k8s
kubernetes
一、kubernetes介绍
container runtime interface #CRI,容器运行时 runc/rkt K8s 定义的一组与容器运行时进行交互的接口
container storage interface #CSI,ceph/netapp 存储标准
container network interface #CNI kubernetes和coreOS提出的容器网络接口标准
#核心组件:
apiserver:提供资源操作的唯一入口,并提供认证、授权、访问控制、api注册和发现等机制
controller mananger: 负责维护整个集群的状态。比如故障检测、自动扩展、滚动更新等
scheduler: 负责资源调度,按照预定的调度策略将Pod调度到相应的机器上
kubelet: 负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理
kuber-proxy: 负责为Service提供cluster内部的服务发现和负载均衡
etcd: 保存了整个集群的状态
#可选组件:
kube-dns: 负责为整个集群提供dns服务
Ingress Controller: 为服务提供外网入口
Heapster: 提供资源监控
Dashboard: 提供GUI
Federation: 提供跨可用区的集群
Fluentd-elasticsearch: 提供集群日志采集、存储与查询
二、kubernetes安装
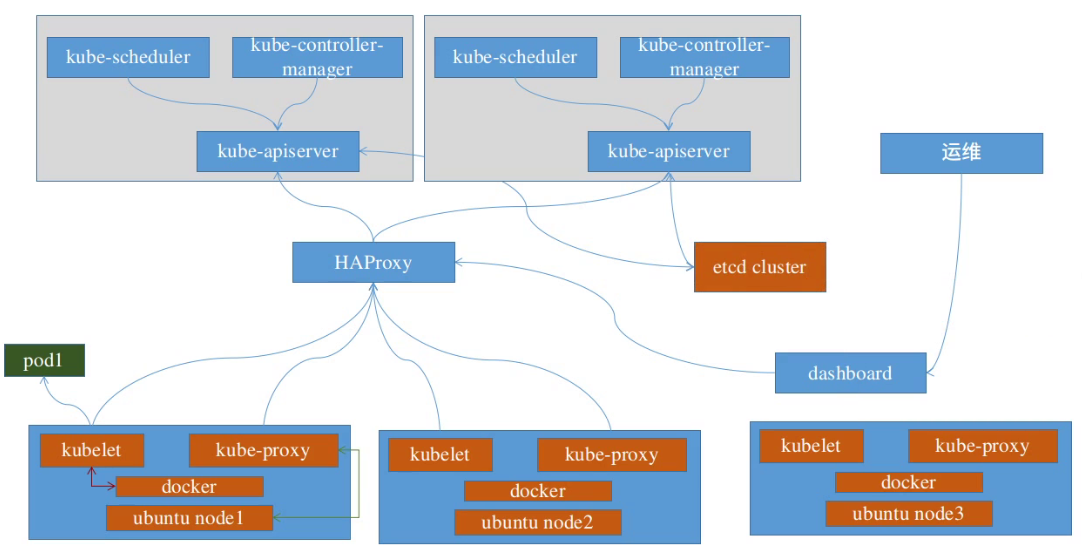
2.1 kubeadm安装kubernetes--规划部署
架构图
管理端配置: 4c 4g
centos 7.3或以上版本,关闭iptables、selinux、NetworkManager、swap分区
#地址规划
master(apiserver、scheduler、controller manager): 172.16.1.45/46/47
两个代理haproxy: 172.16.1.48/49
harbor: 172.16.1.53
node节点: 172.16.1.50/51/52
etcd cluster: 172.16.1.54
2.1.1 系统初始化(关闭swap分区、时间同步、系统优化)
#修改时区,同步时间
yum install chrond -y
vim /etc/chrony.conf
-----
ntpdate ntp1.aliyun.com iburst
-----
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
echo 'Asia/Shanghai' > /etc/timezone
#关闭防火墙,selinux
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/enforcing/disabled/' /etc/selinux/config
setenforce 0
## 关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
#系统优化
cat > /etc/sysctl.d/k8s_better.conf << EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
vm.swappiness=0
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
modprobe br_netfilter
lsmod |grep conntrack
modprobe ip_conntrack
sysctl -p /etc/sysctl.d/k8s_better.conf
#确保每台机器的uuid不一致,如果是克隆机器,修改网卡配置文件删除uuid那一行
cat /sys/class/dmi/id/product_uuid
2.1.2 安装ipvs 转发支持 【所有节点】
###系统依赖包
yum -y install wget jq psmisc vim net-tools nfs-utils socat telnet device-mapper-persistent-data lvm2 git network-scripts tar curl -y
yum install -y conntrack ipvsadm ipset jq iptables curl sysstat libseccomp wget vim net-tools git
### 开启ipvs 转发
modprobe br_netfilter
cat > /etc/sysconfig/modules/ipvs.modules << EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules
bash /etc/sysconfig/modules/ipvs.modules
lsmod | grep -e ip_vs -e nf_conntrack
2.1.3 apt安装kubeadm
1、更新 apt 包索引并安装使用 Kubernetes apt 仓库所需要的包:
