
详细介绍:【python深度学习】Day 45 Tensorboard使用介绍
知识点:
- tensorboard的发展历史和原理
- tensorboard的常见操作
- tensorboard在cifar上的实战:MLP和CNN模型
效果展示如下,很适合拿去组会汇报撑页数:
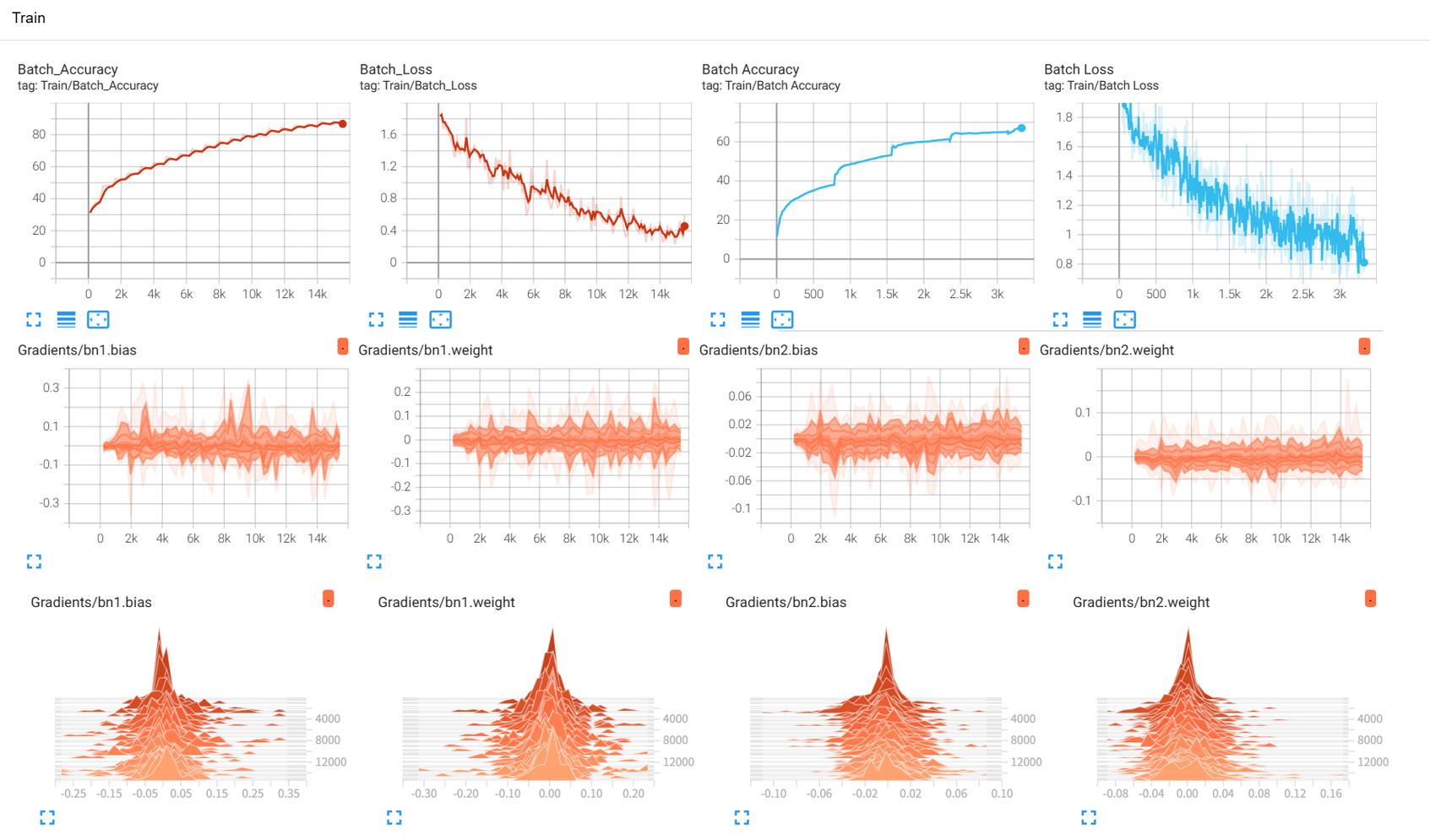
作业:对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。
PS:
- tensorboard和torch版本存在一定的不兼容性,如果报错请新建环境尝试。
- 类似于八股文,看多了就习惯了,难度远远小于考研数学等需要思考的内容就是tensorboard的代码还有有一定的记忆量,实际上深度学习的经典代码都
- 实际上对目前的 AI 而言,你只需要先完成最简便的demo,随后让他给你加上tensorboard需要打印的部分即可。——核心是弄懂tensorboard可以打印什么信息,以及如何看可视化后的结果,把ai当成记忆大师用到的时候通过它来调取对应的代码即可。
一、介绍
之前在神经网络训练中,为了帮助自己理解,借用了很多的组件,比如训练进度条、可视化的loss下降曲线、权重分布图,运行结束后还行查看单张图的推理效果。
tensorboard这个库,集成了以上所有可视化工具
二、代码实战
MLP
import torchimport torch.nn as nnimport torch.optim as optimimport torchvisionfrom torchvision import datasets, transformsfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterimport numpy as npimport matplotlib.pyplot as pltimport os # 设置随机种子以确保结果可复现torch.manual_seed(42)np.random.seed(42) # 1. 数据预处理transform = transforms.Compose([ transforms.ToTensor(), # 转换为张量 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理]) # 2. 加载CIFAR-10数据集train_dataset = datasets.CIFAR10( root='./data', train=True, download=True, transform=transform) test_dataset = datasets.CIFAR10( root='./data', train=False, transform=transform) # 3. 创建数据加载器batch_size = 64train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # CIFAR-10的类别名称classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # 4. 定义MLP模型(适应CIFAR-10的输入尺寸)class MLP(nn.Module): def __init__(self): super(MLP, self).__init__() self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量 self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元 self.relu1 = nn.ReLU() self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合 self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元 self.relu2 = nn.ReLU() self.dropout2 = nn.Dropout(0.2) self.layer3 = nn.Linear(256, 10) # 输出层:10个类别 def forward(self, x): # 第一步:将输入图像展平为一维向量 x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072] # 第一层全连接 + 激活 + Dropout x = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512] x = self.relu1(x) # 应用ReLU激活函数 x = self.dropout1(x) # 训练时随机丢弃部分神经元输出 # 第二层全连接 + 激活 + Dropout x = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256] x = self.relu2(x) # 应用ReLU激活函数 x = self.dropout2(x) # 训练时随机丢弃部分神经元输出 # 第三层(输出层)全连接 x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10] return x # 返回未经过Softmax的logits # 检查GPU是否可用device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 初始化模型model = MLP()model = model.to(device) # 将模型移至GPU(如果可用) criterion = nn.CrossEntropyLoss() # 交叉熵损失函数optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器 # 创建TensorBoard的SummaryWriter,指定日志保存目录log_dir = 'runs/cifar10_mlp_experiment'# 如果目录已存在,添加后缀避免覆盖if os.path.exists(log_dir): i = 1 while os.path.exists(f"{log_dir}_{i}"): i += 1 log_dir = f"{log_dir}_{i}"writer = SummaryWriter(log_dir) # 5. 