
PCIE学习笔记
PCI (Peripheral Component Interface外设组件接口)
1.1 PCI-X简介
PCI-X对PCI的软件和硬件都能做到向后兼容,同时PCI-X还能提供更好的性能和更高的效率。
为了在不改变PCI信号传输模型的基础上达到更高的速率,PCI-X使用了几个技巧来改善总线时序。首先,他们实现了PLL(锁相环)时钟发生器,利用它在内部提供相移时钟。这使得输出信号在相位上前移,而输入再在相位上延后一点进行采样,从而改善总线上的时序。同时,PCI-X的输入信号都在Target设备的输入引脚被寄存(锁存),这样就使得建立时间更小。通过这些方法节省出来的时间可以有效增加信号在总线上传输的可用时间,并使得总线可以进一步提高时钟频率。
1.2 PCI-X特性
拆分事务模型
为了方便描述追踪每个设备正在做什么,我们现在将例子中发起读取操作的一方称为Requester(请求方),将完成读取请求提供数据的一方称为Completer(完成方)。如果Completer无法马上对请求做出相应的服务,它将把这个事务的相关信息存储起来(地址、事务类型、总数据量、Requester ID),并发出拆分响应信号。这就告诉Requester可以将这个事务先放置在队列中,并结束当前的总线时序周期,释放总线使之回到空闲状态。这样,在Completer等待所请求的数据这段时间里,总线上可以执行其他的事务。Requester在这段时间里也可以自由的做其他事情,比如发起另一个请求,甚至是向此前的那个Completer发起请求都可以。一旦Completer收集到了所请求的数据,它将会申请总线占用仲裁,当获取到总线的使用权后,它将发起一个拆分完成(Split Completion)来返回此前Requester所请求的数据。Requester将会响应并参与拆分完成这个事务的总线时序周期,在这个过程中接收来自Completer的数据。对于系统来说,拆分完成事务其实与写事务非常相似。这种拆分事务模型(Split Transaction Model)的可行性在于,在请求发起时就通过属性阶段(Attribute Phase)指出了总共需要传输多少数据,并且也告诉了Completer是谁发起了这个请求(通过提供Requester自己的Bus:Device:Function号码),这使得Completer在发起拆分完成事务时能够找到正确的目标。
