
深入解析:java day17
有很多时候关于一个报错,一定要一步步看,打断点看他执行到哪里去了;有没有到这里来,这样排错会非常快;
再一个思路就是,很多时候你比如后端传过来的请求啊,数据啊,你总得找个东西去接收他,比如集合比如什么,接收到了之后
mysql多表查询
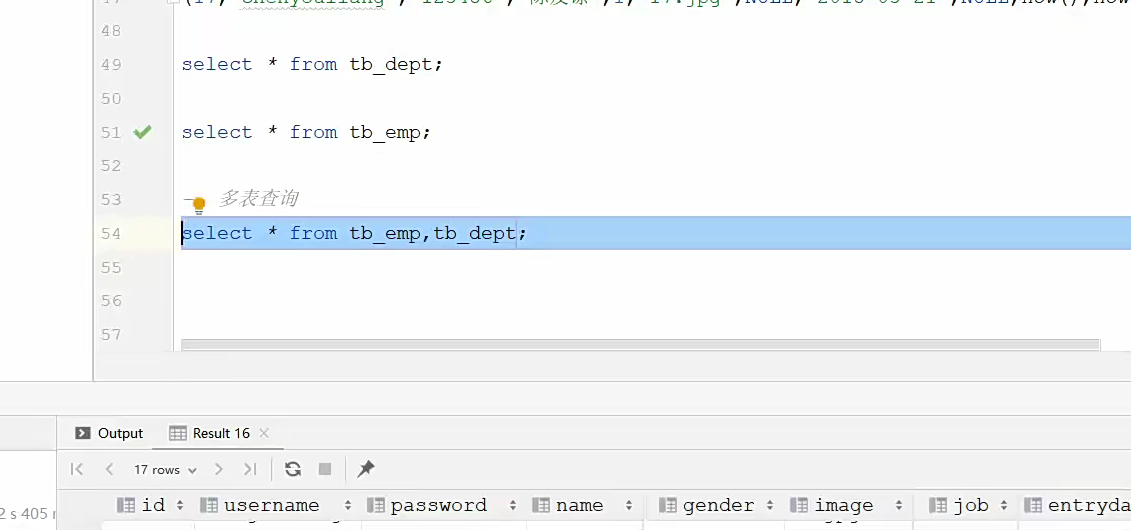
我们按照这样查询完毕之后呢,发现显示了多条信息,足足有85条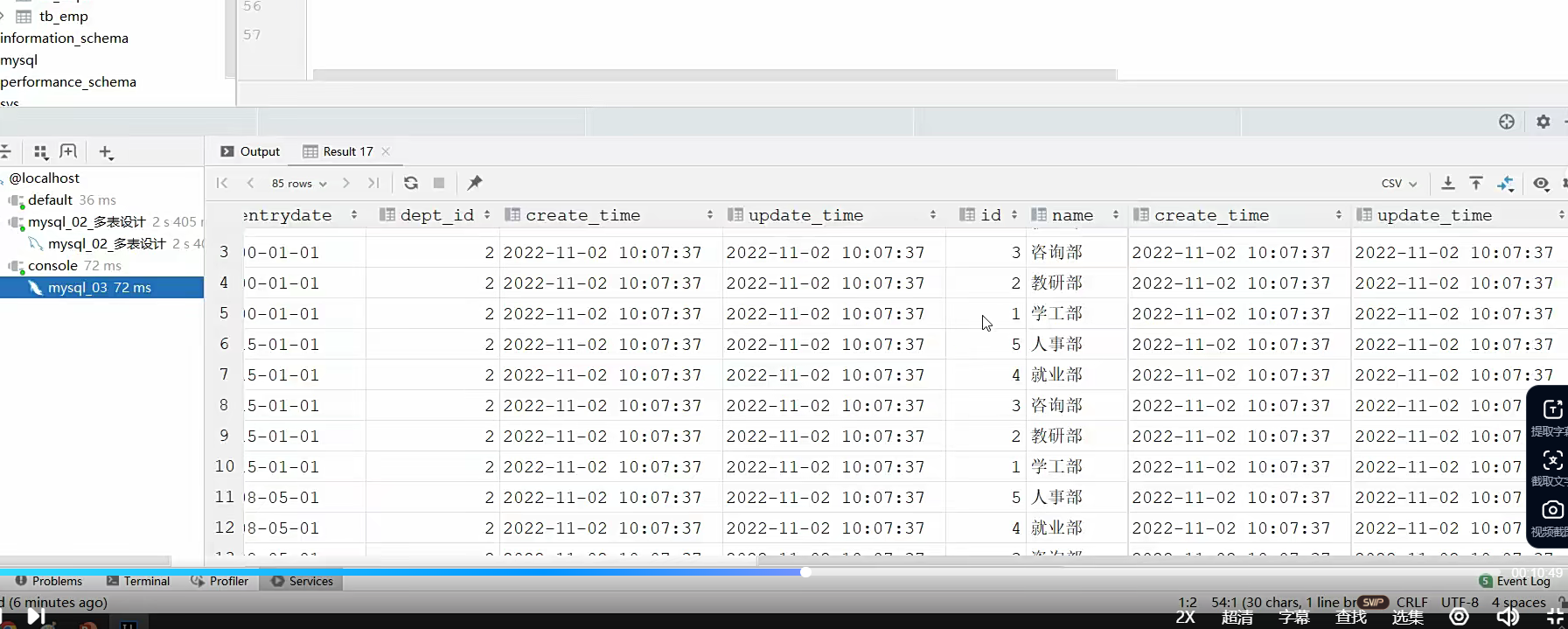
这种就是笛卡尔积,让两张表直接联动;一一匹配,所以匹配出来就有多条结果;
总数据量就是两者相乘;
所以多表查询的时候我们经常添加一个约束where里面写一下,id的匹配这种,然后就能正常查询了;
连接查询;
内连接就是查询a,b两交集部分数据;
外连接就是比如查a表的所有包括交集,和查b表的所有,包括交集;
子查询;
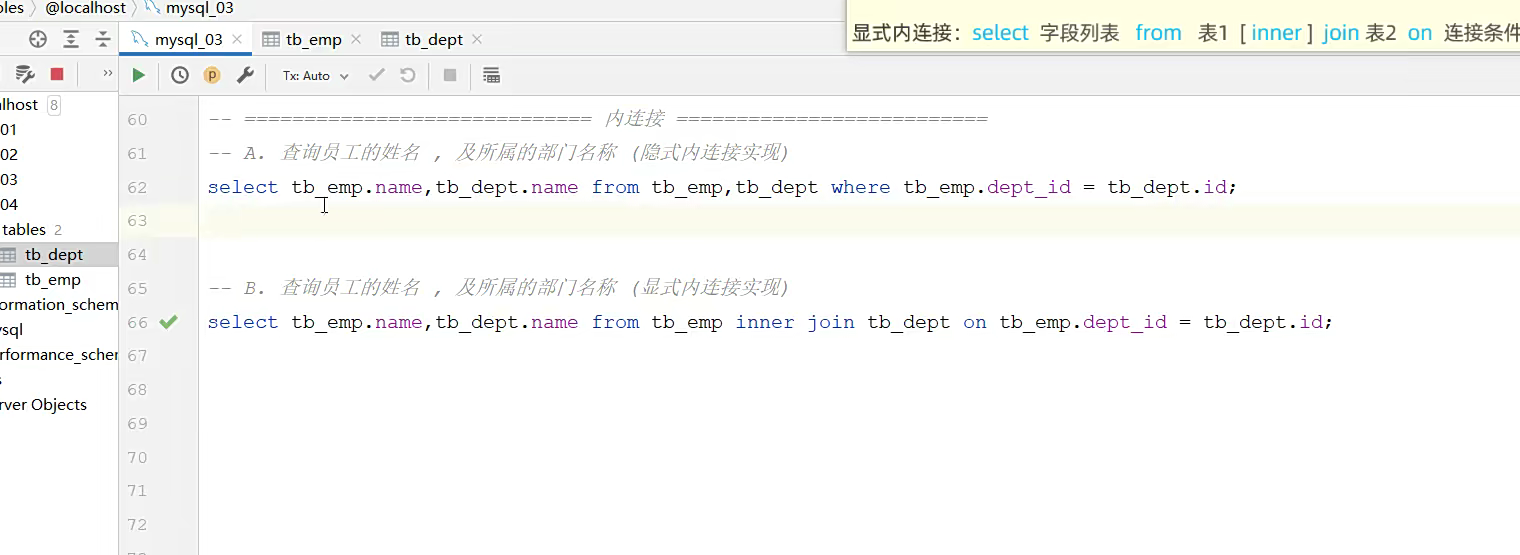
内连接的时候,只能查交集部分,我们该ab交集。只要看名字,就指定两个表的名字,然后添加约束条件,才能保证不产生笛卡尔积;
显示内连接,还是名字都写,然后添加一个【inner】join表二,代表这里两个表内连接,然后再放连接条件;
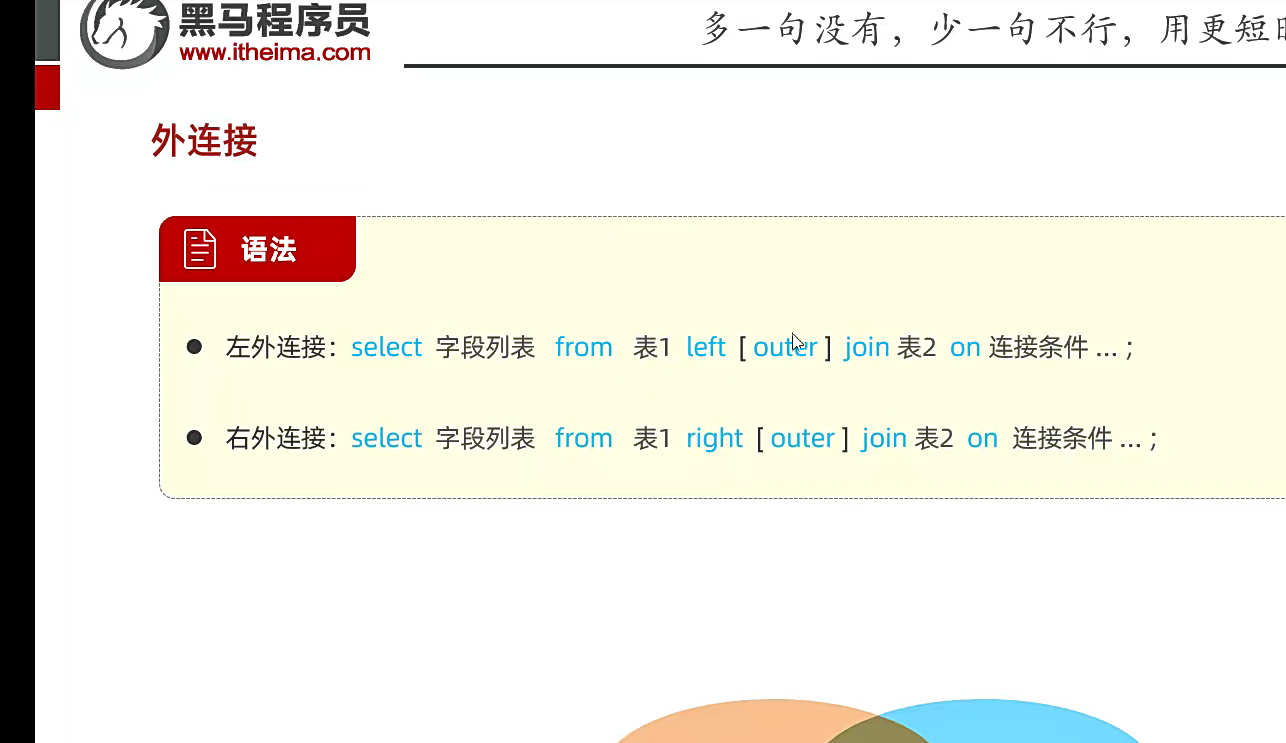
左外连接,右外连接;的语法,是查自己的表加上交集部分‘
其实这个就是,比如你想要左表的所有数据包括交集你就把你要查的表放左边用左连接,但假设要求用右连接就放右边就行了
所以说;基本上就是一个位置问题;也是看要求,很多数据库的东西,其实也就是知道语法就行了;
一般都用左外,本身就能互相替换
子查询
嵌套查询
