

数据分析:某地医院药品销售业务数据分析
数据分析:某地医院药品销售业务数据分析
本篇文章以朝阳医院2018年销售数据为例,目的是了解朝阳医院在2018年里的销售情况几个业务指标
- 月均消费次数
- 月均消费金额
- 客单价
- 消费趋势
数据分析的步骤:提出问题→理解数据→数据清洗→构建模型→数据可视化
一.确定业务问题
我们知道,数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
那么,与之对应的数据分析基本过程包括:获取数据、数据清洗、构建模型、数据可视化以及消费趋势等
二:数据概览
# 2018年朝阳医院数据消费金额趋势图
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
fileNameStr='F:\\Downloads\朝阳医院2018年销售数据.xlsx'
xls=pd.ExcelFile(fileNameStr,dtype='object')
salesDf = xls.parse('Sheet1',dtype='object')
salesDf.info()
打印结果
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6578 entries, 0 to 6577
Data columns (total 7 columns):
购药时间 6576 non-null object
社保卡号 6576 non-null float64
商品编码 6577 non-null float64
商品名称 6577 non-null object
销售数量 6577 non-null float64
应收金额 6577 non-null float64
实收金额 6577 non-null float64
dtypes: float64(5), object(2)
memory usage: 359.8+ KB
数据概览
salesDf.head()
打印结果
购药时间 社保卡号 商品编码 商品名称 销售数量 应收金额 实收金额
0 2018-01-01 星期五 001616528 236701 强力VC银翘片 6 82.8 69
1 2018-01-02 星期六 001616528 236701 清热解毒口服液 1 28 24.64
2 2018-01-06 星期三 0012602828 236701 感康 2 16.8 15
3 2018-01-11 星期一 0010070343428 236701 三九感冒灵 1 28 28
4 2018-01-15 星期五 00101554328 236701 三九感冒灵 8 224 208
# 行、列数
salesDf.shape
(6578, 7)
salesDf.index
RangeIndex(start=0, stop=6578, step=1)
s
salesDf.columns
Index(['购药时间', '社保卡号', '商品编码', '商品名称', '销售数量', '应收金额', '实收金额'], dtype='object')
salesDf.count()
购药时间 6576
社保卡号 6576
商品编码 6577
商品名称 6577
销售数量 6577
应收金额 6577
实收金额 6577
dtype: int64
数据缺失: 总共有6578行7列数据,但是“购药时间”和“社保卡号”这两列只有6576个数据,而“商品编码”一直到“实收金额”这些列都是只有6577个数据, 数据中存在缺失值,可以推断出数据中存在一行缺失值,此外“购药时间”和“社保卡号”这两列都各自存在一个缺失数据。
在任何数据分析的操作步骤中,为保证数据分析准确性,数据清洗步骤就显得尤为重要。
三.数据清洗
数据清洗过程,或称数据预处理,主要包括以下几个步骤
- 选择子集
- 列名重命名
- 删除缺失数据
- 数据类型转换
- 数据排序
- 异常值处理
1选择子集
在我们获取到的数据中,可能数据量非常庞大,并不是每一列都有价值都需要分析,这时候就需要从整个数据中选取合适的子集进行分析,这样能从数据中获取最大价值。
2列名重命名
在数据分析过程中,有些列名和数据容易混淆或产生歧义,不利于数据分析,这时候需要把列名换成容易理解的名称,可以采用rename函数实现:
salesDf.rename(columns ={'购药时间':'销售时间'},inplace=True) #inplace=True,数据框本身会改动
salesDf.head()
打印结果
销售时间 社保卡号 商品编码 商品名称 销售数量 应收金额 实收金额
0 2018-01-01 星期五 1.616528e+06 236701.0 强力VC银翘片 6.0 82.8 69.00
1 2018-01-02 星期六 1.616528e+06 236701.0 清热解毒口服液 1.0 28.0 24.64
