CPU架构和MESI缓存一致性->内存模型一致性->内存屏障和原子操作->内存序->C++内存序
ref
paper、lecture、blog、chatgpt,乱七八糟的都有,具体ref文中会提到。
前言
阅读正文需要事先理解MESI和Store Buffer和Invalidate Queue的基础知识,不理解的看论文《Memory Barriers: a Hardware View for Software Hackers》http://www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.07.23a.pdf。
此外需要对分布式一致性理论有个基础了解,不了解的看Martin Kleppmann的课程《Distributed Systems》 https://www.cl.cam.ac.uk/teaching/2122/ConcDisSys/dist-sys-notes.pdf https://space.bilibili.com/5277360/channel/collectiondetail
内存序要处理的核心问题是如何保证CPU并发访问(读写)同一个数据的一致性。尽管编译器优化和CPU除了读写内存指令外的指令乱序执行也是内存序要处理的问题,但后两个问题更简单也更好处理。
代码指令重排序(Reordering)
导致指令重排序的因素从上到下有三层:编译器、CPU和缓存。
编译器
编译器优化
编译器会对代码进行优化,优化是个广义概念(常量折叠、循环翻转等等),优化包含了编译器指令重排。
例如编译器不保证生成的汇编代码中对p_a的内存写入发生在对p_b的内存读取之前。
*p_a = a;
b = *p_b;
C/C++的volatile关键字
变量声明为 volatile有两个作用:
- 保证编译器对volatile 变量间的访问不会进行汇编指令层面的重排,但是volatile 变量和其他变量间还是有可能会重排的;
- 保证编译器对volatile变量的访问不会进行汇编层面的寄存器优化,每次都从内存读取最新值;
编译器内存屏障指令(Compiler Memory Barrier Instructions)
只讨论GNU编译器指令,其他编译器不谈。
例如编译器会对如下变量的赋值操作进行汇编层面的重排序:

使用__asm__ __volatile__ ("" ::: "memory");可以避免重排:

注意:
- Compiler Memory Barrier只是一个通知的标识,告诉Compiler在看到此指令时,不要对此指令的上下部分做重排序;
- 在编译后的汇编中,Compiler Memory Barrier消失,CPU不能感知到Compiler Memory Barrier的存在,这点与后面提到的CPU Memory Barrier有所不同;
CPU和缓存(Cache)
CPU和缓存导致的指令重排序称为CPU Memory Ordering。
CPU访问缓存和内存的时钟数:L1 Latency 4 clks; L2 10 clks; L3 20 clks; Memory 200 clks -> Huge Latency。
从Intel System Programming Guide 8.2的说明我们知道CPU指令重排(或者说指令乱序执行)的目的是为了解决CPU读写内存的问题,通过Reordering可以提高CPU在涉及到访存时的指令执行速度,避免过大的CPU Stall。
The term memory ordering refers to the order in which the processor issues reads(loads) and writes(stores) through the system bus to system memory.
本文重点讨论CPU Memory Ordering相关问题。
CPU基础
两种主流架构:
- x86-64 / x64 / AMD64
- x86-64 / x64 / AMD64是相同的CPU架构
- AMD64是AMD公司先于Intel公司推出的64位x86架构指令集,其向后兼容32位x86架构指令集
- Intel得到AMD64架构指令集授权后,推出了兼容AMD64的64位指令集,命名Intel 64,又称x86-64或者x64
- 只有Store Buffer,是一种强内存一致性的架构
- ARM(Advanced RISC Machine)
- 有Store Buffer和Invalidate Queue,是一种弱内存一致性的架构
Store和Load
CPU和Cache层面的乱序执行主要就是针对内存的Store和Load乱序。
- Store是CPU把寄存器的数据写入到内存(Cache);
- Load是CPU把内存(Cache)的数据读取到寄存器;
多核处理器
物理处理器芯片(Chip)上的核心(Core)是承载各类指令运算的基本单位,随着芯片技术发展,单个Chip上的核心数从单个变成多个
- 单核处理器
- 只有1个Core,不需要考虑缓存一致性导致的内存访问乱序问题,甚至可以在单个Cache Line上执行实质性的原子操作
- 多核处理器
- 集成了两个或多个Core,这些Core可以并行处理不同的任务
- 每个核心由各自的专属Cache(L1 L2),也有共享的Cache(L3)
- L1和L2的存在造成了缓存一致性问题,MESI协议解决了缓存一致性
- 缓存一致性大体是:某个核心对Cache或者内存的读写,能够被其他核心感知;对于同一份数据,多个核心的并行操作在总体上看来是串行的。
- Store Buffer和Invalidate Queue的引入,优化了核心读写Cache的性能,也是造成Load和Store指令重排的原因之一。
- x86-64架构只有Store Buffer
- ARM架构同时有Store Buffer和Invalidate Queue
- NUMA处理器
- Non-Uniform Memory Access,非一致性内存访问
- 同一个Chip里的Core被组织成多个Node,每个Node都有自己的本地内存
- Node内的Core访问本地内存的速度较快,而访问其他Node的内存(远程内存)则需要更长的时间
- 和多核处理器一样面临缓存一致性的破坏问题
多个核心数需要使用MESI(x86-64架构使用)/MOESI(ARM架构使用)协议保证缓存一致性。
并发(Consistency) 与一致性(Consistency)
并发(Consistency)
在单台计算机的范畴下,多个核心(或者说多个线程/进程)同时访问相同内存地址称为并发。
相同内存地址空间好理解,那同时的定义是什么?
从抽象的角度来看,计算机的任何操作都不是瞬时完成的,操作从开始到结束需要一段时间,而操作结果在开始到结束之间的某一个时间点生效;如果两个操作发生的时间段存在重叠,那么这两个操作就是同时的,就是并发的;两个并发操作的生效顺序存在不确定性;如果操作生效是原子的,两个结果出现顺序有先有后;如果操作不是原子的,两个结果可能会相互混杂生效出现。
从CPU指令角度来看,两个指令(来自不同核心)访问相同内存地址空间的起始和终止时间段如果存在重叠,那么这两个指令就是并发的;来自同一个核心的两个相邻指令在访存的生效上一定有其自然的先后次序,所以不存在并发;
举一个各类并发范畴都要解决的Read-After-Write典型例子:核心A的指令1写数据到某内存地址后的极短时间内核心B的指令2读取相同内存地址,指令1不一定能读到指令2写入的数据,两个指令是并发的;CPU对访存的各类复杂优化手段“模糊"了指令访存的结束时间点,从指令1的角度上看它已经把数据写入到内存并结束了动作(专业术语叫retire),但数据并没有真的到达内存(核心A发出的read Invalidate消息也还没被核心B收到),紧接而来的指令2自然读不到数据(结果读到的是写入之前的老数据),所以这两个指令也是并发的。
一致性(Consistency)
计算机领域不同范畴关于Consistency的定义是不一样的。
CPU多个核心访问内存Cache的角度上有专属的一致性名词:缓存一致性(Cache Coherence)。
缓存一致性要求所有处理器核心中的缓存对共享内存数据的视图应该一致,核心对缓存的写入结果能够被所有核心观测到,这是一种模糊的定义。
本节以Martin Kleppmann的分布式系统课程的多节点分布式系统模型来更细致地定义不同程度的一致性(有助于分析不同cpu架构的cace coherence是什么程度的一致性),本节内容也是摘抄自该课程。
前置知识
多节点分布式系统模型
- 分为client和server;
- server由多个节点组成,多个节点存储了相同数据的副本,节点间通过网络相互通信,每个节点在副本都可能发生各种events;
- client作为observer,希望在每个节点上观测到的副本的值(甚至是副本的变化顺序)是一致的;
该模型可以引申到我们的CPU和cache访存行为上。
注意,一致性并不要求client观测到的副本结果是正确的,如果client在每个节点上观测到的副本变化顺序(比如副本先读到是x值,再读到是y值)是一致的,即使观测结果违背了物理时间上的变化顺序(y -> x),也算是一种一致性。
happens-before relation
An event is something happening at one node (sending orreceiving a message, or a local execution step).