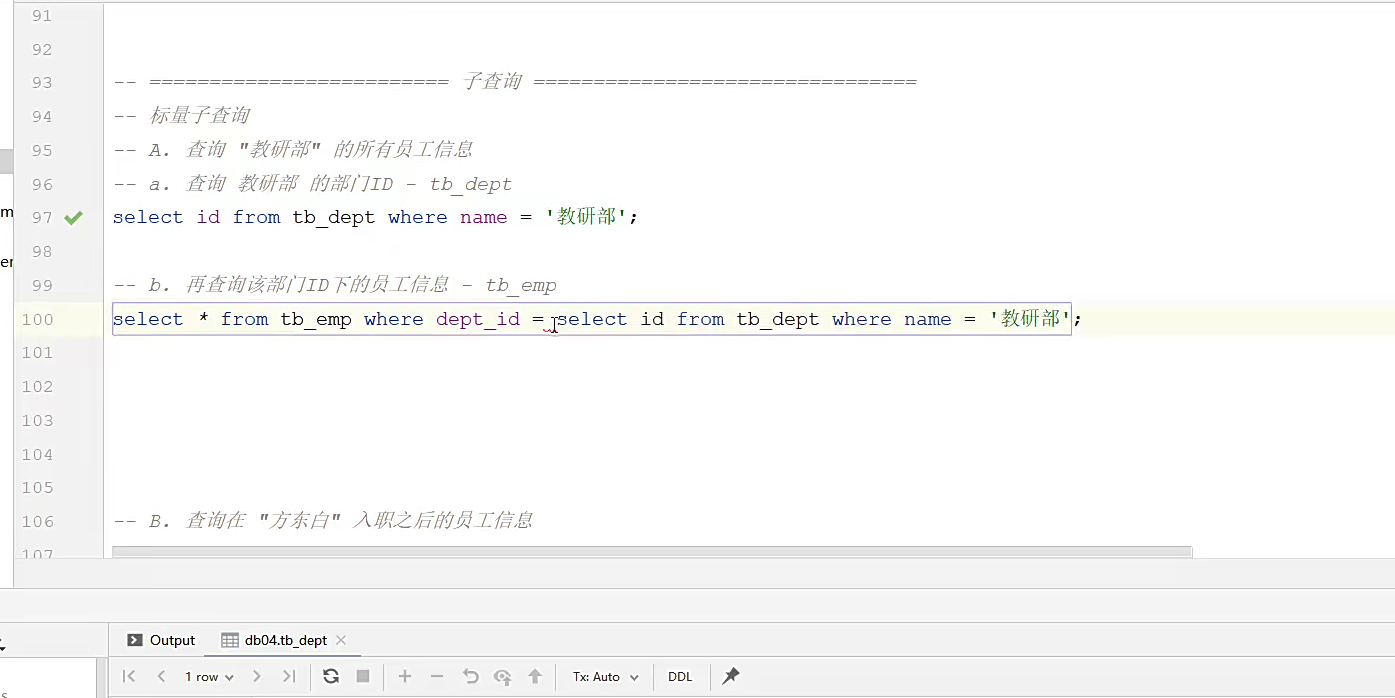
两个查询语句就能完成这个查询,但是比较麻烦,合并成一条,就是上面本来就是查id,下面的约束条件又是id,就是根据id查数据,所以把下面的直接替换了就完了;直接给她一个括号,让他相等就好了;
感觉以前学过,死去的回忆攻击我;呜呜
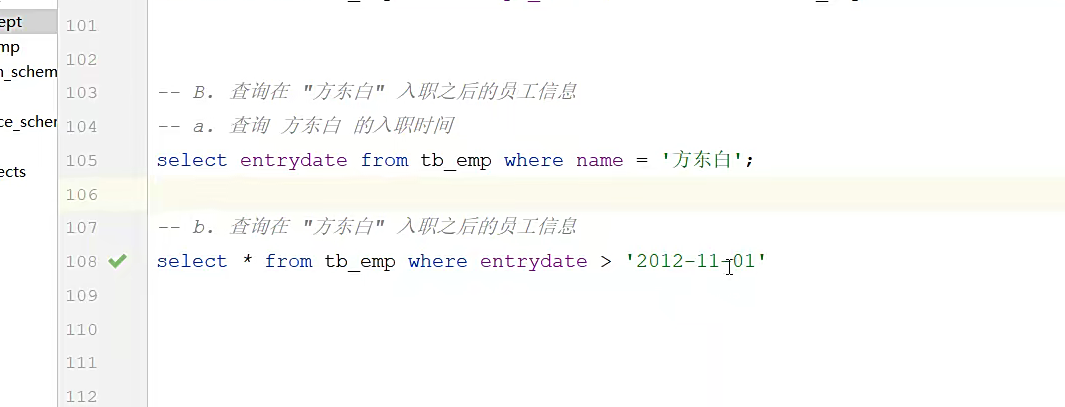
这里逻辑就比较清晰了,要找到方东白入职之后的员工信息,先找到时间,查询对应表把时间找到,然后根据时间找员工信息很好理解;
把他们合并,就是把下面语句的时间进行替换;
推测
select * from tb_emp where entrydate > (select entrydate from tb_emp where name = ‘方东白’)
Ok确实没问题哈;一杯咖啡清醒多了;
他这个嵌套查询返回的是单行单列的值,这边就是说他是标量子查询;
感觉以后这些交给ai更快
然后就是别的类型的子查询;
我觉得可以先跳,时间刻不容缓;
后期都是对sql语句的各种优化;
案例
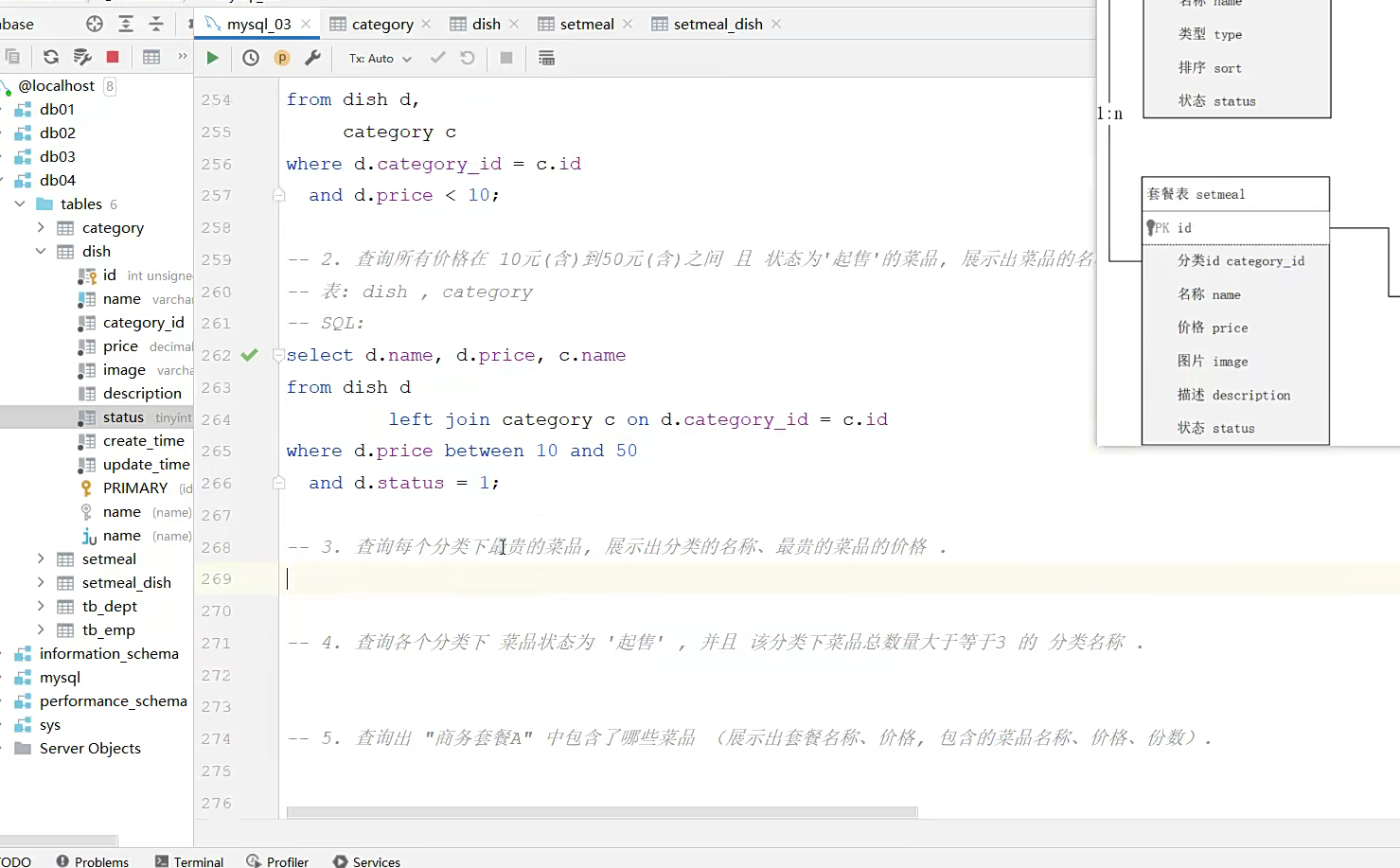
其实多数就是照着打;然后写好约束条件,多表就多用内连接,左外连接,这种,偶尔用嵌套,注意好约束条件,直接表.访问里面的字段就行;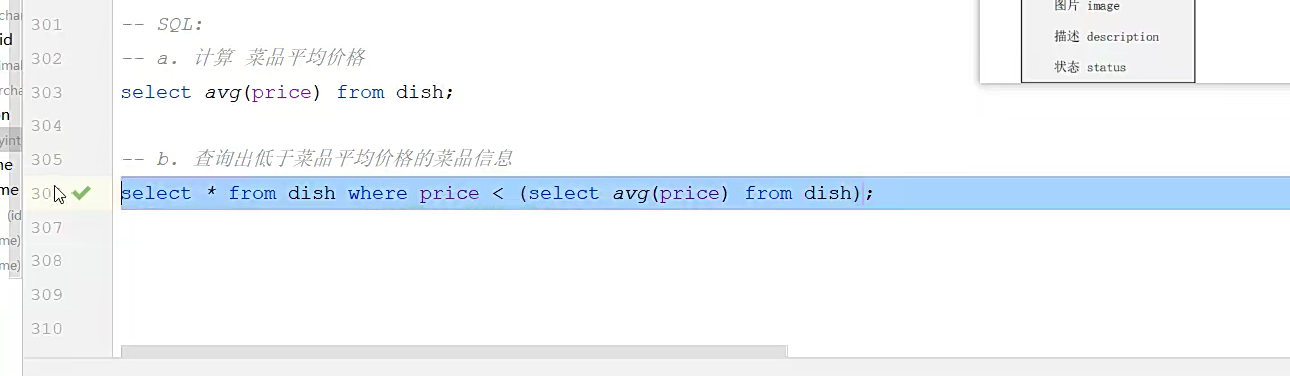
类似这种的,查询语句;计算价格啊;等等,可以用到函数,无论是聚合函数还是什么别的;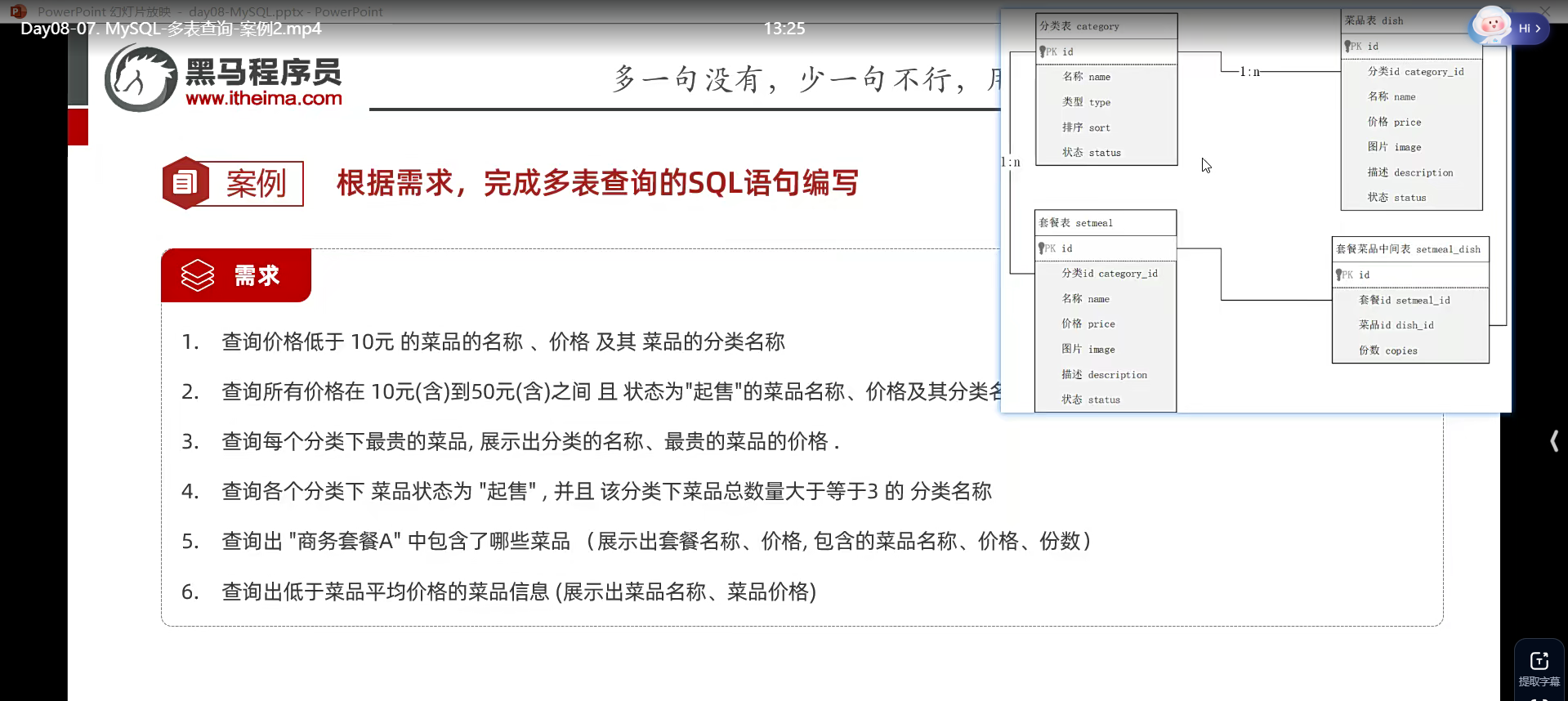
其实总结起来,多表查询,先分析需求,确定那两张表,然后确定查询条件,是谁对应谁条件,配对完毕之后再分析小需求会更好更快,别忘了格式化;