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
2、下载用于 Kubernetes 软件包仓库的公共签名密钥。所有仓库都使用相同的签名密钥,因此你可以忽略URL中的版本:
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.28/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
3、添加 Kubernetes apt 仓库。 请注意,此仓库仅包含适用于 Kubernetes 1.28 的软件包; 对于其他 Kubernetes 次要版本,则需要更改 URL 中的 Kubernetes 次要版本以匹配你所需的次要版本 (你还应该检查正在阅读的安装文档是否为你计划安装的 Kubernetes 版本的文档)。
# 此操作会覆盖 /etc/apt/sources.list.d/kubernetes.list 中现存的所有配置。
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
4、更新 apt 包索引,安装 kubelet、kubeadm 和 kubectl,并锁定其版本:
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
说明:
在 Debian 12 和 Ubuntu 22.04 之前的早期版本中,默认情况下不存在 /etc/apt/keyrings 目录; 你可以通过运行 sudo mkdir -m 755 /etc/apt/keyrings 来创建它。
2.1.4 docker及cri-docker安装优化:
如果你过去安装过 docker,先删掉:
for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do apt-get remove $pkg; done
首先安装依赖:
apt-get update
apt-get install ca-certificates curl gnupg
信任 Docker 的 GPG 公钥并添加仓库:(Ubuntu)
install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
tee /etc/apt/sources.list.d/docker.list > /dev/null
最后安装docker
apt-get update
apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
编译安装cri-dockerd
安装cri-dockerd
# 由于1.24以及更高版本不支持docker所以安装cri-docker
# 下载cri-docker
# wget https://ghproxy.com/https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.1/cri-dockerd-0.3.1.amd64.tgz
# 解压cri-docker
tar -zxvf cri-dockerd-0.3.1.amd64.tgz
cp cri-dockerd/cri-dockerd /usr/bin/
chmod +x /usr/bin/cri-dockerd
# 写入启动配置文件
cat > /usr/lib/systemd/system/cri-docker.service <<EOF
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
EOF
# 写入socket配置文件
cat > /usr/lib/systemd/system/cri-docker.socket <<EOF
[Unit]
Description=CRI Docker Socket for the API
PartOf=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
EOF
# 进行启动cri-docker
systemctl daemon-reload ; systemctl enable cri-docker --now
apt仓库安装配置cri-docker 环境
配置cri-docker
# libcgroup 安装
# yum install -y libcgroup
Ubuntu 安装libcgroup
$ sudo apt-get update
$ sudo apt-get install libcgroup-dev
# wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.4/cri-dockerd-0.3.4-3.el8.x86_64.rpm
# rpm -ivh cri-dockerd-0.3.4-3.el8.x86_64.rpm
# vim /usr/lib/systemd/system/cri-docker.service
----
修改第10行内容
ExecStart=/usr/bin/cri-dockerd --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9 --container-runtime-endpoint fd://