2 2018-01-06 星期三 1.260283e+07 236701.0 感康 2.0 16.8 15.00
3 2018-01-11 星期一 1.007034e+10 236701.0 三九感冒灵 1.0 28.0 28.00
4 2018-01-15 星期五 1.015543e+08 236701.0 三九感冒灵 8.0 224.0 208.00
3 缺失数据处理
任何一个得到的数据都很有可能会有缺失值,删除列(销售时间,社保卡号)中为空的行,使用dropna删除缺失数据
print('删除缺失值前大小',salesDf.shape)
# how='any' 给定的任何一列中有缺失值就删除
salesDf=salesDf.dropna(subset=['销售时间','社保卡号'],how='any')
print('删除缺失后大小',salesDf.shape)
打印结果
删除缺失值前大小 (6578, 7)
删除缺失后大小 (6575, 7)
4 数据类型处理
在导入的时候为了防止有些数据导入不进来,所以强制所有数据都是object类型,但在实际分析上这样是不可能的。
通过观察,销售数量,应收金额,实收金额,应该改成float类型,销售时间应该清理后改成时间类型,对于改变成float类型的几列,使用astype函数,代码如下。
salesDf['销售数量']=salesDf['销售数量'].astype('float')
salesDf['应收金额']=salesDf['应收金额'].astype('float')
salesDf['实收金额']=salesDf['实收金额'].astype('float')
print('转换后的数据类型:\n',salesDf.dtypes)
打印结果
`转换后的数据类型:
销售时间 object
社保卡号 object
商品编码 object
商品名称 object
销售数量 float64
应收金额 float64
实收金额 float64
dtype: object
而销售时间那一列,则需要进行处理后才能转换为时间类型,把销售时间的日期和星期分开
分割时间列,定义函数:分割销售日期,获取销售日期
def splitSaletime(timeColSer):
timeList=[]
for value in timeColSer:
#例如2018-01-01 星期五,分割后为:2018-01-01
dateStr=value.split(' ')[0]
timeList.append(dateStr)
timeSer=pd.Series(timeList)
return timeSer
获取“销售时间”这一列,对字符串进行分割,获取销售日期
timeSer=salesDf.loc[:,'销售时间']
dateSer=splitSaletime(timeSer)
修改销售时间这一列的值
打印结果
dateSer[0:3]
0 2018-01-01
1 2018-01-02
2 2018-01-06
dtype: object
获取分割之后的销售日期,少了星期时间字符
salesDf.loc[:,'销售时间']=dateSer
salesDf.head()
打印结果
销售时间 社保卡号 商品编码 商品名称 销售数量 应收金额 实收金额
0 2018-01-01 001616528 236701 强力VC银翘片 6.0 82.8 69.00
1 2018-01-02 001616528 236701 清热解毒口服液 1.0 28.0 24.64
2 2018-01-06 0012602828 236701 感康 2.0 16.8 15.00
3 2018-01-11 0010070343428 236701 三九感冒灵 1.0 28.0 28.00
4 2018-01-15 00101554328 236701 三九感冒灵 8.0 224.0 208.00
5 数据排序
使用sort_values进行排序,by:按哪几列排序,ascending=True 表示升序排列,ascending=False表示降序排列
#按销售时间进行升序排列
salesDf=salesDf.sort_values(by='销售时间',ascending=True)
#查看排序后的前10行
salesDf.head(10)
打印结果
销售时间 社保卡号 商品编码 商品名称 销售数量 应收金额 实收金额
0 2018-01-01 001616528 236701 强力VC银翘片 6.0 82.8 69.0
3436 2018-01-01 0010616728 865099 硝苯地平片(心痛定) 2.0 3.4 3.0
1190 2018-01-01 0010073966328 861409 非洛地平缓释片(波依定) 5.0 162.5 145.0
3859 2018-01-01 0010073966328 866634 硝苯地平控释片(欣然) 6.0 111.0 92.5
3888 2018-01-01 0010014289328 866851 缬沙坦分散片(易达乐) 1.0 26.0 23.0