事务


第一条是删除部门,第二条是删除部门下的员工,他们是一对多吗,添加外键就行了,然后查询的时候直接多表查询,部门和员工都显示,约束条件就是员工id等于部门的id,正常查询之后,进行删除,比如删除部门,这个是删除掉了部门,但是我们不删除员工,就还能发现部门没了可是员工后面还是连着部门的;
也就是这个部门没了,员工还在
解决这个,就用事务解决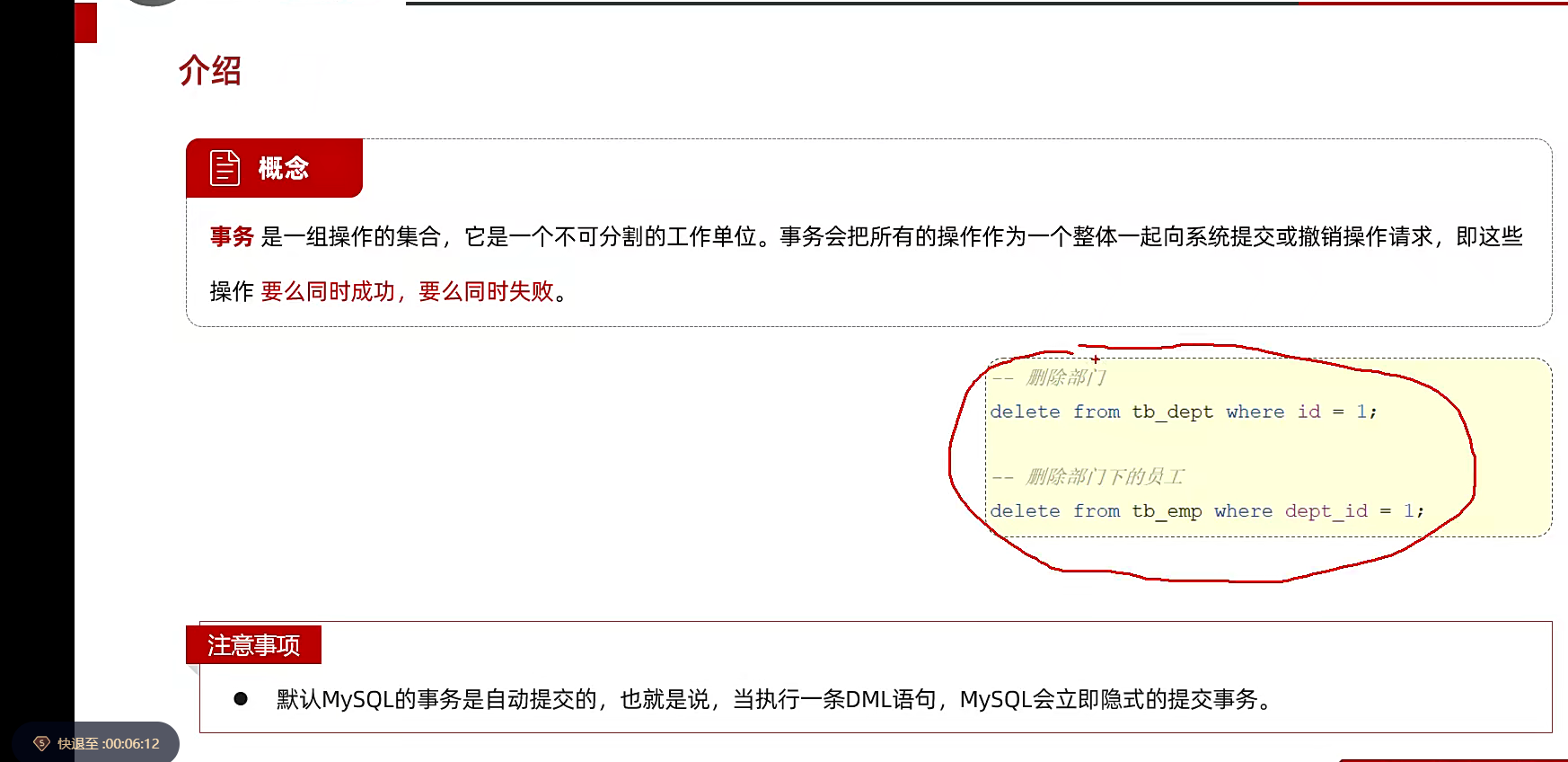
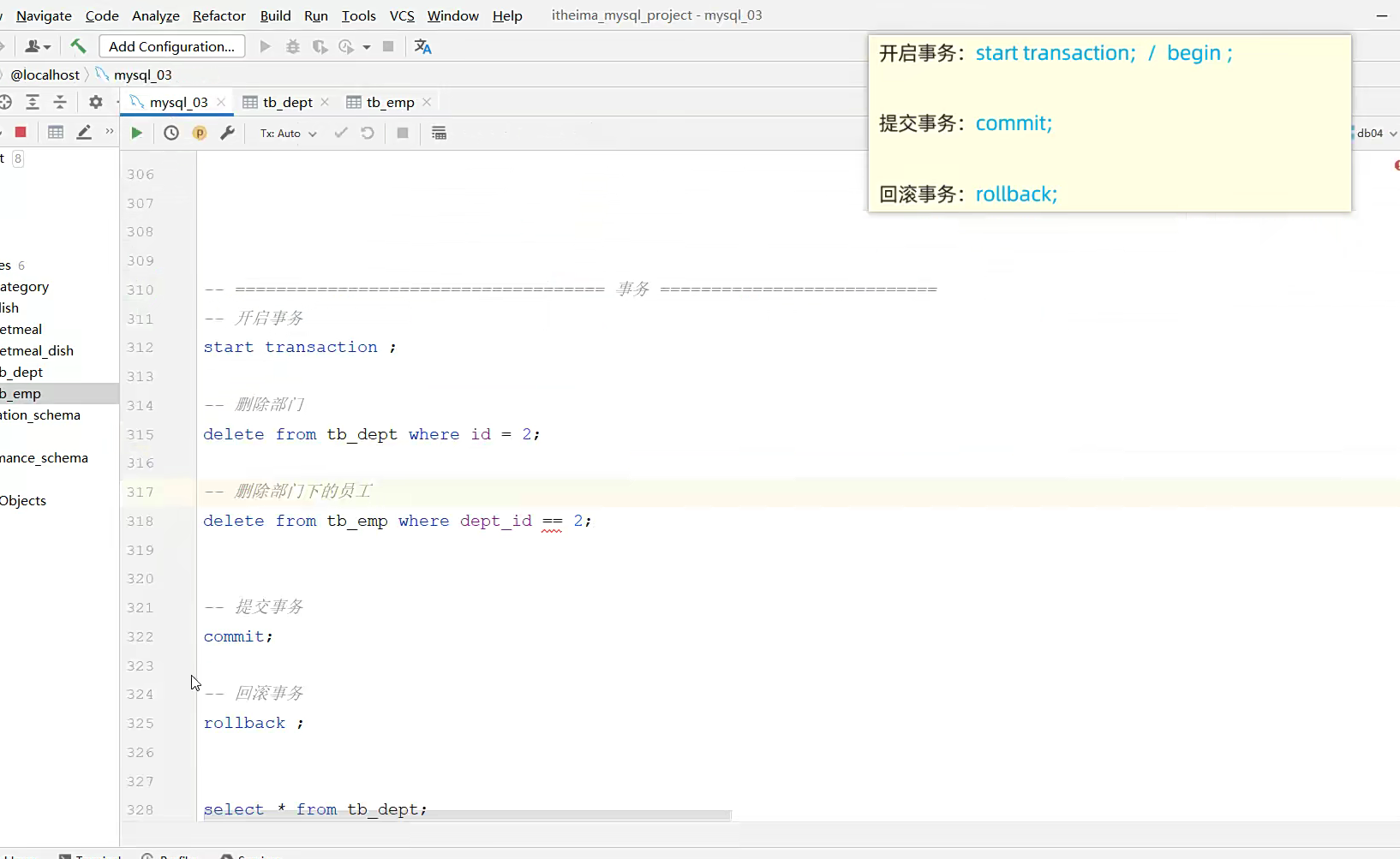
简单来说就是有个流程控制了
事务的四大特性(常见面试题)
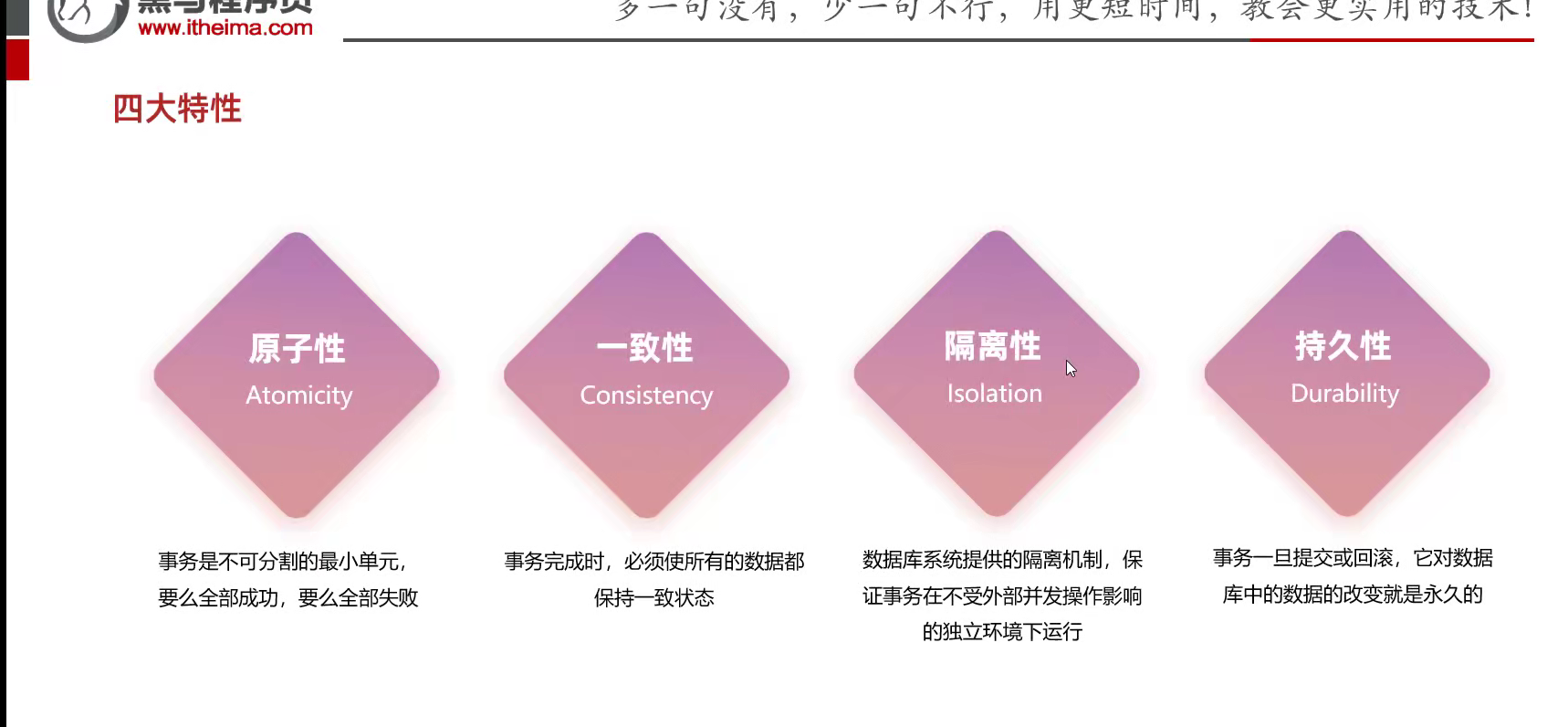
一组操作的集合,根据业务需求来办,比如,解散一个部门吧;等等就是所以事务就
索引
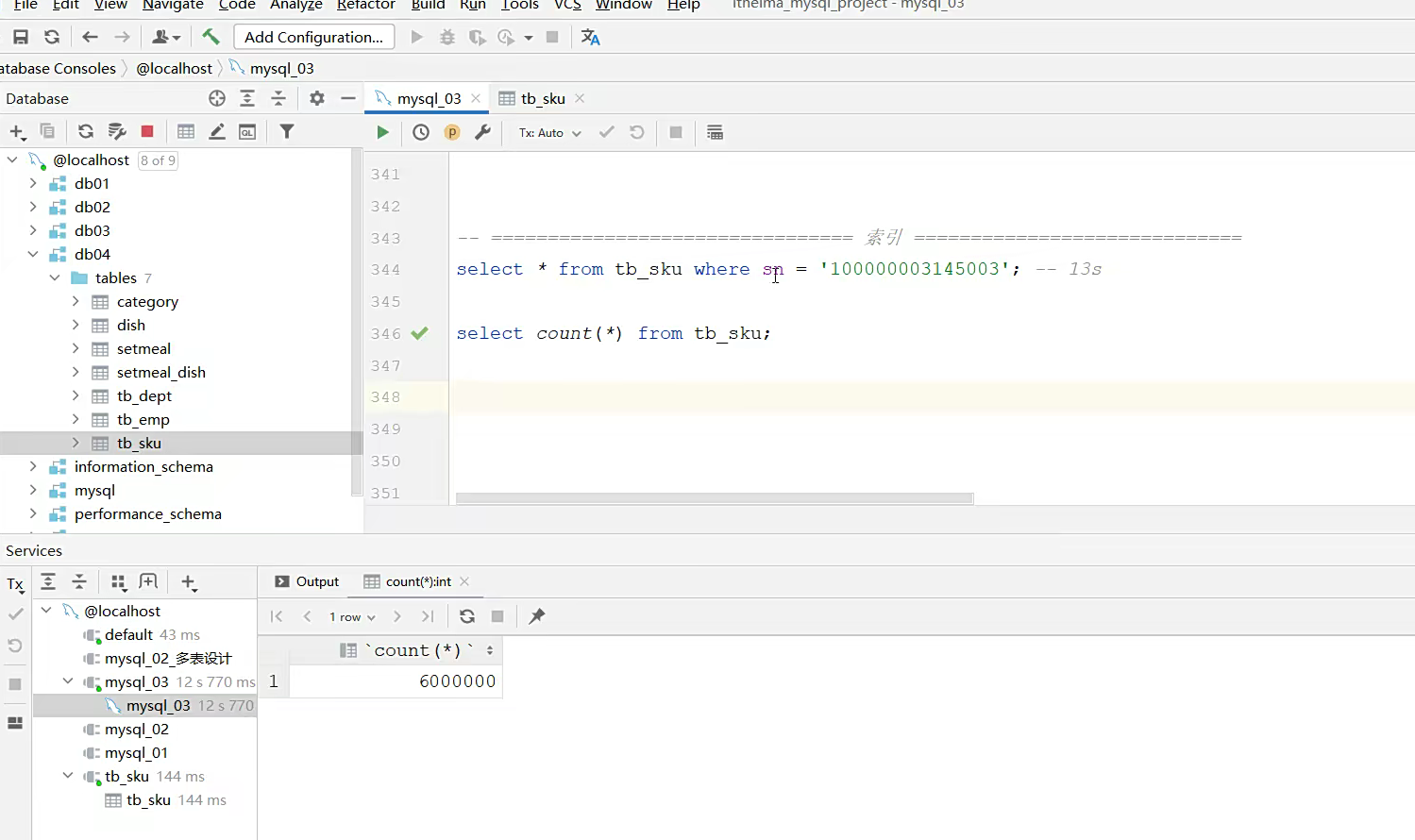
普通语句的查询;源于数据量太大了,而耗时很久;就是这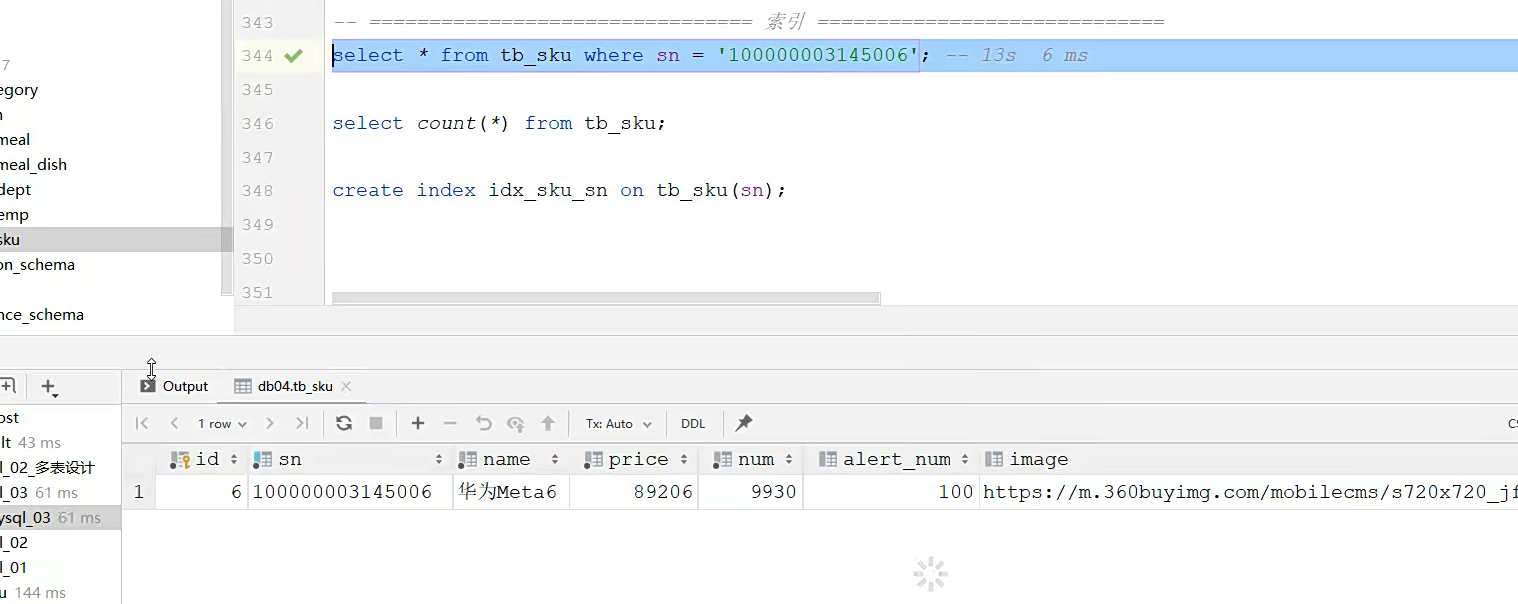
创建了索引之后,查询速度飙升就是这就
因为6百万条数据他都有明确的索引,所以查询起来更快;
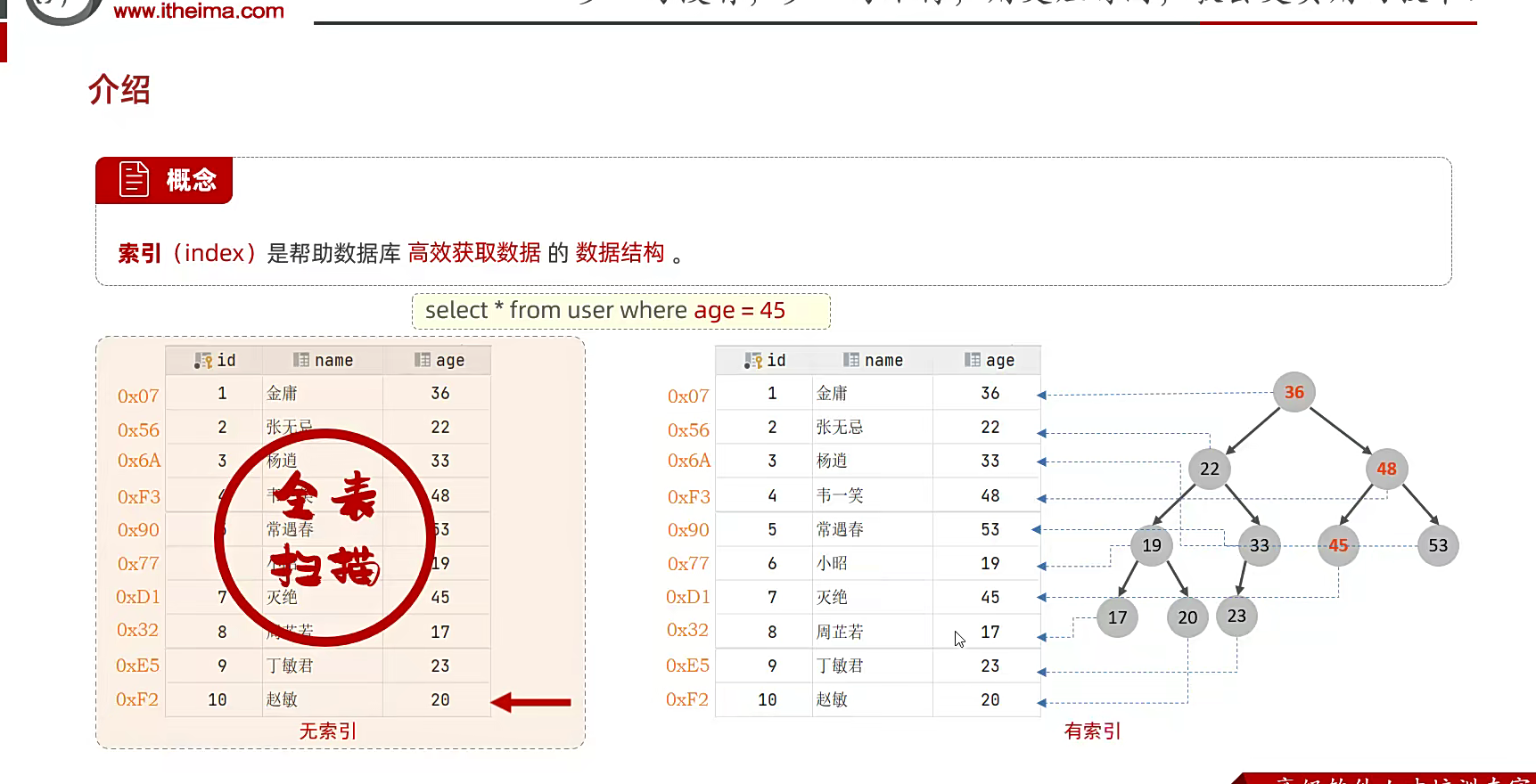
天,原来是这样!!!!死去的回忆攻击我,有索引的时候吧,他直接就是,树形结构,就比如二叉搜索树吧,这一眼感觉独特像bst,我的妈;从基准第一个元素为准,然后依次下排,小的放左边大的放右边;之后这样查找会更快一些,均衡,其实也就是排序算法,很像内个什么排序,我一下子想不起来;
所以索引就是一个数据结构;树形的bst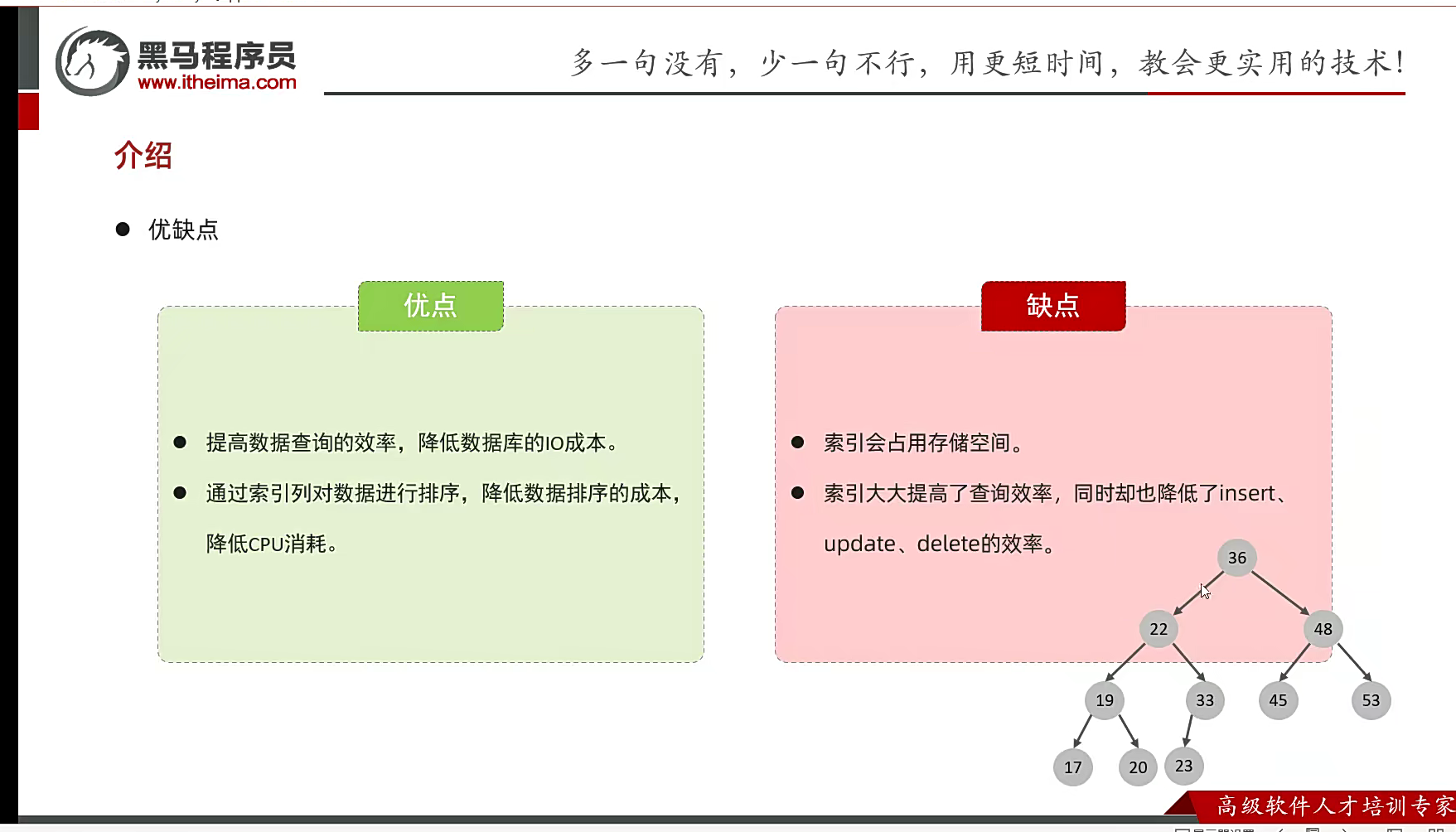
