

7万网站用户行为大数据分析
7万网站用户行为大数据分析
数据分析师,是通过数据对业务团队决策、公司管理层的决策进行“指点江山”。在实际工作内容是做数据分析报告;构建机器学习模型;打造数据产品,非常有“技术含量”。
数据分析师的工作日常是进行各种数据分析,告诉业务小伙伴,根据你的目的,你应该设计什么样的活动,投入什么样的资源,针对什么样的用户群。
收集数据发现活动效果很好,一定是平时活动效果的N倍。然后继续下一次迭代。
然而,万里之行始于足下。
数据分析常被提及两个问题
- 1 如何将新用户、回流用户、活跃用户、不活跃用户进行分层。
- 2 如何求回购率、复购率
你知道该如何回答么?你有更好的答案么?你能验证你的答案么?
让我们一起开始大数据分析之旅吧
一:查看数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
columns = ['user_id','order_dt','order_products','order_amount']
df = pd.read_table("E:/yizhiamumu/yizhiamumu.txt",names = columns,sep = '\s+')
df.head()
打印结果:
user_id order_dt order_products order_amount
0 1 19970101 1 11.77
1 2 19970112 1 12.00
2 2 19970112 5 77.00
3 3 19970102 2 20.76
4 3 19970330 2 20.76
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 69659 entries, 0 to 69658
Data columns (total 4 columns):
user_id 69659 non-null int64
order_dt 69659 non-null int64
order_products 69659 non-null int64
order_amount 69659 non-null float64
dtypes: float64(1), int64(3)
memory usage: 2.1 MB# 数据类型的转化
df['order_dt'] = pd.to_datetime(df.order_dt,format = '%Y%m%d')
df['month'] = df.order_dt.values.astype('datetime64[M]')
df.describe()
user_id order_products order_amount
count 69659.000000 69659.000000 69659.000000
mean 11470.854592 2.410040 35.893648
std 6819.904848 2.333924 36.281942
min 1.000000 1.000000 0.000000
25% 5506.000000 1.000000 14.490000
50% 11410.000000 2.000000 25.980000
75% 17273.000000 3.000000 43.700000
max 23570.000000 99.000000 1286.010000
# 喵喵数据:
# 用户平均每笔订单的购买数是2.4,中位数为2,数据右偏;
# 75分位数在3个商品,说明绝大部分订单的购买量都不多;
# 购买数量最大值达到了99,说明数据存在一定的极值干扰;
# 用户每笔订单平均消费35.89元,中位数25.98元,消费最大金额达到了1286元。
# 消费类订单数据很可能存在二八数据分布
二:大数据分析
1 每月消费情况概览
# 按月
# 1 每月消费频次
df.index = pd.to_datetime(df.order_dt)
month_grouped = df.resample('m').agg({'user_id':'count',
'order_products':'sum',
'order_amount':'sum'})
month_grouped['user_sum'] = df.resample('m')['user_id'].nunique()
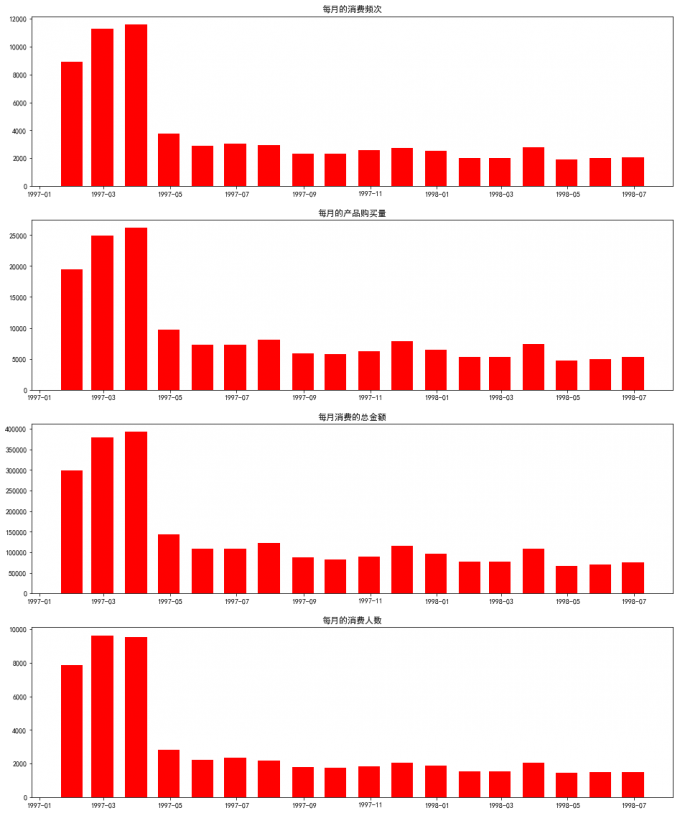
month_grouped.head().style.background_gradient(subset=['order_products','order_amount'],cmap = 'BuGn').highlight_max(color='red')
user_id order_products order_amount user_sum
order_dt
1997-01-31 00:00:00 8928 19416 299060 7846
1997-02-28 00:00:00 11272 24921 379590 9633
1997-03-31 00:00:00 11598 26159 393155 9524
1997-04-30 00:00:00 3781 9729 142824 2822
1997-05-31 00:00:00 2895 7275 107933 2214
import pylab
pylab.rcParams['figure.figsize']=(16,20)
