python爬虫之爬取世界人口排名
(一)、选题的背景
对2021世界各国人口数量,人口密度以及人口增长率进行数据分析,对世界排名和人口密度二者之间的关系分析,进行数据分析和可视化。可以让我们更好的直观各国人口的变化以及增长率,有利于人民预测各国的人口增长数量和分析各国人口增长所呈现出的增长率同国家、地理、社会因素之间的关系。
(二)、主题式网络爬虫设计方案
1.主题式网络爬虫名称
《python爬虫之爬取世界人口排名》
2.主题式网络爬虫爬取的内容与数据特征分析
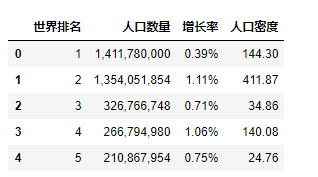
爬取内容:"世界排名","国家名称","人口数量","增长率","人口密度"
数据特征分析:"世界排名"、"人口密度"的之间关系整体呈现上升的趋势,可通过后续绘制直方图、折线图等观察数据的变化情况。
3.主题式网络爬虫设计方案概述
实现思路:在浏览器 中通过F12访问网页源代码,,分析网站源代码,找到自己所需要的数据所在的位置,提取数据,对数据进行保存到相同路径csv文件中,读取改文件,进行数据清洗,数据模型分析,数据可视化处理,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和绘制拟合曲线。
技术难点:对库使用和库中函数的运用,爬取的内容的机构分析处理做数据分析,即求回归系数,因为标题是文字,无法与数字作比较,需要把标题这一列删除才可。由于不明原因,输出结果经常会显示超出列表范围。
(三)、主题页面的结构特征分析(10 分)
1.主题页面的结构与特征分析
url= 'https://www.phb123.com/city/renkou/rk.html'
通过页面的结构分析,可以得到各个数据之间的便签都有关联的关系,<tr><th width="12%">世界排名</th><th width="30%">国家</th><th width="20%">人口数量</th><th width="12%">增长率</th><th width="26%">人口密度(公里²)</th>这种形式如下图所示。
2.Htmls 页面解析


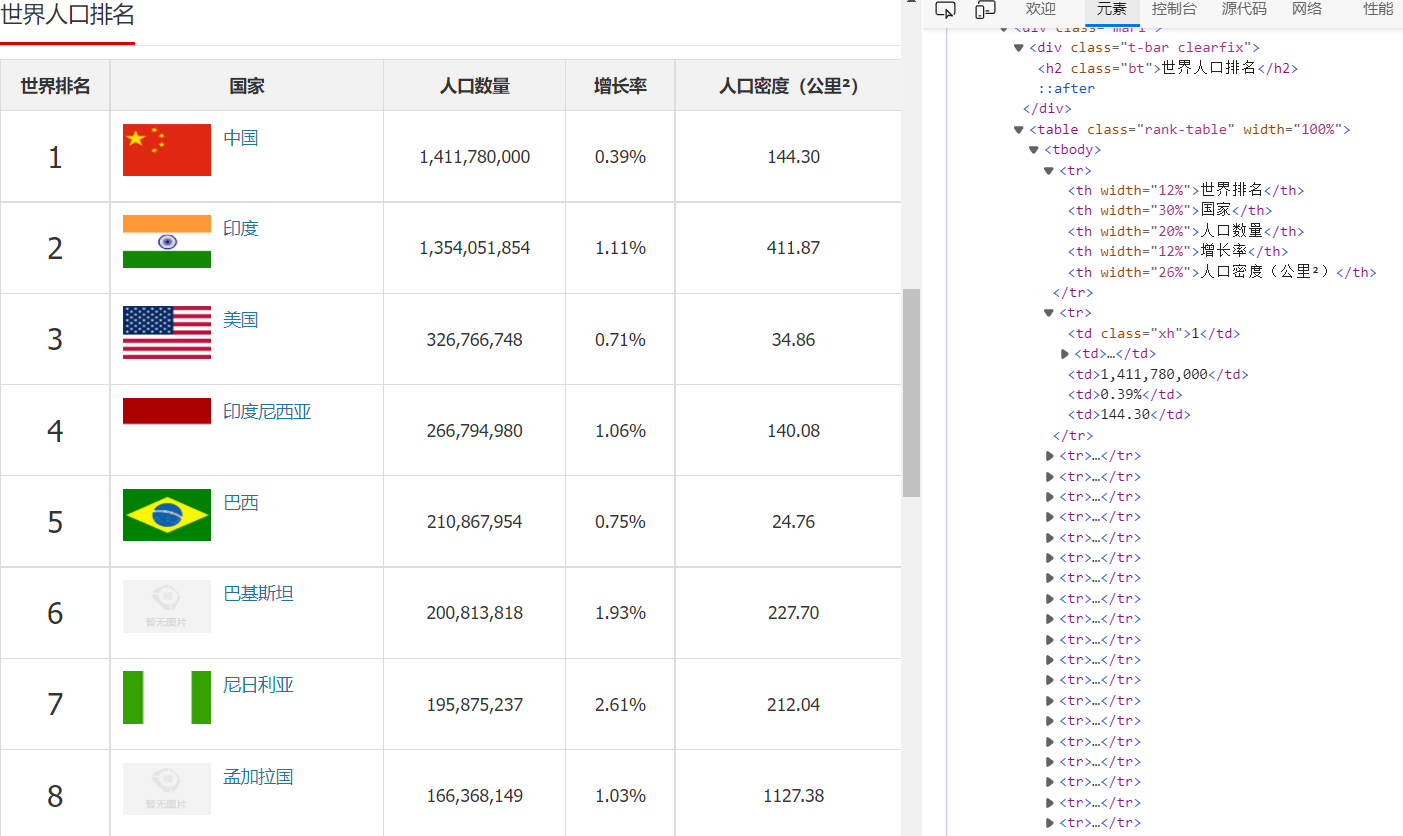
3.节点(标签)查找方法与遍历方法
节点如下图所示:
<td class="xh">1</td>
<td>
<a href="/city/renkou/country_1.html" title="中国" target="_blank" class="cty">
<span class="fl"><img src="https://img.phb123.com/uploads/guoqi/CN.jpg" alt="中国" width="70" height="42"></span>
<p>中国</p>
</a>
</td>
<td>1,411,780,000</td>
<td>0.39%</td>
<td>144.30</td>
</tr><tr>
<td class="xh">2</td>
<td>
<a href="/city/renkou/country_2.html" title="印度" target="_blank" class="cty">
<span class="fl"><img src="https://img.phb123.com/uploads/guoqi/IN.jpg" alt="印度" width="70" height="42"></span>
<p>印度</p>
</a>
</td>
<td>1,354,051,854</td>
<td>1.11%</td>
<td>411.87</td>
</tr><tr>
<td class="xh">3</td>
<td>
<a href="/city/renkou/country_3.html" title="美国" target="_blank" class="cty">
(
(四)、网络爬虫程序设计(60 分)
1.数据爬取与采集
1 import requests 2 from bs4 import BeautifulSoup 3 import pandas as pd 4 5 headers = { 6 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' 7 }#爬虫[Requests设置请求头Headers],伪造浏览器 8 # 核心爬取代码https://www.phb123.com/city/renkou/rk_9.html 9 listData=[] #定义数组 10 counData=[] #定义数组 11 for i in range(1,10): 12 if i==1: 13 url= 'https://www.phb123.com/city/renkou/rk.html' 14 else: 15 url = 'https://www.phb123.com/city/renkou/rk_%s.html'%i 16 params = {"show_ram":1} 17 response = requests.get(url,params=params, headers=headers) #访问url 18 soup = BeautifulSoup(response.text, 'html.parser') #获取网页源代码 19 tr = soup.find('table',class_='rank-table').find_all('tr') #.find定位到所需数据位置 .find_all查找所有的tr(表格) 20 # 去除标签栏 21 for j in tr[1:]: #tr[1:]遍历第1列到最后一列,表头为第0列 22 td = j.find_all('td')#td表格 23 rank = td[0].get_text().strip() #世界排名 24 country = td[1].get_text().strip() #国家 25 counData.append(country) 26 number = td[2].get_text().strip() #人口数量 27 growth = td[3].get_text().strip() #增长率 28 density = td[4].get_text().strip() #人口密度 29 listData.append([rank,country,number,growth,density]) 30 31 32 # 存储结果 33 df = pd.DataFrame(listData,columns=["世界排名","国家名称","人口数量","增长率","人口密度"]) 34 print(df) 35 df.to_csv('世界人口排名2020.csv',encoding = 'gbk') #保存文件,数据持久化 36 df 37 df.to_csv("世界人口排名2020.csv",index=False)
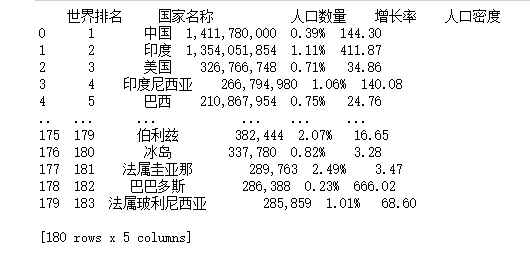

2.对数据进行清洗和处理
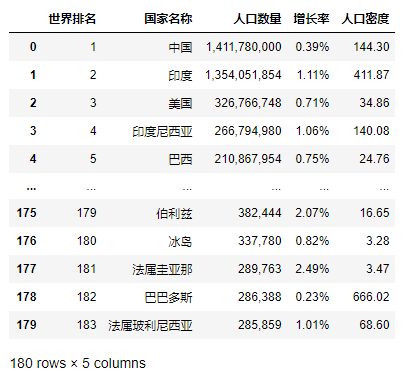
#读取csv文件 import pandas as pd df = pd.DataFrame(pd.read_csv("世界人口排名2021.csv")) df
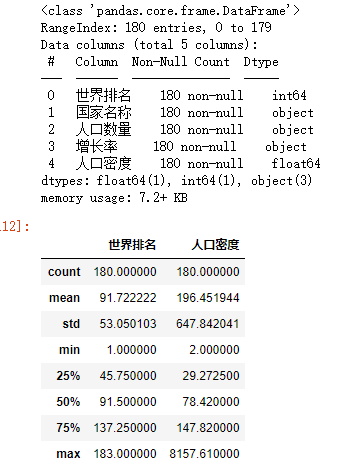
df.info() #使用describe查看统计信息 df.describe()
from sklearn.linear_model import LinearRegression X = df.drop("国家名称", axis = 1) #X是删除了国家名称列后的DataFrame X.head()
#统计“数值”一列中空值的个数 df['人口数量'].isnull().value_counts()
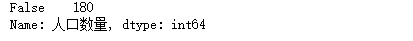
#查找重复值 df.duplicated()

3.文本分析(可选):jieba 分词、wordcloud 的分词可视化
1 # 3.文本分析(可选):jieba 分词、wordcloud 的分词可视化 2 #使用jieba分词 3 file=open('世界人口排名2021.csv',encoding='utf_8') 4 user_dict=file.read() 5 print(user_dict) 6 #读取文件,用jieba进行文本分词并保存文件中 7 asd_excel=open('世界人口排名2021.csv','r',encoding='utf_8').read() 8 #读取文件,编码格式utf-8,防止处理中文出错 9 import jieba.posseg as psg 10 asd_words_with_attr=[(x.word,x.flag)for x in psg.cut(asd_excel) if len(x.word)>=2] 11 #x.word为词本身,x.flag为词性 12 print(len(asd_words_with_attr))#输出 13 with open('cut_words.txt','w+')as f: 14 for x in asd_words_with_attr: 15 f.write('{0}\t{1}\n'.format(x[0],x[1])) 16 #从cut_words.txt中读取带词性的分词结果列表 17 asd_words_with_attr=[] 18 with open('cut_words.txt','w+')as f: 19 for x in f.readlines(): 20 pair=x.split() 21 asd_words_with_attr.append((pair[0],pair[1])) 22 #stop_attr中存放要过滤掉的词性列表 23 stop_attr=['vn','n'] 24 #过滤清洗数据,将结果存放在words中 25 words=[x[0]for x in asd_words_with_attr if x[1] not in stop_attr]