优点显而易见,查询非常快,减少cpu运转时间和消耗了;缺点也并存,像刚刚六百万条数据内个,他占用了2个g的空间;索引大大提高了查询但是增删改也变得麻烦了,你改完可能还得再加一条或者少一条索引,索引得重新建立;该就相当的麻烦了;但是优点更大;
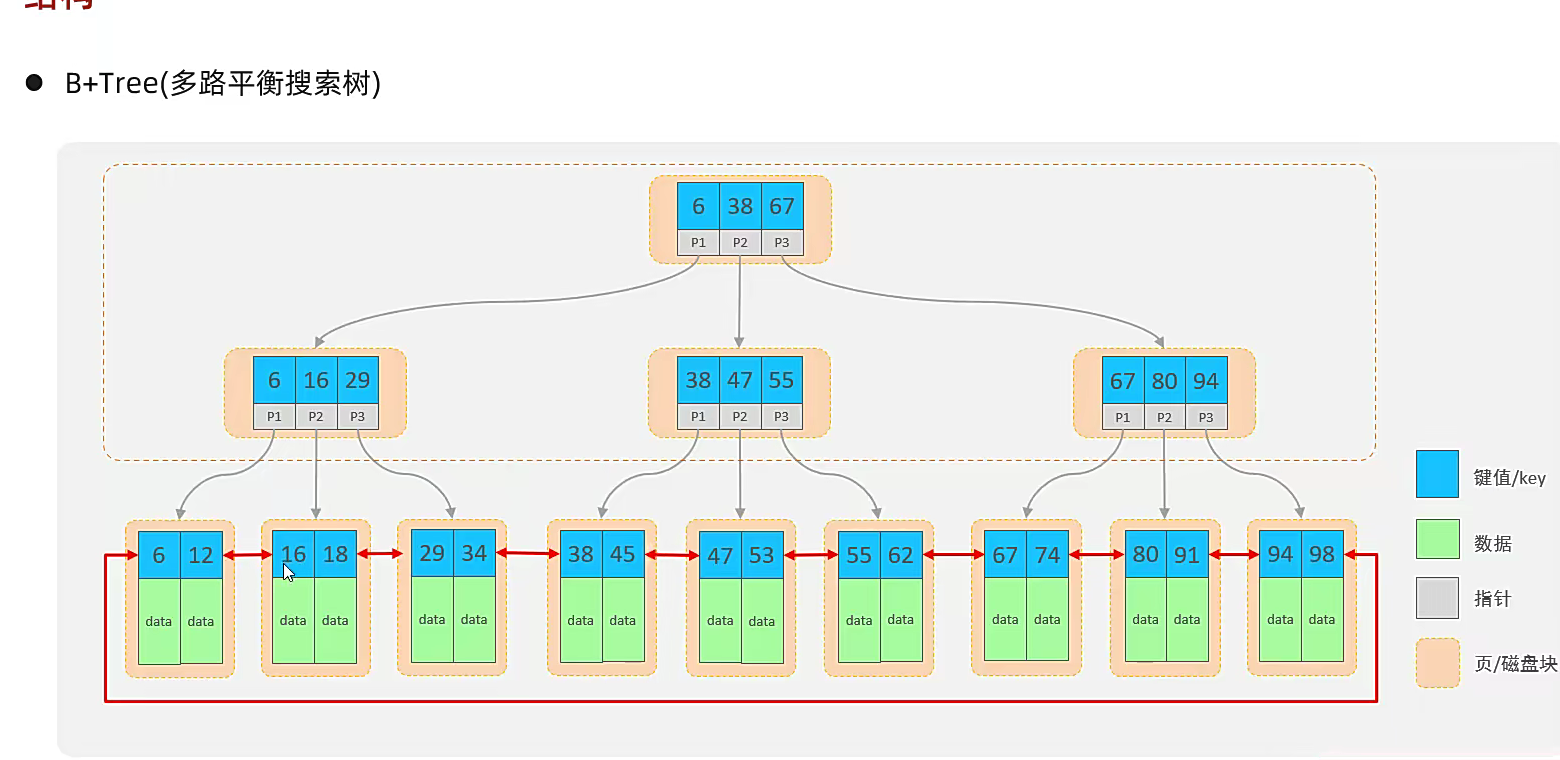
他就是一种索引的数据结构,b+树,他查找一个数字进来是内部是二分查找;然后就是顺着往下一路走到叶子节点,继而叶子节点里面会有对应的数字,找到即可,分多路;
mybatis入门


Mybatis与springboot进行整合
就比如说一个查询所有人信息的一个东西吧;你原来的jdbc是去数据库连接上然后编写sql语句然后发送给数据库,数据库执行返回吗;
现在直接再Java里面写就行了,配置一下mybatis,就能用了;就是sql语句再java里面写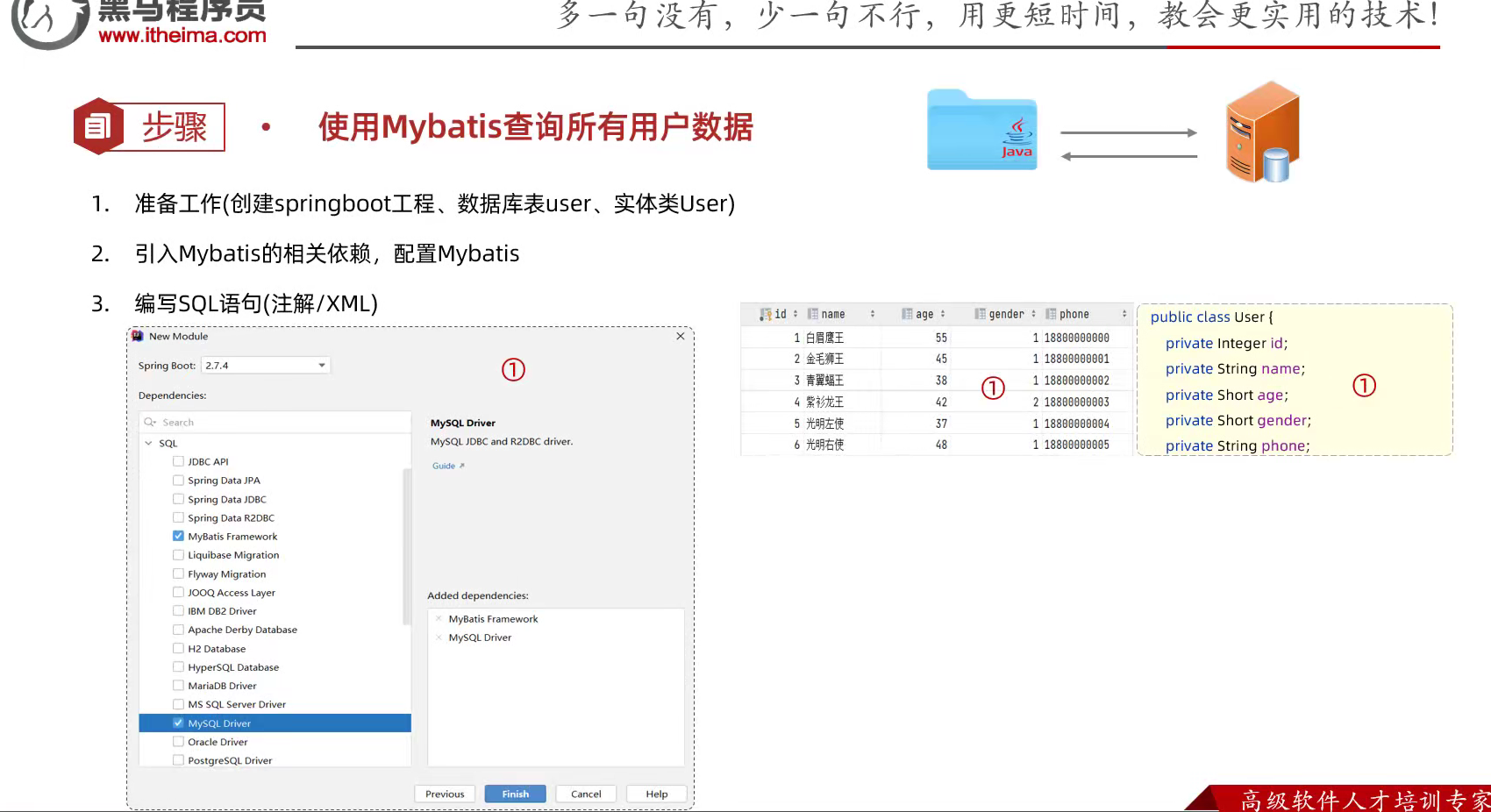
先准备一个springboot工程;给一个用户表,对应有实体类;然后引入mybatis相关依赖,接着去写sql语句;sql语句封装在注解或者xml文件里面,甚至有的都不用写;直接用人家写好的sql语句的注解就行了;非常快啊,增删改查已经要被淘汰啦;
先引入mybatis的依赖和配置
现在用的是mysql数据库因而要引入sql的驱动;然后引入mybatis的依赖;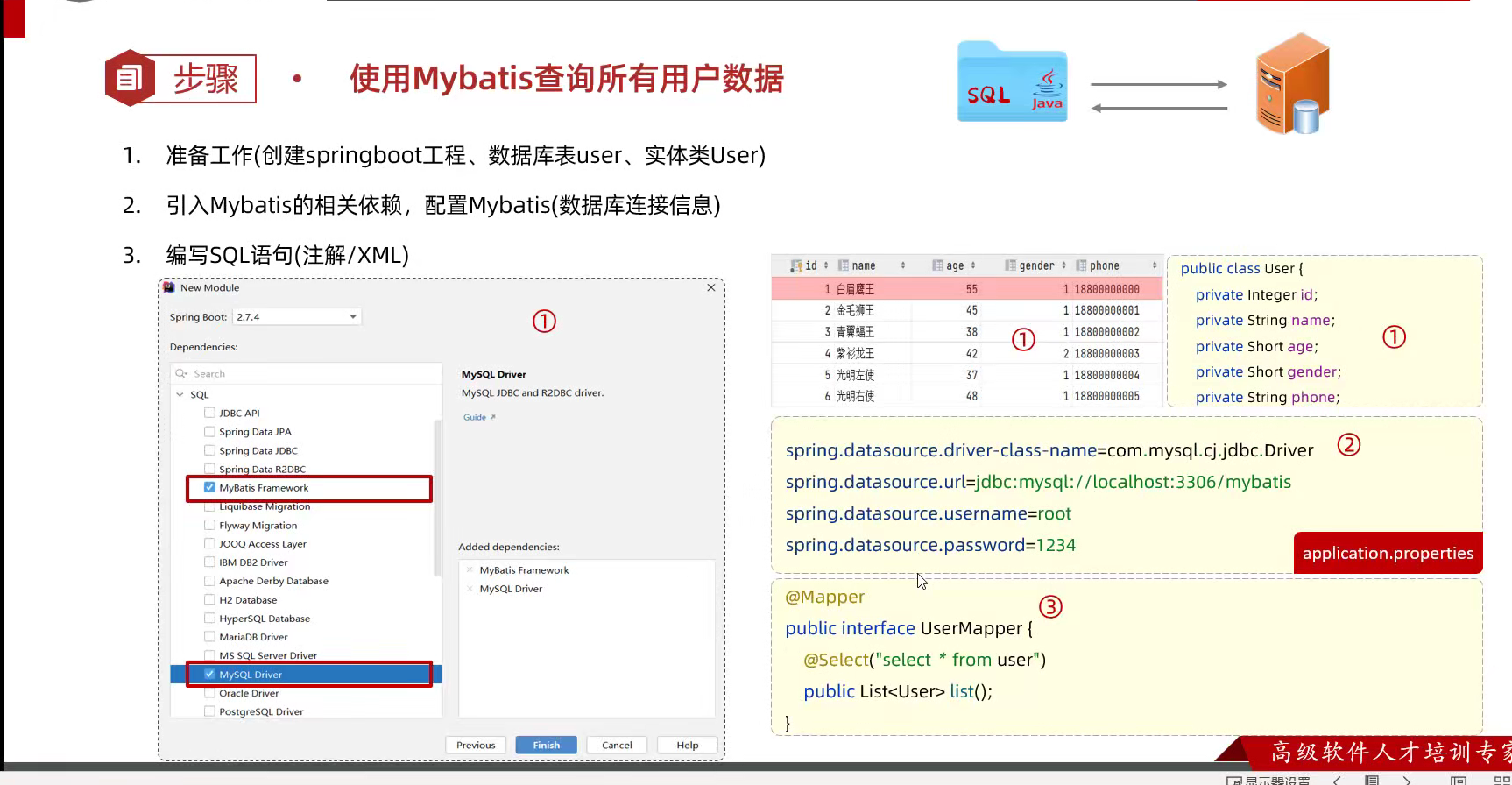
现在先用注解,mybatis的规范就是写一个mapper的注解接着里面的是一个接口,接口里面是标明是一个查询语句,当然别的也ok,再一个接着就是底下定义一个方法,返回类型是一个集合,主要是在Mapper接口里面如何定义sql语句就完了;然后就是,他不用写构建类,实际跑起来的时候,他会自己自动生成实现类;
