




AnolisOS8.6系统少量代码快速布署DeepSeek-R1推理服务
先硬件准备,安装操作系统,安装显卡驱动。
检查环境
cat /etc/system-release --查看系统版本
nvidia-smi --查看显卡驱动
nvcc -V --检查CUDA
安装ollama
查看ollama官网,找查下载方法 https://ollama.com/download/linux
下载ollama并安装
curl -fsSL https://ollama.com/install.sh | sh
安装好后启动ollama
systemctl status ollama --检查Ollama服务状态 systemctl start ollama --启动Ollama ollama list --查看本地模型库列表 ollama ps --查看本地内存中,正在运行的模型
查看网站模型列表,选译适配本地显存的模型 https://ollama.com/library/
从官网远程仓库下载模型到本地并运行(ollama run deepseek-r1:1.5b)此方法测试时,官网的模型库下载太慢。这里不推荐。
推荐ModelScope模型,国内下载更快,一健下载并运行。
考虑网速和新手学习,建议先选择下载个1.1G小模型测试,测试成功后再下载DeepSeek-R1适配本地显卡的模型。
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF
命令行测试图片:
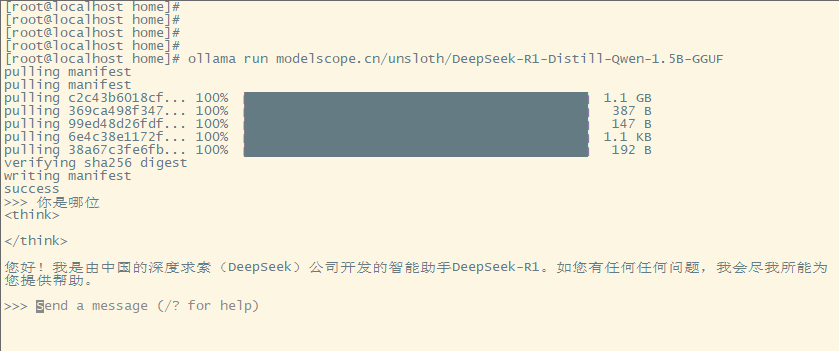
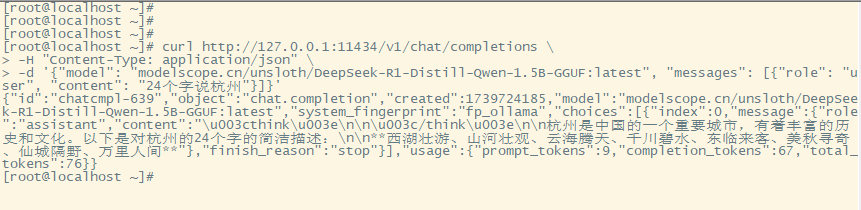
curl命令调用api测试
curl http://127.0.0.1:11434/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{"model": "modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:latest", "messages": [{"role": "user", "content": "24个字说杭州"}]}'
测试截图
配置ollama允许外部电脑访问
编辑参数,在[Service]下增加一行。
vim /etc/systemd/system/ollama.service 编辑
[Service] Environment="OLLAMA_HOST=0.0.0.0"
systemctl daemon-reload --重新加载配置
配置防火墙,允许访问11433端口
sudo firewall-cmd --permanent --zone=public --add-port=11434/tcp sudo firewall-cmd --reload
通过局域网用户电脑,进行测试
找一台用户的windows系统电脑,命令行测试
curl http://192.168.169.111:11434/v1/chat/completions -H "Content-Type: application/json" -d "{\"model\": \"modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:latest\", \"messages\": [{\"role\": \"user\", \"content\": \"24字说杭州\"}]}"
测试截图

通过局域网用户电脑,进行测试
找一台linux系统电脑,curl命令调用api测试
curl http://192.168.169.111:11434/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{"model": "modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:latest", "messages": [{"role": "user", "content": "24个字说杭州"}]}'
测试截图

测试完小模型,现在打开社区 https://www.modelscope.cn/models?libraries=GGUF&page=1&tabKey=libraries
选择适合自已显卡的DeepSeek-R1模型。
这里我选择,DeepSeek-R1-Distill-Qwen-14B-GGUF,大小9G。
一键下载运行
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF
运行成功截图

通过局域网用户电脑,进行测试
找一台用户的windows系统电脑,命令行测试
curl http://192.168.169.111:11434/v1/chat/completions -H "Content-Type: application/json" -d "{\"model\": \"modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF:latest\", \"messages\": [{\"role\": \"system\", \"content\": \"你是一位诗人\"}, {\"role\": \"user\", \"content\": \"24个字说杭州\"}]}"
回复正常,出参已经有推理链文字。

测试完成。
后续 其它
配置ollama模型目录进行迁移
mkdir /home/ollama-models/ --新建目录
mv /usr/share/ollama/.ollama/models /home/ollama-models/ --迁移目录
编辑参数
vim /etc/systemd/system/ollama.service 编辑
Environment="PATH=$PATH" "OLLAMA_HOST=0.0.0.0:11434" "OLLAMA_MODELS=/home/ollama-models/models" "OLLAMA_NUM_PARALLEL=6" "OLLAMA_ORIGINS=*"
systemctl daemon-reload --重新加载配置
systemctl start ollama --启动Ollama
systemctl status ollama --检查Ollama服务状态
Docker的安装
安装Docker运行环境
dnf config-manager --add-repo=https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
dnf install -y docker-ce
安装 NVIDIA Container Toolkit 支持 GPU 容器
dnf install -y nvidia-container-toolkit
重起docker
systemctl restart docker
查看docker运行情况
docker info
docker --version
其它安装
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF --DeepSeek-R1 1.5B 大小1.1G
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF --DeepSeek-R1 7B 大小4.7G
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF --DeepSeek-R1 14B 大小9G
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF --DeepSeek-R1 32B 大小19G
ollama run modelscope.cn/lmstudio-community/DeepSeek-R1-Distill-Llama-70B-GGUF --DeepSeek-R1 70B 大小42G
ollama run modelscope.cn/lmstudio-community/DeepSeek-R1-GGUF --DeepSeek-R1 满血版
以下是DeepSeek-R1模型显存需求及显卡建议的表格整理:
| 模型 | 文件大小 | 显存需求 | 推荐显卡 |
|---|---|---|---|
| 1.5B | 1.1G | ≥1GB | 入门级显卡(如GTX 1650、RTX 3050等) |
| 7B/8B | 4.7G | ≥4GB | 中端显卡(如RTX 3060、RTX 4060等) |
| 14B | 9G | ≥8GB | 高端显卡(如RTX 3080、RTX 4070等) |
| 32B | 19G | ≥18GB | 旗舰级显卡(如RTX 4090、A100等) |
| 70B | 42G | ≥140GB | 多卡并行(如8张A100 80G) |
| 671B 满血 | ≥320GB | 超算级配置(如多张A100或H100) |
Ollama 高阶配置
增加上下文窗口
假设你从Ollama上拉取了大模型,其默认的窗口大小只有2048。我们可以通过如下方法,提高上下文窗口。
生成的Modelfile
ollama show --modelfile qwen2:72b > Modelfile
我们看一下生成的Modelfile
vi Modelfile
然后在PARAMETER处增加如下配置,32768就是上下文窗口大小,设置成你想要的即可。注意增加上下文窗口可能增加显存的使用,谨慎增加。
PARAMETER num_ctx 32768
然后创建新模型即可
ollama create qwen2:72b-32k -f Modelfile
查看新建的模型
ollama list

 浙公网安备 33010602011771号
浙公网安备 33010602011771号