
详细介绍:python进程、线程、协程
简介
- 并发(Concurrency):多个任务交替执行(宏观上同时进行,微观上交替处理),适合 I/O 密集型任务(如网络请求、文件读写)。
- 并行(Parallelism):多个任务真正同时执行(需多核 CPU 支持),适合 CPU 密集型任务(如数据计算、图像处理)。
多线程(Threading)
线程是进程内的执行单元,共享进程内存空间,切换成本低。
特点
- 共享内存:线程间可直接共享变量(需注意同步问题)。
- GIL 限制:Python 的全局解释器锁(GIL)导致同一时刻只有一个线程执行 Python 字节码,多线程无法利用多核 CPU(对 CPU 密集型任务效率低)。
- 适用场景:I/O 密集型任务(如爬虫、网络服务)。
基本用法
import threading
import time
def task(name):
print(f"任务 {name
} 开始")
time.sleep(2) # 模拟 I/O 操作
print(f"任务 {name
} 结束")
# 创建线程
t1 = threading.Thread(target=task, args=("t1",))
t2 = threading.Thread(target=task, args=("t2",))
# 启动线程
t1.start()
t2.start()
# 等待线程结束
t1.join()
t2.join()
print("所有任务完成")线程同步
Lock:互斥锁,确保同一时间只有一个线程访问共享资源。
lock = threading.Lock()
count = 0
def increment():
global count
with lock: # 自动获取和释放锁
count += 1
# 多线程调用 increment() 不会出现计数错误多进程(Multiprocessing)
进程是独立的内存空间,由操作系统调度,可利用多核 CPU。
特点
- 独立内存:进程间不共享内存,通信需用特定机制(如队列、管道)。
- 无 GIL 限制:多进程可真正并行执行,充分利用多核 CPU。
- 适用场景:CPU 密集型任务(如数据分析、复杂计算)。
- 缺点:创建和切换成本高,内存占用大。
基本用法
import multiprocessing
import time
def task(name):
print(f"任务 {name
} 开始")
time.sleep(2) # 模拟计算
print(f"任务 {name
} 结束")
if __name__ == "__main__": # 多进程必须在 main 模块中启动
p1 = multiprocessing.Process(target=task, args=("p1",))
p2 = multiprocessing.Process(target=task, args=("p2",))
p1.start()
p2.start()
p1.join()
p2.join()
print("所有任务完成")进程通信
q = multiprocessing.Queue()
def producer():
q.put("数据")
def consumer():
data = q.get()
print(data)
# 启动生产者和消费者进程协程(Coroutine)
协程是轻量级线程(用户态线程),由程序主动控制切换,切换成本极低。
特点
- 单线程内执行:所有协程在一个线程内交替运行,无需线程切换开销。
- 主动切换:通过 await 关键字主动让出 CPU,适合 I/O 等待时切换。
- 适用场景:高并发 I/O 密集型任务(如异步 Web 框架、高并发爬虫)。
基本用法(Python 3.5+ async/await 语法)
import asyncio
import time
async def task(name):
print(f"任务 {name
} 开始")
await asyncio.sleep(2) # 模拟 I/O 操作(非阻塞)
print(f"任务 {name
} 结束")
async def main():
# 并发执行两个任务
await asyncio.gather(
task("c1"),
task("c2")
)
# 运行事件循环
asyncio.run(main())
print("所有任务完成")核心原理
- 事件循环(Event Loop):调度协程执行,当一个协程 await 时,事件循环切换到其他就绪协程。
- 非阻塞 I/O:协程的 I/O 操作(如网络请求)需使用异步库(如 aiohttp 而非 requests)。
线程池与进程池
频繁创建 / 销毁线程 / 进程会消耗资源,池化技术可复用资源,提高效率。
线程池(concurrent.futures.ThreadPoolExecutor)
from concurrent.futures import ThreadPoolExecutor
import time
def task(name):
print(f"任务 {name
} 开始")
time.sleep(2)
return f"任务 {name
} 结果"
# 创建线程池(最多 3 个线程)
with ThreadPoolExecutor(max_workers=3) as executor:
# 提交任务
futures = [executor.submit(task, f"t{i
}") for i in range(5)]
# 获取结果
for future in futures:
print(future.result())进程池(concurrent.futures.ProcessPoolExecutor)
from concurrent.futures import ProcessPoolExecutor
import time
def task(name):
print(f"任务 {name
} 开始")
time.sleep(2)
return f"任务 {name
} 结果"
if __name__ == "__main__":
# 创建进程池(最多 2 个进程)
with ProcessPoolExecutor(max_workers=2) as executor:
futures = [executor.submit(task, f"p{i
}") for i in range(4)]
for future in futures:
print(future.result())池的优势
- 减少创建 / 销毁线程 / 进程的开销。
- 控制并发数量,避免资源耗尽。
- 简化任务提交和结果获取流程。
选择
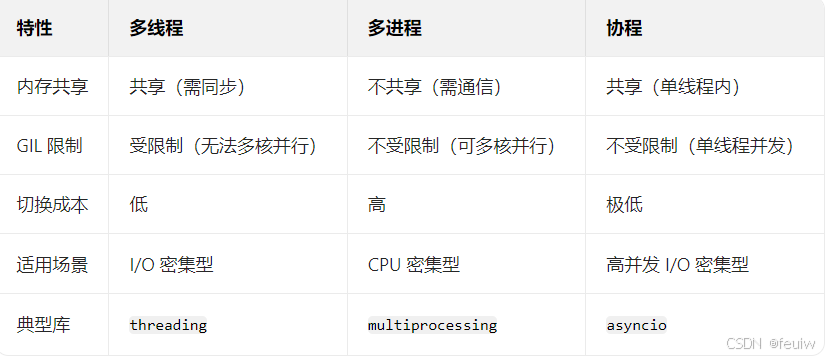
选择建议:
- I/O 密集型任务(如爬虫、API 调用):
- 优先用 协程(最高效,适合超大规模并发)。
- 其次用 线程池(实现简单,适合中等规模并发)。
- CPU 密集型任务(如数据计算):
- 必须用 进程池(利用多核 CPU,避免 GIL 限制)。
- 混合任务:
- 结合使用(如多进程 + 协程,进程利用多核,协程处理每个进程内的 I/O)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号