然后来mapper里面定义xml文件的sql,基于在mapper里面吧纯注解定义没法实现困难sql,就很麻烦,所以还是开一个xml文档更合适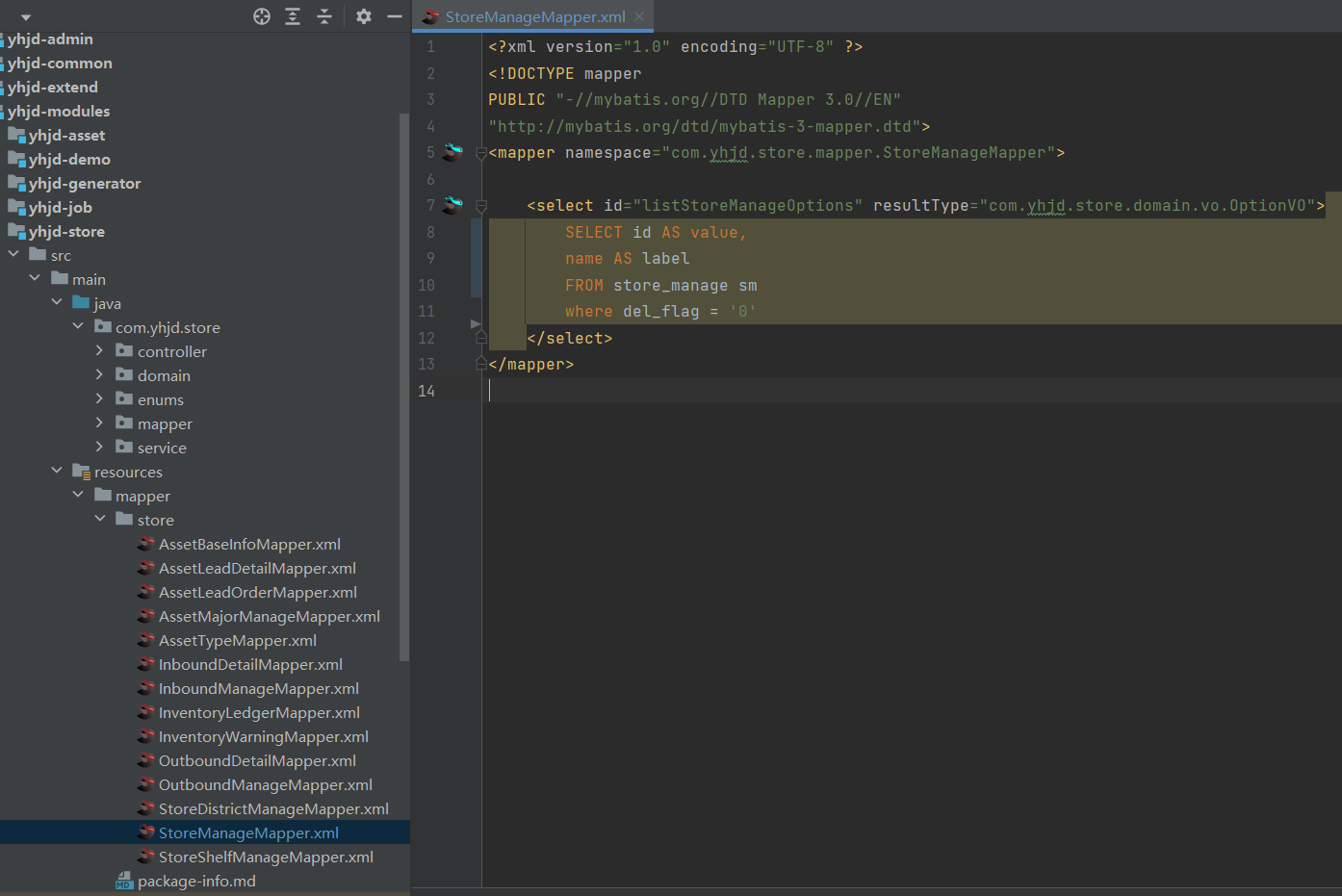
类似于这种吧,然后就是说xml文档官方的注解要标上不然会出问题
搜mybatis中文官网,找到xml的约束,有了这个约束才能成为一个标准的mybatis的材料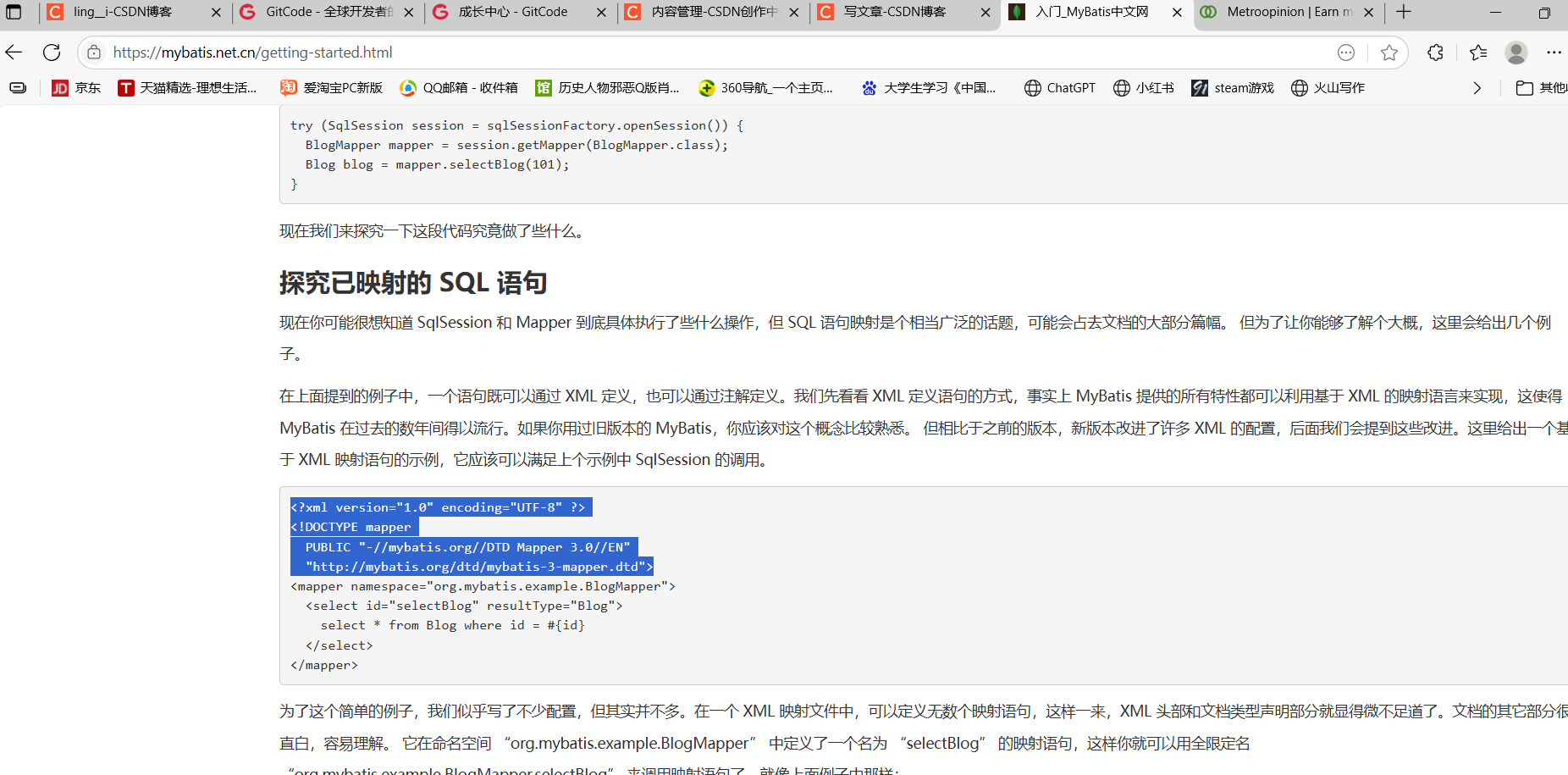
<
?xml version="1.0" encoding="UTF-8" ?>
<
!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">xml文件
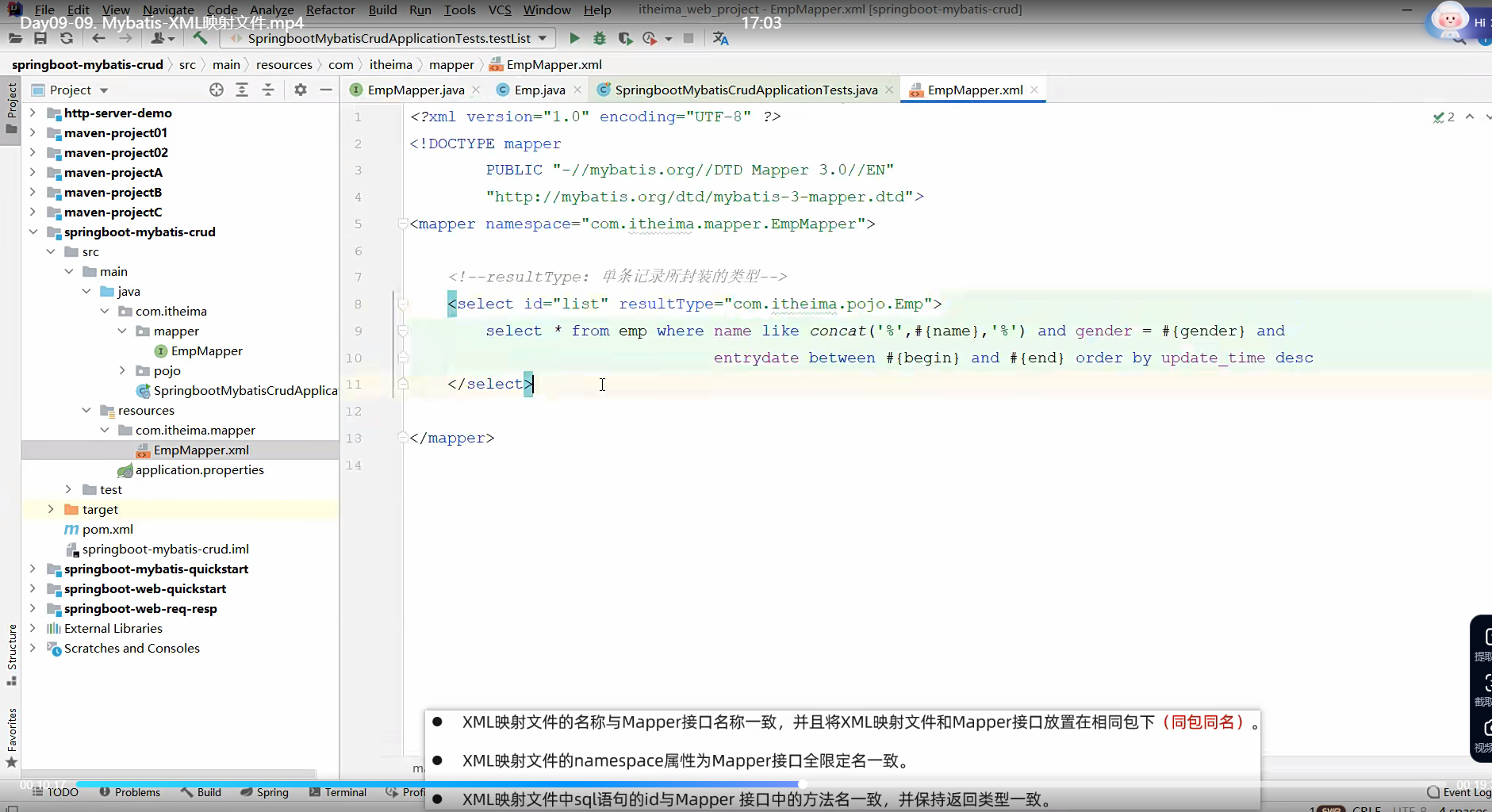
这里的xml文件吧,你写好约束之后呢,要写一个mapper标签哪一个mapper映射过去的实体类的xml文件,不然你查出来的东西他都找不到mapper层,就是,这个mapper标签吧他要表示你输入namespace,这里面就是对应你想要对应的mapper层的路径,然后按照域名反写后面的就是的方式弄过去就行,再一个开始写sql,这里面标签就多了,crud的标签基本都有,免去去navicat里面写了,不过一般都写查,因为增删改他你可以直接去navicat里面弄,再一个就resultType,顾名思义,这就是返回的类型,这个返回的类型他是单条记录的类型,你按照你这个语句查,他就只能查出来一个,所以你允许直接用resultType,返回的东西封装到这个类里面去,然后返回给你id对应的这个mapper层里面的手段,当然结果类型要和方法的类型一致;之后再层层返回;如果你是多条记录的话,确定是数据库记录就Type,不确定那就最好直接用resultMap,map都是给不确定结构的。比如分页吧。