4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)
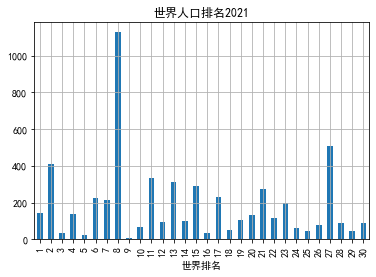
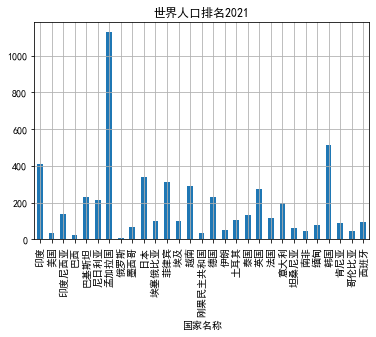
#直方图 import pandas as pd import numpy as np import matplotlib.pyplot as plt import pandas as pd import warnings plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False filename = "世界人口排名2021.csv" colnames=["世界排名","国家名称","人口数量","增长率","人口密度"] #skiprows用于指定跳过csv文件的头部的前几行(标题等无效数据,否则程序会报错) df = pd.read_csv(filename,skiprows=1,names=colnames) data=np.array(df['人口密度'][:30]) index=df['世界排行'][:30] s = pd.Series(data,index) s.name='世界人口排名2021' s.plot(kind='bar',title='世界人口排名2021') plt.grid() plt.s #2 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False filename = "世界人口排名2020.csv" colnames=["世界排名","国家名称","人口数量","增长率","人口密度"] #skiprows用于指定跳过csv文件的头部的前几行(标题等无效数据,否则程序会报错) df = pd.read_csv(filename,skiprows=1,names=colnames) data=np.array(df['人口密度'][1:30]) index=df['国家名称'][1:30] s = pd.Series(data,index) s.name='世界人口排名2021' s.plot(kind='bar',title='世界人口排名2021') plt.grid() plt.show()
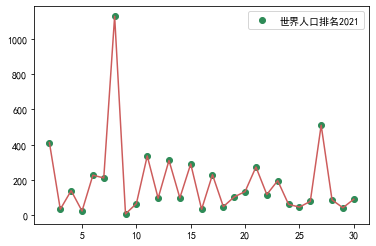
#折线图 import numpy as np import matplotlib.pyplot as plt import pandas as pd df=pd.read_csv('世界人口排名2021.csv') print(df.head()) x=df["世界排名"][1:30] y=df["人口密度"][1:30] plt.plot(x,y,'o', color='seagreen') plt.plot(x,y,'-', color='indianred') plt.legend(labels=['世界人口排名2021'])#添加图标 plt.show()
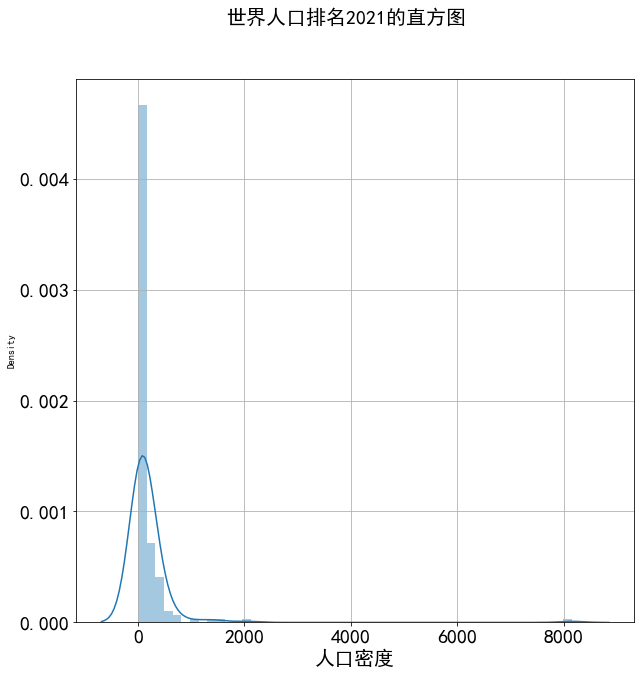
# 直方图 import seaborn as sns plt.figure(figsize=(10,10)) plt.suptitle('世界人口排名2021的直方图',fontsize=20) plt.xticks(fontsize=20) plt.yticks(fontsize=20) plt.xlabel("世界排行",fontsize=20) sns.distplot(df["人口密度"]) plt.grid() plt.show()
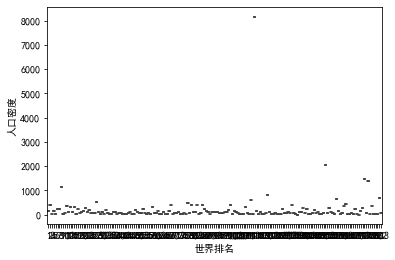
#盒图 plt.xlabel("世界排名") plt.ylabel("人口密度") sns.boxplot(x='世界排名',y='人口密度',data=df)
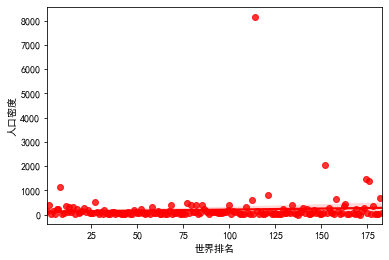
# “世界人口排名2020“中人口数量和增长率之间的散点图 import pandas as pd import numpy as np import matplotlib.pyplot as plt import pandas as pd plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False filename = '世界人口排名2021.csv' colnames=["世界排名","国家名称","人口数量","增长率","人口密度"] #skiprows用于指定跳过csv文件的头部的前几行(标题等无效数据,否则程序会报错) df = pd.read_csv(filename,skiprows=1,names=colnames) plt.scatter(df["人口数量"][1:15],df["增长率"][1:15],alpha = 0.6) plt.title("世界人口排名2021") plt.grid() plt.show()
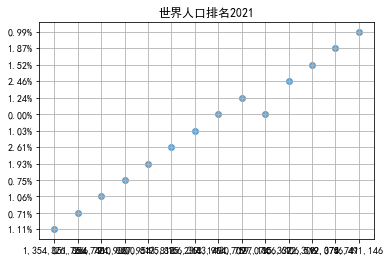