对于上述的整个数据传输过程来说,需要通过两个总线事务来完成,但是读请求和拆分完成这两个事务之间的这段时间里,总线是可以执行其他任务的。Requester不需要重复的轮询设备来检查数据是否已经准备好。Completer只需要简单的申请总线占用仲裁,然后在能使用总线时将被请求的数据返回给Requester即可。就总线利用率而言,这样的操作流程使得事务模型更加高效。
2.1 PCI Express 简介
PCI Express 的出现代表了其前身并行总线的重大转变。作为一种串行总线,它与早期的串行设计(例如 InfiniBand 或者 Fibre Channel)有许多的共同点,但是它完全保持了在软件层面对 PCI 的后向兼容。
正如许多高速串行传输方法一样,PCIe 使用双向连接的方式,可以在同一时间进行信息的收发操作。这种模型被称为双单工连接,因为每个接口都有一个单工发送路径和一个单工接收路径,图2‑1 展示了这种模型。因为数据流可以同时进行双向传输,因此在技术层面上来说两个设备间的通信其实是全双工的,但是 PCIe 协议规范依然使用双单工这个术语,这是因为这种称呼对实际通信信道也进行了一点描述。
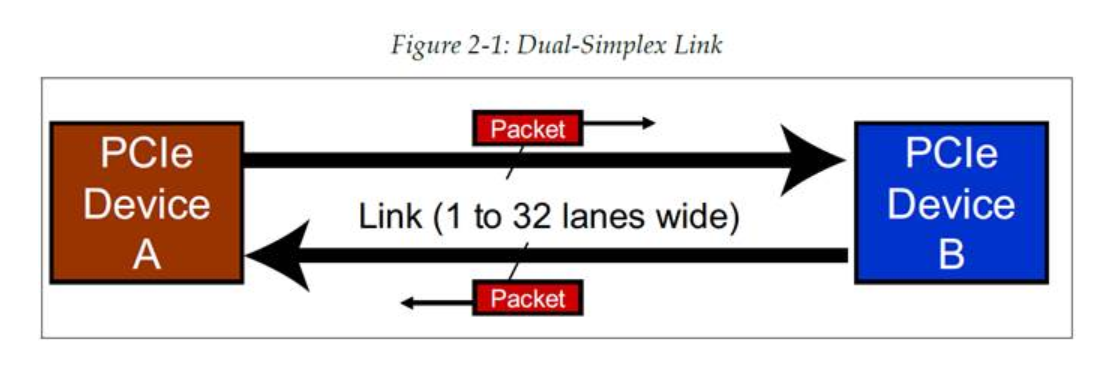
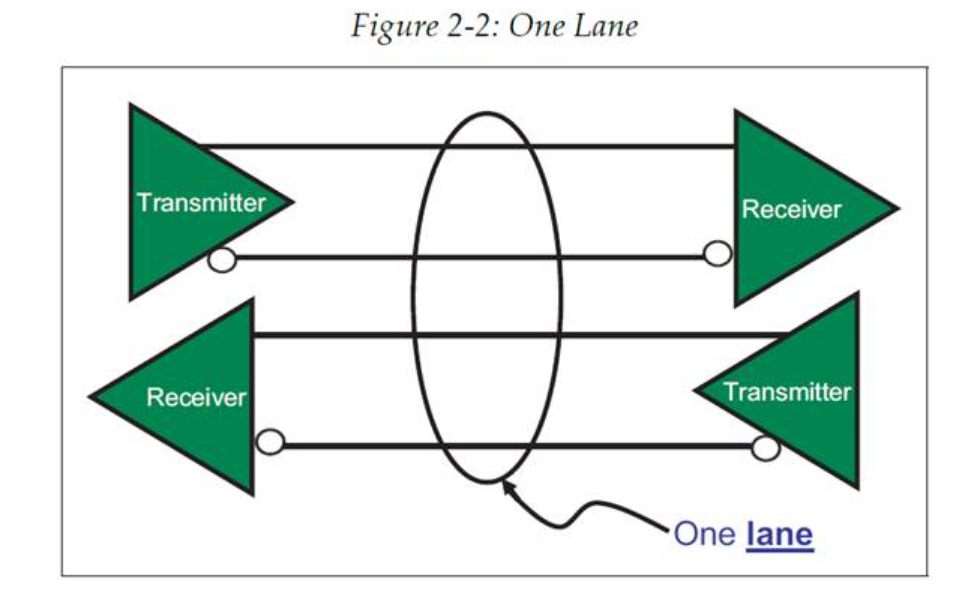
用于描述设备之间信号传输路径的术语为“链路(Link)”,它由一个或以上的接收发送对组成。这样的一对接收和发送被称为一个“通道(Lane)”,协议规范允许一条链路内有 1、2、4、8、12、16 或 32 个通道。链路内通道的数量称为链路宽度,通常用 x1、x2、x4、x8、x16 以及 x32 来进行表示。用于权衡在实际设计中使用多少通道的思路其实很简单:使用更多的通道可以增加带宽,但是也会增加成本、增加空间占用以及增加功耗。更多关于这方面的信息,可以阅读“链路与通道”这一节。
2.2 PCIe 带宽计算方法 (PCIe Bandwidth Calculation)
要计算上述表格中的 PCIe 带宽大小,可以参照如下的计算方法。
-
Gen1 PCIe 带宽 =(2.5Gb/s x 2 directions)/ 10bits per symbol = 0.5GB/s
-
Gen2 PCIe 带宽 =(5.0Gb/s x 2 directions)/ 10bits per symbol = 1.0GB/s