mybatis类型映射

比如就是resulttype里面我单条,或者多条信息我就list<实体类>集合类型,就是用类封装再变成集合返回。假如是别的就是什么分页啊,比如返回一个对象?反正不太确定结构类型的就用map然后技巧的类型用上面的map类型。
mybatisX
用这个插件变成可跳转的小鸟
动态sql
简单的来说就是再sql的xml文件里面再sql的后面加上where条件语句;里面用test判断参数是否传,传的话给一个参数,不传就给空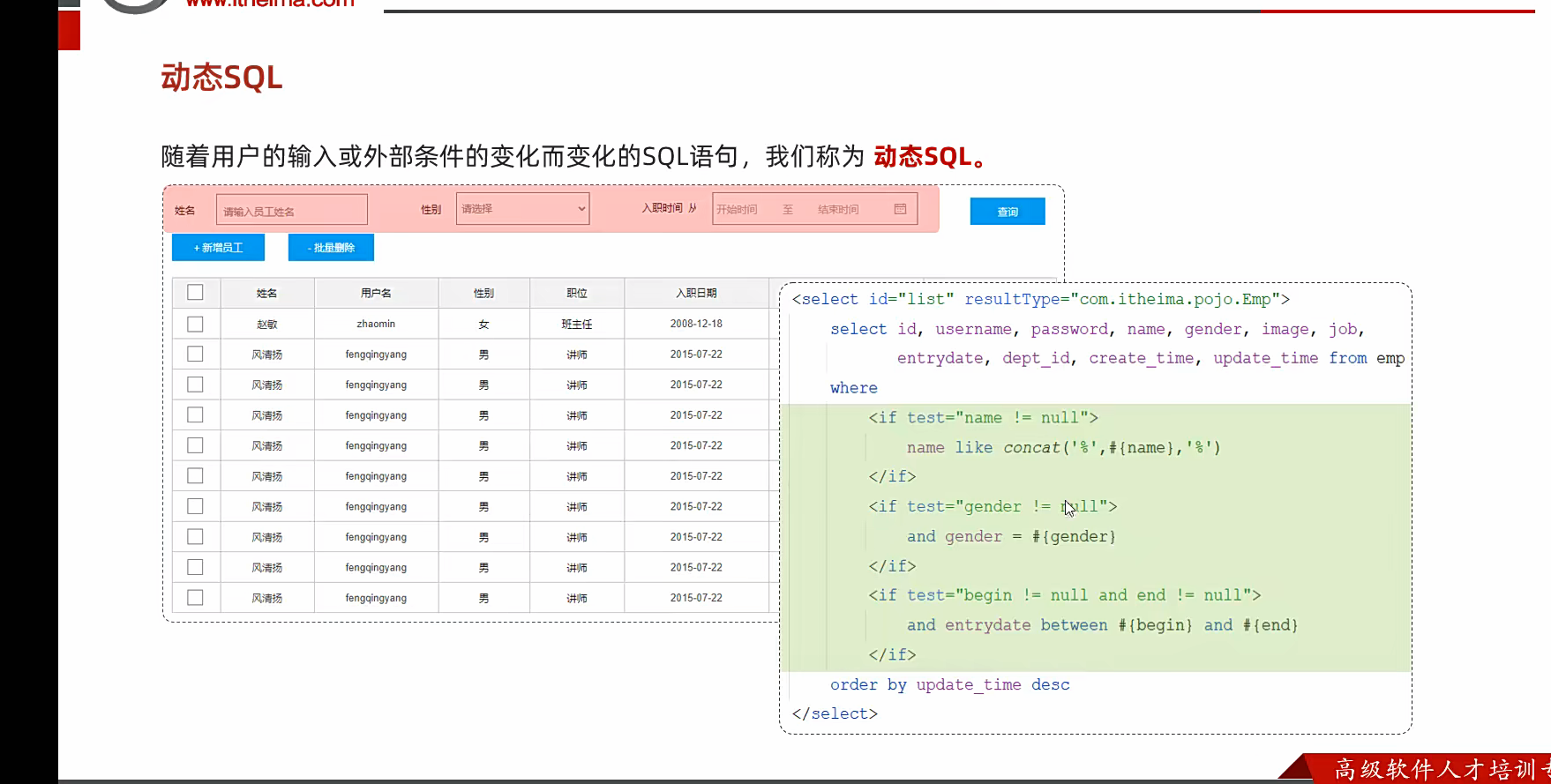
通过该动态的sql传入进来吧,你就能够根据用户的操作的参数进行查询了,我们不可能把参数写死;最好的动态就是用判断语句,我设置好查询条件,但是倘若其中一个查询条件不为空,我就去模糊匹配,类推,看是否模糊匹配,所有参数都来一遍;
好继续,然后呢?大家如果为空怎么办,为空就不去拼接这个语句呀,就没有这个参数嘛给这个参数传空;
当然,这个所有的动态sql他都要写在where之后哈
学一下动态sql的标签
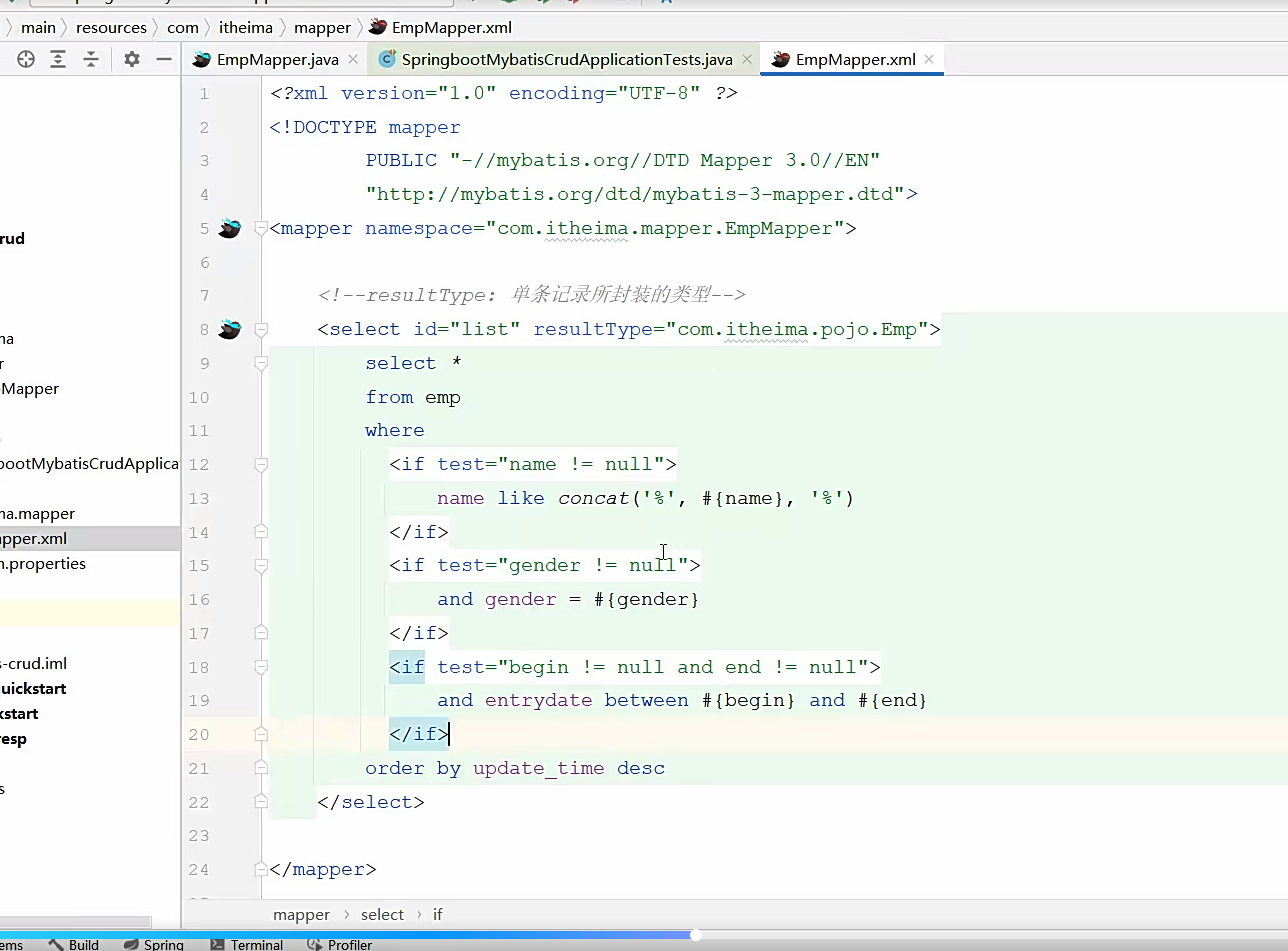
字符串拼接的函数;就是这是if的标签,要是测试的名字的参数不为空,那名字就去模糊匹配 concat
以此类推,后面都说预编译sql,这种写法是可以直接替代字符串的;
好,然后直接正常传参就行,去test里面传递参数;

测试类如何测试呢?首先整理思路,你sql写好了是不是封装到了你建立的员工对象里面去,所以你是不是直接给你的实体类传参就可能了?