训练模型(使用TensorBoard记录各种信息)def train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer): model.train() # 设置为训练模式 # 记录训练开始时间,用于计算训练速度 global_step = 0 # 可视化模型结构 dataiter = iter(train_loader) images, labels = next(dataiter) images = images.to(device) writer.add_graph(model, images) # 添加模型图 # 可视化原始图像样本 img_grid = torchvision.utils.make_grid(images[:8].cpu()) writer.add_image('原始训练图像', img_grid) for epoch in range(epochs): running_loss = 0.0 correct = 0 total = 0 for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) # 移至GPU optimizer.zero_grad() # 梯度清零 output = model(data) # 前向传播 loss = criterion(output, target) # 计算损失 loss.backward() # 反向传播 optimizer.step() # 更新参数 # 统计准确率和损失 running_loss += loss.item() _, predicted = output.max(1) total += target.size(0) correct += predicted.eq(target).sum().item() # 每100个批次记录一次信息到TensorBoard if (batch_idx + 1) % 100 == 0: batch_loss = loss.item() batch_acc = 100. * correct / total # 记录标量数据(损失、准确率) writer.add_scalar('Train/Batch_Loss', batch_loss, global_step) writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step) # 记录学习率 writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step) # 每500个批次记录一次直方图(权重和梯度) if (batch_idx + 1) % 500 == 0: for name, param in model.named_parameters(): writer.add_histogram(f'weights/{name}', param, global_step) if param.grad is not None: writer.add_histogram(f'grads/{name}', param.grad, global_step) print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} ' f'| 单Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}') global_step += 1 # 计算当前epoch的平均训练损失和准确率 epoch_train_loss = running_loss / len(train_loader) epoch_train_acc = 100. * correct / total # 记录每个epoch的训练损失和准确率 writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch) writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch) # 测试阶段 model.eval() # 设置为评估模式 test_loss = 0 correct_test = 0 total_test = 0 # 用于存储预测错误的样本 wrong_images = [] wrong_labels = [] wrong_preds = [] with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) test_loss += criterion(output, target).item() _, predicted = output.max(1) total_test += target.size(0) correct_test += predicted.eq(target).sum().item() # 收集预测错误的样本 wrong_mask = (predicted != target).cpu() if wrong_mask.sum() > 0: wrong_batch_images = data[wrong_mask].cpu() wrong_batch_labels = target[wrong_mask].cpu() wrong_batch_preds = predicted[wrong_mask].cpu() wrong_images.extend(wrong_batch_images) wrong_labels.extend(wrong_batch_labels) wrong_preds.extend(wrong_batch_preds) epoch_test_loss = test_loss / len(test_loader) epoch_test_acc = 100. * correct_test / total_test # 记录每个epoch的测试损失和准确率 writer.add_scalar('Test/Loss', epoch_test_loss, epoch) writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch) # 计算并记录训练速度(每秒处理的样本数) # 这里简化处理,假设每个epoch的时间相同 samples_per_epoch = len(train_loader.dataset) # 实际应用中应该使用time.time()来计算真实时间 print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%') # 可视化预测错误的样本(只在最后一个epoch进行) if epoch == epochs - 1 and len(wrong_images) > 0: # 最多显示8个错误样本 display_count = min(8, len(wrong_images)) wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count]) # 创建错误预测的标签文本 wrong_text = [] for i in range(display_count): true_label = classes[wrong_labels[i]] pred_label = classes[wrong_preds[i]] wrong_text.append(f'True: {true_label}, Pred: {pred_label}') writer.add_image('错误预测样本', wrong_img_grid) writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch) # 关闭TensorBoard写入器 writer.close() return epoch_test_acc # 返回最终测试准确率 # 6. 执行训练和测试epochs = 20 # 训练轮次print("开始训练模型...")print(f"TensorBoard日志保存在: {log_dir}")print("训练完成后,使用命令 `tensorboard --logdir=runs` 启动TensorBoard查看可视化结果") final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer)print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
 浙公网安备 33010602011771号
浙公网安备 33010602011771号