级的影响要素并形成分类逻辑。
由于本项目的数据集是图片,我们首先来了解一下图片的CHW布局:
缩写:C =通道,H =高度,W =宽度
由cv2或PIL打开的图像的默认布局是HWC。
而PaddlePaddle仅支持CHW布局,而CHW只是HWC的转置,故我们在输入数据前要进行转置操作将HWC布局调整为CHW。
1 def reader_creator(flag): 2 def reader(): 3 cnt = 0 4 if flag == 'train': 5 path = './train' 6 else: 7 path = './test' 8 for label_dir in os.listdir(path): 9 if('0' in label_dir or '1' in label_dir or '2' in label_dir or '3' in label_dir): 10 label = label_dir[-1:] 11 for dir in os.listdir(path+'/'+label_dir): 12 if('.' not in dir): 13 for image_name in os.listdir(path+'/'+label_dir+'/'+dir): 14 if('png' in image_name): 15 im = Image.open(path+'/'+label_dir+'/'+dir+'/'+image_name) 16 #if path == './test': 17 # print path+'/'+label_dir+'/'+dir+'/'+image_name 18 # print label 19 try: 20 pass 21 #im = im.resize((800, 600), Image.ANTIALIAS) 22 #im = im.resize((32, 32), Image.ANTIALIAS) 23 except: 24 print 'lose frame' 25 continue 26 # 由cv2或PIL打开的图像的默认布局是HWC。 27 # PaddlePaddle仅支持CHW布局。而CHW只是HWC的转置。 28 im = np.array(im).astype(np.float32) 29 im = im.transpose((2, 0, 1)) # 转置操作,以得到CHW布局 30 im = im.flatten() 31 im = im / 255.0 32 if im.shape[0] != 230400: 33 continue 34 cnt = cnt+1 35 yield im, int(label) 36 print cnt 37 return reader
构造train reader 与test reader:
1 def train(): 2 return reader_creator('train'); 3 def test(): 4 return reader_creator('test');
3.3 搭建模型
在完成了数据预处理与Reader的构造等基础工程之后,我们就可以正式进入神经网络模型的搭建流程了。搭建模型的内容主要有以下几点:
-
定义网络结构
-
初始化PaddlePaddle
-
配置网络结构和设置参数
- 配置网络结构
- 定义损失函数cost
- 创建parameters
- 定义优化器optimizer
(1)定义网络结构
两个隐藏层激活函数选用Relu激活函数,各层均使用全连接层。
1 # 定义多层感知机结构 2 def multilayer_perceptron(img): 3 hidden1 = paddle.layer.fc(input=img, size=128, act=paddle.activation.Relu()) 4 hidden2 = paddle.layer.fc(input=hidden1, size=64, act=paddle.activation.Relu()) 5 predict = paddle.layer.fc(input=hidden2, size=4, act=paddle.activation.Softmax()) 6 return predict
(2)初始化PaddlePaddle
然后进行最基本的初始化操作,在PaddlePaddle中使用paddle.init(use_gpu=False, trainer_count=1)来进行初始化:
- use_gpu=False表示不使用gpu进行训练
- trainer_count=1表示仅使用一个训练器进行训练
1 # PaddlePaddle 初始化 2 paddle.init(use_gpu=False, trainer_count=1)
(3)配置网络结构及参数设置
定义参数及输入:
设置算法参数(如数据维度、类别数目和batch size等参数),所用数据集是桃子图片。桃子所分的种类是4,因此,classdim=4。
定义数据输入层image和类别标签lbl,本实验使用image=paddle.layer.data(name=”image”, type=paddle.data_type.dense_vector_sequence(data_dim))函数,名称为“image”,数据类型为data_dim维向量;
1 #数据格式 2 datadim = 3 * 320 *240 3 #图片类别数目 4 classdim = 4 5 # 描述神经网络的输入,定义数据输入层image 6 image = paddle.layer.data(name="image", height=320, width=240, type=paddle.data_type.dense_vector(datadim)) 7 # 定义类别标签 8 lbl = paddle.layer.data(name="label", type=paddle.data_type.integer_value(classdim))
选用net模型,使用前面定义的multilayer_perceptron()
1 # 使用net模型为 multilayer_perceptron() 2 net = multilayer_perceptron(image)
获得网络最后的Softmax层
1 # 获得网络最后的Softmax层 2 out = paddle.layer.fc(input=net, size=classdim, act=paddle.activation.Softmax())
定义损失函数
在配置网络结构之后,我们需要定义一个损失函数来计算梯度并优化参数。
1 # 定义损失函数 2 cost = paddle.layer.classification_cost(input=out, label=lbl)
创建参数
PaddlePaddle中提供了接口paddle.parameters.create(cost)来创建和初始化参数,参数cost表示基于我们刚刚创建的cost损失函数来创建和初始化参数。
1 # 利用cost创建 parameters Create parameters 2 parameters = paddle.parameters.create(cost)
创建优化器
通过 learning_rate_decay_a (简写a) 、learning_rate_decay_b (简写b) 和 learning_rate_schedule 指定学习率调整策略,这里采用离散指数的方式调节学习率。
计算公式如下, n 代表已经处理过的累计总样本数,lr0 即为参数里设置的 learning_rate。

