正则表达式
正则表达式:
正则表达式(Regular Expression,常简写为regex或者RE),又称规则表达式,它不是某个编程语言所特有的,是计算机科学的一个概念,通常被用来检索和替换符合某些规则的文本。目前,正则表达式已经在各种计算机语言(如Java、 C#和Python等)中得到了广泛的应用和发展。
在Python中,可以使用正则表达式进行与字符串相关的一些匹配,正则表达式是一种用来匹配字符串的强有力武器,它只和字符串打交道,设计思想是用一种描述行的语言来给字符串定义一个规则,凡是符合规则的字符串就认为它“匹配”,否则就不匹配。即从大段的文字中找到符合规则的内容!!!
字符组:
[ ] 写在中括号中的内容,都出现在下面的某一个字符的位置上都是符合规则的
[0-9] 匹配数字0-9
[a-z] 匹配a到z的小写字母
[A-Z] 匹配A到Z的大写字母
[a-zA-Z0-9] 匹配大小写字母+数字
[a-zA-Z0-9_] 匹配数字字母下滑线
元字符:
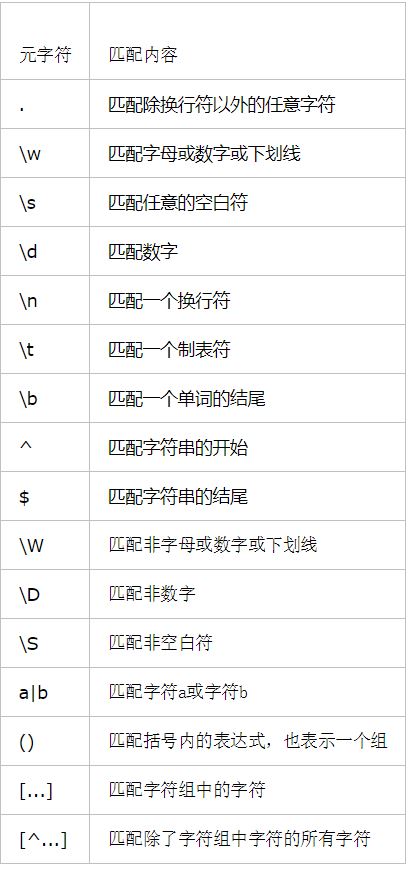
量词:
{n}表示 这个量词之前的字符出现n次
{n,} 表示这个量词之前的字符至少出现n次
{n,m} 表示这个量词之前的字符出现n-m次
? 表示匹配量词之前的字符出现 0次 或者 1次 表示可有可无
+ 表示匹配量词之前的字符出现 1次 或者 多次
* 表示匹配量词之前的字符出现 0次 或者 多次
. ^ $
|
正则表达 |
待匹配的字符 |
匹配到的结果 |
说明 |
|
结. |
结果结束结缘 |
结果结束结缘 |
匹配所有”海.”的字符 |
|
^结. |
结果结束结缘 |
结果 |
只从开头匹配”海.”匹配到了一个就会停 |
|
结.$ |
结果结束结缘 |
结缘 |
只匹配结尾的”海.”,同上面的相反 |
* + ? { }
|
正则表达 |
待匹配的字符 |
匹配到的结果 |
说明 |
|
结.? |
结果和结束和结缘 |
结果 结束 结缘 |
?表示重复零次或一次,即只匹配"结"后面一个任意字符 |
|
结.* |
结果和结束和结缘 |
结果和结束和结缘 |
*表示重复零次或多次,即匹配"结"后面0或多个任意字符 |
|
结.+ |
结果和结束和结缘 |
结果和结束和结缘 |
+表示重复一次或多次,即只匹配"结"后面1个或多个任意字符 |
|
结.{1,2} |
结果和结束和结缘 |
结果和 结束和 结缘 |
{1,2}匹配1到2次任意字符
|
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
|
正则 |
待匹配字符 |
匹配结果 |
说明 |
|
结.*? |
结果和结束和结缘 |
结 结 结 |
惰性匹配 |
正则表达式的匹配特点 :
贪婪匹配,它会在允许的范围内取最长的结果
非贪婪模式/惰性匹配 : 在量词的后面加上?
.*?x 匹配任意非换行符字符任意长度 直到遇到x就停止
2019年11月18日

 浙公网安备 33010602011771号
浙公网安备 33010602011771号