fig,axes = plt.subplots(4,1)
axes0,axes1,axes2,axes3 = axes.flatten()
axes0.bar(month_grouped.index,month_grouped.user_id,width=20,color='red')
axes0.set_title('每月的消费频次')
axes1.bar(month_grouped.index,month_grouped.order_products,width=20,color='red')
axes1.set_title('每月的产品购买量')
axes2.bar(month_grouped.index,month_grouped.order_amount,width=20,color='red')
axes2.set_title('每月消费的总金额')
axes3.bar(month_grouped.index,month_grouped.user_sum,width=20,color='red')
axes3.set_title('每月的消费人数')
# 去重user_id
df.drop_duplicates('user_id')['user_id'].resample('m').count()
order_dt
1997-01-31 7846
1997-02-28 8476
1997-03-31 7248
Freq: M, Name: user_id, dtype: int64# 喵喵数据:
# 用户粘性不足:前三个月每月的消费人数在8000-10000之间,后续月份平均消费人数在2000人不到,说明用户的粘性不足;
# 长期消费平稳:消费人群集中在前三月,4月开始,订单量、产品购买量、购买金额、消费用户数量基本处于平稳;
# 用户回购消费:新用户的购买行为主要集中在前三月,后面的消费主要是由前三月用户的回购行为产生。
2 每月用户平均消费金额分析
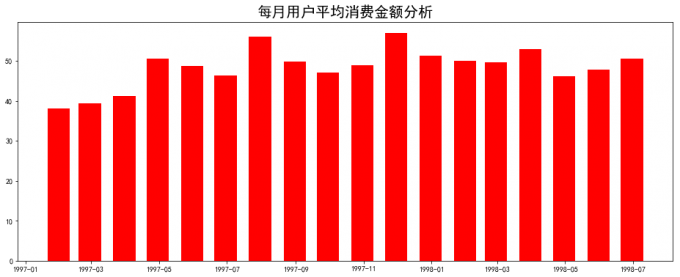
# 2 每月用户平均消费金额分析
pylab.rcParams['figure.figsize']=(16,6)
user_avgamount = month_grouped['order_amount']/month_grouped['user_sum']
plt.title('每月用户平均消费金额',size=20)
plt.bar(user_avgamount.index,user_avgamount,width=20,color='red')
# 喵喵数据:
# 用户每月消费金额平稳:用户每月的平均消费水平比较稳定,主要集中在38-60之间。
3 每月用户平均消费次数分析
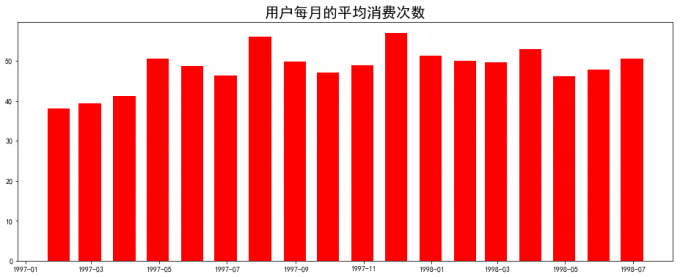
# 3 每月用户平均消费次数分析
user_avgorder = month_grouped['order_products']/month_grouped['user_sum']
plt.bar(user_avgorder.index,user_avgamount,width=20,color='red')
plt.title('每月用户平均消费次数',size=20)
# 喵喵数据:
# 用户每月消费次数平稳:用户每月的平均消费次数也较为平稳,基本集中在2.5-3.5之间。
# 用户消费金额、消费次数
user_grouped = df.groupby('user_id').agg({'user_id':'count',
'order_products':'sum',
'order_amount':'sum'})
user_grouped.describe()
# 喵喵数据:
# 一次消费用户多:用户平均消费次数是2.95次,四分位数和中位数的值均为1,说明大部分用户只一次消费,直方图右偏;
# 消费主要来自老用户:商品购买量和购买金额的平均值均等于其3/4分位数,说明少量的用户购买了大量的产品,直方图右偏。
| user_id | order_products | order_amount | |
|---|---|---|---|
| count | 23570.000000 | 23570.000000 | 23570.000000 |
| mean | 2.955409 | 7.122656 | 106.080426 |
| std | 4.736558 | 16.983531 | 240.925195 |
| min | 1.000000 | 1.000000 | 0.000000 |
| 25% | 1.000000 | 1.000000 | 19.970000 |
| 50% | 1.000000 | 3.000000 | 43.395000 |
| 75% | 3.000000 | 7.000000 | 106.475000 |
| max | 217.000000 | 1033.000000 | 13990.930000 |
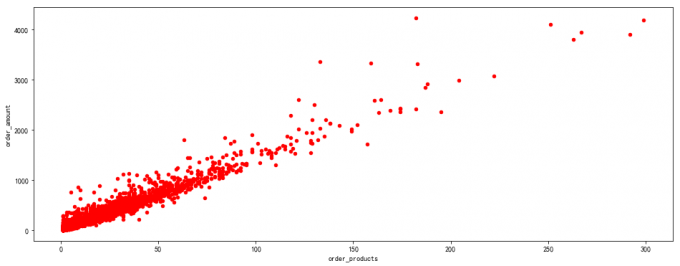
4 用户消费金额和消费次数的散点图
# 4 用户消费金额和消费次数的散点图
user_grouped.plot.scatter(x='order_products',y='order_amount', color='red')
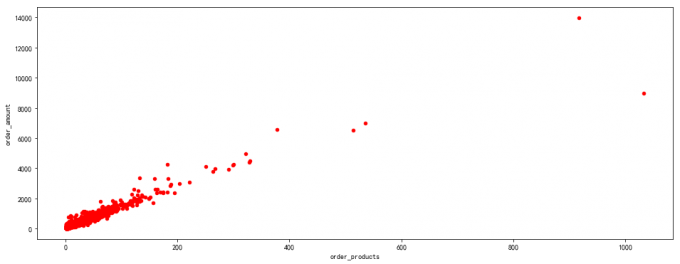