894 2018-01-01 0013331728 861405 苯磺酸氨氯地平片(络活喜) 2.0 69.0 62.0
893 2018-01-01 0011743428 861405 苯磺酸氨氯地平片(络活喜) 1.0 34.5 31.0
4368 2018-01-01 00103283128 870921 卡托普利片 1.0 2.4 2.2
4562 2018-01-01 0010074599128 874684 厄贝沙坦氢氯噻嗪片(依伦平) 5.0 118.0 118.0
5039 2018-01-01 0010017493928 868042 马来酸左旋氨氯地平片(玄宁) 1.0 46.0 46.0
重命名行名(index),使用reset_index修改成从0到N按顺序排序的索引值index
salesDf=salesDf.reset_index(drop=True)
查看数据 salesDf.head(6)
销售时间 社保卡号 商品编码 商品名称 销售数量 应收金额 实收金额
0 2018-01-01 001616528 236701 强力VC银翘片 6.0 82.8 69.0
1 2018-01-01 0010616728 865099 硝苯地平片(心痛定) 2.0 3.4 3.0
2 2018-01-01 0010073966328 861409 非洛地平缓释片(波依定) 5.0 162.5 145.0
3 2018-01-01 0010073966328 866634 硝苯地平控释片(欣然) 6.0 111.0 92.5
4 2018-01-01 0010014289328 866851 缬沙坦分散片(易达乐) 1.0 26.0 23.0
5 2018-01-01 0013331728 861405 苯磺酸氨氯地平片(络活喜) 2.0 69.0 62.0
6 异常值处理
查看汇总数据描述,其中销售数量值不能小于0
salesDf.describe()
打印结果
销售数量 应收金额 实收金额
count 6549.000000 6549.000000 6549.000000
mean 2.384486 50.449076 46.284370
std 2.375227 87.696401 81.058426
min -10.000000 -374.000000 -374.000000
25% 1.000000 14.000000 12.320000
50% 2.000000 28.000000 26.500000
75% 2.000000 59.600000 53.000000
max 50.000000 2950.000000 2650.000000
通过条件判断来删除异常值
querySer=salesDf.loc[:,'销售数量']>0
print('删除异常值前:',salesDf.shape)
salesDf=salesDf.loc[querySer,:]
print('删除异常值后:',salesDf.shape)
# 打印结果
删除异常值前: (6549, 7)
删除异常值后: (6506, 7)
数据的预处理工作完成,接下来分析业务的各个指标
四 构建数据模型
1.月份数
业务指标1:月均消费次数=总消费次数 / 月份数
在计算总的消费次数当中将每个人每天的不同消费记录作为消费一次,用drop_duplicates去掉同一天同一个人的重复消费记录
根据列名(销售时间,社区卡号),如果这两个列值同时相同,只保留1条,将重复的数据删除
kpi1_Df=salesDf.drop_duplicates(subset=['销售时间', '社保卡号'])
#总消费次数
totalI=kpi1_Df.shape[0]
print('总消费次数=',totalI)
# 打印结果:总消费次数= 5342
# 计算月份数
#按销售时间升序排序
kpi1_Df=kpi1_Df.sort_values(by='销售时间',ascending=True)
#重命名行名,索引排序
kpi1_Df=kpi1_Df.reset_index(drop=True)
kpi1_Df.head()
打印结果
销售时间 社保卡号 商品编码 商品名称 销售数量 应收金额 实收金额
0 2018-01-01 001616528 236701 强力VC银翘片 6.0 82.8 69.0
1 2018-01-01 0012697828 861464 复方利血平片(复方降压片) 4.0 10.0 9.4
2 2018-01-01 0010060654328 861458 复方利血平氨苯蝶啶片(北京降压0号) 1.0 10.3 9.2
3 2018-01-01 0011811728 861456 酒石酸美托洛尔片(倍他乐克) 1.0 7.0 6.3
4 2018-01-01 0013448228 861507 苯磺酸氨氯地平片(安内真) 1.0 9.5 8.5
计算总月份数,第一行时间与结尾时间之差除以30取整