----
2.1.5 修改cgroup Driver
修改docker的Cgroup Driver与kubelet的保持一致:
修改cgroup方式
mkdir -p /etc/docker
在/etc/docker/daemon.json添加如下内容
# cat /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
修改kubelet的cgroup:
为了实现docker使用的cgroupdriver与kubelet使用的cgroup的一致性,建议修改如下文件内容。
# vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
设置kubelet为开机自启动即可,由于没有生成配置文件,集群初始化后自动启动
# systemctl enable kubelet
https://blog.51cto.com/flyfish225/7253183:底层容器引擎用containerd
2.1.6 kubeadm init初始化
"init" 命令执行以下阶段
preflight 预检
certs 生成证书
/ca 生成自签名根 CA 用于配置其他 kubernetes 组件
/apiserver 生成 apiserver 的证书
/apiserver-kubelet-client 生成 apiserver 连接到 kubelet 的证书
/front-proxy-ca 生成前端代理自签名CA(扩展apiserver)
/front-proxy-client 生成前端代理客户端的证书(扩展 apiserver)
/etcd-ca 生成 etcd 自签名 CA
/etcd-server 生成 etcd 服务器证书
/etcd-peer 生成 etcd 节点相互通信的证书
/etcd-healthcheck-client 生成 etcd 健康检查的证书
/apiserver-etcd-client 生成 apiserver 访问 etcd 的证书
/sa 生成用于签署服务帐户令牌的私钥和公钥
kubeconfig 生成建立控制平面和管理所需的所有 kubeconfig 文件
/admin 生成一个 kubeconfig 文件供管理员使用以及供 kubeadm 本身使用
/super-admin 为超级管理员生成 kubeconfig 文件
/kubelet 为 kubelet 生成一个 kubeconfig 文件,*仅*用于集群引导
/controller-manager 生成 kubeconfig 文件供控制器管理器使用
/scheduler 生成 kubeconfig 文件供调度程序使用
etcd 为本地 etcd 生成静态 Pod 清单文件
/local 为本地单节点本地 etcd 实例生成静态 Pod 清单文件
control-plane 生成建立控制平面所需的所有静态 Pod 清单文件
/apiserver 生成 kube-apiserver 静态 Pod 清单
/controller-manager 生成 kube-controller-manager 静态 Pod 清单
/scheduler 生成 kube-scheduler 静态 Pod 清单
kubelet-start 写入 kubelet 设置并启动(或重启) kubelet
upload-config 将 kubeadm 和 kubelet 配置上传到 ConfigMap
/kubeadm 将 kubeadm 集群配置上传到 ConfigMap
/kubelet 将 kubelet 组件配置上传到 ConfigMap
upload-certs 将证书上传到 kubeadm-certs
mark-control-plane 将节点标记为控制面
bootstrap-token 生成用于将节点加入集群的引导令牌
kubelet-finalize 在 TLS 引导后更新与 kubelet 相关的设置
/experimental-cert-rotation 启用 kubelet 客户端证书轮换
addon 安装用于通过一致性测试所需的插件
/coredns 将 CoreDNS 插件安装到 Kubernetes 集群
/kube-proxy 将 kube-proxy 插件安装到 Kubernetes 集群
show-join-command 显示控制平面和工作节点的加入命令
kubeadm init 主要参数:
*** --apiserver-advertise-address string
#API 服务器所公布的其正在监听的 IP 地址。如果未设置,则使用默认网络接口。
*** --apiserver-bind-port int32 默认值:6443
#API 服务器绑定的端口。
--apiserver-cert-extra-sans strings
#用于 API Server 服务证书的可选附加主题备用名称(SAN)。可以是 IP 地址和 DNS 名
--cert-dir string 默认值:"/etc/kubernetes/pki"
#保存和存储证书的路径。
--certificate-key string
#用于加密 kubeadm-certs Secret 中的控制平面证书的密钥。 证书密钥为十六进制编码的字符串,是大小为 32 字节的 AES 密钥。
