

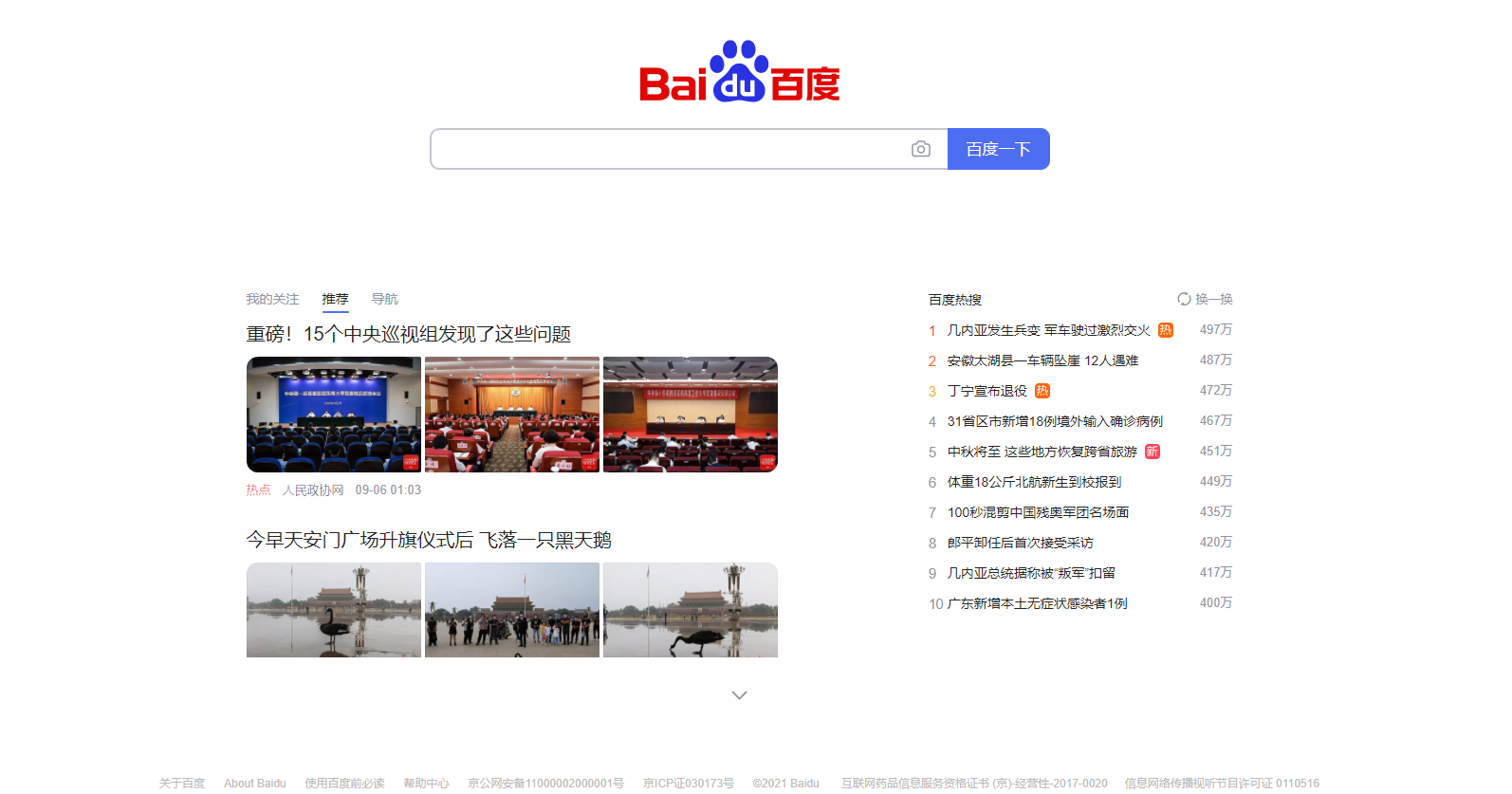
我们先看看要爬取的网页
要应用爬虫,就要用到它的一个包requests
import requests
首先我们要一个能够爬取的网站把它的地址装进变量里面
url = "https://www.baidu.com/"
拿到地址后就要对它发送请求发送后得到的东西应该把一个变量装起来
res = requests.get(url)
这样爬取后有可能会出现乱码的情况
这个时候就应该对字符编码进行修改
encoding:修改字符编码
apparent_encoding:获取字符编码
#这串代码能解决大部分字符编码的问题
res.encoding = res.apparent_encoding
然后就是打印了
完整代码
import requests url = "https://www.baidu.com/"
