Python运算符和编码
运算符和编码
一. 格式化输出
现在有以下需求,让用户输入name, age, job,Gender 然后输出如下所示:
------------ info of Yong Jie -----------
Name : Yong Jie
Age : 19
job : Programmer
Gender: Boy
------------- end -----------------
你怎么实现呢?你会发现,用字符拼接的方式还难实现这种格式的输出,所以一起来学一下新姿势只需要把要打印的格式先准备好, 由于里面的 一些信息是需要用户输入的,你没办法预设知道,因此可以先放置个占位符,再把字符串里的占位符与外部的变量做个映射关系就好啦
name = input("Name:")
age = input("Age:")
job = input("Job:")
Gender = input("Gender:")
info = '''
------------ info of %s ----------- #这里的每个%s就是一个占位符,本行的代表 后面拓号里的 name
Name : %s #代表 name
Age : %s #代表 age
job : %s #代表 job
Gender: %s #代表 Gender
------------- end -----------------
''' % (name,name,age,job,Gender) # 这行的 % 号就是 把前面的字符串 与拓号 后面的变量 关联起来
print(info)
%s就是代表字符串占位符,除此之外,还有%d, 是数字占位符, 如果把上面的age后面的换成%d,就代表你必须只
能输入数字啦
这时对应的数据必须是int类型. 否则程序会报错
使用时,需要进行类型转换.
int(str) # 字符串转换成int
str(int) # int转换成字符串
类似这样的操作在后面还有很多
如果, 你头铁. 就不想转换. 觉着转换很麻烦. 也可以全部都用%s. 因为任何东西都可以直接转换成字符串--> 仅限%s
现在又来新问题了. 如果想输出:
我叫xxx, 今年xx岁了,我们已经学习了2%的python基础了
这里的问题出在哪里呢? 没错2%, 在字符串中如果使用了%s这样的占位符. 那么所有的%都将变成占位符. 我们的2%也变成了
占位符. 而"%的"是不存在的, 这里我们需要使用%%来表示字符串中的%.
注意: 如果你的字符串中没有使用过%s,%d占位. 那么不需要考虑这么多. 该%就%.没毛病老铁.
print("我叫%s, 今年19岁了, 学习python2%了" % 'YJ') # 有%占位符
print("我叫YJ, 今年19岁, 已经很厉害了100%了") # 没有占位符
二. 基本运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为:
- 算数运算、
- 比较运算、
- 逻辑运算、
- 赋值运算、
- 成员运算、
- 身份运算、
- 位运算.
今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算
算数运算
以下假设变量:a=10,b=20

比较运算
以下假设变量:a=10,b=20

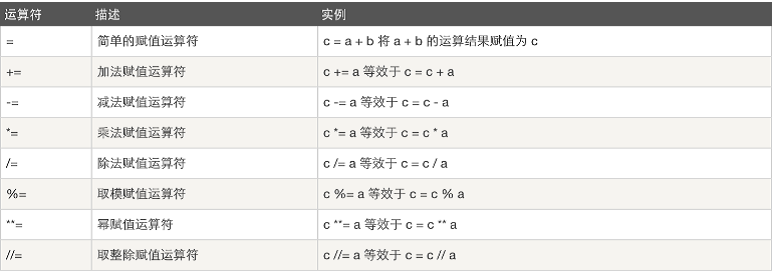
赋值运算
以下假设变量:a=10,b=20
算逻辑运

针对逻辑运算的进一步研究:
在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往
右计算。
() > not > and > or
判断下列逻辑语句的True,False。
3>4 or 4<3 and 1==1
1 < 2 and 3 < 4 or 1>2
2 > 1 and 3 < 4 or 4 > 5 and 2 < 1
1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8
1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
2, x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。

例题:求出下列逻辑语句的值。
8 or 4
0 and 3
0 or 4 and 3 or 7 or 9 and 6
三. 编码的问题
编码:
1. ascii 最早的编码. 至今还在使用. 8位一个字节(字符),支持英文, 数字, 一些特殊符号
2. Unicode 万国码. 32位4个字节,兼容ASCII
3. GBK. 国标码,汉字 16位2个字节,必须兼容ASCII
4. UTF-8. 可变长度的万国码,英文: 8位1个字节,欧洲文字:16位2个字节,汉字24位3个字节
8bit = 1byte
1024byte = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
python2解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ASCII),而python3对内容进行编码的默认为utf-8
Python2 每个文件中只要出现中文,头部必须加:# -*- coding:utf8 -*-否则会出现乱码。
计算机:早期. 计算机是美国发明的. 普及率不高, 一般只是在美国使用. 所以. 最早的编码结构就是按照美国人的习惯来编码的. 对应数字+字母+特殊字符一共也没多少. 所以就形成了最早的编码ASCII码. 直到今天ASCII依然深深的影响着我们.ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
随着计算机的发展. 以及普及率的提高. 流行到欧洲和亚洲. 这时ASCII码就不合适了. 比如: 中文汉字有几万个. 而ASCII最多也就256个位置. 所以ASCII不行了. 怎么办呢? 这时, 不同的国家就提出了不同的编码用来适用于各自的语言环境.比如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等. 这时各个国家都可以使用计算机了
GBK, 国标码占用2个字节. 对应ASCII码 GBK直接兼容. 因为计算机底层是用英文写的. 你不支持英文肯定不行. 而英文已经使用了ASCII码. 所以GBK要兼容ASCII.
这里GBK国标码. 前面的ASCII码部分. 由于使用两个字节. 所以对于ASCII码而言. 前9位都是0
字母A:0100 0001 # ASCII
字母A:0000 0000 0100 0001 # 国标码
国标码的弊端: 只能中国用. 日本就垮了. 所以国标码不满足我们的使用. 这时提出了一个万国码Unicode. unicode一
开始设计是每个字符两个字节. 设计完了. 发现我大中国汉字依然无法进行编码. 只能进行扩充. 扩充成32位也就是4个字节. 这回够了. 但是. 问题来了. 中国字9万多. 而unicode可以表示40多亿. 根本用不了. 太浪费了. 于是乎, 就提出了新的UTF编码.可变长度编码
UTF-8: 每个字符最少占8位. 每个字符占用的字节数不定.根据文字内容进行具体编码. 比如. 英文. 就一个字节就够了. 汉
字占3个字节. 这时即满足了中文. 也满足了节约. 也是目前使用频率最高的一种编码
UTF-16: 每个字符最少占16位.
GBK: 每个字符占2个字节, 16位.
单位转换:
8bit = 1byte
1024byte = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
1024TB = 1EB
1024EB = 1ZB
1024ZB = 1YB
1024YB = 1NB
1024NB = 1DB
常用到TB就够了
2019年11月2日

 浙公网安备 33010602011771号
浙公网安备 33010602011771号