--config string
#kubeadm 配置文件的路径。
*** --control-plane-endpoint string
#为控制平面指定一个稳定的 IP 地址或 DNS 名称。即配置一个可以长期使用且是高可用的VIP或者域名,k8s多master高可用基于此参数实现
--cri-socket string
#要连接的 CRI 套接字的路径。如果为空,则 kubeadm 将尝试自动检测此值; 仅当安装了多个 CRI 或具有非标准 CRI 套接字时,才使用此选项。
--dry-run
#不做任何更改;只输出将要执行的操作。
--feature-gates string
#一组用来描述各种功能特性的键值(key=value)对。选项是:
#EtcdLearnerMode=true|false (BETA - 默认值=true)
#PublicKeysECDSA=true|false (DEPRECATED - 默认值=false)
#RootlessControlPlane=true|false (ALPHA - 默认值=false)
#UpgradeAddonsBeforeControlPlane=true|false (DEPRECATED - 默认值=false)
#WaitForAllControlPlaneComponents=true|false (ALPHA - 默认值=false)
-h, --help
#init 操作的帮助命令。
*** --ignore-preflight-errors strings
#错误将显示为警告的检查列表;例如:'IsPrivilegedUser,Swap'。取值为 'all' 时将忽略检查中的所有错误。比如忽略swap报错
*** --image-repository string 默认值:"registry.k8s.io"
#选择用于拉取控制平面镜像的容器仓库。
*** --kubernetes-version string 默认值:"stable-1"
#为控制平面选择一个特定的 Kubernetes 版本。
--node-name string
#指定节点的名称。
*** --pod-network-cidr string
#指明 Pod 网络可以使用的 IP 地址段。如果设置了这个参数,控制平面将会为每一个节点自动分配 CIDR。
*** --service-cidr string 默认值:"10.96.0.0/12"
#为服务的虚拟 IP 地址另外指定 IP 地址段。设置service网络地址范围。
*** --service-dns-domain string 默认值:"cluster.local"
#为服务另外指定域名,例如:"myorg.internal"。设置k8s内部域名
--skip-certificate-key-print
#不要打印用于加密控制平面证书的密钥。
*** --skip-phases strings
#要跳过的阶段列表。
--skip-token-print
#跳过打印 'kubeadm init' 生成的默认引导令牌。
--token string
#这个令牌用于建立控制平面节点与工作节点间的双向通信。 格式为 [a-z0-9]{6}.[a-z0-9]{16} - 示例:abcdef.0123456789abcdef
--token-ttl duration 默认值:24h0m0s
#令牌被自动删除之前的持续时间(例如 1s,2m,3h)。如果设置为 '0',则令牌将永不过期。
--upload-certs
#将控制平面证书上传到 kubeadm-certs Secret。
#全局可选项:
--add-dir-header #如果为true,在日志头部添加日志目录
--log-file string #如果不为空,将使用此日志文件
--log-file-max-size uint #设置日志文件的最大大小,单位为兆,默认为1800兆,0为没有限制
--rootfs #宿主机的根路径,也就是绝对路径#如果为true,在1og日志里面不显示标题前缀
--skip-headers--skip-log-headers #如果为true,在1og日志里里不显示标题
拉取k8s组件镜像:
#!/bin/bash
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.28.11
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.28.11
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.28.11
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.28.11
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.12-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.10.1
k8s单机初始化参数:
kubeadm init --apiserver-advertise-address=172.16.1.45 --kubernetes-version=v1.28.11 --pod-network-cidr=10.100.0.0/16 --service-cidr=10.200.0.0/24 --service-dns-domain=wangchi.local --image-repository=registry.cn-hangzhou.aliyuncs.com/google_containers --ignore-preflight-errors=swap --cri-socket unix:///var/run/cri-dockerd.sock --v=5
k8s多主初始化参数:
kubeadm init --apiserver-advertise-address=172.16.1.45 --control-plane-endpoint=172.16.1.188 --apiserver-bind-port=6443 --kubernetes-version=v1.28.11 --pod-network-cidr=10.100.0.0/16 --service-cidr=10.200.0.0/24 --service-dns-domain=wangchi.local --image-repository=registry.cn-hangzhou.aliyuncs.com/google_containers --ignore-preflight-errors=swap --cri-socket unix:///var/run/cri-dockerd.sock --v=5
安装成功返回结果:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.16.1.45:6443 --token 0qolwo.gj6at52fklb15m1n \
--discovery-token-ca-cert-hash sha256:61b02f33cc18763cb0aece04e76d817a1db45954c294673c7d1acaf93f9beef9
集群模式init成功
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 172.16.1.188:6443 --token o9ldhj.tfn8pyxyqtflaba4 \
--discovery-token-ca-cert-hash sha256:8ff65b5da47570feec15fa8cede09f0113a1702c93221729664b6d4de4a9b05e \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.16.1.188:6443 --token o9ldhj.tfn8pyxyqtflaba4 \
--discovery-token-ca-cert-hash sha256:8ff65b5da47570feec15fa8cede09f0113a1702c93221729664b6d4de4a9b05e
failure loading certificate for CA: couldn't load the certificate file /etc/kubernetes/pki/ca.crt: open /etc/kubernetes/pki/ca.crt: no such file or directory
#需要把master01的ca文件同步到master02
# 在master02创建目录
mkdir -p /etc/kubernetes/pki && mkdir -p /etc/kubernetes/pki/etcd
# 同步master01的文件,在master01上执行
scp -rp /etc/kubernetes/pki/ca.* root@172.16.1.46:/etc/kubernetes/pki
scp -rp /etc/kubernetes/pki/sa.* root@172.16.1.46:/etc/kubernetes/pki
scp -rp /etc/kubernetes/pki/front-proxy-ca.* root@172.16.1.46:/etc/kubernetes/pki
scp -rp /etc/kubernetes/pki/etcd/ca.* root@172.16.1.46:/etc/kubernetes/pki/etcd
scp -rp /etc/kubernetes/admin.conf root@172.16.1.46:/etc/kubernetes
第一部分:是指定jion加入的主机及端口,这里为 192.18.106.87:6443 , 这个就是master节点的IP地址+固定的端口
第二部分:需要指定token值,这个值,我们可以通过如下命令的TOKEN字段得到(默认情况下Token的有效期为24小时):
[root@k8s-master qq-5201351]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
r6pcfk.ak6bm89c3sbm5lp4 21h 2023-05-17T03:17:40Z authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token