# query 过滤极值
user_grouped.query('order_products<300').plot.scatter(x='order_products',y='order_amount',color='red')
# 喵喵数据:
# 产品服务单一:订单总数和消费金额承明显的线性关系,说明产品单一,价格也稳定。
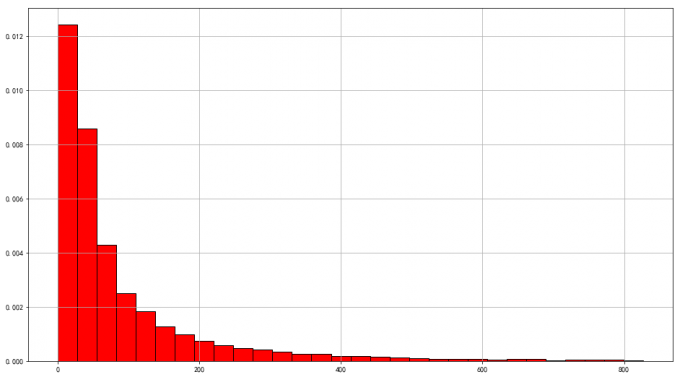
5用户消费金额的分布图
# 5用户消费金额的分布图:
pylab.rcParams['figure.figsize']=(16,9)
user_grouped['order_amount'].hist(bins=30,density=1,edgecolor='black',color='red')
# 喵喵数据:
# 存在干扰数据:大部分购买金额集中在0-2000左右,存在极值影响数据分布。
# 用户的消费金额在829的范围内:根据切比雪夫定理,距离平均值有三个标准差的值均为异常值,用户的消费金额应该在106+241*3=829的范围内

user_grouped.query('order_amount<829')['order_amount'].hist(bins=30,density=1,edgecolor='black',color='red')
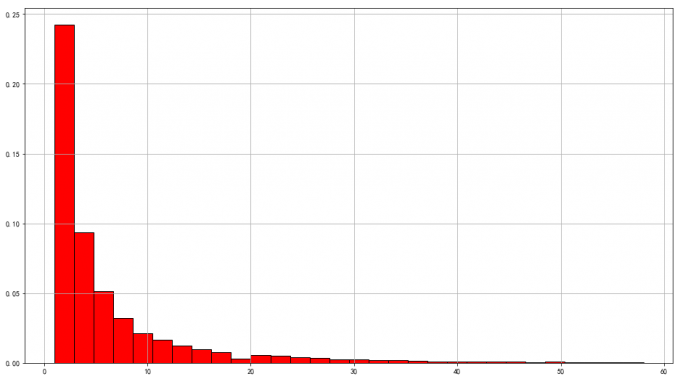
6 用户产品购买量分析
# 6 用户产品购买量分析
# query 过滤极值数据
user_grouped.query('order_products<58.12')['order_products'].hist(bins=30,density=1,edgecolor='black',color='red')
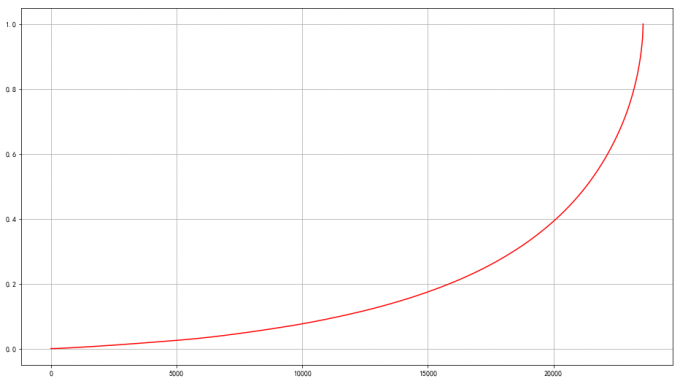
7 用户累计消费金额占比
# 7 用户累计消费金额占比
user_cumsum = user_grouped.sort_values('order_amount').apply(lambda x : x.cumsum()/x.sum())
user_cumsum.reset_index(drop=True).order_amount.plot(color='red')
plt.grid()
# 喵喵数据:
# 验证消费数据二八分布:
# 按用户消费金额进行升序排列,65%的用户仅贡献了20% 的消费额度,
# 消费金额排名前20%的用户贡献了超过60%的消费额度。
8 用户留存分析
# 8 用户留存分析-新、活跃、回流、消失
pivoted_counts=df.pivot_table(index = "user_id",
columns = "month",
values = "order_dt",
aggfunc = "count").fillna(0)
pivoted_counts.head()
month 1997-01-01 00:00:00 1997-02-01 00:00:00 1997-03-01 00:00:00 1997-04-01 00:00:00 1997-05-01 00:00:00 1997-06-01 00:00:00 1997-07-01 00:00:00 1997-08-01 00:00:00 1997-09-01 00:00:00 1997-10-01 00:00:00 1997-11-01 00:00:00 1997-12-01 00:00:00 1998-01-01 00:00:00 1998-02-01 00:00:00 1998-03-01 00:00:00 1998-04-01 00:00:00 1998-05-01 00:00:00 1998-06-01 00:00:00
user_id
1 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2 2.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
3 1.0 0.0 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 2.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0
4 2.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0
5 2.0 1.0 0.0 1.0 1.0 1.0 1.0 0.0 1.0 0.0 0.0 2.0 1.0 0.0 0.0 0.0 0.0 0.0
#简化模型,只需判断是否存在 即 1与0
df_purchase = pivoted_counts.applymap(lambda x: 1 if x>0 else 0)
#判断尾部数据 是从 3月份才开始第一次购买
df_purchase.tail ()
month 1997-01-01 00:00:00 1997-02-01 00:00:00 1997-03-01 00:00:00 1997-04-01 00:00:00 1997-05-01 00:00:00 1997-06-01 00:00:00 1997-07-01 00:00:00 1997-08-01 00:00:00 1997-09-01 00:00:00 1997-10-01 00:00:00 1997-11-01 00:00:00 1997-12-01 00:00:00 1998-01-01 00:00:00 1998-02-01 00:00:00 1998-03-01 00:00:00 1998-04-01 00:00:00 1998-05-01 00:00:00 1998-06-01 00:00:00