# “世界人口排名2020“中世界排名和人口密度之间的散点图 import pandas as pd import numpy as np import matplotlib.pyplot as plt import pandas as pd plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False filename = '世界人口排名2021.csv' colnames=["世界排名","国家名称","人口数量","增长率","人口密度"] #skiprows用于指定跳过csv文件的头部的前几行(标题等无效数据,否则程序会报错) df = pd.read_csv(filename,skiprows=1,names=colnames) plt.scatter(df["世界排名"][:20],df["人口密度"][:20],alpha = 0.6) plt.title("世界人口排名2021") plt.grid() plt.show()
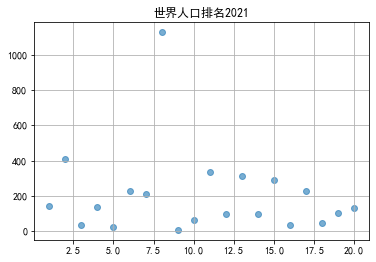
#散点图 # 用来正常显示中文标签 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示负号 plt.rcParams['axes.unicode_minus'] = False #x,y轴 plt.xlabel("世界排名") plt.ylabel("人口密度") sns.regplot(x='世界排名',y='人口密度',data=df,color='r') # kind='hex' sns.jointplot(x="世界排名",y="人口密度",data=df,kind='hex') # kind='kde' sns.jointplot(x="世界排名",y="人口密度",data=df,kind="kde",space=0,color='g') #盒图 plt.xlabel("世界排名") plt.ylabel("人口密度") sns.boxplot(x='世界排名',y='人口密度',data=df)
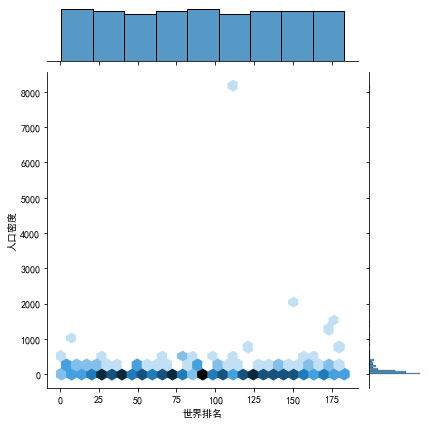

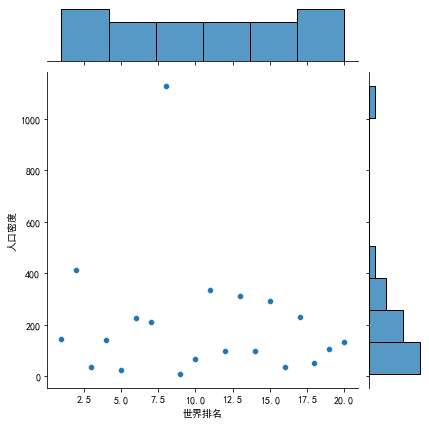
#分布图 sns.jointplot(df["世界排名"][:20],df["人口密度"][:20])
fig,axes=plt.subplots(2,2) #1.默认绘图效果 sns.regplot(x='世界排名',y='人口密度',data=df,ax=axes[0][0]) #2.ci参数可以控制是否显示置信区间 sns.regplot(x='世界排名',y='人口密度',data=df,ci=None,ax=axes[0][1]) #3.mark参数可以设置数据点格式,color参数可以设置颜色 sns.regplot(x='世界排名',y='人口密度',data=df,color='g',marker='*',ax=axes[1][0]) #4.fit_reg参数可以控制是否显示拟合的直线 sns.regplot(x='世界排名',y='人口密度',data=df,color='g',marker='+',fit_reg=False,ax=axes[1][1])
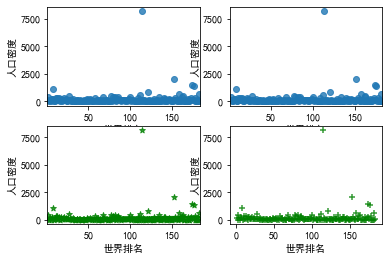
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变
量之间的回归方程(一元或多元)。
1 #选择世界排名以及人口数量两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 filename = '世界人口排名2021.csv' 5 colnames=["世界排名","国家名称","人口数量","增长率","人口密度"] 6 df = pd.read_csv(filename,skiprows=1,names=colnames) 7 X = df["世界排名"][1:20] 8 Y = df["人口密度"][1:20] 9 def A(): 10 plt.scatter(X,Y,color="blue",linewidth=2) 11 plt.title("总情况",color="blue") 12 plt.grid() 13 plt.show() 14 def B(): 15 plt.scatter(X,Y,color="green",linewidth=2) 16 plt.title("总情况",color="blue") 17 plt.grid() 18 plt.show() 19 def func(p,x): 20 a,b,c=p 21 return a*x*x+b*x+c 22 def error(p,x,y): 23 