需要注意,上述计算中,我们是除以 10bits 而不是 8bits,这是因为 Gen1 和 Gen2 的协议中要求将字节进行 8b/10b 编码后进行数据包的传输,因此原数据中的 1 字节在实际传输时其实是需要传输 10 比特。
- Gen3 PCIe 带宽 =(8.0Gb/s x 2 directions)/ 8bits per byte = 2.0GB/s
注意到在 Gen3 速率的计算中,我们除以的是 8bits 而不再是 10bits 了,这是因为 Gen3 中不再使用 8b/10b 编码方式,而是 128b/130b 编码方式。这种编码方式每 128位 引入 2 比特开销,这个开销非常小以至于我们暂且可以将它在我们的计算中忽略。
上述三种方法计算出来的带宽只需要再乘以链路宽度即可得到整个多通道链路的链路带宽。
2.3 不再使用公共时钟 (No Common Clock)
在先前的内容中有提到,PCIe 链路不再像 PCI 一样使用公共时钟,它使用了一个源同步模型,这意味着需要由发送端给接收端提供一个时钟来用于对输入数据进行锁存采样。
2.4 灵活的拓扑结构选择
一条 PCIe 链路必须是一个点对点的连接,而不是像 PCI 一样的共享总线,这是因为 PCIe 使用的链路速率非常高。由于一条链路只能连接两个接口,因此需要一种扩展连接的方法来构建一个不琐碎的系统,这里不琐碎的意思是指不过于细碎和冗杂,例如若直接对所有设备都采用直接的两两相连,那么会使得整个系统十分冗杂琐碎。这种需求在 PCIe 中通过交换机和桥接来实现,这两者可以灵活的构建系统拓扑——系统中元素之间的连接集。
3.1 设备层次介绍
PCIe 定义了一种分层的体系结构。可以认为这些层在逻辑上是相互独立的部分,因为他们各自都有一个用于发出信息流的发送端和一个接收信息流的接收端。这种分层的设计方法对硬件设计者来说有不少的优点,因为如果在设计中对逻辑进行了仔细的划分,那么就可以在以后升级到新的协议规范版本时仅改变原设计中的某一层即可,而不会影响或者变动其它层。
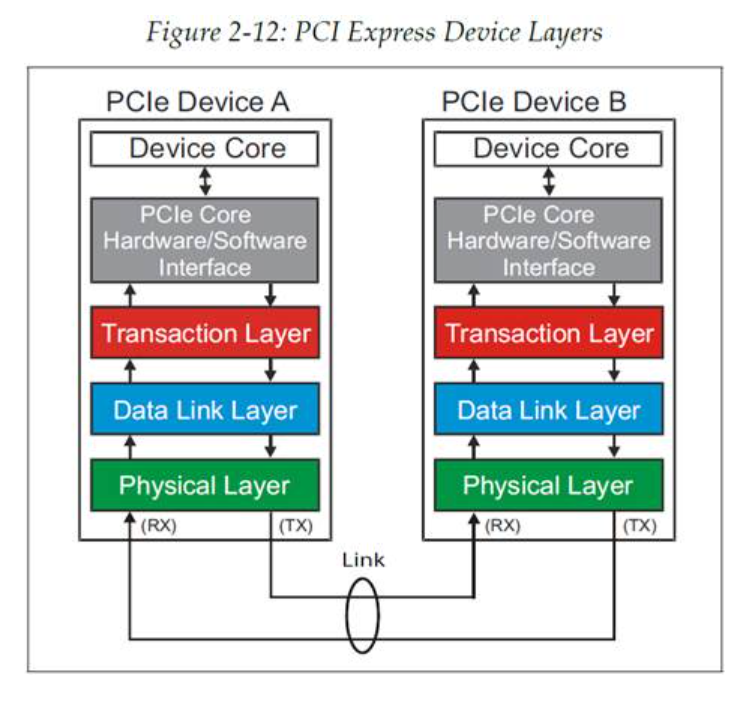
PCIe 设备内部层次包括:
-
设备核心层以及它与事务层的接口。设备核心层实现设备的主要功能。如果设备是一个端点,那么它最多可以包含 8 个功能(function),每个功能实现自己的配置空间。如果设备是一个交换机,那么它的核心由数据包路由逻辑和为了实现路由的内部总线构成。如果设备是一个 RC,那么其核心会实现一个虚拟的 PCI 总线 0,在这个虚拟的 PCI 总线 0中存在着所有的芯片组嵌入式端点以及虚拟桥。