user_id
23566 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
23567 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
23568 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
23569 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
23570 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# 用户状态分类
# 将用户状态分为unreg(未注册)、new(新客)、active(活跃用户)return(回流用户)和unactive(不活跃用户)
def active_status(data):
status = []
for i in range(18): #12+6个月
#若本月没有消费
if data[i] == 0:
if len(status) > 0: #判断 存在记录的话时
if status[i-1] == "unreg": #unreg 未注册
status.append("unreg")
else:
status.append("unactive") # 如果前一个为 unreg 未注册,则后一个应判断为不活跃
else:
status.append("unreg") #不存在记录时,加入 unreg
#若本月消费
else:
if len(status) == 0:
status.append("new")
else:
if status[i-1] == "unactive" :
status.append("return") #回流
elif status[i-1] == "unreg" :
status.append("new")
else:
status.append("active")
return status
indexs=df['month'].sort_values().astype('str').unique()
purchase_stats = df_purchase.apply(lambda x:pd.Series(active_status(x),index=indexs),axis=1)
purchase_stats.head(5)
1997-01-01 1997-02-01 1997-03-01 1997-04-01 1997-05-01 1997-06-01 1997-07-01 1997-08-01 1997-09-01 1997-10-01 1997-11-01 1997-12-01 1998-01-01 1998-02-01 1998-03-01 1998-04-01 1998-05-01 1998-06-01
user_id
1 new unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive
2 new unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive
3 new unactive return active unactive unactive unactive unactive unactive unactive return unactive unactive unactive unactive unactive return unactive
4 new unactive unactive unactive unactive unactive unactive return unactive unactive unactive return unactive unactive unactive unactive unactive unactive
5 new active unactive return active active active unactive return unactive unactive return active unactive unactive unactive unactive unactive
purchase_stats.tail(5)
1997-01-01 1997-02-01 1997-03-01 1997-04-01 1997-05-01 1997-06-01 1997-07-01 1997-08-01 1997-09-01 1997-10-01 1997-11-01 1997-12-01 1998-01-01 1998-02-01 1998-03-01 1998-04-01 1998-05-01 1998-06-01
user_id
23566 unreg unreg new unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive
23567 unreg unreg new unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive
23568 unreg unreg new active unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive
23569 unreg unreg new unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive
23570 unreg unreg new unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive unactive
purchase_stats_ct = purchase_stats.apply(lambda x:pd.value_counts(x))
purchase_stats_ct
1997-01-01 1997-02-01 1997-03-01 1997-04-01 1997-05-01 1997-06-01 1997-07-01 1997-08-01 1997-09-01 1997-10-01 1997-11-01 1997-12-01 1998-01-01 1998-02-01 1998-03-01 1998-04-01 1998-05-01 1998-06-01
active NaN 1157.0 1681.0 1773.0 852.0 747.0 746.0 604.0 528.0 532.0 624.0 632.0 512.0 472.0 571.0 518.0 459.0 446.0
new 7846.0 8476.0 7248.0 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
return NaN NaN 595.0 1049.0 1362.0 1592.0 1434.0 1168.0 1211.0 1307.0 1404.0 1232.0 1025.0 1079.0 1489.0 919.0 1029.0 1060.0
unactive NaN 6689.0 14046.0 20748.0 21356.0 21231.0 21390.0 21798.0 21831.0 21731.0 21542.0 21706.0 22033.0 22019.0 21510.0 22133.0 22082.0 22064.0
unreg 15724.0 7248.0 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
# 转置
purchase_stats_ct.fillna(0).T.head() #fillna将空值填充为0, .T转置
active new return unactive unreg
1997-01-01 0.0 7846.0 0.0 0.0 15724.0
1997-02-01 1157.0 8476.0 0.0 6689.0 7248.0
1997-03-01 1681.0 7248.0 595.0 14046.0 0.0
1997-04-01 1773.0 0.0 1049.0 20748.0 0.0
1997-05-01 852.0 0.0 1362.0 21356.0 0.0
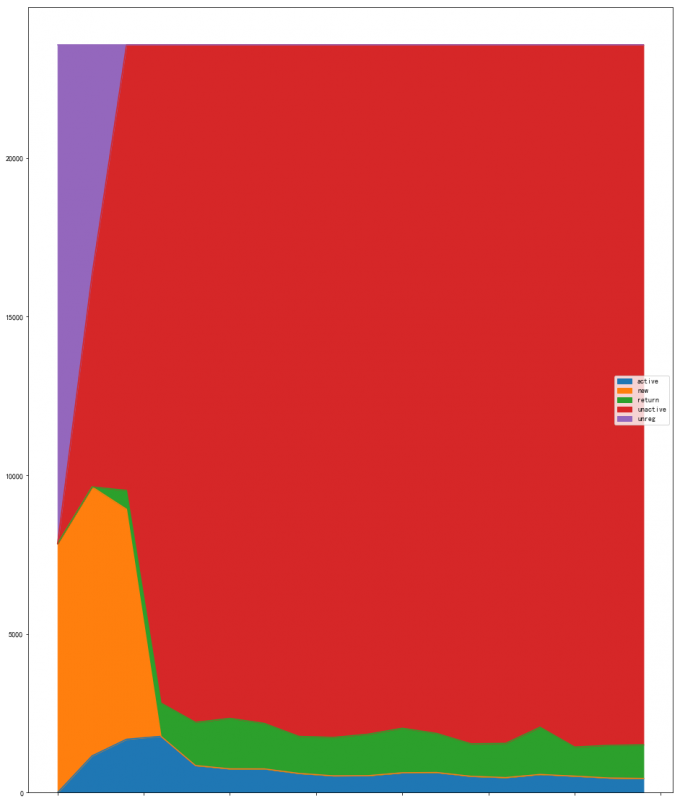
#.plot.area()面积图
purchase_stats_ct.fillna(0).T.plot.area()
# unreg(未注册)、new(新客)、active(活跃用户)return(回流用户)和unactive(不活跃用户)
# 喵喵数据:
# 活跃用户是持续消费的用户,对应的是消费运营的质量;
# 回流用户,之前不消费,本月才消费,对应的是唤回运营;
# 不活跃用户,对应的是流失
# 前三月份用户人数不断增高,新增用户数量和活跃用户数量都占较大比例,
# 后续无新用户注册,活跃用户数量下降最后趋于稳定水平,同时也有稳定的回流用户。
9 复购率分布图
# 9 复购率
# 复购率:自然月内,购买多次的用户占比
pivoted_count = df.pivot_table(index = 'user_id',
columns='month',
values = 'order_products',
aggfunc={'order_products':'count'})
pivoted_count = pivoted_count.fillna(0)
#清洗数据,消费超过两次为1,消费过1次为0,没有消费为nan
df_purchase = pivoted_count.applymap(lambda x:1 if x>1 else np.nan if x==0 else 0)
df_purchase.head()
month 1997-01-01 00:00:00 1997-02-01 00:00:00 1997-03-01 00:00:00 1997-04-01 00:00:00 1997-05-01 00:00:00 1997-06-01 00:00:00 1997-07-01 00:00:00 1997-08-01 00:00:00 1997-09-01 00:00:00 1997-10-01 00:00:00 1997-11-01 00:00:00 1997-12-01 00:00:00 1998-01-01 00:00:00 1998-02-01 00:00:00 1998-03-01 00:00:00 1998-04-01 00:00:00 1998-05-01 00:00:00 1998-06-01 00:00:00