return func(p,x)-y 24 def main(): 25 plt.figure(figsize=(10,6)) 26 p0=[0,0,0] 27 Para = leastsq(error,p0,args=(X,Y)) 28 a,b,c=Para[0] 29 print("a=",a,"b=",b,"c=",c) 30 plt.scatter(X,Y,color="blue",linewidth=2) 31 x=np.linspace(0,20,20) 32 y=a*x*x+b*x+c 33 plt.plot(x,y,color="blue",linewidth=2,) 34 plt.title("总情况") 35 plt.grid() 36 plt.show() 37 print(A()) 38 print(B()) 39 print(main())
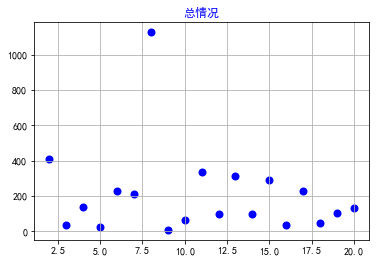
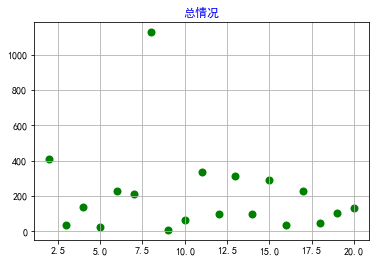

6.数据持久化
#6.数据持久化 df = pd.DataFrame(listData,columns=["世界排名","国家名称","人口数量","增长率","人口密度"]) df.to_csv('世界人口排名2020.csv',encoding = 'gbk') #保存文件,数据持久化
7.将以上各部分的代码汇总,附上完整程序代码
1 # 1.数据爬取与采集 2 import requests 3 from bs4 import BeautifulSoup 4 import pandas as pd 5 6 headers = { 7 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' 8 }#爬虫[Requests设置请求头Headers],伪造浏览器 9 # 核心爬取代码https://www.phb123.com/city/renkou/rk_9.html 10 listData=[] #定义数组 11 counData=[] #定义数组 12 for i in range(1,10): 13 if i==1: 14 url= 'https://www.phb123.com/city/renkou/rk.html' 15 else: 16 url = 'https://www.phb123.com/city/renkou/rk_%s.html'%i 17 params = {"show_ram":1} 18 response = requests.get(url,params=params, headers=headers) #访问url 19 soup = BeautifulSoup(response.text, 'html.parser') #获取网页源代码 20 tr = soup.find('table',class_='rank-table').find_all('tr') #.find定位到所需数据位置 .find_all查找所有的tr(表格) 21 # 去除标签栏 22 for j in tr[1:]: #tr[1:]遍历第1列到最后一列,表头为第0列 23 td = j.find_all('td')#td表格 24 rank = td[0].get_text().strip() #世界排名 25 country = td[1].get_text().strip() #国家 26 counData.append(country) 27 number = td[2].get_text().strip() #人口数量 28 growth = td[3].get_text().strip() #增长率 29 density = td[4].get_text().strip() #人口密度 30 listData.append([rank,country,number,growth,density]) 31 32 33 # 存储结果 34 df = pd.DataFrame(listData,columns=["世界排名","国家名称","人口数量","增长率","人口密度"]) 35 print(df) 36 df.to_csv('世界人口排名2020.csv',encoding = 'gbk') #保存文件,数据持久化 37 df 38 df.to_csv("世界人口排名2020.csv",index=False) 39 40 # 2.对数据进行清洗和处理 41 42 #读取csv文件 43 df = pd.DataFrame(pd.read_csv("世界人口排名2021.csv")) 44 45 df.head() 46 df.shape 47 df.info() 48 #使用describe查看统计信息 49 df.describe() 50 51 from sklearn.linear_model import LinearRegression 52 X = df.drop("国家名称", axis = 1) #X是删除了国家名称列后的DataFrame 53 Y = df.drop("人口数量", axis = 1) 54 Y.head() 55 X.head() 56 #统计“数值”一列中空值的个数 57 df['人口数量'].isnull().value_counts() 58 #查找重复值 59 df.duplicated() 60 61 # 3.