We say event a happens before event b (written a → b) if:
- a and b occurred at the same node, and a occurred
before b in that node’s local execution order; or - event a is the sending of some message m, and event b is the receipt of that same message m (assuming sent messages are unique); or
- there exists an event c such that a → c and c → b.
happens-before关系是一种偏序关系。
Causality relation
这是物理上的概念。
事件B受到了事件A的发生的影响,从而发生了事件B,那么A和B就存在因果关系。
显然,A导致B发生,说明A肯定在B之前发生。
因此happens-before关系有可能是Causality关系,反过来不一定。
偏序(partial order)和全序(total order)
这是数学上的概念。
假设R是非空集合A上的关系,关系R可能有以下特性:
- 自反性:任取一个A中的元素x,如果都有<x,x>在R中,那么R是自反的;
- 对称性:任取两个A中的元素x,y,如果<x,y> 在关系R上,那么<y,x> 也在关系R上,那么R是对称的;
- 反对称性:任取两个A中元素x,y(x!=y),如果<x,y> 在关系R上,那么<y,x> 不在关系R上,那么R是反对称的;
- 传递性:任取三个A中元素x,y,z,如果<x,y>,<y,z> 在关系R上,那么 <x,z> 也在关系R上,那么R是传递的;
如果集合A上的关系R满足自反的,反对称的,和传递的,则R是A上的偏序(partial order)。
偏序的R不一定涉及到集合A上的所有元素,有可能是部分元素;所以根据偏序关系R,无法比较集合A任意两个元素x、y的大小。
如果偏序关系R在集合A上涉及到任意元素,即任意两个元素x、y都是可比的,要么是<x, y>,要么是<y, x>,不可能出现两种情况同时存在或者同时不存在,那么R就是全序关系。
全序关系可以保证分布式系统上所有的事件按照统一的先后顺序发生。偏序关系只能保证部分事件集合按照先后顺序发生。
happens-before关系是一种偏序,发生在分布式系统上的事件 x、y不一定能区分出发生的先后顺序,既不是x->y也不是y->x,此时我们定义x和y是并发关系,即x || y。
不同程度的一致性
一致性强度从高到低:线性一致性 > 顺序一致性 > 因果一致性 > 最终一致性。具体参考博客http://www.xuyasong.com/?p=1970
线性一致性(linearizability consistency)
分布式系统最期望的一致性,CAP 中的C一般指该种强度。
线性一致性符合total order的定义,分布式系统里的任何event的发生都服从全局的物理时间次序:
- 是所有event集合上的全序关系
- 任何一次读都能读到某个数据的最近一次写的数据;
- 系统中的所有进程,看到的操作顺序,都与全局时钟下的顺序一致,所以该一致性一定是正确的,服从真实物理世界发生次序的一致性;
顺序一致性(Sequential Consistency)
- 顺序一致性是所有event集合上部分event的偏序关系;
- 节点A上发生的event1 可能无法和节点B发生的event2进行发生次序的比较;
- 但是所有节点上发生的相同的event集合上的元素都服从相同的顺序,该顺序可以不服从物理世界的发生次序;
举例:
- W表示读操作, W(x, 1)表示向x写入1;
- R表示写操作,R(x, 1)表示从x读取到1;
- --表示读写时间在物理时间上发生的事件范围,读写事件在该范围的某个时间点上生效;
- 无论何种情况,我们无法区分A节点和B节点上两个W操作发生的先后顺序;
- 因为两个操作的时间overlap了;
- 假设物理时间上实际是先写入1后写入2;
- 情况1和情况2下,C节点和D节点对于x的读取结果的顺序是一样的,符合顺序一致性;
- 即使两个节点先都读到2再读到1,违背了物理发生次序,也合理的一致性;
- 情况3下,C节点和D节点对于x的读取结果的顺序是一样的,不符合顺序一致性;
情况1:
A: --W(x,1)----------------------
B: --W(x,2)----------------------
C: -R(x,1)- --R(x,2)-
D: -R(x,1)- --R(x,2)--
情况2:
A: --W(x,1)----------------------
B: --W(x,2)----------------------
C: -R(x,2)- --R(x,1)-
D: -R(x,2)- --R(x,1)--
情况3
A: --W(x,1)----------------------
B: --W(x,2)----------------------
C: -R(x,2)- --R(x,1)-
D: -R(x,1)- --R(x,2)--
因果一致性(Casual Consistency)
- 因果一致性是所有event集合上部分event的偏序关系;
- 如果分布式系统上两个event(可以发生在相同节点或不同节点)有因果关系,那么在所有节点上必须观测到这个因果关系,即两个event服从happens before关系;
- 例如因为event1发生,才会有event2发生,故event1 -> event2;
微信的某个具体的朋友圈 与 该朋友圈的评论 存在因果关系,朋友圈 -> 评论;评论 与 该评论的回复存在因果关系, 评论 -> 回复;
微信朋友圈在各个数据中心的消息同步符合因果一致性,详情见https://www.cnblogs.com/king0101/p/11908305.html。
最终一致性(Eventual Consistency)
不保证在任意时刻任意节点上的同一份数据都是相同的,但在一段时间后,节点间的数据会最终达到一致状态。
CPU架构
我们只讨论两种主流架构:
- x86-64 / x64 / AMD64
- x86-64 / x64 / AMD64是相同的CPU架构
- AMD64是AMD公司先于Intel公司推出的64位x86架构指令集,其向后兼容32位x86架构指令集
- Intel得到AMD64架构指令集授权后,推出了兼容AMD64的64位指令集,命名Intel 64,又称x86-64或者x64
- 只有Store Buffer,是一种强内存一致性的架构
- ARM(Advanced RISC Machine)
- 有Store Buffer和Invalidate Queue,是一种弱内存一致性的架构
指令重排和内存屏障
- STORE是CPU把寄存器的数据写入到内存(Cache);
- LOAD是CPU把内存(Cache)的数据读取到寄存器;
- CPU指令重排主要是对STORE和LOAD的重排
- 内存屏障是控制CPU1)读写内存顺序和2)写入数据对其他Core可见的机制,内存屏障也称内存序;
- 内存屏障保证某个Core写内存结果对其他Core可见
- 内存屏障保证读写内存的顺序
- 可以保证对不同地址的数据的读写顺序
- 也可以保证对同一个数据的读写,乱序会导致非预期程序行为
指令重排(Reordering)
Definition: Reads and writes do not always happen in the order that you have written them in your code.
Why Reordering: Performance
Reordering Principle: In single threaded programs form the programmer's point of view, all operations appear to have been executed in the order specified, with all inconsistencies hidden by hardware.