1 # 创建 optimizer Create optimizer 2 momentum_optimizer = paddle.optimizer.Momentum( 3 momentum=0.9, 4 regularization=paddle.optimizer.L2Regularization(rate=0.0002 * 128), 5 learning_rate=0.01 / 128.0, 6 learning_rate_decay_a=0.1, 7 learning_rate_decay_b=50000 * 100, 8 learning_rate_schedule='discexp')
定义事件处理程序
定义事件处理函数可以帮助我们在训练时实时了解训练进度
1 #定义事件处理函数 2 def event_handler(event): 3 if isinstance(event, paddle.event.EndIteration): 4 # 每隔5个batch 打印一次进度 5 if event.batch_id % 5 == 0: 6 print "\nPass %d, Batch %d, Cost %f, %s" % ( 7 event.pass_id, event.batch_id, event.cost, event.metrics) 8 else: 9 sys.stdout.write('.') 10 sys.stdout.flush() 11 if isinstance(event, paddle.event.EndPass): 12 # 每隔2个pass 保存一次模型参数parameters 13 if event.pass_id %2 == 0: 14 with open('params_pass_%d.tar' % event.pass_id, 'w') as f: 15 parameters.to_tar(f) 16 17 result = trainer.test( 18 reader=paddle.batch( 19 paddle.reader.shuffle( 20 test(), buf_size=50000), batch_size=128), 21 feeding={'image': 0, 22 'label': 1}) 23 print "\nTest with Pass %d, %s" % (event.pass_id, result.metrics)
3.4 训练模型
完成了模型搭建的过程,接下来我们就可以开始模型的训练过程了,首先,我们需要用 paddle.trainer.SGD() 函数定义一个随机梯度下降trainer,配置三个参数cost、parameters、update_equation,它们分别表示损失函数、参数和更新公式。
1 # 创建训练器 2 trainer = paddle.trainer.SGD( 3 cost=cost, parameters=parameters, update_equation=momentum_optimizer)
训练器创建完成后就可以正式开始训练了,训练参数设置如下:
- paddle.reader.shuffle(train(),buf_size=20000)表示trainer从train()这个reader中读取了buf_size=20000大小的数据并打乱顺序
- paddle.batch(reader(), batch_size=128)表示从打乱的数据中再取出batch_size=128大小的数据进行一次迭代训练
- 参数feeding是feeding索引,其将数据层image和label输入trainer,也就是训练数据的来源。
- 参数event_handler是事件管理机制,读者可以自定义event_handler,根据事件信息作相应的操作。
- 参数num_passes=20 表示迭代训练20次后停止训练。
当然,这些参数可以根据需求自行设置,读者可以通过修改参数来观察其对训练结果的影响。
1 # 开始训练 2 trainer.train( 3 reader=paddle.batch( 4 paddle.reader.shuffle( 5 train(), buf_size=20000), 6 batch_size=128), 7 num_passes=20, 8 event_handler=event_handler, 9 feeding={'image': 0, 10 'label': 1})
3.5 加载模型并进行预测
模型训练完成以后,我们就可以加载训练好的来进行分类预测并观察预测效果了,首先我们需要加载训练好的模型:
1 # 加载训练的模型文件 params_pass_18.tar,可视训练效果调整所要加载的模型文件 2 with open('params_pass_18.tar', 'r') as f: 3 parameters = paddle.parameters.Parameters.from_tar(f)
加载了训练模型以后,我们同样需要对测试集数据进行处理,使之成为预测模型可以接受的输入格式,因此,测试集中的数据同样要进行转置操作,以达到PaddlePaddle输入图片CHW布局要求。
然后使用预测函数 paddle.infer(output_layer = out,parameters = parameters ,input = test_data) 进行预测,其中参数output_layer 表示输出层,参数parameters表示模型参数,参数input表示输入的测试数据。
1 for i in range(0,10000): 2 i = str(i) 3 # 选择测试集所在路径,这里选择的是类别为3的测试集,可以调整为其他类别的继续测试 4 file = './test/class3/3/'+i+'.png' 5 try: 6 im = Image.open(file) 7 except: 8 continue 9 im = np.array(im).astype(np.float32) 10 im = im.transpose((2, 0, 1)) # CHW 11 im = im.flatten() 12 im = im / 255.0 13 if im.shape[0] != 230400: 14 continue 15 # 先建立图像列表文件 16 test_data = [] 17 test_data.append((im, )) 18 19 20 probs = paddle.infer( output_layer=out, parameters=parameters, input=test_data) 21 lab = np.argsort(-probs) # probs and lab are the results of one batch data 22 # np.argsort(x) 返回的是数组值从小到大的索引值 np.argosrt(-x)返回的是数组值从大到小的索引值 23 # 输出预测结果 24 print "Label of image/%s.png is: %d" % (i,lab[0][0]) 25 print probs[0][lab[0][0]]
4.参考文献
1.https://github.com/PaddlePaddle/book/tree/develop/03.image_classification
2.https://github.com/sorting4peach/sorting4peach

 浙公网安备 33010602011771号
浙公网安备 33010602011771号