user_id
1 0.0 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
2 1.0 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
3 0.0 NaN 0.0 0.0 NaN NaN NaN NaN NaN NaN 1.0 NaN NaN NaN NaN NaN 0.0 NaN
4 1.0 NaN NaN NaN NaN NaN NaN 0.0 NaN NaN NaN 0.0 NaN NaN NaN NaN NaN NaN
5 1.0 0.0 NaN 0.0 0.0 0.0 0.0 NaN 0.0 NaN NaN 1.0 0.0 NaN NaN NaN NaN NaN
# 复购率分布图
df_purchase.apply(lambda x:x.sum()/x.count()).plot.bar(linestyle=':',alpha=0.6, rot=45,title="复购率分布图")
# 喵喵数据:
# 长期数据平稳:购率基本上稳定在20%左右,
# 前三个月因为有大量新用户涌入,且大部分只购买了一次,导致复购率偏低。
# 后续月份用户消费次数大于两次的占比稳定在20%上下。
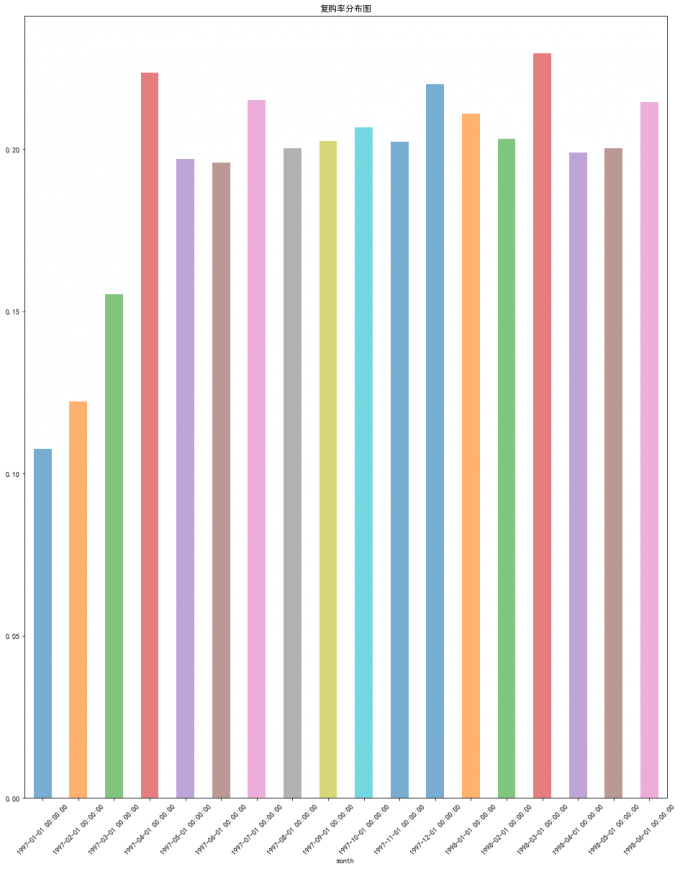
10 回购率分布图
# 10 回购率
# 计算用户的回购率主要以本月与上月的进行对比,假如上月进行过消费,本月再次消费了,说明该用户是回购用户。
df_purchase_back = pivoted_count.applymap(lambda x:1 if x>0 else np.nan)
df_purchase_back.head()
month 1997-01-01 00:00:00 1997-02-01 00:00:00 1997-03-01 00:00:00 1997-04-01 00:00:00 1997-05-01 00:00:00 1997-06-01 00:00:00 1997-07-01 00:00:00 1997-08-01 00:00:00 1997-09-01 00:00:00 1997-10-01 00:00:00 1997-11-01 00:00:00 1997-12-01 00:00:00 1998-01-01 00:00:00 1998-02-01 00:00:00 1998-03-01 00:00:00 1998-04-01 00:00:00 1998-05-01 00:00:00 1998-06-01 00:00:00
user_id
1 1.0 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
2 1.0 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
3 1.0 NaN 1.0 1.0 NaN NaN NaN NaN NaN NaN 1.0 NaN NaN NaN NaN NaN 1.0 NaN
4 1.0 NaN NaN NaN NaN NaN NaN 1.0 NaN NaN NaN 1.0 NaN NaN NaN NaN NaN NaN
5 1.0 1.0 NaN 1.0 1.0 1.0 1.0 NaN 1.0 NaN NaN 1.0 1.0 NaN NaN NaN NaN NaN
def purchase_back(data):
lenth = len(data)
state = []
for i in range(0,lenth-1):
if data[i] == 1:
if data[i+1]==1:
state.append(1) #若本月已消费,下个月也消费置1
else:
state.append(0) #本月已消费,下月未消费置0
else:
state.append(np.nan) #本月未消费置np.nan
state.append(np.nan)
return state
indexs=df['month'].sort_values().astype('str').unique()
df_purchase_b = df_purchase.apply(lambda x :pd.Series(purchase_back(x),index = indexs),axis =1)
df_purchase_b.head()
1997-01-01 1997-02-01 1997-03-01 1997-04-01 1997-05-01 1997-06-01 1997-07-01 1997-08-01 1997-09-01 1997-10-01 1997-11-01 1997-12-01 1998-01-01 1998-02-01 1998-03-01 1998-04-01 1998-05-01 1998-06-01
user_id
1 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
2 0.0 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
3 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 0.0 NaN NaN NaN NaN NaN NaN NaN