startTime=kpi1_Df.loc[0,'销售时间']
#最大时间值
endTime=kpi1_Df.loc[totalI-1,'销售时间']
#天数
daysI=(endTime-startTime).days
#月份数: 运算符“//”表示取整除
#返回商的整数部分,例如9//2 输出结果是4
monthsI=daysI//30
print('月份数:',monthsI)
月份数: 6
2.月均消费次数
业务指标2:月均消费次数=总消费次数 / 月份数
计算月均消费次数
kpi1_I=totalI // monthsI
print('业务指标2:月均消费次数=',kpi1_I)
# 打印结果
业务指标2:月均消费次数= 890
3.月均消费金额
指标3:月均消费金额 = 总消费金额 / 月份数
#总消费金额
totalMoneyF=salesDf.loc[:,'实收金额'].sum()
#月均消费金额
monthMoneyF=totalMoneyF / monthsI
print('业务指标3:月均消费金额=',monthMoneyF)
业务指标3:月均消费金额= 50668.35166666666
4.客单价
指标4:客单价=总消费金额 / 总消费次数
客单价(per customer transaction)是指商场(超市)每一个顾客平均购买商品的金额,客单价也即是平均交易金额。
'''
totalMoneyF:总消费金额
totalI:总消费次数
'''
pct=totalMoneyF / totalI
print('客单价:',pct)
客单价: 56.909417821040805
5.消费趋势图
#在进行操作之前,先把数据复制到另一个数据框中,防止对之前清洗后的数据框造成影响
groupDf=salesDf
#第1步:重命名行名(index)为销售时间所在列的值
groupDf.index=groupDf['销售时间']
groupDf.head()
打印结果
销售时间 社保卡号 商品编码 商品名称 销售数量 应收金额 实收金额
销售时间
2018-01-01 2018-01-01 001616528 236701 强力VC银翘片 6.0 82.8 69.0
2018-01-01 2018-01-01 0010616728 865099 硝苯地平片(心痛定) 2.0 3.4 3.0
2018-01-01 2018-01-01 0010073966328 861409 非洛地平缓释片(波依定) 5.0 162.5 145.0
2018-01-01 2018-01-01 0010073966328 866634 硝苯地平控释片(欣然) 6.0 111.0 92.5
2018-01-01 2018-01-01 0010014289328 866851 缬沙坦分散片(易达乐) 1.0 26.0 23.0
分组
gb=groupDf.groupby(groupDf.index.month)
gb
# 打印结果
<pandas.core.groupby.DataFrameGroupBy object at 0x000000000ED4CC18>
#第3步:应用函数,计算每个月的消费总额
mounthDf=gb.sum()
mounthDf
打印结果
销售数量 应收金额 实收金额
销售时间
1 2527.0 53561.6 49461.19
2 1858.0 42028.8 38790.38
3 2225.0 45318.0 41597.51
4 3005.0 54296.3 48787.84
5 2225.0 51263.4 46925.27
6 2328.0 52300.8 48327.70
7 1483.0 32568.0 30120.22
选取每个月的应收金额和实收金额的消费总额
mounthDf=DataFrame(mounthDf,columns=['应收金额','实收金额'])
mounthDf
打印结果
应收金额 实收金额
销售时间
1 53561.6 49461.19
2 42028.8 38790.38
3 45318.0 41597.51
4 54296.3 48787.84
5 51263.4 46925.27
6 52300.8 48327.70
7 32568.0 30120.22
五 数据可视化
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] #防止中文乱码
mounthDf.plot(title='2018年朝阳医院数据消费金额趋势图',figsize=(15,8),fontsize=20)
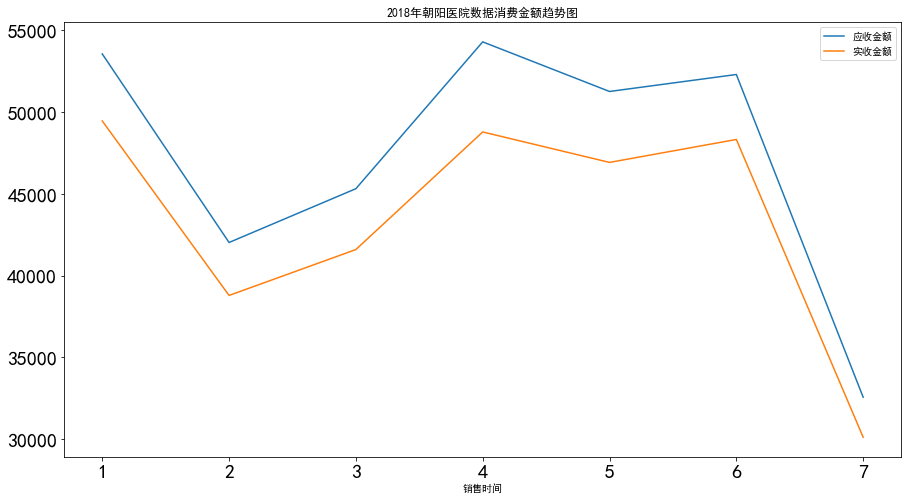
我们可以发现,周五周六的销售总额要显著的的高于其他日期,即周五周六应该前来买药的人更多,销售的药品更多。
1月和第七月消费总金额是最高的,在第七月消费金额最低。
医药销售量和天气变化有一定的影响,尤其在冬季天气寒冷和初春季节,容易受到天气影响,气温变化大,市民容易感冒,从而在医药行业销售更多了医药,销售量上升,在气温平稳时期销售量下降。