指令重排会发生在编译器和CPU中,指令重排可以提升性能,重排原则保证在单线程程序里指令执行的实际效果和代码预期效果一样,不保证多线程的程序的实际效果和预期一样。
四种内存屏障的抽象
以下四种内存读写顺序是STORE和LOAD的排列组合。在实际的内存屏障机制里,可能包含以下一种/多种内存屏障效果。
LoadLoad Barrier
StoreStore Barrier之前的所有Load指令 先于 LoadLoad Barrier之后的所有Load指令 执行,即保证了CPU读取内存的顺序性。
Load1(s) //复数
LoadLoad Barrier
Load2(s) //复数
x86-64 CPU架构的有一样的概念《Intel® 64 and IA-32 Architectures Software Developer’s Manual》:Reads are not reordered with other reads.
StoreStore Barrier
StoreStore Barrier之前的所有Store指令 先于 StoreStore Barrier之后的所有Store指令 执行,即保证了CPU写入内存的顺序性。(如果访问的是同一个地址,可以避免Store1覆盖了Store2写入到内存的值)
Store1(s) //复数
StoreStore Barrier
Store2(s) //复数
x86-64 CPU架构的有一样的概念,但是有些例外,《Intel® 64 and IA-32 Architectures Software Developer’s Manual》: Writes to memory are not reordered with other writes, with the following exceptions: writes executed with the CLFLUSH instruction;streaming stores(writes) executed with the non-temporal move instructions(MOVNTI, MOVNTQ, MOVNEDQ, MOVNTPS, and MOVNTPD); and string operations (see Section 8.2.4.1).
LoadStore Barrier
LoadStore Barrier之前的所有Load指令 先于 LoadStore Barrier之后所有Store指令 执行,即保证了Load和Store内存的先后顺序。(如果访问的是同一个地址,可以避免Load指令读到Store指令写入内存的值)
Load(s) //复数
LoadStore Barrier
Store(s) //复数
x86-64 CPU架构的有一样的概念《Intel® 64 and IA-32 Architectures Software Developer’s Manual》:Writes are not reordered with older reads.
StoreLoad Barrier
- 开销最大的屏障,几乎禁止了所有的优化:
- StoreLoad Barrier之前的Store指令 先于 StoreLoad Barrier之前的Load指令 执行,保证了Store指令结果对其他处理器可见。
切 - StoreLoad Barrier之前的所有指令(Store/Load) 先于 StoreLoad Barrier之前的所有指令(Store/Load) 执行。
- StoreLoad Barrier之前的Store指令 先于 StoreLoad Barrier之前的Load指令 执行,保证了Store指令结果对其他处理器可见。
- 从禁止重排和保证内存访问先后顺序的效果上看,StoreLoad Barrier > LoadLoad Barrier + StoreStore Barrier + LoadStore Barrier
Store(s)/Load(s) //复数
StoreLoad Barrier
Load(s)/Store(s) //复数
三种内存屏障指令(也是一种抽象,更加贴近现实CPU架构的内存屏障)
Store Barrier
- 在Store Barrier指令前的所有Store操作,必须在Store Barrier指令开始执行之前全部执行完毕;
- 在Store Barrier指令后的所有Store操作,必须在Store Barrier指令执行结束后才能开始执行;
- Store Barrier只针对Store操作,对Load无任何影响;
Load Barrier
- 在Load Barrier指令前的所有Load操作,必须在Load Barrier指令开始执行之前全部执行完毕;
- 在Load Barrier指令后的所有Load操作,必须在Load Barrier指令执行结束后才能开始执行;
- Load Barrier只针对Load操作,对Store无任何影响;
Full Barrier
• Load + Store Barrier,Full Barrier两边的任何读写操作,均不可跨过Full Barrier交换顺序
CPU的内存一致性模型(Memory Consistency Models)
缓存一致性是共享资源数据的一致性,在多核CPU系统中,多个CPU的缓存副本的数据应该保持一致。
MESI保证了缓存一致性(Cache Coherence),但是Store Buffer和Invalidate Queue带来了顺序一致性(Sequential Consistency)的问题。
举例1. Core-0对某变量A的写入操作仅比Core-1对A的读取操作提前很短的一点时间,Core-1不一定读到Core-0新写入的值。
新写入的值多久之后能确保被读取操作读取到,是内存一致性模型(Memory Consistency Models)要讨论的问题。
内存一致性模型(Memory Consistency Models)
内存一致性模型(Memory Consistency Models)是硬件层面的概念,定义了处理器中核心对内存操作的执行顺序,可以理解为内存一致性模型是CPU硬件上能支持的各类内存序(内存屏障)的集合。按照模型能满足哪些内存序,大体分为以下三种细分模型:
顺序一致性模型(Sequential consistency)
理想模型,强度等同于线性一致性,没有乱序的存在,对指令重排的限制过大,性能不好,没有硬件体系实现该模型,以前没有多少优化的单核CPU符合该模型。
本节部分内容总结摘抄自https://www.0xffffff.org/2017/02/21/40-atomic-variable-mutex-and-memory-barrier/ 和 https://wiki.cyub.vip/computer-system/CPU-Cache-and-Memory-Ordering.pdf
强一致性模型 (Strong consistency)
x86-64的Total Store Ordering (TSO) 内存一致性模型是典型代表。因为Store Buffer的引入,Total Store Ordering强度略低于顺序一致性,但强于因果一致性。
本节英文内容来自《Intel® 64 and IA-32 Architectures Software Developer’s Manual》
x86-64架构单个Core上的指令重排规则
保证了LoadLoad、LoadStore、StoreStore的顺序,但不保证StoreLoad的顺序。具体如下:
- Reads are not reordered with other reads.
- Writes are not reordered with older reads.
- Writes to memory are not reordered with other writes.
- Reads may be reordered with older writes to different locations but not with older writes to the same location.
- 这意味着哪怕在同一个core上,即使需要执行的汇编指令是先写y地址,再读x地址,但是在cpu实际的执行中会出现先Load x地址,再Store y地址。
x86-64架构多个Core之间的指令重排规则
- Individual processors use the same ordering principles as in a single-processor system.
- Writes by a single processor are observed in the same order by all processors.
- 某个Core上的全部写操作以同样的顺序被其他Core观测到
- Writes from an individual processor are NOT ordered with respect to the writes from other processors.
- 不同Core之间的Store操作不会重排序
- Memory ordering obeys causality (memory ordering respects transitive visibility).
- 满足因果一致性
- Any two stores are seen in a consistent order by processors other than those performing the stores.