-
事务层。事务层负责在发送端产生 TLP(Transaction Layer Packet,事务层包),在接收端对 TLP 进行译码。这一层也负责 QoS(Quality of Service,服务质量)、流量控制以及事务排序。
-
数据链路层。数据链路层负责在发送端产生 DLLP(Data Link Layer Packet,数据链路层包),在接收端对 DLLP 进行译码。这一层也负责链路错误检测以及修正,这个数据链路层功能被称为 Ack/Nak 协议。
-
物理层。物理层负责在发送端产生字符序列包,在接收端对字符序列包进行译码。这一层将处理上述三种类型的包(TLP、DLLP、字符序列包)在物理链路上的发送与接收。数据包在发送端要经过字节条带化逻辑、扰码器、8b/10b 编码器(对于 Gen1/Gen2)或是 128b/130b 编码器(对于 Gen3)以及数据包并串转换模块的处理。最终数据包以训练后的链路速率在所有通道上按照时钟以差分形式输出。在物理层的接收端,数据包处理包括串行地接收差分形式的比特信号,将其转换为数字信号形式,然后将输入比特流做串并转换。这个操作基于来源于 CDR(Clock and Data Recovery,时钟数据恢复)电路所提供的恢复时钟。接收下来的数据包要经过弹性缓存、8b/10b 解码器(对于 Gen1/Gen2)或者 128b/130b 解码器(对于 Gen3)、解扰器以及字节交换恢复逻辑。最终,物理层的 LTSSM(Link Training and Status State Machine,链路训练状态机)负责进行链路初始化以及训练。
3.2.1 设备核心层/软件层
设备核心层是一个设备的核心功能,例如网络接口或是硬盘驱动控制器。它并不是 PCIe 协议规范中所定义的一个层级,但是我们可以把它当做一个 PCIe 的层级,这是因为它位于事务层的上方,而且它是所有请求的源头或是目的地。它为事务层提供了需要发送的请求信息,其中的信息包括事务类型、地址、需要传输的数据量等等。当事务层接收到输入数据包时,它也是事务层向上转发输入数据包信息的目的地。
3.2.2 事务层
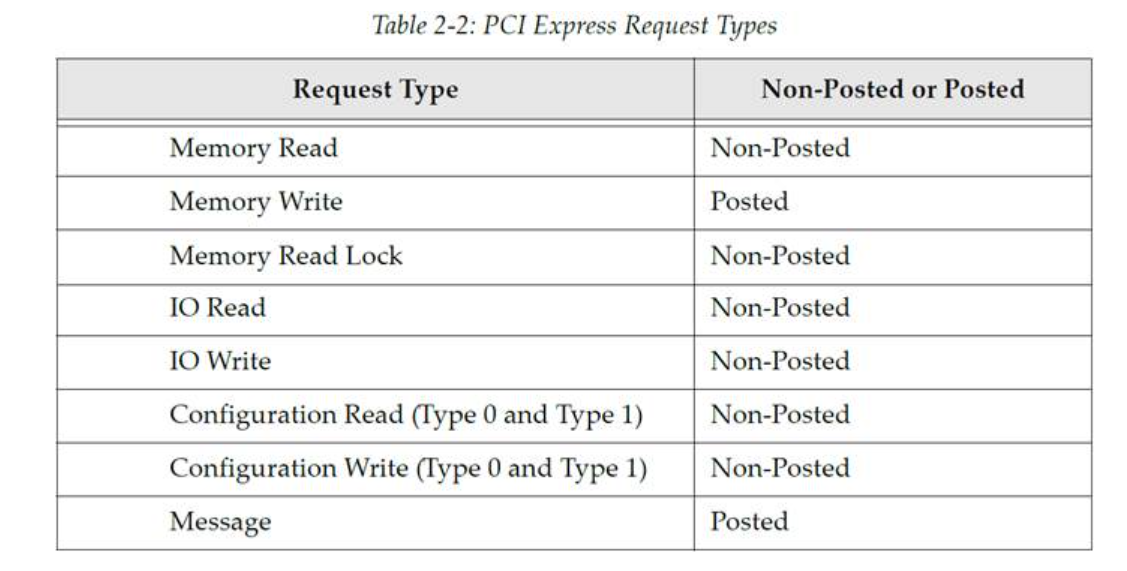
