
函数(三)
一、函数递归
1.什么是递归函数
函数在调用阶段直接或间接的又调用了自身。
ps:递归的最大深度:997
2.查询递归函数的最大递归深度
import sys print(sys.getrecursionlimit())
3.修改递归函数的最大递归深度
import sys sys.setrecursionlimit(2000)
4.递归分为两个阶段
(1)回溯:一次次重复的过程,这个重复的过程必须建立在每一次重复问题的复杂度都应该下降,直到有一个最终的结束条件
理解:是一个重复的过程,但是不能一味的重复。应该做到每一次重复问题的复杂度应该下降,最终要有一个明确的结束条件
(2)递推:一次次往回推导的过程
理解:基于回溯得到的结果,一步步往后推导得出结论
5.递归函数必须要有结束条件,一般通过return结束递归
"""
age(5) = age(4)+2
age(4) = age(3) + 2
age(3) = age(2) + 2
age(2) = age(1) + 2
age(1) = 18
"""
def age(n): if n == 1: # 必须要有结束条件 return 18 return age(n-1) + 2 res = age(5) print(res)
例子:
l = [1,[2,[3,[4,[5,[6,[7,[8,[9,[10,[11,[12,[13,]]]]]]]]]]]]] # 将列表中的数字依次打印出来(循环的层数是你必须要考虑的点) def get_num(l): for i in l: if type(i) is int: print(i) else: get_num(i) get_num(l)
# 每一层都是由1个整数和一个列表组成的,通过for循环加上if判断来打印出整数,然后在外包一个函数用来调用该列表
一个数,除2直到次数等于5退出
def calc(n,count): print(n, count) if count < 5: r = calc(n / 2, count + 1) return r # 里层返回为上层,此处不加return 返回None else: return n # 最里层返回 res = calc(188, 1) print('res ', res)
一个数,除2直到不能整除2
n = 100 def cal(n): if n == 0: return else: n = int(n // 2) print(n) cal(n) print("退出=", n) cal(100)
二、算法之二分法
为什么要用到二分法?
当在查找一个元素是否在一个容器里时,首先想到的是用for循环将每一个元素与之对应,但如果容器的长度太长的话,这种方法就太复杂了
算法:解决问题的高效率的方法
二分法:容器类型里面的数字必须有大小顺序
l = [1,3,5,12,57,89,101,123,146,167,179,189,345] target_num = 666 def get_num(l,target_num): if not l: print('你给的工资 这个任务怕是没法做') return # 获取列表中间的索引 print(l) middle_index = len(l) // 2 # 判断target_num跟middle_index对应的数字的大小 if target_num > l[middle_index]: # 切取列表右半部分 num_right = l[middle_index + 1:] # 再递归调用get_num函数 get_num(num_right,target_num) elif target_num < l[middle_index]: # 切取列表左半部分 num_left = l[0:middle_index] # 再递归调用get_num函数 get_num(num_left, target_num) else: print('find it',target_num) get_num(l,target_num)
理解:每次截取上一次容器类型一半进行比较,利用列表的切片操作截取 小列表
三、列表生成式
1.三元表达式:
如果if后面的条件成立返回if前面的值,否则返回else后面的值
2.固定表达式:
值1 if 条件 else 值2
条件成立返回值1
条件不成立返回值2
ps:三元表达式的应用场景只推荐只有两种的情况下
例子:比较两数大小
x = 999 y = 989 res = x if x > y else y # 如果x>y返回x,否则返回y print(res)
is_free = input('请输入是否免费(y/n)>>>:') is_free = '免费' if is_free == 'y' else '收费' print(is_free)
2.列表生成式
[函数+for+item+in+序列+if判断语句]
给列表中的元素添加_sb
方法一:
l = ['tank','nick','oscar','sean'] l1 = [] for name in l: l1.append('%s_sb'%name) # l1.append(name + '_sb') # 不推荐使用 print(l1)
# 先定一个空列表,然后通过for循环和格式化输出将_sb添加到列表中的元素
方法二:
l = ['tank','nick','oscar','sean'] res = ['%s_sb'%name for name in l] # 左边格式化输出,右边for循环每个元素,先循环后格式化输出 print(res)
加上if判断(不支持再加else)
先for循环依次取出列表里面的每一个元素
然后交由if判断,条件成立才会交给for前面的代码
如果条件不成立,当前的元素,直接舍弃
l = ['tank_sb', 'nick_sb', 'oscar_sb', 'sean_sb','jason_NB'] res = [name for name in l if name.endswith('_sb')] print(res)
四、字典生成式
将两个列表写入一个字典里
l1 = ['name','password','hobby'] l2 = ['jason','123','DBJ','egon'] d = {} for i,j in enumerate(l1): d[j] = l2[i] print(d)
将列表中的元素不写入字典
l1 = ['jason','123','read'] d = {i:j for i,j in enumerate(l1) if j != '123'} print(d)
res = {i for i in range(10) if i != 4} # 集合表达式
print(res) # 0-9没有4
生成器表达式
res1 = (i for i in range(10) if i != 4) # 这样写不是元组生成式 而是生成器表达式 print(res1) # <generator object <genexpr> at 0x000001D52141CF68> for i in res1: print(i) # 0-9没有4
五、匿名函数
匿名函数就是不显示函数名
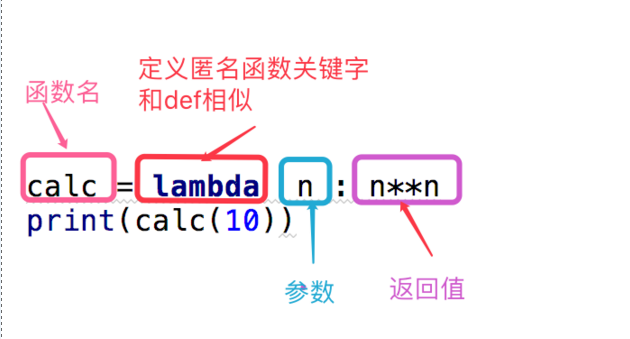
特点:临时存在用完就没了
通常不会单独使用,需要配合内置函数一起使用
lambda x,y : x+y
左边相当于函数的形参,右边相当于函数的返回值
计算两数之和
# 方法一: def my_sum(x,y): return x + y # 方法二: res = (lambda x,y:x+y)(1,2) print(res) # 方法三: func = lambda x,y:x+y print(func(1,2))
六、常用的内置内涵
1.max()内部基于for循环,先一个个将传入的容器类型中的元素一个个取出,
当你没有指定key(key对应的是一个函数)的时候 就按照for循环取出来的值比较大小,
如果指定了key,那么max会将元素交给这个函数,拿着该函数返回结果来做大小比较
min()同理
例如:数字比较
l = [1,2,3,4,5] print(max(l)) # 内部是基于for循环的
字典中比较薪资,返回人名
A-Z:65-90,a-z:97-122
d = { 'egon':30000, 'jason':20000, 'nick':3000, 'tank':10000 } print(max(d,key=lambda name:d[name])) # 先取字典中每个键对应的值,再相互比较得出最大的值,再返回该值的键 # 比较薪资 返回人名 print(min(d,key=lambda name:d[name])) # 先取字典中每个键对应的值,再相互比较得出最小的值,再返回该值的键
2.map:映射(对于参数iterable中的每个元素都应用fuction函数,并将结果作为列表返回)
l = [1,2,3,4,5,6] # print(list('hello')) # 将字符串拆分成单个字符拼凑成一个列表 print(list(map(lambda x:x+5,l))) # 基于for循环 每个值加5
3.zip:拉链(将对象逐一配对,如果配不上,则丢弃)
l1 = [1,2,] l2 = ['jason','egon','tank'] l3 = ['a','b','c'] print(list(zip(l1,l2,l3))) # 将三个列表中的元素按顺序一一对应形成一个元组,若其中列表元素不等,则按最少元素列表形成 # [(1, 'jason', 'a'), (2, 'egon', 'b')]
4.filter:过滤(过滤函数依次作用于每一个过滤序列的元素,返回符合要求的过滤值。)
l = [1,2,3,4,5,6] print(list(filter(lambda x:x != 3,l))) # 基于for循环 将列表中的某个元素过滤掉
5.sorted:排序(将序列中的元素排序)
l = ['jason','egon','nick','tank'] print(sorted(l,reverse=True)) # 按从小到大排序
6.reduce模块:是个工厂 将多个值变成一个值,变的过程依据你传入的函数
from functools import reduce l = [1,2,3,4,5,6] print(reduce(lambda x,y:x+y,l,19)) # 19初始值 第一个参数 40 # 当初始值不存在的情况下 按照下面的规律 # 第一次先获取两个元素 相加 # 之后每次获取一个与上一次相加的结果再相加

 浙公网安备 33010602011771号
浙公网安备 33010602011771号