
AAAI2019的论文
链接:https://arxiv.org/pdf/1901.08211.pdf
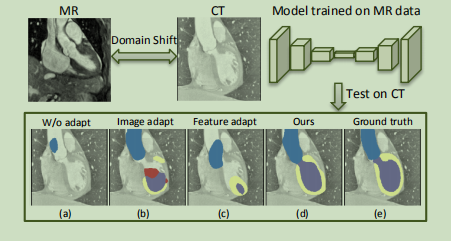
- 本文提出了一种协同多模态的无监督领域自适应框架,也称为协同图像和特征自适应(SIFA)。以有效解决医学图像域迁移的问题。
- 传统无监督自适应框架通过两种方式进行迁移学习: 在图像级别将源域图像转化到接近目标域的图像,然后对网络进行微调。在特征级别进行对抗学习,使模型能够生成域不变的特征。
- 本文融合了图像和特征的两个角度进行协同性的域迁移。首先跨域变换图像的外观,将源域图像转换为目标域类似的图像,使用源域标签进行有监督训练,同时在特征级别通过对抗学习进行域迁移,促使模型生成域不变的特征。两种域迁移使用相同的权重参数,在不使用任何目标域标注的情况下进行端到端的训练,学习到两个域共有的特征。
Network Architecture
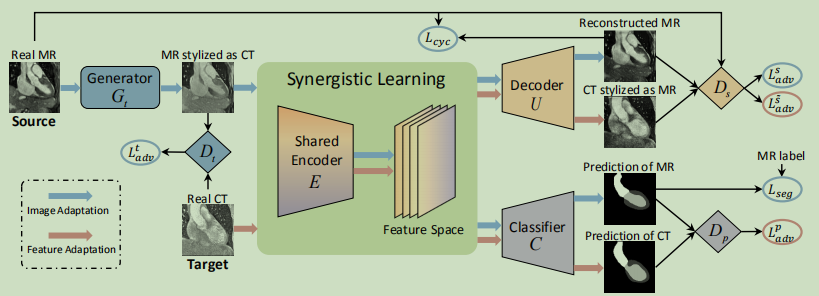
- 下图为作者提出的无监督域自适应框架,首先借鉴CycleGAN来将源域图像转化为类似目标域图像,生成器Gt为源域到目标域的映射,Dt为目标域的判别器。编码器E和解码器U构成目标域到源域的映射Gs,那么Gt,Gs,Dt,Ds,就构成了一个CycleGAN,然后编码器E还与分类器C连接以进行图像分割。对源域生成的图像的分割结果计算分割损失,进行有监督训练,判别器Dp对两个域样本的分割预测图进行判别,使编码器E生成域不变特征。
- 图中蓝色和红色箭头分别指示用于图像自适应和特征自适应的数据流。
网络训练
Image Adaptation for Appearance Alignment

Feature Adaptation for Domain Invariance
- 域迁移最重要的是要模型学习到域不变特征,常见方法是直接在特征空间使用对抗学习,让鉴别器无法区分特征来自哪个域即可,但是特征空间具有高维度,难以对齐,所以作者在两个低维空间进行对抗学习,分别是重构的图像空间和语义分割预测空间。
- 在语义预测空间,预测的分割结果,通常带有高维特征的信息的,作者在语义预测分支中加入了鉴别器Dp,当鉴别器无法分类分割结果的时候,则代表模型学习到的特征是域不变特征。该鉴别器的对抗损失为:
![在这里插入图片描述]()
- 在重构的图像空间,有类目标域和目标域的图像的两种重构图像,重构结果是对特征的上采样,同理也可以用鉴别器对其分类,当鉴别器无法区分两种重构图像时,则代表模型学习到的特征是域不变特征。该鉴别器的对抗损失为:
![在这里插入图片描述]()
- 上面这些措施鼓励E从两个方面生成具有域不变性的措施,缩小两个域之间的间隙。


Synergistic Learning Diagram
- 借助编码器,无缝的集成了图像和特征适应,可以端到端的训练整个框架,在每次迭代训练中,模块按照以下顺序一次更新:Gt -> Dt -> E -> C -> U -> Ds -> Dp,Gt首先更新以将源域图像转化到类目标域,Dt更新以区分类目标图像和真实目标图像,接下来,更新编码器E以从类目标图像中提取特征,然后更新分类器C和解码器U,将提取的特征用于语义分割和生成重构图像,最后鉴别器Ds和Dp更新,对输入域进行分类,以增强特征不变性。框架的总体目标如下:
![在这里插入图片描述]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号