- 第三方总是观察到一致的写操作顺序
x86-64架构不满足顺序一致性
以下是关于x84-64处理器之间的因为Store buffer导致违背顺序一致性的举例:
- 初始情况下,Processor0和Processor1的L1 Cache上的x和y变量的值都为0
- Processor0和Processor1同时开始执行各自线程的代码(假设3行代码依次服从时间点1、2、3)
- 在时间点1下,Processor0对x地址执行Store指令,结果被写入Processor0的store buffer
- Processor0的store buffer的x新值不会立刻被Processor1看到
- 在时间点1下,Processor1对y地址执行Store指令,结果被写入Processor1的store buffer
- Processor1的store buffer的y新值不会立刻被Processor0看到
- 在时间点2下,Processor0执行Load指令读取x,从自身store buffer上读x的新值到寄存器r1
- 在时间点2下,Processor1执行Load指令读取y,从自身store buffer上到y的新值到寄存器r3
- 在时间点3下,Processor0执行Load指令读取y地址,此时Processor1的Store指令的Read Invalidate消息还没到达Processor0的cache,所以读取y的旧址到寄存器r2
- 在时间点3下,Processor1执行Load指令读取x地址,此时Processor0的Store指令的Read Invalidate消息还没到达Processor1的cache,所以读取x的旧址到寄存器r4
Processor0先读到x再读到y,Processor1先读到y再读到x,违反了顺序一致性的定义,从结果上导致了发生在时间节点3的Load指令没有读取到发生在时间节点1的Store指令,这是另一个StoreLoad乱序情况。

弱一致性模型 (Weak consistency)
Arm架构的CPU自身不保证LoadLoad、LoadStore、StoreStore和StoreLoad的顺序,Arm架构提供了dmb、dsb、isb等内存屏障指令。
真实的CPU内存屏障指令(x86-64/AMD64 CPU架构,Arm架构后续再补)
本文梳理了3种实际内存屏障指令以及和上文所述的两类CPU抽象屏障的的关系
x86-64内存屏障的官方介绍

lfence(读屏障)
lfence = LoadLoad Barrier + LoadStore Barrier > Load Barrier
- 和Load Barrier相对应
- 和通用的Load Barrier相比,lfence不允许lfence之后的Store指令在lfence之前执行
- 实际效果等同于LoadLoad Barrier + LoadStore Barrier
x86-64的 sfence(写屏障)
sfence = Store Barrier = StoreStore Barrier
- Store Barrier
- 效果等同于同于抽象的 StoreStore Barrier
mfence(全屏障)
mfence = StoreLoad Barrier = Full Barrier > lfence + sfence
- Full Barrier
- 效果大于 lfence + sfence
- x86-64架构里,实际上只有mfence指令有实际意义,因为其他类型的内存屏障已经在架构上保证了
在C/C++中使用内存屏障指令
- Only CPU Memory Barrier:
asm volatile(“mfence”); - CPU + Compiler Memory Barrier:
asm volatile(“mfence” ::: ”memory”);
![]()

Linux针对x86-64的内存屏障的内置函数
smp_rmb()
smp_wmb()
smp_mb()

原子操作指令自带内存屏障
除了CPU本身提供的三种Memory Barrier指令之外,所有带Lock前缀的指令或者自带Lock效果的指令也能起到mfence的作用:
Reads or writes cannot be reordered with I/O instructions, locked instructions, or serializing instructions.
原子操作
定义:
- An operation acting on shared memory is atomic if it completes in a single step relative to other threads.
- When an atomic store is performed on a shared variable, no other thread can observe the modification half-complete.
- When an atomic load is performed on a shared variable, it reads the entire value as it appeared at a single moment in time.
非原子操作可能出现的问题,以下图为例

- Half Write
- mov dword ptr [c], 2执行后,会短暂出现c的half write现象;
- Half Read
- 若c出现half write,则读取c会出现half read现象;
- Composite Write
- 两个线程同时write c,一个完成,一个half write,则c的值,来自线程1,2两个write操作的组合;
Simple Write和Simple Read是原子的
下图可知,x86架构CPU在读写内存对齐的2/4字节内(32位系统下),或者2/4/8字节(64位系统下)的变量操作是原子的:
- Simple Write,例如 int a = 1;
- Simple Read,例如 int b; b = a;
![]()
![]()


Read-Modify-Write(RMW)操作
普通的RMW操作,例如C/C++中的++ --操作符,例如对int a执行a++操作,实际上是由至少3条指令组成的:
- Read from Memory
- Modify
- Write to Memory
![]()

在多线程的临界区里执行RMW操作,可以使用CPU提供的具备原子性的RMW类型指令
CPU实现原子操作的原理
- 总线锁
- 一些CPU通过锁定总线来实现原子操作。在执行原子指令时,CPU可以锁住总线以独占对内存的访问权。这种方法可以确保在操作期间没有其他处理器或内核运行能够访问被锁定的内存区域。
- 缓存锁
- 现代处理器通常采用更为细粒度的缓存锁定(cache locking)机制。在这种情况下,CPU锁定的是缓存行而不是整个总线。这种方法相对更高效,因为它允许其他处理器访问非锁定的内存区域。
![]()
- 现代处理器通常采用更为细粒度的缓存锁定(cache locking)机制。在这种情况下,CPU锁定的是缓存行而不是整个总线。这种方法相对更高效,因为它允许其他处理器访问非锁定的内存区域。

编程中如何保证原子性
- x86架构内存对齐的simple-read 和 simple-write
- 使用x86架构原子操作指令:
- LOCK CMPXCHG: 比较并交换。
- LOCK XADD: 加并返回原值。
- LOCK XCHG: 交换。
- LOCK INC/DEC: 原子增/减。
- LOCK ADD/SUB: 原子加/减。
- 使用ARM架构原子操作指令:
- 从易用性和可移植性考虑,一般使用Linux的内置函数或者编程语言的原子库API:
原子操作和内存屏障和内存序的关系
- 内存序的本质是定义了不同线程之间的内存访问顺序,解决多线程访问临界区的问题;
- 内存序的主要通过内存屏障指令来实现;
- 内存序不一定需要通过内存屏障来实现;
- 例如在只有两个线程访问临界区时可以使用Peterson’s Algorithm来进行线程间的同步;
- CPU架构层面上,原子操作指令包含了内存屏障效果;
- x86架构的Lock前缀指令隐式地包含mfence内存屏障的作用
- 编程语言层面上,C++关于内存序的实现强制关联了原子操作和内存屏障;
Peterson’s Algorithm简介
int flag[2]; //0号线程想获得锁时会把flag[0] 置1
//1号线程想获得锁时会把flag[1] 置1
int turn; //0号线程想获得锁时会把turn置1,表示谦让,希望1号线程先进入
//1号线程想获得锁时会把turn置0,表示谦让,希望0号线程先进入
//在并发场景下,以上四个操作无论以何种顺序交替执行,都会只有一个线程可以获取锁
//turn变量需要内存对齐,保证并发操作的原子性
void init() {
flag[0] = flag[1] = 0; // 1->thread wants to grab lock
turn = 0; // whose turn? (thread 0 or 1?)
}
void lock() {
flag[self] = 1; // self: thread ID of caller
turn = 1 - self; // make it other thread's turn
while ((flag[1-self] == 1) && (turn == 1 - self))
; // spin-wait
}
void unlock() {
flag[self] = 0; // simply undo your intent
}
线程0的行为
void lock() {
flag[0] = 1;
turn = 1;
while ((flag[1] == 1) && (turn == 1 ));
}
void unlock() {
flag[0] = 0;
}
线程1的行为
void lock() {
flag[1] = 1;
turn = 0;
while ((flag[0] == 1) && (turn == 0));
}
void unlock() {
flag[1] = 0;
}
2个以上的线程使用peterson锁需要将线程分成两组抢夺锁,胜出组继续分组,直到最后一个线程所有轮次里都胜出获取perterson 锁,该方式会导致获取锁有较大延迟产生。
内存序(Memory Order)
内存序定义了不同线程之间的内存访问顺序。
编程语言层面上,内存序是对于编译器和不同架构CPU内存一致性模型在多线程临界区内存访问顺序控制上的语义封装,内存序实现的基础包含3个主要方面:编译器内存屏障指令、CPU架构的内存屏障指令以及CPU架构(Lock)原子操作指令。
Read-Acquire和Write-Release语义
本节介绍的是编程语言层面的内存屏障抽象。
不同编程在内存序语义上基本可以抽象出两种基础语义内存屏障Acquire和Release:
- A read-acquire executes before all reads and writes by the same thread that follow it in program order.