梳理,跟敲
我现在现在navicat里面建立了一张表,然后我去写好动态的xml文档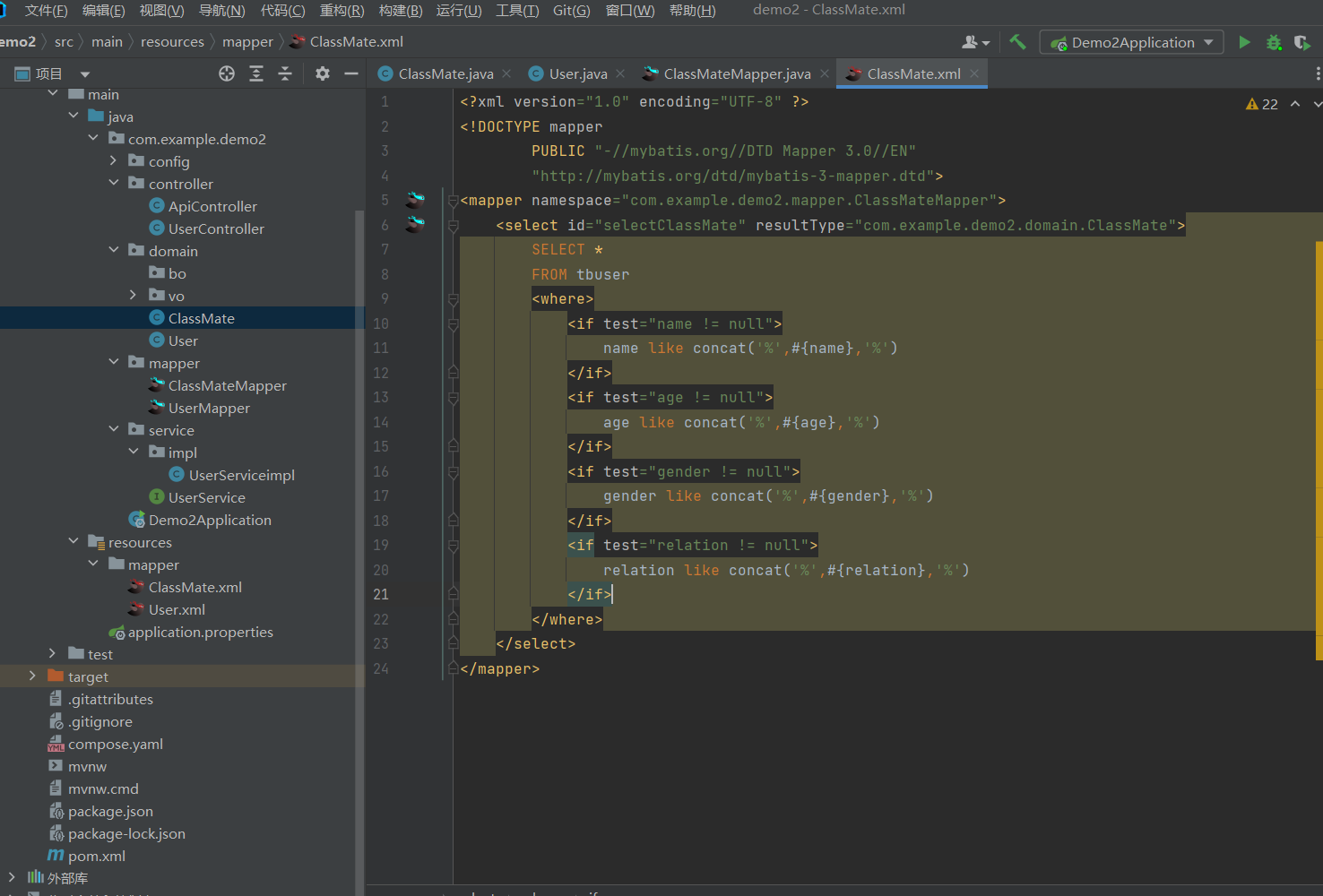
把刚刚学到的if 的标签用好写好之后,记住你的官方约束,mapper里面的 namespace是记录你这个xml文件对应的是哪个mapper接口,写对位置,然后写查询语句,查询的id要与mapper里面相同,再一个是resultType和Map的区别
resultType与resultMap的区别
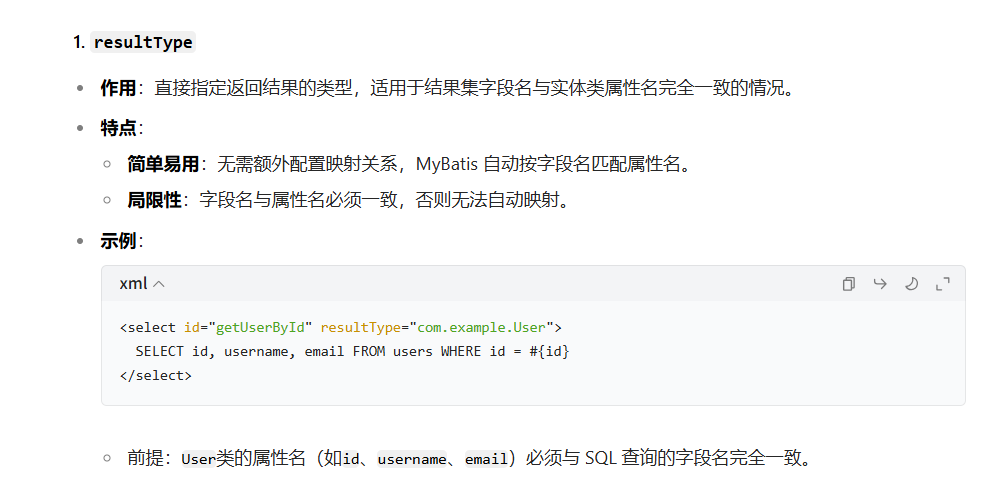
必须一一对应;就是他这个示例呢就是从这个表里面查这些,然后条件是动态的id,根据人家传进来的id去替换字符串,type是把查出来的这些东西对应到这个类里面的字段里面去。因此,反向思考,你像传参你不就直接去主类里面给你的user类创建一个对象,接着直接.set 不就设置了吗?因为他创建get set手段不就是为了把字段暴露出来可以修改嘛;总得来说,type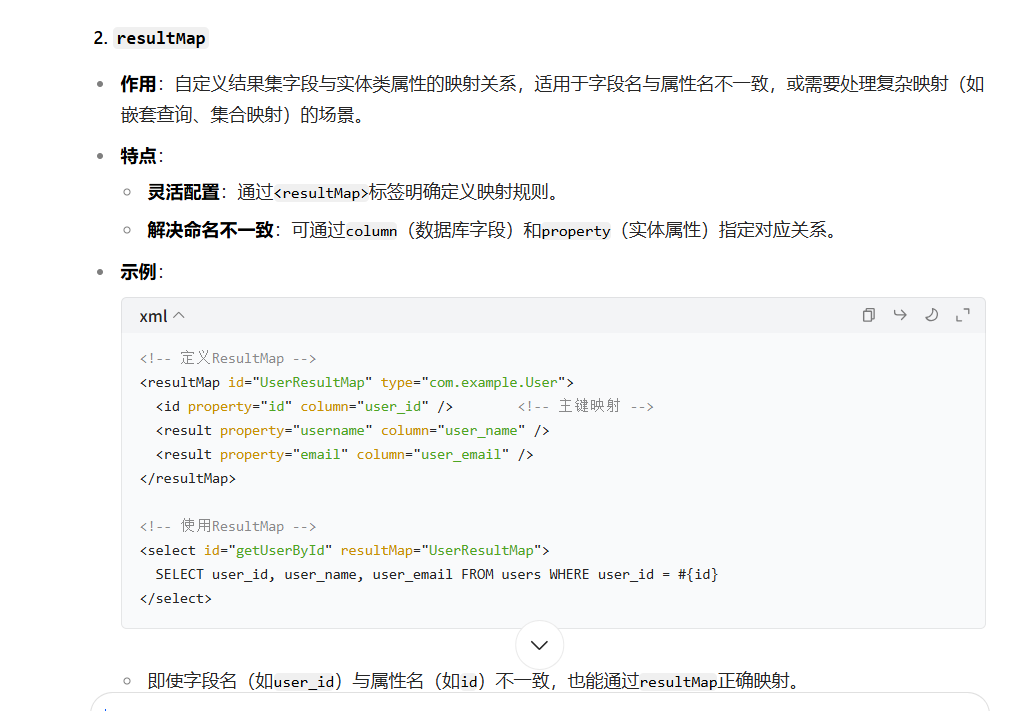
map就可以不是一一对应啦;map的结构他好像就不太一样,他的id不用去对应方法名字,然后你行自己定义映射的规则,比如如图的下面的标签。你自己定义哪个字段对应表里面的哪个字段;先定义好规则,然后去下面使用resultmap开始查询的时候就等于他,id就等于你定义的规则;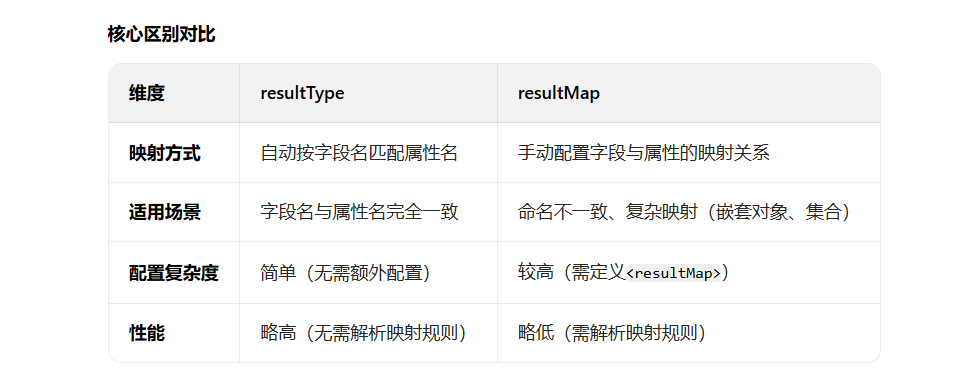
测试,写死参数
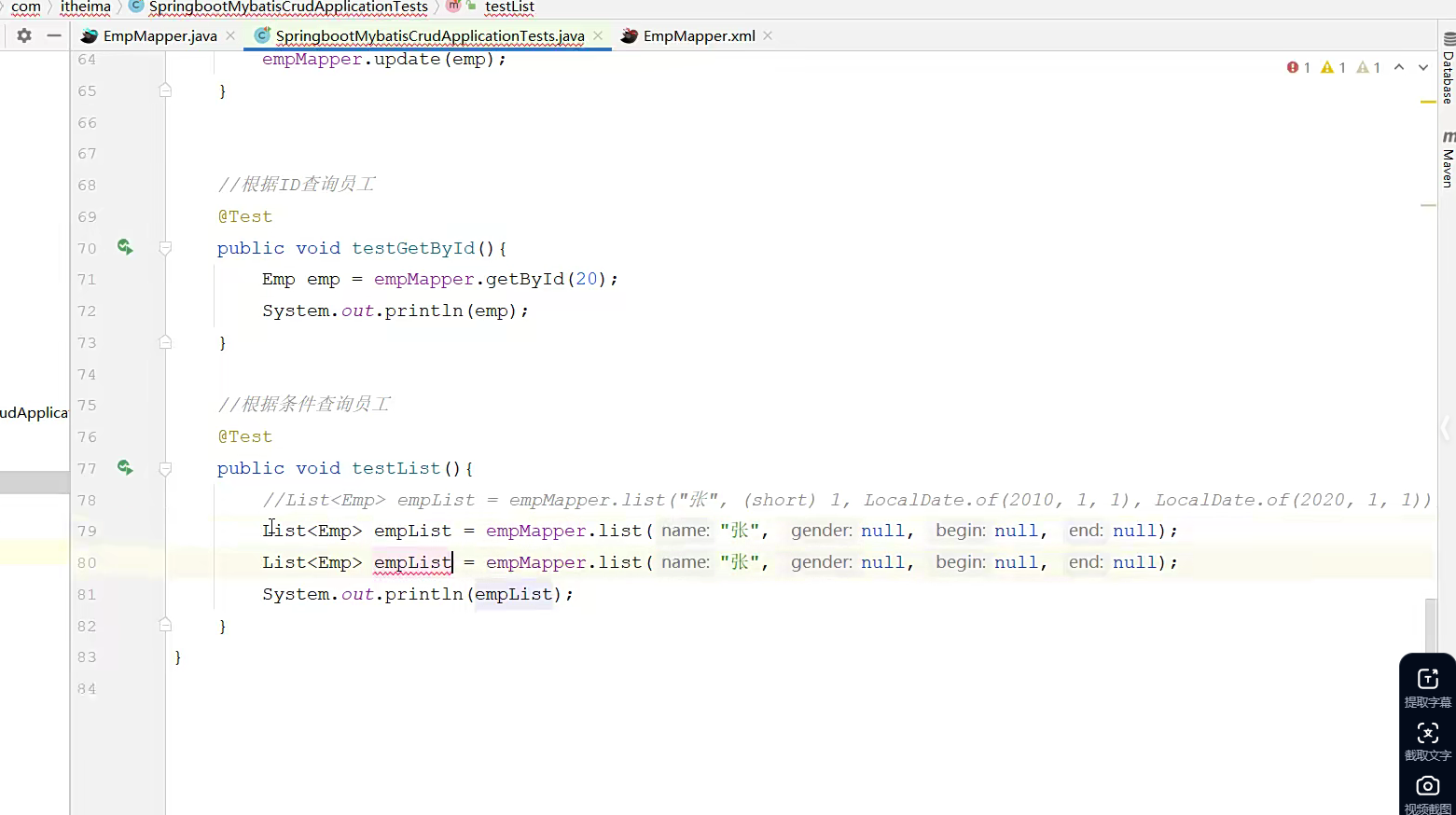
emp这个实体类;就是先来分析一下他怎么写的,起初他在测试类里面,建立了一个小的单元测试,他定义了一个方法,公开 方法返回值的类型是未定义的void 然后testlist是方法名字;方法体里面的逻辑是用一个集合变量去接收到查的东西,后面的是用这个mapper接口的bean对象去访问到mapper层的手段,list,调用这个方法就是直接给这里面赋值,直接传参;传参过去后,弄回来的东西吧用一个变量去接受;这个变量的类型吧是List集合类型,集合参考的
疑问1,为什么mapper层这个方法可以直接传参赋参数?
通过因为以前都是直接给实体类创建对象随后用对象一个个设置;现在的意思好像是mybatis允许自动绑定参数,既然写了这个方法,就和xml文件融为一体;当这里面有参数的时候呢,会自动识别给xml然后传递进去,正好你的xml里面的sql是动态传参, 你的条件是若是不为空才去拼接;为空那就不去拼接了;既然mybatis给你映射好了,以后能够直接在别的层调用mapper层的方法了;然后给其传参;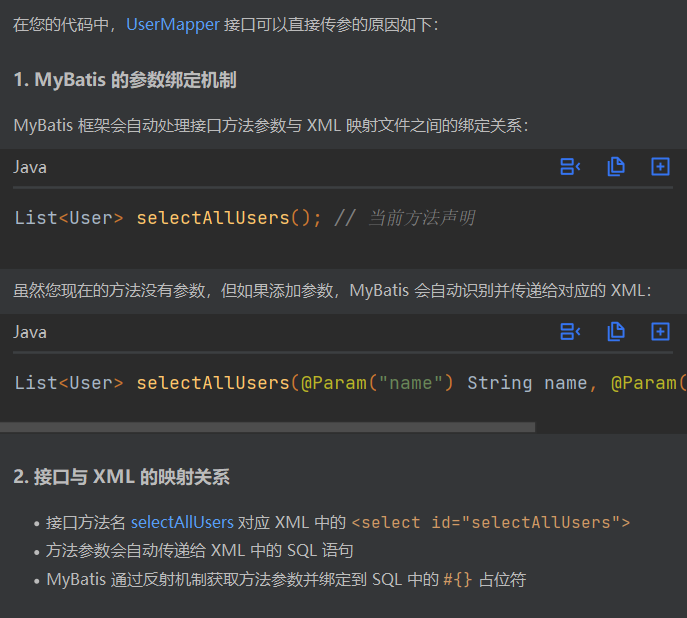
所以说采用起来吧,你写好了xml文件,你要去封装返回给mapper层的时候设置好对应的参数,在手段的括号里面一个个写@para;之后逐层返回,这样你外面的controller层啊才能调用到,给前端,这样前端才能把监听到的用户的操作返给你;
疑问2,为什么接收到的集合类型里面非得加上该实体类对象?