res = requests.get(url) res.encoding = res.apparent_encoding print(res.text)
这样的话我们爬取的网页就有可能出现问题
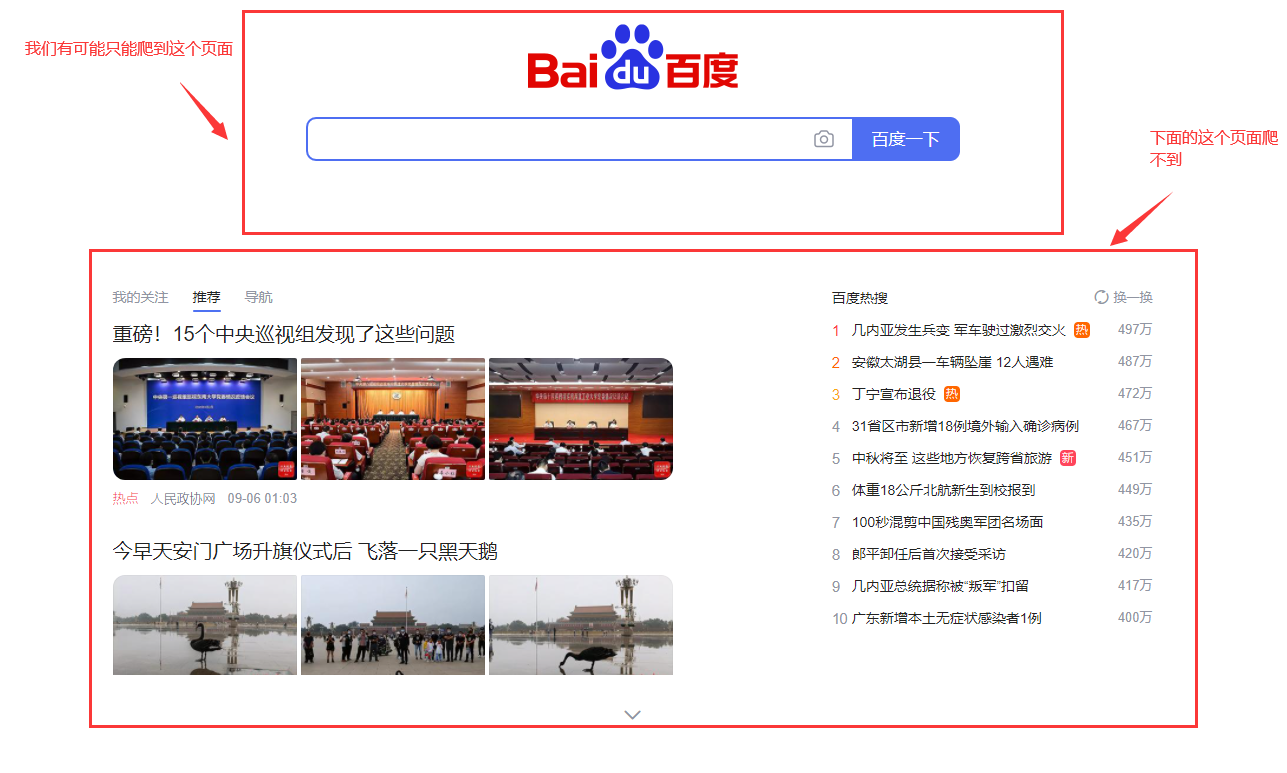
这说明我们被反爬了想要我们改一下我们的请求头
header
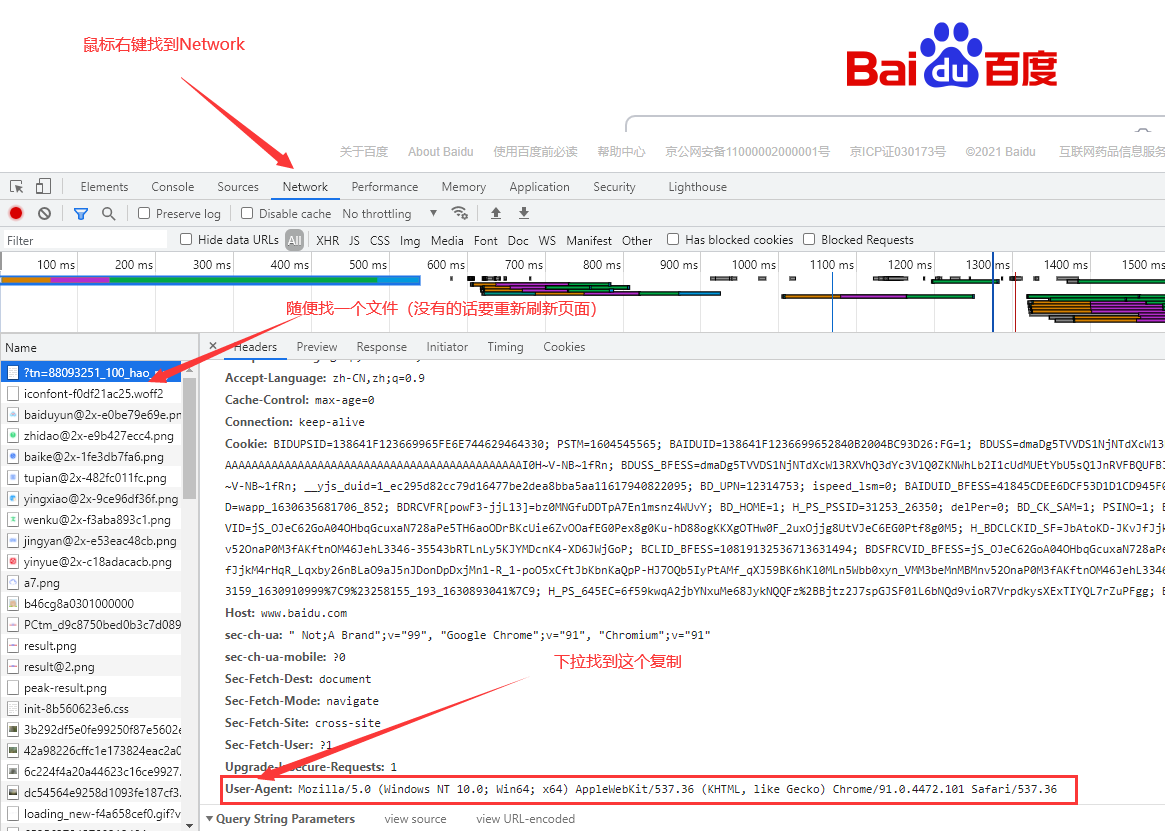
#我们先创建一个字典 #将刚刚复制的粘贴进来记住加引号 header={ "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36" } #在将他放进get请求里
#这里header=header第一个是它get请求自带的第二个是我们的字典将我们的字典传进系统自带的参数里
res = requests.get(url,header=header)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号