文本分析(可选):jieba 分词、wordcloud 的分词可视化 62 #使用jieba分词 63 file=open('世界人口排名2021.csv',encoding='utf_8') 64 user_dict=file.read() 65 print(user_dict) 66 #读取文件,用jieba进行文本分词并保存文件中 67 asd_excel=open('世界人口排名2021.csv','r',encoding='utf_8').read() 68 #读取文件,编码格式utf-8,防止处理中文出错 69 import jieba.posseg as psg 70 asd_words_with_attr=[(x.word,x.flag)for x in psg.cut(asd_excel) if len(x.word)>=2] 71 #x.word为词本身,x.flag为词性 72 print(len(asd_words_with_attr))#输出 73 with open('cut_words.txt','w+')as f: 74 for x in asd_words_with_attr: 75 f.write('{0}\t{1}\n'.format(x[0],x[1])) 76 #从cut_words.txt中读取带词性的分词结果列表 77 asd_words_with_attr=[] 78 with open('cut_words.txt','w+')as f: 79 for x in f.readlines(): 80 pair=x.split() 81 asd_words_with_attr.append((pair[0],pair[1])) 82 #stop_attr中存放要过滤掉的词性列表 83 stop_attr=['vn','n'] 84 #过滤清洗数据,将结果存放在words中 85 words=[x[0]for x in asd_words_with_attr if x[1] not in stop_attr] 86 87 # 4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图) 88 #4.1世界人口排名2021中世界排行和人口密度的 89 #柱状图 90 import pandas as pd 91 import numpy as np 92 import matplotlib.pyplot as plt 93 import pandas as pd 94 import warnings 95 plt.rcParams['font.sans-serif'] = ['SimHei'] 96 plt.rcParams['axes.unicode_minus'] = False 97 filename = "世界人口排名2021.csv" 98 colnames=["世界排名","国家名称","人口数量","增长率","人口密度"] 99 #skiprows用于指定跳过csv文件的头部的前几行(标题等无效数据,否则程序会报错) 100 df = pd.read_csv(filename,skiprows=1,names=colnames) 101 data=np.array(df['人口密度'][:30]) 102 index=df['世界排名'][:30] 103 s = pd.Series(data,index) 104 s.name='世界人口排名2021' 105 s.plot(kind='bar',title='世界人口排名2021') 106 plt.grid() 107 plt.show() 108 109 #2 110 plt.rcParams['font.sans-serif'] = ['SimHei'] 111 plt.rcParams['axes.unicode_minus'] = False 112 113 filename = "世界人口排名2020.csv" 114 colnames=["世界排名","国家名称","人口数量","增长率","人口密度"] 115 #skiprows用于指定跳过csv文件的头部的前几行(标题等无效数据,否则程序会报错) 116 df = pd.read_csv(filename,skiprows=1,names=colnames) 117 118 data=np.array(df['人口密度'][1:30]) 119 index=df['国家名称'][1:30] 120 s = pd.Series(data,index) 121 s.name='世界人口排名2021' 122 123 s.plot(kind='bar',title='世界人口排名2021') 124 