

运商大数据架构--二章(1)
架构驱动的因素
运营商和互联网面临不同的历史时期,因而大数据在各自领域承担的使命是不一样的
运营商面临被管道化的挑战,营收下滑,大数据项目承担企业战略转型、数据变现的使命。同时由于成本的压力,以及大量基础设施和设备利旧的诉求,所以运营商在大数据项目中,对性能、成本和集成度提出了很高的要求。
互联网企业近几年盈利颇丰,大数据往往是承担业务快速创新、未来探索的一种驱动因素,所以对架构的扩展性、灵活性等方面的追求优先级在成本之上。互联网企业每建一个数据中心通常就是几千台的规模,这在运营商看来是不可想象的。
背后的商业驱动因素不一样,所带来的架构挑战也不一样。
大数据平台架构
我们将以一个实际的大数据架构参与者、旁观者的角色讲述真正的实战经验,希望带给读者一些启发。前面讲到商业驱动因素不一样,所面临的场景不一样,选择的技术措施也会有所区别,但是其实存在即合理,实践出真知
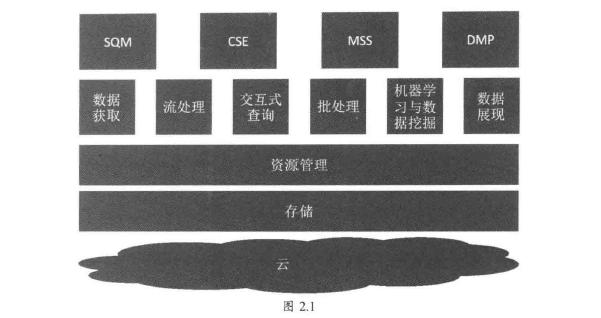
大数据平台架构如图2.1所示。可以看到,最上层是应用,大数据平台最后还是要解决实际的业务问题,在运营商领域分别解决SQM(运维质量管理)、CSE(客户体验提升)、MSS(市场运维支撑)、DMP(数据管理平台)等问题。这部分内容会在第3章详细介绍。
第二层是各个组件/技术支撑,包括数据从产生获取、处理(实时、批处理)、分析(交互式查询、机器学习与数据挖掘)到最后的展现。这部分内容会在第4、8章介绍。
第三层,为了支持数据的存储处理,需要统一的资源管理及分配。这部分内容会在第9章介绍。
第四层,上层框架和处理都构建在存储的基础上,所以存储是基础中的基础。这部分内容会在第10章介绍。
第五层,大数据部署形态有云化部署、物理机部署等多种部署模式。这部分内容会在第1 1章介绍。
第12章介绍大数据技术开发文化
平台发展趋势
Hadoop从2006年项目成立开始,已经风风雨雨走过了10年,从最开始的HDFS和MapReduce 两个组件到现在完整的生态链。展望未来,随着技术和业务的发展,下面这些趋势应该是所有设计和实现大数据平台的人需要认真考虑的。
· Cloud First:云优先。服务端利用云的部署和扩展能力,保证数据访问高并发、高可用、高可靠。
· stream Default:流优先。数据源端更多的是流数据,要求实时分析,进行秒级或分钟级计算。
· Pervasive Analytics:普适分析。将分析能力推至数据源端、管道和服务端,低时延反馈结果
· self service:自服务。无须太多的人为干预和人力投人,使得数据合理放置,转换为适合分析的数据类型,方便APP开发等。
现在看着风光无限的组件或者平台,会不断地被后来者所替代。
小结
本章简要总结了本书的主要章节和内容。本书是围绕一个通用的大数据处理逻辑架构来展开的。在实际的生产环境中,该架构并不是一成不变的,会根据业务来灵活地部署和应用。当然,在一个完整的企业大数据系统里,本书介绍的内容完全不够,本书只介绍最基础的大数据平台,很多底层或者上层的内容可能没有覆盖到。另外,架构不是凭空出现的,由业务场景驱动的架构才是真正可用的架构。
谢谢支持,喜欢关注哟!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号