为了响应来自软件层的请求,事务层生成出站数据包(outbound packet)。它也会检查入站数据包(inbound packet),并将入站数据包内包含的信息向上转发给软件层。事务层支持非报告式请求(non‐posted transaction)的拆分事务协议,并将入站完成包(inbound Completion)与先前传输的出站非报告式请求包关联起来,即知道这个完成包是对应到哪个非报告式请求包。事务层所处理的事务使用的数据包种类为 TLP,TLP 可以分为四个请求种类:
-
内存(Memory)
-
IO
-
配置(Configuration)
-
消息( Messages)
前三种在 PCI 和 PCI-X 中就已经得到支持,但是消息是 PCIe 中的一个新的请求种类。一个请求包向目标设备传送命令,目标设备作为响应请求而发回的一个或多个完成包,这二者组合起来就是对一个事务的定义,即一个事务由一个请求包以及所有返回的完成包共同组成。如表2‑2 列出了 PCIe 请求的类型。
对于非报告式请求,发起方首先向完成方发送一个请求数据包,完成方应该产生一个完成包作为响应。(继承自PCI-X拆分事务协议)
对于报告式完成方在完成这些请求后不需要向发起方返回完成包 TLP。(继承自PCI)尽管不要求返回完成包,报告式写操作仍然要参与数据链路层的 Ack/Nak 协议,以此来保证较为可靠的数据包传输。
3.2.2.1 TLP基础内容
1、XDMA概述
XDMA是SGDMA,并非BLOCK DMA,SG模式下,主机会把要传输的数据组成链表的形式,然后将链表的首地址通过BAR传送给XDMA,XDMA会根据链表结构首地址依次完成链表所指定的传输任务。
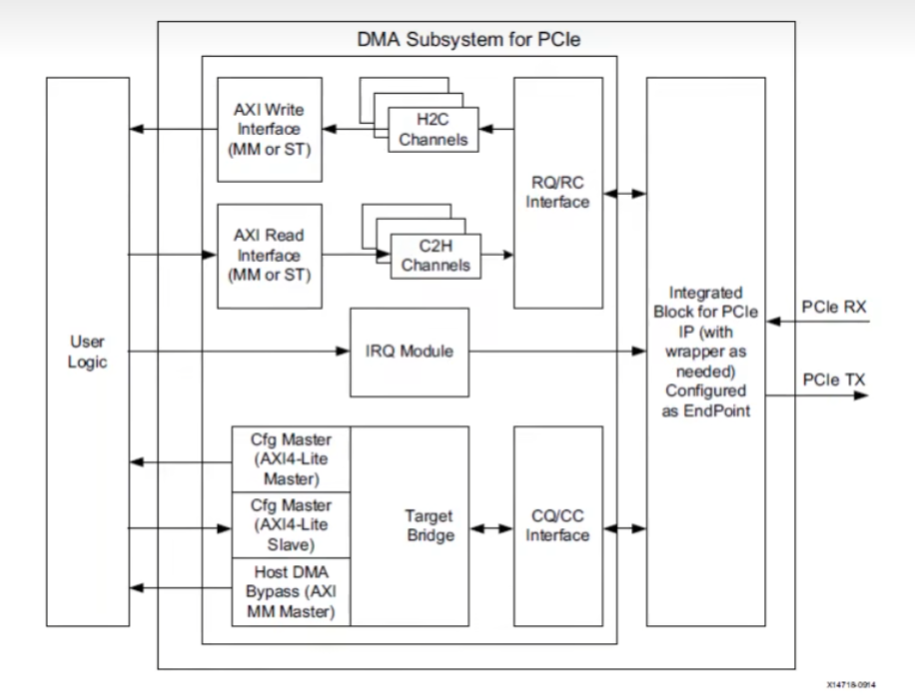
2、XDMA接口
- AXI4、AXI4-Stream,必须选择其中一个,用来数据传输
- AXI4-Lite Master,可选,用来实现PCIE BAR地址到AXI-Lite寄存器地址的映射,可用来读写用户逻辑寄存器
- AXI4-Lite Slave,可选,用来将XDMA内部寄存器开放给用户逻辑,用户逻辑可以通过此接口访问XDMA内部寄存器,不会映射到BAR
- AXI4 Bypass接口,可选,用来实现PCIE直通用户逻辑访问,可用于低延迟数据传输
3、XDMA IP 配置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号