医药销售金额会受到节日、天气、重大活动等因素的影响。
六 数据建模
# 2018年朝阳医院数据消费金额趋势图
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] #防止中文乱码
fileNameStr='F:\\Downloads\朝阳医院2018年销售数据.xlsx'
xls=pd.ExcelFile(fileNameStr,dtype='object')
salesDf = xls.parse('Sheet1',dtype='object')
def splitSaletime(timeColSer):
timeList=[]
for value in timeColSer:
#例如2018-01-01 星期五,分割后为:2018-01-01
dateStr=value.split(' ')[0]
timeList.append(dateStr)
timeSer=pd.Series(timeList)
return timeSer
salesDf.rename(columns ={'购药时间':'销售时间'},inplace=True) #inplace=True,数据框本身会改动
#how='any' 给定的任何一列中有缺失值就删除
salesDf=salesDf.dropna(subset=['销售时间','社保卡号'],how='any')
salesDf['销售数量']=salesDf['销售数量'].astype('float')
salesDf['应收金额']=salesDf['应收金额'].astype('float')
salesDf['实收金额']=salesDf['实收金额'].astype('float')
timeSer=salesDf.loc[:,'销售时间']
dateSer=splitSaletime(timeSer)
salesDf.loc[:,'销售时间']=dateSer
salesDf.loc[:,'销售时间']=pd.to_datetime(salesDf.loc[:,'销售时间'],
format='%Y-%m-%d', errors='coerce')
salesDf=salesDf.dropna(subset=['销售时间','社保卡号'],how='any')
#按销售时间进行升序排列
salesDf=salesDf.sort_values(by='销售时间',ascending=True)
salesDf=salesDf.reset_index(drop=True)
# 删除异常值
querySer=salesDf.loc[:,'销售数量']>0
salesDf=salesDf.loc[querySer,:]
kpi1_Df=salesDf.drop_duplicates(subset=['销售时间', '社保卡号'])
#总消费次数
totalI=kpi1_Df.shape[0]
#按销售时间升序排序
kpi1_Df=kpi1_Df.sort_values(by='销售时间',ascending=True)
#重命名行名,索引排序
kpi1_Df=kpi1_Df.reset_index(drop=True)
startTime=kpi1_Df.loc[0,'销售时间']
#最大时间值
endTime=kpi1_Df.loc[totalI-1,'销售时间']
#天数
daysI=(endTime-startTime).days
#月份数: 运算符“//”表示取整除
#返回商的整数部分,例如9//2 输出结果是4
monthsI=daysI//30
# 业务指标2:月均消费次数
kpi1_I=totalI // monthsI
#总消费金额
totalMoneyF=salesDf.loc[:,'实收金额'].sum()
#业务指标3:月均消费金额
monthMoneyF=totalMoneyF / monthsI
'''
totalMoneyF:总消费金额
totalI:总消费次数
'''
pct=totalMoneyF / totalI
#在进行操作之前,先把数据复制到另一个数据框中,防止对之前清洗后的数据框造成影响
groupDf=salesDf
#第1步:重命名行名(index)为销售时间所在列的值
groupDf.index=groupDf['销售时间']
gb=groupDf.groupby(groupDf.index.month)
#第3步:应用函数,计算每个月的消费总额
mounthDf=gb.sum()
mounthDf=DataFrame(mounthDf,columns=['应收金额','实收金额'])
mounthDf.plot(title='2018年朝阳医院数据消费金额趋势图',figsize=(15,8),fontsize=20)
b一只阿木木

 浙公网安备 33010602011771号
浙公网安备 33010602011771号