第三部分:这个与的kubernetes的CA 证书有关系,可以通过如下方式获得其sha256值
[root@k8s-master qq-5201351]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
0cd98b24ec444c83f9be3ccf2d043040808ece28721ce5a66ce72a1440b9f2d2
最后将三部分的值进行组合,形成最初的让nodes节点加入的命令:
kubeadm join 192.18.106.87:6443 --token r6pcfk.ak6bm89c3sbm5lp4 \
--discovery-token-ca-cert-hash sha256:0cd98b24ec444c83f9be3ccf2d043040808ece28721ce5a66ce72a1440b9f2d2
注意:这个命令有效的前提,是需要保证TTL值还没有过期~
kubeadm join 172.16.1.188:6443 --token u3o71y.3wirdhmng0vkbt09
--discovery-token-ca-cert-hash sha256:9497cb24fe89a27ab535b99538c93d2ec76d869c16501c3a787d4e4ca042e250
2.2 安装cni插件
# 下载flannel插件的yml
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 修改kube-flannel.yml中的镜像仓库地址为国内源
sed -i 's/quay.io/quay-mirror.qiniu.com/g' kube-flannel.yml
# 安装网络插件
kubectl apply -f kube-flannel.yml
查看kubeadm配置的默认pod网段和sv网段
# kubeadm的配置信息存在config-map中
kubectl -n kube-system describe cm kubeadm-config |grep -i pod
# 查看pod网段和svc网段
kubectl -n kube-system describe cm kubeadm-config |grep -i net
安装calico
# 下载calico-v3-25版的calico插件的yaml
wget https://docs.projectcalico.org/manifests/calico.yaml
修改定义pod网络CALICO_IPV4POOL_CIDR的值
要和kubeadm init pod-network-cidr的值一致
# 修改calico.yaml
vim calico.yaml
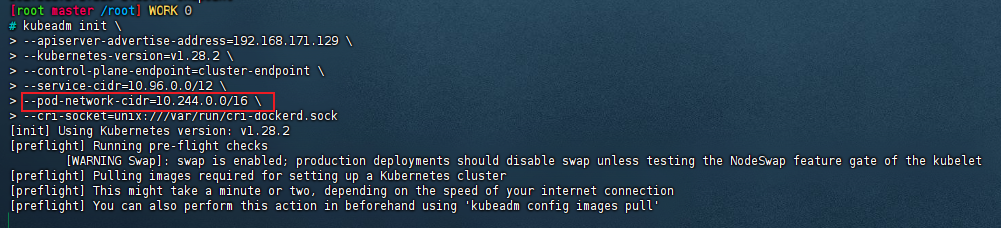
## 取消注释
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
calico配置自动检测此主机的 IPv4 地址的方法
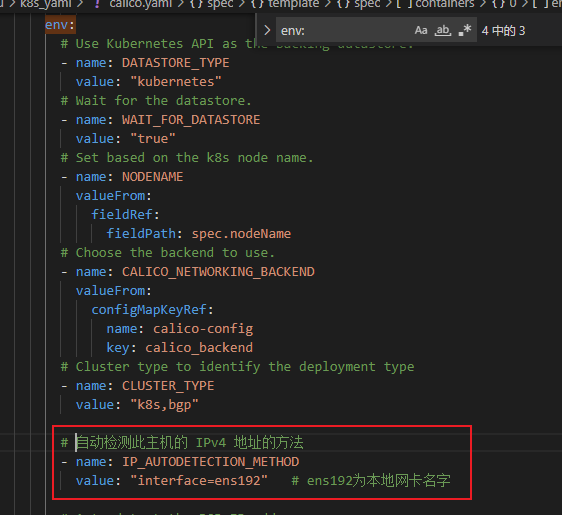
下载calico-v3.29.3的yaml
tigera-operator.yaml
文件作用: 部署 Tigera Calico Operator,用于管理 Calico 生命周期(安装、升级、配置)
# 下载 tigera-operator.yaml
wget -c https://raw.githubusercontent.com/projectcalico/calico/v3.29.3/manifests/tigera-operator.yaml

# 下载 custom-resources.yaml
curl https://raw.githubusercontent.com/projectcalico/calico/v3.29.3/manifests/custom-resources.yaml -O
# 先把master节点设为尽量不调度(可以调度)
kubectl taint nodes master node-role.kubernetes.io/master:PreferNoSchedule
# 安装 Operator,使其具备管理 Calico 的能力
kubectl create -f tigera-operator.yaml
# Operator 监听 custom-resources.yaml 中的自定义资源,按配置生成 Calico 的 DaemonSet、Deployment 等核心组件
kubectl create -f custom-resources.yaml
# 查看 tigera-operator 空间下的pod状态
kubectl get pods -n tigera-operator -owide
calico安装常见错误
# 安装calico
kubectl apply -f calico.yaml
# 弹出警告信息
Warning: policy/v1beta1 PodDisruptionBudget is deprecated in v1.21+, unavailable in v1.25+; use policy/v1 PodDisruptionBudget
