详细介绍:LDA模型如何挖掘海量文本中背后的隐藏主题?
目录
基于LDA模型文本主题分析
弹幕是一种新兴的实时互动媒介,如今是反映观众观影行为、情感态度和文化参与的关键载体,小小科研团队选取网络平台的 52780 条弹幕作为分析素材,借助 LDA主题模型,究竟能帮我们揭开哪些用户在观看时讨论的核心话题?又能从中发现大家真正的兴趣焦点都集中在哪里呢?让我们来一起探讨一下吧~
一、准备工作

数据清洗
获取文本数据后,我们对杂乱的文本进行了文本分词,挖出核心话题、高频词、给每个词分词性。
(详细步骤说明翻看上期内容:还在对着一堆用户评论发呆?学会文本分词,再乱也能抓重点!)
经过数据清洗等流程,我们最终得到了这一分析结果:
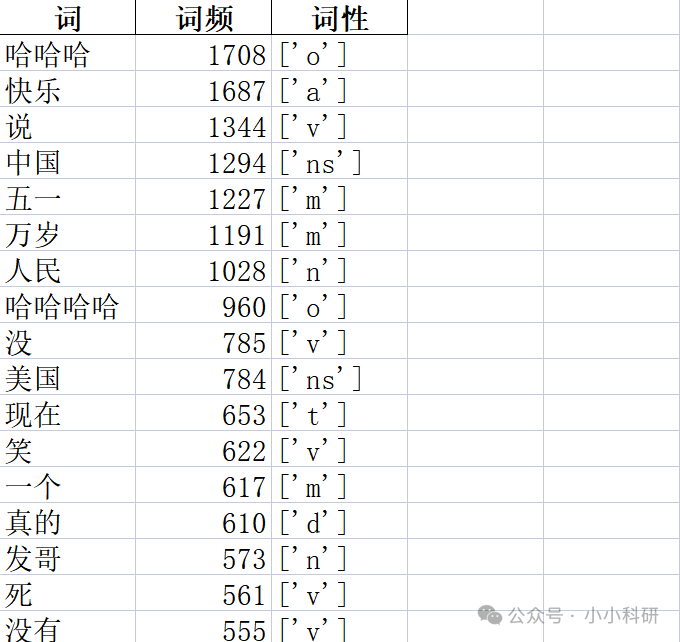
(仅展示部分)
二、LDA主题模型是什么?
模型介绍
LDA(Latent Dirichlet Allocation,潜在狄利克雷分配)是一种用于文本内容建模的概率生成模型,重要用于从文档集合中发现潜在的主题结构。
想象你是一个图书管理员,面对一堆乱七八糟的文章,但老板要求你:“把这些文章按主题分类,但我不告诉你主题是啥,你自己猜!” —— 这就是LDA的任务:从一堆文档中自动发现隐藏的主题。
其核心思想是假设每个文档由多个主题混合而成,而每个主题又由一组相关的词语构成。LDA属于无监督学习模型,广泛应用于自然语言处理、文本挖掘和信息检索等领域。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号