plt.grid() 125 plt.show() 126 127 #折线图 128 import numpy as np 129 import matplotlib.pyplot as plt 130 import pandas as pd 131 df=pd.read_csv('世界人口排名2021.csv') 132 print(df.head()) 133 x=df["世界排名"][1:30] 134 y=df["人口密度"][1:30] 135 plt.plot(x,y,'o', color='seagreen') 136 plt.plot(x,y,'-', color='indianred') 137 plt.legend(labels=['世界人口排名2021'])#添加图标 138 plt.show() 139 140 # 直方图 141 import seaborn as sns 142 plt.figure(figsize=(10,10)) 143 plt.suptitle('世界人口排名2021的直方图',fontsize=20) 144 plt.xticks(fontsize=20) 145 plt.yticks(fontsize=20) 146 plt.xlabel("世界排行",fontsize=20) 147 sns.distplot(df["人口密度"]) 148 plt.grid() 149 plt.show() 150 151 #盒图 152 plt.xlabel("世界排名") 153 plt.ylabel("人口密度") 154 sns.boxplot(x='世界排名',y='人口密度',data=df) 155 156 # 散点图 157 import pandas as pd 158 import numpy as np 159 import matplotlib.pyplot as plt 160 import pandas as pd 161 plt.rcParams['font.sans-serif'] = ['SimHei'] 162 plt.rcParams['axes.unicode_minus'] = False 163 filename = '世界人口排名2021.csv' 164 colnames=["世界排名","国家名称","人口数量","增长率","人口密度"] 165 #skiprows用于指定跳过csv文件的头部的前几行(标题等无效数据,否则程序会报错) 166 df = pd.read_csv(filename,skiprows=1,names=colnames) 167 plt.scatter(df["世界排名"][:20],df["人口密度"][:20],alpha = 0.6) 168 plt.title("世界人口排名2021") 169 plt.grid() 170 plt.show() 171 172 # “世界人口排名2020“中人口数量和增长率之间的散点图 173 import pandas as pd 174 import numpy as np 175 import matplotlib.pyplot as plt 176 import pandas as pd 177 plt.rcParams['font.sans-serif'] = ['SimHei'] 178 plt.rcParams['axes.unicode_minus'] = False 179 filename = '世界人口排名2021.csv' 180 colnames=["世界排名","国家名称","人口数量","增长率","人口密度"] 181 #skiprows用于指定跳过csv文件的头部的前几行(标题等无效数据,否则程序会报错) 182 df = pd.read_csv(filename,skiprows=1,names=colnames) 183 plt.scatter(df["人口数量"][1:15],df["增长率"][1:15],alpha = 0.6) 184 plt.title("世界人口排名2021") 185 plt.grid() 186 plt.show() 187 188 #散点图 189 # 用来正常显示中文标签 190 plt.rcParams['font.sans-serif'] = ['SimHei'] 191 # 用来正常显示负号 192 plt.rcParams['axes.unicode_minus'] = False 193 #x,y轴 194 plt.xlabel("世界排名") 195 plt.ylabel("人口密度") 196 sns.regplot(x='世界排名',y='人口密度',data=df,color='r') 197 # kind='hex' 198 sns.jointplot(x="世界排名",y="人口密度",data=df,kind='hex') 199 # kind='kde' 200 sns.jointplot(x="世界排名",y="人口密度",data=df,kind="kde",space=0,color='g') 201 #盒图 202 plt.xlabel("世界排名") 203 plt.ylabel("人口密度") 204 sns.boxplot(x='世界排名',y='人口密度',data=df) 205 206 #分布图 207 sns.jointplot(df["世界排名"][:20],df["人口密度"][:20]) 208 209 #回归图 210 fig,axes=plt.subplots(2,2) 211 #1.