4 0.0 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
5 0.0 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 0.0 NaN NaN NaN NaN NaN NaN
# 回购率分布图
df_purchase_b.apply(lambda x:x.sum()/x.count()).plot.bar(linestyle=':',alpha=0.6, rot=45,title="回购率分布图")
# 喵喵数据:
# 末月不存在回购行为,因此其回购率为0;
# 前三个月由于有大量新用户涌入,大部分人只消费过一次,所以两个月回购率偏低;
# 第四个月回购率回升,最后稳定在35%左右,即当月消费人数中有30%左右的用户会在下一个月再次消费。
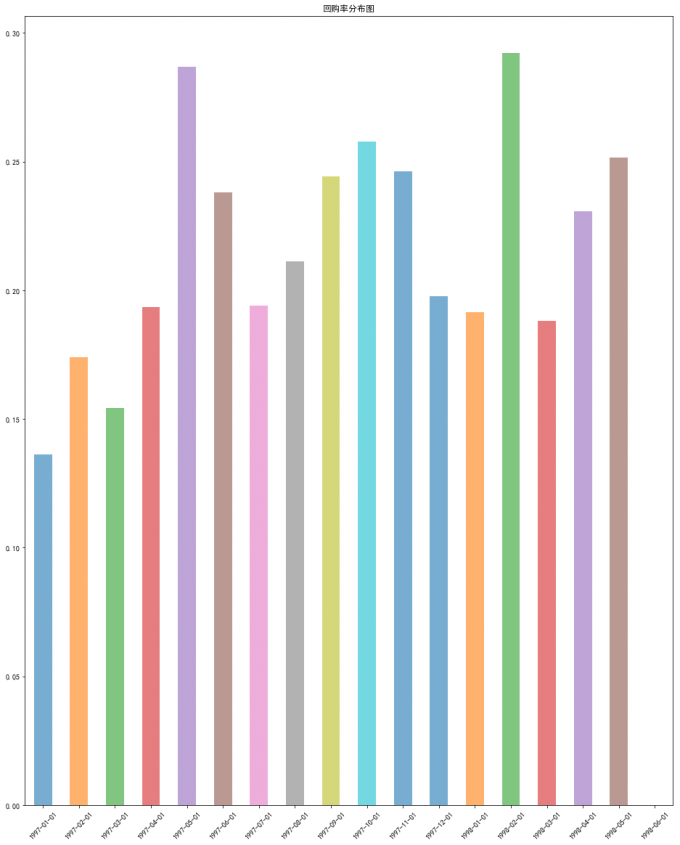
11 用户第一次消费
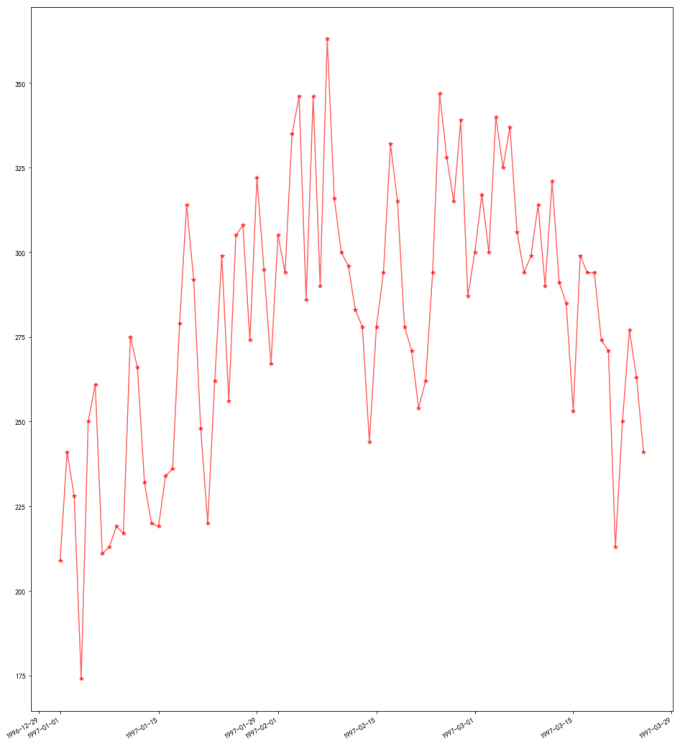
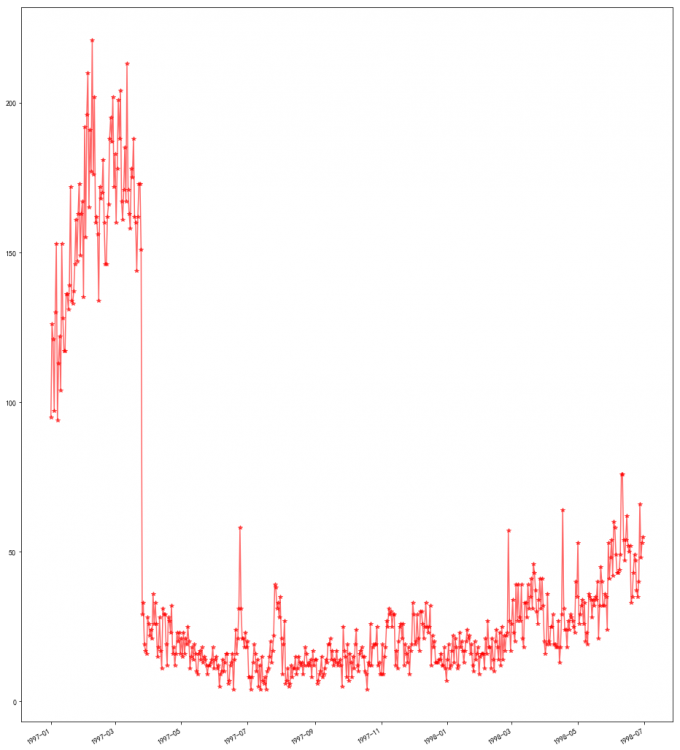
# 11 用户第一次消费
df.groupby('user_id')['order_dt'].min().value_counts().plot(color='red', alpha=0.6,marker='*')
# 喵喵数据:
# 用户消费的首因效应吗:所有用户的第一次消费都集中在前三个月
12用户最后一次消费
# 12用户最后一次消费
df.groupby('user_id')['order_dt'].max().value_counts().plot(color='red', alpha=0.6,marker='*')
# 喵喵数据:
# 一次消费用户多:用户最后一次消费比第一次消费分布广,说明很多用户在前三月进行一次购买后不再回购;
# 用户忠诚度下降:随着时间的增长,最后一次购买数也在递增,呈现流失上升的情况,用户忠诚度在慢慢下降
13 新老用户消费比
# 13 新老用户消费比
user_dt = df.groupby('user_id').order_dt.agg(['min','max'])
pylab.rcParams['figure.figsize']=(8,8)
rate = (user_dt['min'] == user_dt['max']).value_counts()
labels = ['新用户','老用户']
patches,l_text,p_text = plt.pie(rate,labels=labels,
explode=(0,0.15),
autopct='%2.1f%%',
startangle=90,
)
for t in l_text: #调整标签字体大小
t.set_size(15)
for t in p_text: #调整百分数字体大小
t.set_size(15)
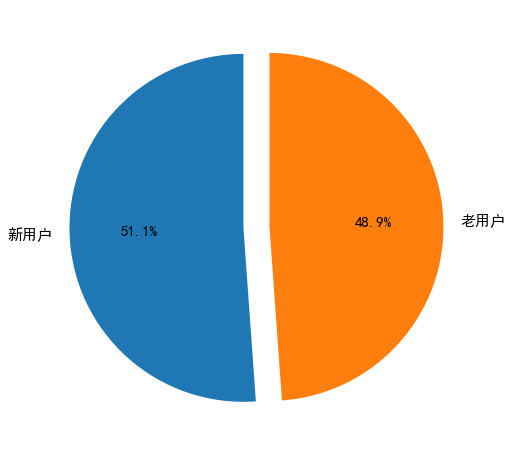
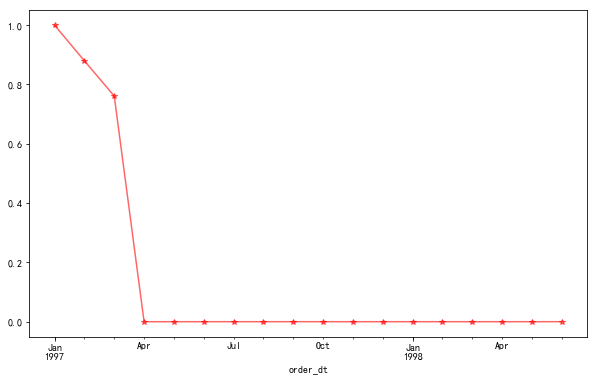
14 新用户占比
# 14 新用户占比
pylab.rcParams['figure.figsize']=(10,6)
user_new = df.drop_duplicates('user_id')['user_id'].resample('m').count()#计算每月首次购买产品的用户数
user_sum = df.resample('m')['user_id'].nunique()#计算每月购买产品的用户总数
(user_new/user_sum).fillna(0).plot(color='red', alpha=0.6,marker='*')
# 喵喵数据:
# 用心维护老用户:新客消费主要集中在前三月,后面消费群体全部为老用户。为了kpi,要用心维护老用户
15 RFM 用户分层
# 15 RFM 用户分层
df['period']=(df.order_dt - df.order_dt.max())/np.timedelta64(1,'D')
df.head()
user_id order_dt order_products order_amount month period
order_dt
1997-01-01 1 1997-01-01 1 11.77 1997-01-01 -545.0
1997-01-12 2 1997-01-12 1 12.00 1997-01-01 -534.0
1997-01-12 2 1997-01-12 5 77.00 1997-01-01 -534.0
1997-01-02 3 1997-01-02 2 20.76 1997-01-01 -544.0
1997-03-30 3 1997-03-30 2 20.76 1997-03-01 -457.0
user_rfm = df.pivot_table(values=['period','order_products','order_amount'],
index='user_id',aggfunc={'period':'max',
'order_products':'count',
'order_amount':'sum' })
user_rfm = user_rfm.rename(columns = {'order_amount':'M','order_products':'F','period':'R'})