poddisruptionbudget.policy/calico-kube-controllers created
警告:policy/v1beta1 PodDisruptionBudget 在 v1.21+ 中被弃用,在 v1.25+ 中不可用; 使用 policy/v1 PodDisruptionBudget
poddisruptionbudget.policy/calico-kube-controllers 创建
排查步骤
# 查看下colico-pod的日志,确定错误信息
kubectl logs calico-node-xxx -n kube-system
解决办法
https://github.com/projectcalico/calico/issues/4570
# 把
apiVersion: policy/v1beta1
# 修改为
apiVersion: policy/v1
再次apply资源清单
# 然后再次执行资源清单即可
kubectl apply -f calico.yaml
# 查看nodes状态,已经是Ready(就绪)状态
kubectl get nodes
参考文档
https://blog.csdn.net/omaidb/article/details/121283067
PS:太多了不想抄了
三、资源对象
-
对象 用k8s是和什么打交道? k8s声明式api
-
yaml文件 怎么打交道? 调用声明式api
-
必需字段 怎么声明?
-
apiVersion 创建该对象所使用的kubernetes api的版本
-
kind 想要创建的对象类型
-
metadata 帮助识别对象唯一性的数据,包括一个name名称、可选的namespace
-
spec
-
status (Pod创建完成后k8s自动生成status状态)
spec和status的区别:
spec是期望状态
status是实际状态
-
3.1 资源对象类型
资源对象:Pod、ReplicaSet、ReplicationController、Deployment、StatefulSet、DaemonSet、Job、CronJob、HorizontalPodAutoscaling、Node、NameSpace、Service、Ingress、Label、CustomResourceDefinition
存储对象:Volume、PersistentVolume、Secret、ConfigMap
策略对象: SecurityContext、ResourceQuta、LimitRange
身份对象:ServiceAccount、Role、ClusterRole
cordon #scheduling disable 禁止调度
drain #驱逐
kubectl drain
3.1.1 Controller 控制器
Replication Controller #第一代pod副本控制器 RC
- 选择标标签字符只支持等于or不等于
apiVersion: v1
kind: ReplicationController
metadata:
name: ng-rc
spec:
replicas: 2
selector:
app: ng-rc-80
template:
metadata:
labels:
app: ng-rc-80
spec:
containers:
- name: ng-rc-80
image: nginx
ports:
- containerPort: 80
ReplicaSet #第二代pod副本控制器
- 选择标标签字符支持等于or不等于和模糊匹配
apiVersion: apps/v1
Kind: ReplicaSet
metadata:
name: frontend
namespace: m43
spec:
replicas: 2
selector:
#app: ng-rc-80 #rc 写法
#matchLabels: #rs or deployment 写法
# app: ng-rs-80
matchExpressions:
- {key: app, operator: In,vlauesL [ng-rs-80,ng-rs-81]}
template:
metadata:
labels:
app: ng-rs-80
spec:
containers:
- name: ng-rs-80
image: nginx:1.16.1
ports:
- containerPort: 80
Deployment #第三代pod副本控制器
维持副本数调用ReplicaSet,本身实现更高级回滚升级等功能
livenessprobe 存活探针
检测应用发生故障时使用,不能提供服务、超时等检测失败重启Pod
readinessprobe 就绪探针
检测Pod启动之后应用是否就绪,是否可以提供服务 检测成功,Pod才开始接收流量
3.1.2 volume
emptydir 随pod删除一起删除
hostpath 单node使用
nfs
本文来自博客园,作者:原味玉米烙,转载请注明原文链接:https://www.cnblogs.com/yml2024/p/18878483

 浙公网安备 33010602011771号
浙公网安备 33010602011771号