- 必须先执行完read-acquire内存屏障,才能执行在read-acquire之后的读写指令
- 相当于LoadLoad + LoadStore Barrier + 编译器内存屏障
- A write-release executes after all reads and writes by the same thread that precede it in program order.
- 必须先执行完write-release内存屏障之前所有的读写指令,才能执行write-release内存屏障
- 相当于LoadStore + StoreStore Barrier + 编译器内存屏障
- read-acquire和write-release一前一后,将读写指令限定在一个临界区内,确保读写指令不会在临界区外允许
- Read-Acquire + Write-Release语义,是所有锁实现的基础(Spinlock, Mutex, RWLock, ...)
- Read-Acquire又称为Lock Acquire;
- Write-Release又称为Unlock Release;
![]()
![]()

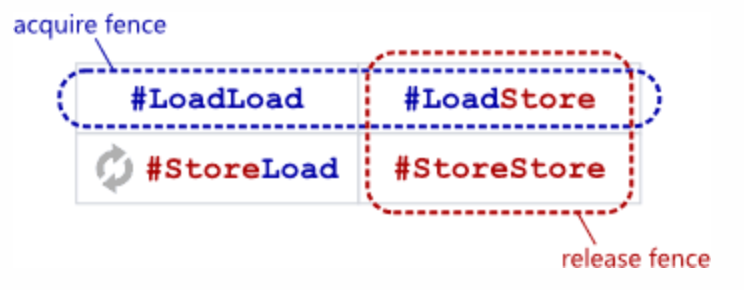
C++的原子库及内存序
在理解本文的内容的基础上(特别是Acquire Release语义),你可以非常容易看懂cppref官网 https://en.cppreference.com/w/cpp/atomic/memory_order ,里面的内容讲得非常好,网上各种博客的内容都是它的翻译。
此外一位B站博主关于C++内存序的内容视频讲解 https://www.bilibili.com/video/BV1Qy411q7Xq ,https://github.com/parallel101/course/tree/master/slides/atomic,给出了C++原子库和内存序的使用讲解,并且给了一个测试框架(框架有些小问题,偶尔死锁,)用于验证,此外基于C++原子库和内容序还给出了 Mutex 、Spinlock、无锁链表的实现。
本节给出一些容易忽略的点,可以解决看cppreference官网和博主视频时的小疑问:
- 根据cppref官网原文
RMWs (with any ordering) following a release form a release sequence可知,原子类的RMW操作有读取、修改、写入三个操作,会强制给写入操作加上memory_order_release内存序,因此我们只需要关心读取操作的内存序; - 根据cppref官网原文
If failure is stronger than success or(until C++17) is one of std::memory_order_release and std::memory_order_acq_rel, the behavior is undefined.可知,无论是compare_exchange_strong还是compare_exchange_weak,success参数的内存序强度要高于failure,否则就是未定义行为,可以推断这两个CAS的读取操作部分默认使用的是failure的内存序;根据cppref官网原文std::memory_order_acquire if order is std::memory_order_acq_rel和std::memory_order_relaxed if order is std::memory_order_release和otherwise order这三个关于failure参数的说明,我们更加确信推断正确。 - 关于C++内存序强度排序,release是最弱的,seq_cst是最强的,acq_rel是次强的,acquire强于consume,acquire和release不好比较它们是组合使用的,同理consume和release也不好比较。
- compare_exchange_weak在弱内存一致性的平台上开销比compare_exchange_strong小,强内存一致性平台上开销一样;compare_exchange_weak在比较时即使expected参数和实际的值相等也有几率返回false,而compare_exchange_strong不会有该问题;因此compare_exchange_weak一般要结合do while循环使用。
- compare_exchange_strong和compare_exchange_weak都会在返回false前将expected参数赋值为实际的值,因此在do while循环里,可以不用额外去更新expected的值,避免多余消耗。
- 在多线程简单地对某个原子变量x进行x++的操作,relaxed内存序都可以保证结果的正确性,要注意把原子性 和 内存序这两个概念区分开。
- 多线程环境下如果线程之间有Acquire Release依赖,或者说线程间需要实现happens-before,例如上锁/解锁,生产者/消费者 场景,一定要考虑内存序。
- C++20标准,基于linux系统调用futex给原子变量增加了wait和notify能力,类似condition variable。
- futex, Fast User space muTEX,用户态和内核态混合的同步机制,基于futex可以在userspace实现互斥锁、读写锁、condition variable等同步机制,在没有竞争的场景下,锁的获取和释放性能都非常高,不需要内核的参与,仅仅是通过用户空间的原子操作来修改futex word的状态即可。在有竞争的场景下,如果线程无法获取futex锁,那么把自己放入到 wait queue中(陷入内核,有系统调用的开销),而在owner task释放锁的时候,如果检测到有竞争(等待队列中有阻塞任务),就会通过系统调用来唤醒等待队列中的任务,使其恢复执行,继续去持锁。如果没有竞争,那么也无需陷入内核。
- 我在arm服务器上验证了
同一个cache line上的多个变量可以自行保证内存序这个说法,代码(使用了B站博主的测试框架)和执行结果如下,个人看了结果尚无定论
多线程测试框架
#pragma once
#include <map>
#include <string>
#include <atomic>
#include <thread>
#include <type_traits>
#include <utility>
#include <vector>
#if defined(__unix__) && __has_include(<sched.h>) && __has_include(<unistd.h>)
#include <sched.h>
#include <unistd.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/syscall.h>
#elif defined(_WIN32) && __has_include(<windows.h>)
#include <windows.h>
#endif
#if defined(__unix__) && __has_include(<cxxabi.h>)
#include <cxxabi.h>
#endif
struct SpinBarrier
{
explicit SpinBarrier(std::size_t n) noexcept
: m_top_waiting((std::uint32_t)n - 1),
m_num_waiting(0),
m_sync_flip(0) {}
bool arrive_and_wait() noexcept
{
bool old_flip = m_sync_flip.load(std::memory_order_relaxed);
if (m_num_waiting.fetch_add(1, std::memory_order_relaxed) == m_top_waiting)
{
m_num_waiting.store(0, std::memory_order_relaxed);
m_sync_flip.store(!old_flip, std::memory_order_release);
#if __cpp_lib_atomic_wait
m_sync_flip.notify_all();
#endif
return true;
}
else
{
#if __cpp_lib_atomic_wait
std::uint32_t retries = 255;
do
{
if (m_sync_flip.load(std::memory_order_acquire) != old_flip)
return false;
if (m_sync_flip.load(std::memory_order_acquire) != old_flip)
return false;
if (m_sync_flip.load(std::memory_order_acquire) != old_flip)
return false;
if (m_sync_flip.load(std::memory_order_acquire) != old_flip)
return false;
} while (--retries);
#else
while (m_sync_flip.load(std::memory_order_acquire) == step)
;
#endif
m_sync_flip.wait(old_flip, std::memory_order_acquire);
return false;
}
}
private:
std::uint32_t const m_top_waiting;
std::atomic<std::uint32_t> m_num_waiting;
std::atomic<bool> m_sync_flip;
};
template <std::size_t I>
struct MTIndex
{
explicit MTIndex() = default;
};
template <std::size_t IBegin, std::size_t IEnd>