user_rfm.head()
| M | F | R | |
|---|---|---|---|
| user_id | |||
| 1 | 11.77 | 1 | -545.0 |
| 2 | 89.00 | 2 | -534.0 |
| 3 | 156.46 | 6 | -33.0 |
| 4 | 100.50 | 4 | -200.0 |
| 5 | 385.61 | 11 | -178.0 |
#定义RFM 分层函数
def level_label(data):
level = data.apply(lambda x :'1' if x>=0 else '0')
label = level['R']+level['F']+level['M']
d = {
'111':"高价值客户",
'011':"重点保持客户",
'101':"重点发展客户",
'001':"重点挽留客户",
'110':"一般价值客户",
'010':"一般保持客户",
'100':"一般发展客户",
'000':"潜在客户"
}
result = d[label]
return result
user_rfm['label'] = (user_rfm - user_rfm.mean()).apply(level_label,axis=1)
label_count = user_rfm.groupby('label').count()
label_count
| M | F | R | |
|---|---|---|---|
| label | |||
| 一般价值客户 | 1974 | 1974 | 1974 |
| 一般保持客户 | 543 | 543 | 543 |
| 一般发展客户 | 1532 | 1532 | 1532 |
| 潜在客户 | 13608 | 13608 | 13608 |
| 重点保持客户 | 449 | 449 | 449 |
| 重点发展客户 | 268 | 268 | 268 |
| 重点挽留客户 | 579 | 579 | 579 |
| 高价值客户 | 4617 | 4617 | 4617 |
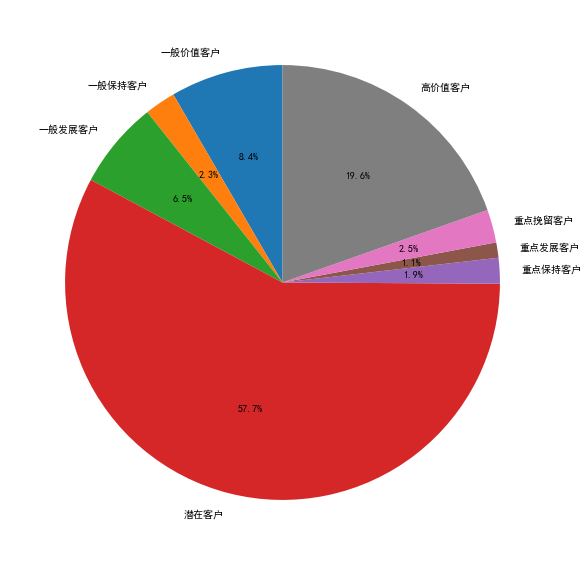
# RFM 用户分层模型图
pylab.rcParams['figure.figsize']=(10,10)
labels = ['一般价值客户','一般保持客户','一般发展客户','潜在客户','重点保持客户','重点发展客户','重点挽留客户','高价值客户']
plt.pie(label_count['M'],labels=labels,autopct = '%3.1f%%',startangle = 90)
# 喵喵数据
# 不活跃用户多:不活跃用户占了较大的比重,为57.7%;
# 用户维护高价值用户:高价值用户占比第二,为19.6%,这也是该网站的消费主力,需重点保持;
# 用心经营挽留用户:重点挽留客户、重点发展客户、重点保持客户占比较低,分别为2.5%,1.1%,1.9%。
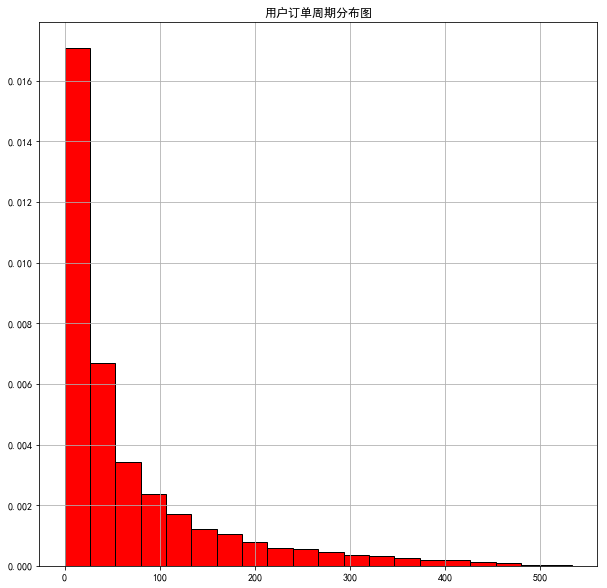
16 用户订单周期
# 16 用户订单周期
user_period = df.groupby('user_id').apply(lambda x:x.order_dt-x.order_dt.shift())
user_period.describe()
count 46089
mean 68 days 23:22:13.567662
std 91 days 00:47:33.924168
min 0 days 00:00:00
25% 10 days 00:00:00
50% 31 days 00:00:00
75% 89 days 00:00:00
max 533 days 00:00:00
Name: order_dt, dtype: object(user_period/np.timedelta64(1,'D')).hist(bins=20,density=1,edgecolor='black',color='red')
plt.title('用户订单周期分布图')
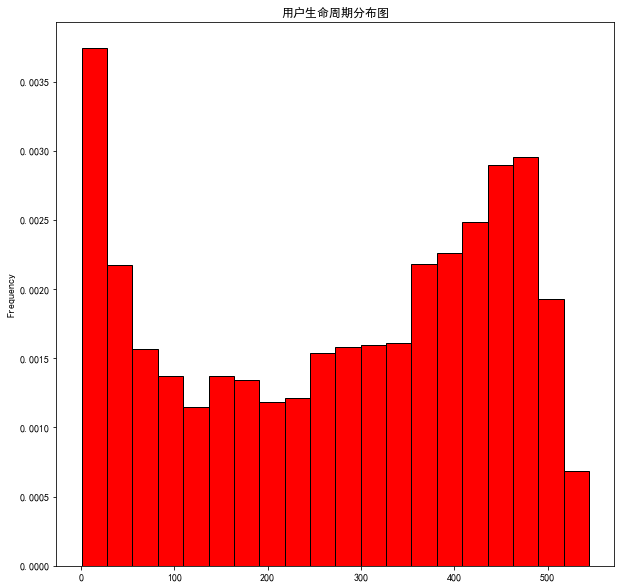
17 用户生命周期
# 17 用户生命周期
user_cycle = df.groupby('user_id').apply(lambda x:x.order_dt.max()-x.order_dt.min())
user_cycle.describe()
count 23570
mean 134 days 20:55:36.987696
std 180 days 13:46:43.039788
min 0 days 00:00:00
25% 0 days 00:00:00
50% 0 days 00:00:00
75% 294 days 00:00:00
max 544 days 00:00:00
dtype: objectuser_cycle = user_cycle/timedelta64(1,"D")
user_cycle[user_cycle>0].plot.hist(bins=20,density=1,edgecolor='black',color='red')
plt.title('用户生命周期分布图')
欢迎关注:一只阿木木

 浙公网安备 33010602011771号
浙公网安备 33010602011771号