默认绘图效果 212 sns.regplot(x='世界排名',y='人口密度',data=df,ax=axes[0][0]) 213 #2.ci参数可以控制是否显示置信区间 214 sns.regplot(x='世界排名',y='人口密度',data=df,ci=None,ax=axes[0][1]) 215 #3.mark参数可以设置数据点格式,color参数可以设置颜色 216 sns.regplot(x='世界排名',y='人口密度',data=df,color='g',marker='*',ax=axes[1][0]) 217 #4.fit_reg参数可以控制是否显示拟合的直线 218 sns.regplot(x='世界排名',y='人口密度',data=df,color='g',marker='+',fit_reg=False,ax=axes[1][1]) 219 220 #5选择世界排名以及人口数量两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 221 import pandas as pd 222 import matplotlib.pyplot as plt 223 filename = '世界人口排名2021.csv' 224 colnames=["世界排名","国家名称","人口数量","增长率","人口密度"] 225 df = pd.read_csv(filename,skiprows=1,names=colnames) 226 X = df["世界排名"][1:20] 227 Y = df["人口密度"][1:20] 228 def A(): 229 plt.scatter(X,Y,color="blue",linewidth=2) 230 plt.title("总情况",color="blue") 231 plt.grid() 232 plt.show() 233 def B(): 234 plt.scatter(X,Y,color="green",linewidth=2) 235 plt.title("总情况",color="blue") 236 plt.grid() 237 plt.show() 238 def func(p,x): 239 a,b,c=p 240 return a*x*x+b*x+c 241 def error(p,x,y): 242 return func(p,x)-y 243 def main(): 244 plt.figure(figsize=(10,6)) 245 p0=[0,0,0] 246 Para = leastsq(error,p0,args=(X,Y)) 247 a,b,c=Para[0] 248 print("a=",a,"b=",b,"c=",c) 249 plt.scatter(X,Y,color="blue",linewidth=2) 250 x=np.linspace(0,20,20) 251 y=a*x*x+b*x+c 252 plt.plot(x,y,color="blue",linewidth=2,) 253 plt.title("总情况") 254 plt.grid() 255 plt.show() 256 print(A()) 257 print(B()) 258 print(main()) 259 260 #6.数据持久化 261 df = pd.DataFrame(listData,columns=["世界排名","国家名称","人口数量","增长率","人口密度"]) 262 df.to_csv('世界人口排名2020.csv',encoding = 'gbk') #保存文件,数据持久化
(五)、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
通过对数据进行可视化分析发现,在世界人口数量排名居中的国家人口密度相较于排名靠前或靠后的国家更高一点,这种结果可能与各个国家的面积和人口增长率相关,人口数量排名越靠前的国家其增长率越高。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
通过这次的课程设计,更好的巩固了我们所学习的知识,除此之外还了解了许多课堂之外的知识。让我们学会懂得利用网络来为自己解惑。让我们掌握Python基本概念、编程思想以及程序设计技术,在完成课程的学习后能够更加熟练地综合应用Python技术,提高我们自身程序设计水平和计算机应用能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号