干嘛的接收了谁的;就是解答,本来就是集合类型,里面多个实体类对象是明确这个集合只接收这个实体类的对象,更精确了;也让别人更清楚了你这个集合
postman 测试,前端测试,正常业务流程
在postman里面连接好现在的端口,然后去逐一测试,postman里面你就可以进行传值啊等等的操作吗,那我们就不应该把参数写死,要等待前端传值进来,比如前端要这个数据,然后传进来了,一个张吧,别的都是空,这样的参数传递给后端之后呢,后端根据这个去查询,查到的数据,作为一个集合返回,这个集合明确了是封装这个对象的东西;返回之后前端拿到了这个集合,用for遍历一下,想作为列表输出还是别个输出都行;
问题1;现在出现的问题是:后台我可以正常查出来,但是不知道为什么我的postman里面查出来是一个空的集合;
开始,可能是第一个是有映射挑战,映射的没对上,xml材料和实体类对不上;
可能性2,查出来为空没有做对空的处理;
待解决
完善更新

更新吧
更新可以是就是比如测试类里面有个新的功能吧,其实也就是修改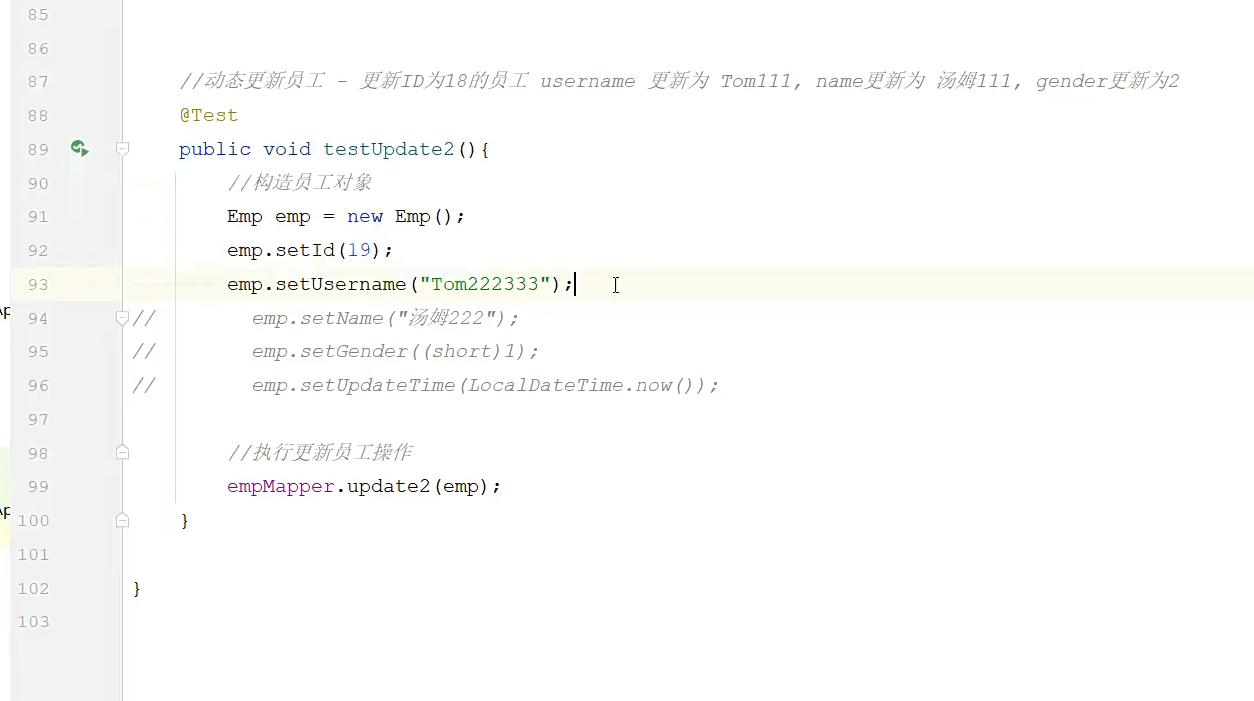
他是直接在单元测试里面,构建类的对象然后直接进行更改;这不是直接在实体类里面进行更改了吗,然后调了一下更新的方法,把这些值给赋进去;

通过于是说其实以后写标签,最好的直接就是用where标签则可,一个大where标签可以嵌套很多小的if 标签,之后里面能够写很多动态sql;
动态sql删除
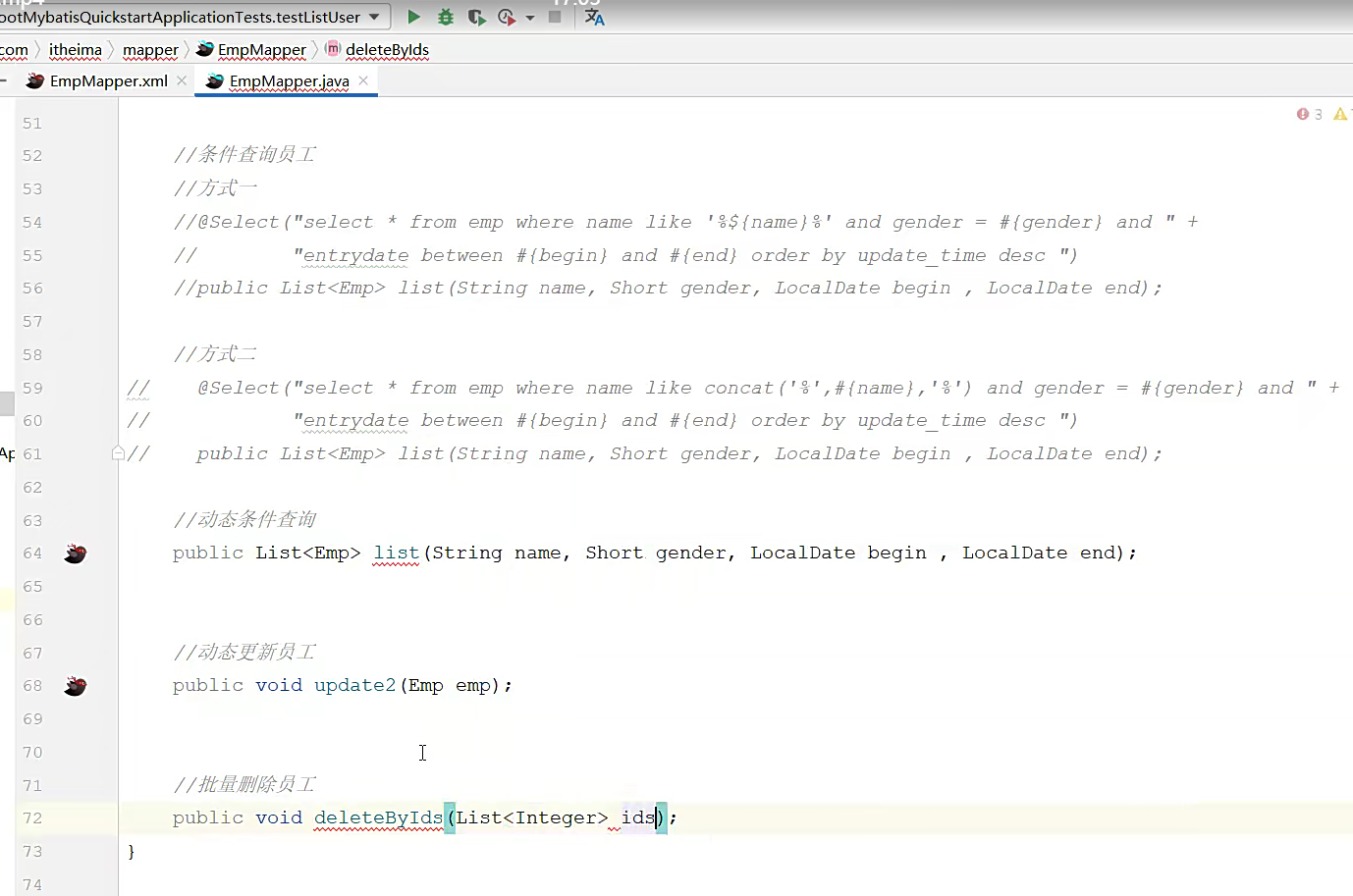
一样的在mapper层写好方法,写一个批量删除吧,然后他给该技巧传递了个参数,就这个集合的参数ids;就是首先还
然后去xml文件里面去达成这个方法,在xml文件里面放一个删除标签,然后里面开始写删除的逻辑,删除,首先写删除的sql,不过你是动态删除,人家要删id为2,的你怎么能预测?所以你要获取到用户输入的id,所以要有参数要有预编译sql,接着,他比如做批量删除的时候,就会传过来好几个id,然后就是一个集合,集合里面有四五个id吧,你拿到之后需要去遍历,遍历访问你就得用for,接着就有这个标签,foreach,这个标签里面他自带了一些属性你需要去完善,比如,第一个collection的集合里面是就是集合名字,剩下 的介绍如图所示;
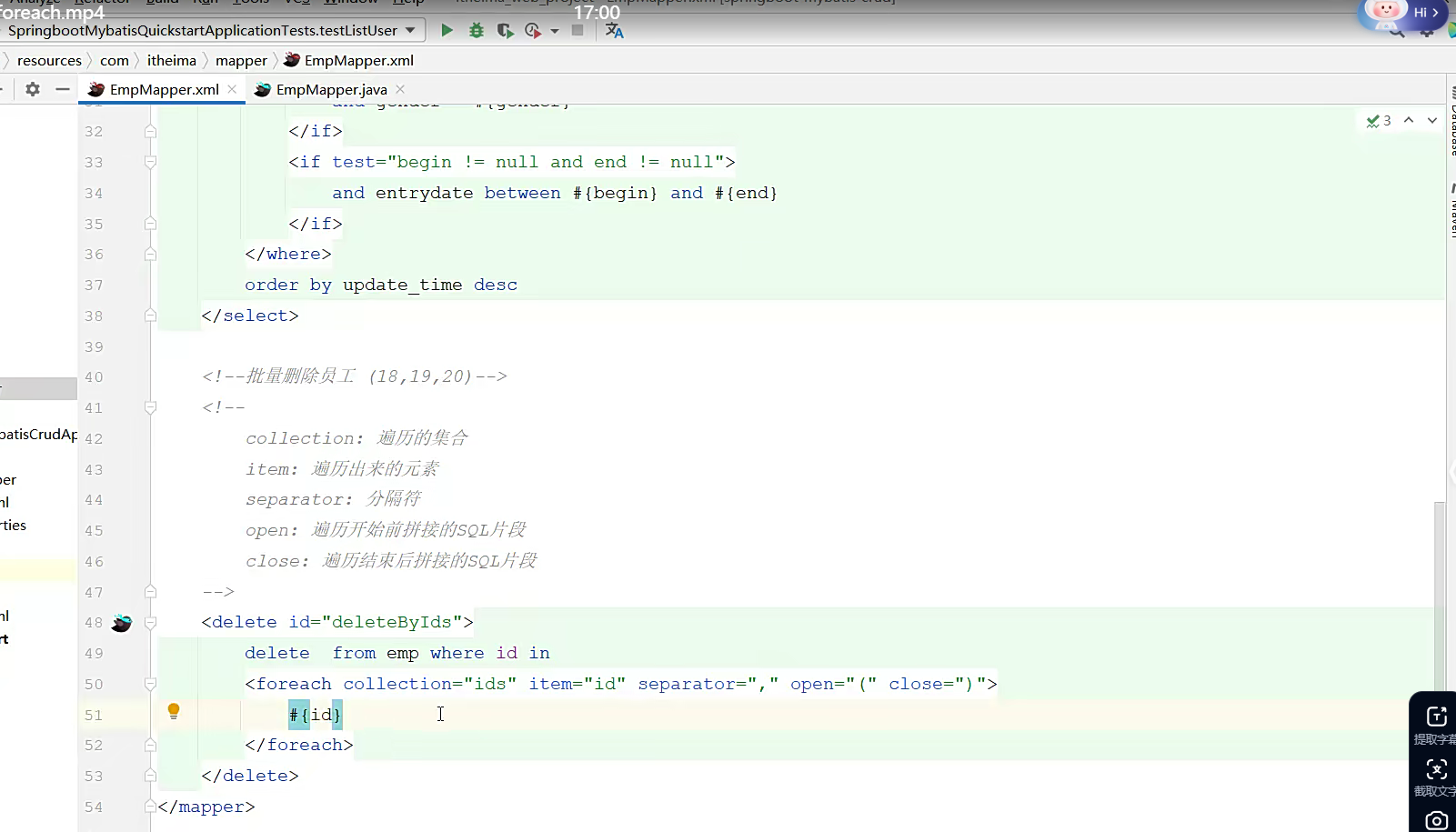
sql标签和include标签
这两个标签可以配套运用,sql标签里面吧,我直接把该封装的东西封装起来,就比如把一段长度很长的sql封装起来,然后下一次还能继续复用,这样的话,代码的复用性就很强了;可是还是要赋予人家唯一标识;用id给,随后我们在用的时候我们就许可直接去用Include标签去应用他,比如你现在要用到你封装好的哪一条sql,你sql不是设置了唯一的id吗,那你就可以在用的时候用该去找到你要用的sql, 用refid去绑定你sql的唯一标识。
用refid去绑定你sql的唯一标识。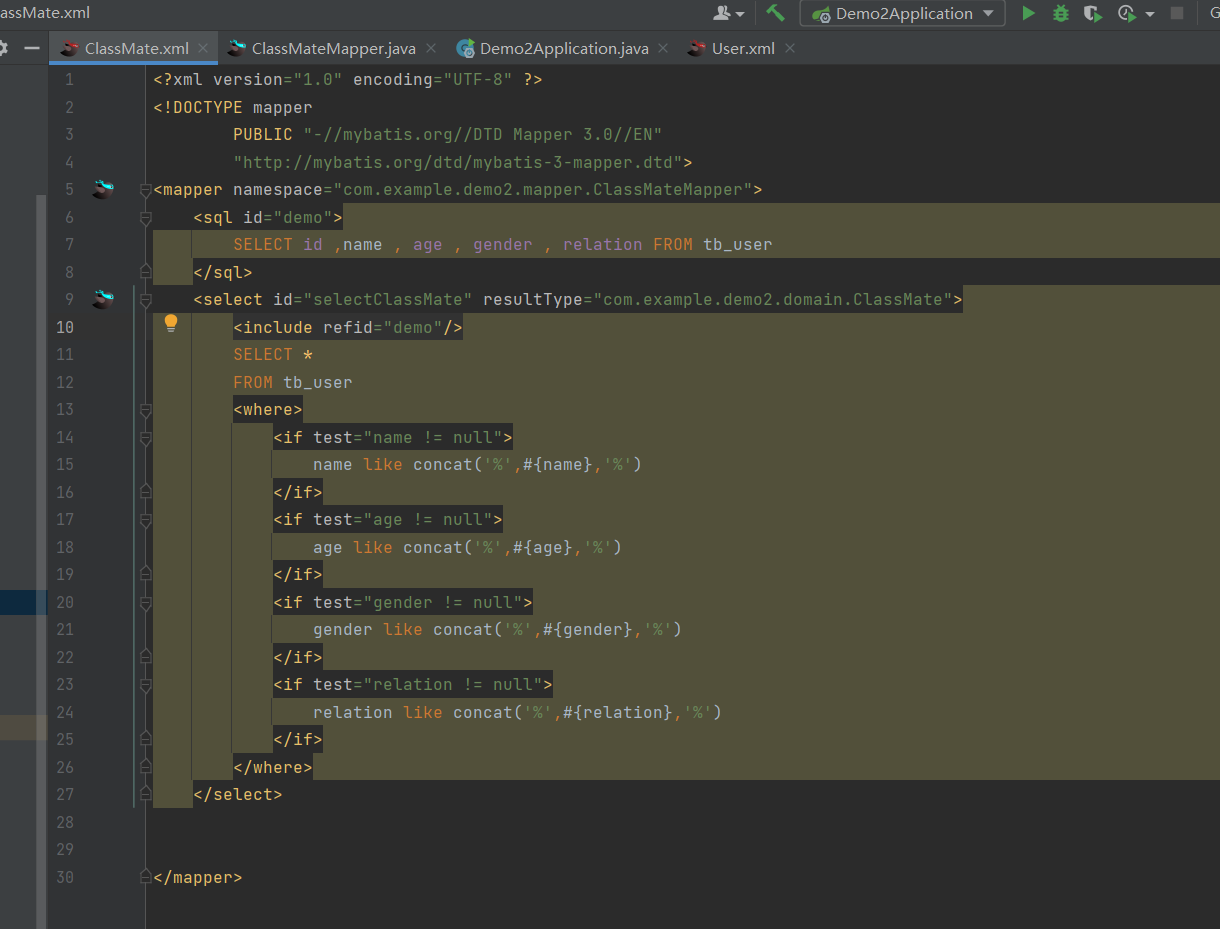
**大致逻辑如图所示,我直接在mapper里面定义sql的标签里面可以直接写好查询,这类似于把他封装成一个方法,想用的时候我在下面的select标签里面我直接复用就可以了,让他自闭和;**就许可达到使用效果了;
你写到了这个select标签里面你就许可用这个select标签里面定义好的东西去返回给你mapper接收的方法;你就不用去新写返回值啦就是一样的逻辑
小结

小结:
1.这就是起码xml文件里面的所有东西,一个xml文件所定义的规范,与接口名字必须一致,namespace必须和mapper层一致,
2.然后就是说select标签里面的id必须是返回的方法名字,再去定义resulttype和resultmap,type一般是确定就返回一条或者几条资料的,比较确定的类型,但是resultmap不确定返回类型是多少;定义结果的返回类型;
3.完了之后学到了这几个标签,比如if是条件判断,判断你是否满足这个条件,里面一般用测试类,比如 意思就是如果测试类等于名字不等于空值,意思就是有参数传给name,那我们就可以进行sql的拼接,我们直接去拼接预编译sql则可;比如里面就写; name like concat(‘%’,#{name},‘%’) 就是name去模糊匹配预编译字段。
一条就是4.concat函数,这里面是拼接字符串的,#{}这种是预编译sql,是直接去替代字符串的;其实正常情况下,比如年龄一般就是age=#{age} 再一个点,但是别忘了加and,就是两个if隔开的时候要加and,不然他拼接的可能
5.以上很多标签都是再where select标签内涵盖的,就是都是这样的里面的内容; set用于更新函数;foreach用于遍历循环,sql是与select同级的封装sql的语句,提高复用性的;最后就是,include是使用sql里面的语句的;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号