struct MTRangeIndex
{
explicit MTRangeIndex() = default;
template <std::size_t I, std::enable_if_t<(I >= IBegin && I <= IEnd), int> = 0>
MTRangeIndex(MTIndex<I>) noexcept {}
};
struct MTTest
{
private:
virtual void setupThreadLocal(std::size_t index) noexcept = 0;
virtual void onSetup() noexcept = 0;
virtual void onTeardown() noexcept = 0;
virtual void resetState() noexcept = 0;
virtual std::size_t numEntries() const noexcept = 0;
virtual std::string testName() const noexcept = 0;
static inline thread_local void (*testFunc)();
static inline thread_local void *testClass;
public:
using Result = int;
static inline Result result;
MTTest() = default;
virtual ~MTTest() = default;
private:
template <class TestClass, class = void>
struct HasSetup : std::false_type
{
};
template <class TestClass>
struct HasSetup<
TestClass, std::void_t<decltype(std::declval<TestClass>().setup())>>
: std::true_type
{
};
template <class TestClass, class = void>
struct HasTeardown : std::false_type
{
};
template <class TestClass>
struct HasTeardown<
TestClass, std::void_t<decltype(std::declval<TestClass>().teardown())>>
: std::true_type
{
};
template <class TestClass, std::size_t Begin = 0, class = void>
struct CountEntries : std::integral_constant<std::size_t, Begin>
{
};
template <class TestClass, std::size_t Begin>
struct CountEntries<TestClass, Begin,
std::void_t<decltype(std::declval<TestClass>().entry(
MTIndex<Begin>()))>>
: CountEntries<TestClass, Begin + 1>
{
};
template <class TestClass, class MTTest = MTTest>
struct MTTestImpl final : MTTest
{
MTTestImpl() noexcept : m_testClass() {}
MTTestImpl(MTTestImpl &&) = delete;
MTTestImpl(MTTestImpl const &) = delete;
private:
template <std::size_t... Is>
void setupThreadLocalImpl(std::size_t index,
std::index_sequence<Is...>) noexcept
{
testClass = &m_testClass;
testFunc = nullptr;
// 带 break 的静态 for 循环,第二步是通过 ... 搏杀暴徒
(void)((Is == index
? ((testFunc =
[]
{
static_cast<TestClass *>(testClass)->entry(
MTIndex<Is>());
}),
true)
: false) ||
...);
}
void setupThreadLocal(std::size_t index) noexcept override
{
// 带 break 的静态 for 循环需要分两步走,第一步是通过 make_index_sequence 领域展开
setupThreadLocalImpl(
index,
std::make_index_sequence<CountEntries<TestClass>::value>());
}
void onSetup() noexcept override
{
if constexpr (HasSetup<TestClass>::value)
{
m_testClass.setup();
}
}
void onTeardown() noexcept override
{
if constexpr (HasTeardown<TestClass>::value)
{
m_testClass.teardown();
}
}
void resetState() noexcept override
{
m_testClass.~TestClass();
new (&m_testClass) TestClass();
onSetup();
}
std::size_t numEntries() const noexcept override
{
static_assert(CountEntries<TestClass>::value > 0);
return CountEntries<TestClass>::value;
}
std::string testName() const noexcept override
{
std::string name = typeid(TestClass).name();
#if defined(__unix__) && __has_include(<cxxabi.h>)
char *demangled =
abi::__cxa_demangle(name.c_str(), nullptr, nullptr, nullptr);
name = demangled;
std::free(demangled);
#endif
return name;
}
alignas(64) TestClass m_testClass;
};
static std::string resultToString(Result result)
{
return std::to_string(result);
};
struct MTTestPool final
{
MTTestPool(std::unique_ptr<MTTest> testData, std::size_t repeats)
: m_threads(testData->numEntries()),
m_barrier(testData->numEntries() + 1),
m_repeats(repeats),
m_testData(std::move(testData))
{
std::size_t maxCores = std::thread::hardware_concurrency();
for (std::size_t i = 0; i < m_threads.size(); ++i)
{
m_threads[i] =
std::thread(&MTTestPool::testThread, this, i, i % maxCores);
}
m_statThread = std::thread(&MTTestPool::statisticThread, this,
m_threads.size() % maxCores);
}
void joinAll()
{
for (auto &&t : m_threads)
{
t.join();
}
m_statThread.join();
}
void showStatistics()
{
/* std::cout << "在测试 " << m_testData->testName() << " 中:\n"; */
/* for (auto &&[result, count]: m_statistics) { */
/* std::cout << " " << result << " 出现了 " << count << " 次\n"; */
/* } */
printf("在测试 %s 中:\n", m_testData->testName().c_str());
for (auto &&[result, count] : m_statistics)
{
printf(" %s 出现了 %zu 次\n", resultToString(result).c_str(), count);
}
}
private:
void setThisThreadAffinity(std::size_t cpuid)
{
// 绑定当前线程到指定 CPU 核心
#if defined(__unix__) && __has_include(<sched.h>) && __has_include(<unistd.h>)
cpu_set_t cpu;
CPU_ZERO(&cpu);
CPU_SET(cpuid, &cpu);
pid_t tid = syscall(SYS_gettid);
sched_setaffinity(tid, sizeof(cpu),
&cpu);
#elif defined(_WIN32) && __has_include(<windows.h>)
SetThreadAffinityMask(GetCurrentThread(), DWORD_PTR(1) << cpuid);
#endif
}
void testThread(std::size_t index, std::size_t cpuid) noexcept
{
// barrier 是为了保证所有线程尽可能同时开始运行,不要一前一后
// setAffinity 是为了绑定线程到不同的 CPU
// 核心上,保证线程之间是并行而不是并发
setThisThreadAffinity(cpuid);
m_testData->setupThreadLocal(index);
std::this_thread::yield();
for (int t = 0; t < 8; ++t)
{ // 热身运动
m_barrier.arrive_and_wait(); // 等待其他线程就绪
}
for (std::size_t i = 0; i < m_repeats; ++i)
{
testFunc();
m_barrier.arrive_and_wait(); // 等待统计线程开始
m_barrier.arrive_and_wait(); // 等待统计线程结束
}
}
void statisticThread(std::size_t cpuid) noexcept
{
setThisThreadAffinity(cpuid);
m_testData->onSetup(); // 初始化状态
for (int t = 0; t < 8; ++t)
{ // 热身运动
m_barrier.arrive_and_wait(); // 等待其他线程就绪
}
for (std::size_t i = 0; i < m_repeats; ++i)
{
m_barrier.arrive_and_wait(); // 等待其他线程结束
m_testData->onTeardown(); // 最终处理
++m_statistics[result]; // 将当前结果纳入统计
m_testData->resetState(); // 重置所有状态
result = Result(); // 重置结果
m_barrier.arrive_and_wait(); // 通知其他线程开始
}
}
std::vector<std::thread> m_threads;
std::thread m_statThread;
SpinBarrier m_barrier;
std::size_t const m_repeats;
std::unique_ptr<MTTest> const m_testData;
std::map<Result, std::size_t> m_statistics;
};
public:
template <class TestClass>
static void runTest(std::size_t repeats = 10000000)
{
MTTestPool pool(std::make_unique<MTTestImpl<TestClass>>(), repeats);
pool.joinAll();
pool.showStatistics();
}
};
多线程框架编译运行脚本
#!/bin/bash
FILE=
SYMBOL=
DUMP=false
RUN=false
DEBUG=false
RELEASE=false
HELP=false
ARGV0="$0"
while :; do
case "$1" in
--file)
FILE="$2"
shift 2;;
--dump-symbol)
SYMBOL="$2"
DUMP=true
shift 2;;
--dump)
DUMP=true
shift;;
--debug)
DEBUG=true
shift;;
--release)
RELEASE=true
shift;;
--run)
RUN=true
shift;;
--help)
HELP=true
shift;;
*)
break;;
esac
done
if $HELP || [ -z $FILE ]; then
echo "Usage: $ARGV0 --file <file> [--dump | --dump-symbol <symbol>] [--run] [--debug] [--release] [--help]"
exit 0
fi
if ! $DUMP && ! $RUN; then
RUN=true
fi
CXX=/usr/local/gcc-13.2.0/bin/g++
if $DEBUG; then
CXXFLAGS=(-std=c++20 -lpthread -O0)
elif $RELEASE; then
CXXFLAGS=(-std=c++20 -lpthread -O3)
elif [ -z $CXXFLAGS ]; then
CXXFLAGS=(-std=c++20 -lpthread -O1)
fi
textdump() {
local OBJ="${1?file}"
local KEY="$2"
if [ "x" == "x$KEY" ]; then
kg() {
grep -Pv '^([^\(\)]+ )?std::' | grep -v '\.cold$' | grep -v '^main$' | grep -v '^__' | grep -v '^decltype (.*) std::' | grep -Pv '^operator (new|delete)' | grep -v 'SpinBarrier::' | grep -v '^init_have_lse_atomics$'
}
else
kg() {
local tmp="$(mktemp)"
cat > $tmp
grep "^$KEY\$" $tmp || grep "^$KEY" $tmp || grep "$KEY" $tmp
rm -f $tmp
}
fi
# objdump -Ct "$OBJ" -j.text
if [ "xx86_64" == "x$(uname -m)" ]; then
objdump -Ct "$OBJ" -j.text | grep -P '^[0-9a-f]{16}\s+[glw]' | sort | awk -F '\t' '{print $2}' | sed 's/[0-9a-f]\{16\}\s\+//' | grep -Pv '^\.hidden ' | grep -Pv '^_start(_main)?$' | grep -Pv '^(lib)?unwind[_:]' | grep -Pv 'MTTest::' | kg | sort | uniq | xargs -d'\n' -i objdump -Cd "$OBJ" --section=.text --disassembler-color=on -Mintel --disassemble="{}" | grep -Pv '^Disassembly of section ' | grep -Pv "^$OBJ:\\s+file format elf" | grep -Pv '^$' | sed -e 's/\(BYTE\|[A-Z]\{1,3\}WORD\) PTR/\x1b[36m\L\1\x1b[0m/g' | sed -e 's/\(byte\|[a-z]\{1,3\}word\)\x1b\[0m \[/\1\x1b\[0m\[/g' | sed -e 's/\(^[0-9a-f]\{16\} <\)\(.*\)\(>:$\)/\x0a\1\x1b[32m\2\x1b[0m\3/' | sed -e 's/\(# [0-9a-f]\{1,16\} <\)\(.*\)\(>\)/\1\x1b[32m\2\x1b[0m\3/' | sed -e 's/::entry(MTIndex<\([0-9]\+\)ul>)/::entry\1/g' #| tee "$DUMP"
else
objdump -Ct "$OBJ" -j.text | grep -P '^[0-9a-f]{16}\s+[glw]' | sort | awk -F '\t' '{print $2}' | sed 's/[0-9a-f]\{16\}\s\+//' | grep -Pv '^\.hidden ' | grep -Pv '^_start(_main)?$' | grep -Pv '^(lib)?unwind[_:]' | grep -Pv 'MTTest::' | kg | sort | uniq | xargs -d'\n' -i objdump -Cd "$OBJ" --section=.text --disassembler-color=on --disassemble="{}" | grep -Pv '^Disassembly of section ' | grep -Pv "^$OBJ:\\s+file format elf" | grep -Pv '^$' | sed -e 's/\(^[0-9a-f]\{16\} <\)\(.*\)\(>:$\)/\x0a\1\x1b[32m\2\x1b[0m\3/' | sed -e 's/\(# [0-9a-f]\{1,16\} <\)\(.*\)\(>\)/\1\x1b[32m\2\x1b[0m\3/' | sed -e 's/::entry(MTIndex<\([0-9]\+\)ul>)/::entry\1/g' #| tee "$DUMP"
fi
#sed -i 's/\x1b\[[0-9]\+m//g' "$DUMP"
}
OUT="$(mktemp)"
echo "-- 编译选项:$CXX ${CXXFLAGS[@]}"
if $DUMP; then
oldfile="$FILE"
FILE="$(mktemp)"
sed -e 's/^\(\s*\)\(void entry(MT\(Range\)\?Index<[0-9]\+>)\)/\1[[gnu::noinline]] \2/' "$oldfile" > "$FILE"
CXXFLAGS+=(-x c++ -I.)
fi
if "$CXX" "${CXXFLAGS[@]}" "$FILE" -o "$OUT"; then
if $RUN; then
echo "-- 正在测试..."
"$OUT"
fi
if $DUMP; then
textdump "$OUT" "$SYMBOL"
fi
fi
rm -f "$OUT"
CacheLine保证内存序的验证代码和4次结果
#include <iostream>
#include <atomic>
#include "mtpool.hpp"
using namespace std;
struct Test1
{
char data1 = 0;
char data2 = 0;
char r1 = 0;
char r2 = 0;
};
struct Test2
{
char data1 = 0;
char s1[512];
char data2 = 0;
char s2[512];
char r1 = 0;
char s3[512];
char r2 = 0;
};
struct TestNativeSameCacheLine
{
Test1 tt;
void entry(MTIndex<0>) // 0 号线程
{
tt.data2 = 1;
tt.r2 = tt.data1;
}
void entry(MTIndex<1>) // 1 号线程
{
tt.data1 = 1;
tt.r1 = tt.data2;
}
void teardown()
{
MTTest::result = tt.r1 + tt.r2;
}
};
struct TestNativeNonSameCacheLine
{
Test2 tt;
void entry(MTIndex<0>) // 0 号线程
{
tt.data2 = 1;
tt.r2 = tt.data1;
}
void entry(MTIndex<1>) // 1 号线程
{
tt.data1 = 1;
tt.r1 = tt.data2;
}
void teardown()
{
MTTest::result = tt.r1 + tt.r2;
}
};
struct TestAtomicAcquireReleaseSameCacheline
{
atomic<int> x{0};
atomic<int> y{0};
int r1;
int r2;
void entry(MTIndex<0>)
{ // 0 号线程
y.store(1, memory_order_release);
r1 = x.load(memory_order_acquire);
}
void entry(MTIndex<1>)
{ // 1 号线程
x.store(1, memory_order_release);
r2 = y.load(memory_order_acquire);
}
void teardown()
{
MTTest::result = r1 + r2;
}
};
struct TestAtomicAcquireReleaseNonSameCacheline
{
atomic<int> x{0};
atomic<int> y{0};
int r1;
int r2;
void entry(MTIndex<0>)
{ // 0 号线程
y.store(1, memory_order_release);
r1 = x.load(memory_order_acquire);
}
void entry(MTIndex<1>)
{ // 1 号线程
x.store(1, memory_order_release);
r2 = y.load(memory_order_acquire);
}
void teardown()
{
MTTest::result = r1 + r2;
}
};
struct TestAtomicRelaxedSameCacheline
{
atomic<int> x{0};
char s1[512];
atomic<int> y{0};
char s2[512];
int r1;
char s3[512];
int r2;
void entry(MTIndex<0>)
{ // 0 号线程
y.store(1, memory_order_relaxed);
r1 = x.load(memory_order_relaxed);
}
void entry(MTIndex<1>)
{ // 1 号线程
x.store(1, memory_order_relaxed);
r2 = y.load(memory_order_relaxed);
}
void teardown()
{
MTTest::result = r1 + r2;
}
};
struct TestAtomicRelaxedNonSameCacheline
{
atomic<int> x{0};
char s1[512];
atomic<int> y{0};
char s2[512];
int r1;
char s3[512];
int r2;
void entry(MTIndex<0>)
{ // 0 号线程
y.store(1, memory_order_relaxed);
r1 = x.load(memory_order_relaxed);
}
void entry(MTIndex<1>)
{ // 1 号线程
x.store(1, memory_order_relaxed);
r2 = y.load(memory_order_relaxed);
}
void teardown()
{
MTTest::result = r1 + r2;
}
};
int main()
{
cout << sizeof(Test1) << endl;
cout << sizeof(Test2) << endl;
MTTest::runTest<TestNativeSameCacheLine>();
MTTest::runTest<TestNativeNonSameCacheLine>();
MTTest::runTest<TestAtomicAcquireReleaseSameCacheline>();
MTTest::runTest<TestAtomicAcquireReleaseNonSameCacheline>();
MTTest::runTest<TestAtomicRelaxedSameCacheline>();
MTTest::runTest<TestAtomicRelaxedNonSameCacheline>();
return 0;
}
/*
$./run.sh --file t0.cpp
-- 编译选项:/usr/local/gcc-13.2.0/bin/g++ -std=c++20 -lpthread -O1
-- 正在测试...
4
1540
在测试 TestNativeSameCacheLine 中:
0 出现了 7042864 次
1 出现了 2957134 次
2 出现了 2 次
在测试 TestNativeNonSameCacheLine 中:
0 出现了 148012 次
1 出现了 9851728 次
2 出现了 260 次
在测试 TestAtomicAcquireReleaseSameCacheline 中:
1 出现了 9999993 次
2 出现了 7 次
在测试 TestAtomicAcquireReleaseNonSameCacheline 中:
1 出现了 9999999 次
2 出现了 1 次
在测试 TestAtomicRelaxedSameCacheline 中:
0 出现了 131425 次
1 出现了 9868296 次
2 出现了 279 次
在测试 TestAtomicRelaxedNonSameCacheline 中:
0 出现了 131355 次
1 出现了 9868381 次
2 出现了 264 次
$./run.sh --file t0.cpp
-- 编译选项:/usr/local/gcc-13.2.0/bin/g++ -std=c++20 -lpthread -O1
-- 正在测试...
4
1540
在测试 TestNativeSameCacheLine 中:
0 出现了 1839668 次
1 出现了 8160328 次
2 出现了 4 次
在测试 TestNativeNonSameCacheLine 中:
0 出现了 104575 次
1 出现了 9895150 次
2 出现了 275 次
在测试 TestAtomicAcquireReleaseSameCacheline 中:
1 出现了 9999993 次
2 出现了 7 次
在测试 TestAtomicAcquireReleaseNonSameCacheline 中:
1 出现了 9999995 次
2 出现了 5 次
在测试 TestAtomicRelaxedSameCacheline 中:
0 出现了 205275 次
1 出现了 9794003 次
2 出现了 722 次
在测试 TestAtomicRelaxedNonSameCacheline 中:
0 出现了 147314 次
1 出现了 9852374 次
2 出现了 312 次
$./run.sh --file t0.cpp
-- 编译选项:/usr/local/gcc-13.2.0/bin/g++ -std=c++20 -lpthread -O1
-- 正在测试...
4
1540
在测试 TestNativeSameCacheLine 中:
0 出现了 3949348 次
1 出现了 6050651 次
2 出现了 1 次
在测试 TestNativeNonSameCacheLine 中:
0 出现了 222745 次
1 出现了 9776828 次
2 出现了 427 次
在测试 TestAtomicAcquireReleaseSameCacheline 中:
1 出现了 9999996 次
2 出现了 4 次
在测试 TestAtomicAcquireReleaseNonSameCacheline 中:
1 出现了 9999995 次
2 出现了 5 次
在测试 TestAtomicRelaxedSameCacheline 中:
0 出现了 294870 次
1 出现了 9704803 次
2 出现了 327 次
在测试 TestAtomicRelaxedNonSameCacheline 中:
0 出现了 245375 次
1 出现了 9754405 次
2 出现了 220 次
$./run.sh --file t0.cpp
-- 编译选项:/usr/local/gcc-13.2.0/bin/g++ -std=c++20 -lpthread -O1
-- 正在测试...
4
1540
在测试 TestNativeSameCacheLine 中:
0 出现了 2986257 次
1 出现了 7013741 次
2 出现了 2 次
在测试 TestNativeNonSameCacheLine 中:
0 出现了 30421 次
1 出现了 9969373 次
2 出现了 206 次
在测试 TestAtomicAcquireReleaseSameCacheline 中:
1 出现了 9999997 次
2 出现了 3 次
在测试 TestAtomicAcquireReleaseNonSameCacheline 中:
1 出现了 9999992 次
2 出现了 8 次
在测试 TestAtomicRelaxedSameCacheline 中:
0 出现了 26357 次
1 出现了 9973511 次
2 出现了 132 次
在测试 TestAtomicRelaxedNonSameCacheline 中:
0 出现了 23634 次
1 出现了 9976255 次
2 出现了 111 次
*/
操作系统和cpu信息
$uname -r
4.19.91-007.ali4000.alios7.aarch64
$lscpu
Architecture: aarch64
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 1
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 4
Model: 0
CPU max MHz: 2600.0000
CPU min MHz: 200.0000
BogoMIPS: 200.00
L1d cache: 64K
L1i cache: 64K
L2 cache: 512K
L3 cache: 65536K
NUMA node0 CPU(s): 0-31
NUMA node1 CPU(s): 32-63
NUMA node2 CPU(s): 64-95
NUMA node3 CPU(s): 96-127
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma dcpop asimddp asimdfhm
结束
参考cppreference和B站博主代码,下篇博客将会给出 Mutex 、Spinlock、无锁链表、无锁栈、无锁哈希表的实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号