

Hadoop基础-HDFS数据清理过程之校验过程代码分析
Hadoop基础-HDFS数据清理过程之校验过程代码分析
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
想称为一名高级大数据开发工程师,不但需要了解hadoop内部的运行机制,还需要掌握hadoop在写入过程中的报文分析。当然代码的调试步骤是一个开发必须得会的技能!想要掌握这三个技能,我们就可以拿HDFS写入过程来练练手,了解一下平时就几行的代码在它的内部是如何帮我们实现数据传输的。
一.Idea代码调试简介
1>.编写测试代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.hdfs; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FSDataOutputStream; 10 import org.apache.hadoop.fs.FileSystem; 11 import org.apache.hadoop.fs.Path; 12 import org.apache.hadoop.io.IOUtils; 13 14 import java.io.FileInputStream; 15 import java.io.IOException; 16 17 public class WriterToHdfs { 18 public static void main(String[] args) throws IOException { 19 //设置访问hdfs的用户名为“yinzhengjie” 20 System.setProperty("HADOOP_USER_NAME","yinzhengjie"); 21 Configuration conf = new Configuration(); 22 FileSystem fs = FileSystem.get(conf); 23 //定义需要在hdfs中写入的路径,别忘记把core-site.xml文件放在resources目录下哟!并fs.defaultFS的值设置为"hdfs://s101:8020" 24 Path p = new Path("/yinzhengjie.sql"); 25 //通过fs对象create方法创建一个输出流,第一个参数是hdfs路径,第二个参数表示当hdfs中存在时是否覆盖 26 FSDataOutputStream fos = fs.create(p,true); 27 FileInputStream fis = new FileInputStream("D:\\10.Java\\IDE\\yhinzhengjieData\\MyHadoop\\yinzhengjie.sql"); 28 //通过hadoop提供的IOUtils工具类对拷数据 29 IOUtils.copyBytes(fis,fos,1024); 30 fis.close(); 31 fos.close(); 32 } 33 }
2>.进入调试模式
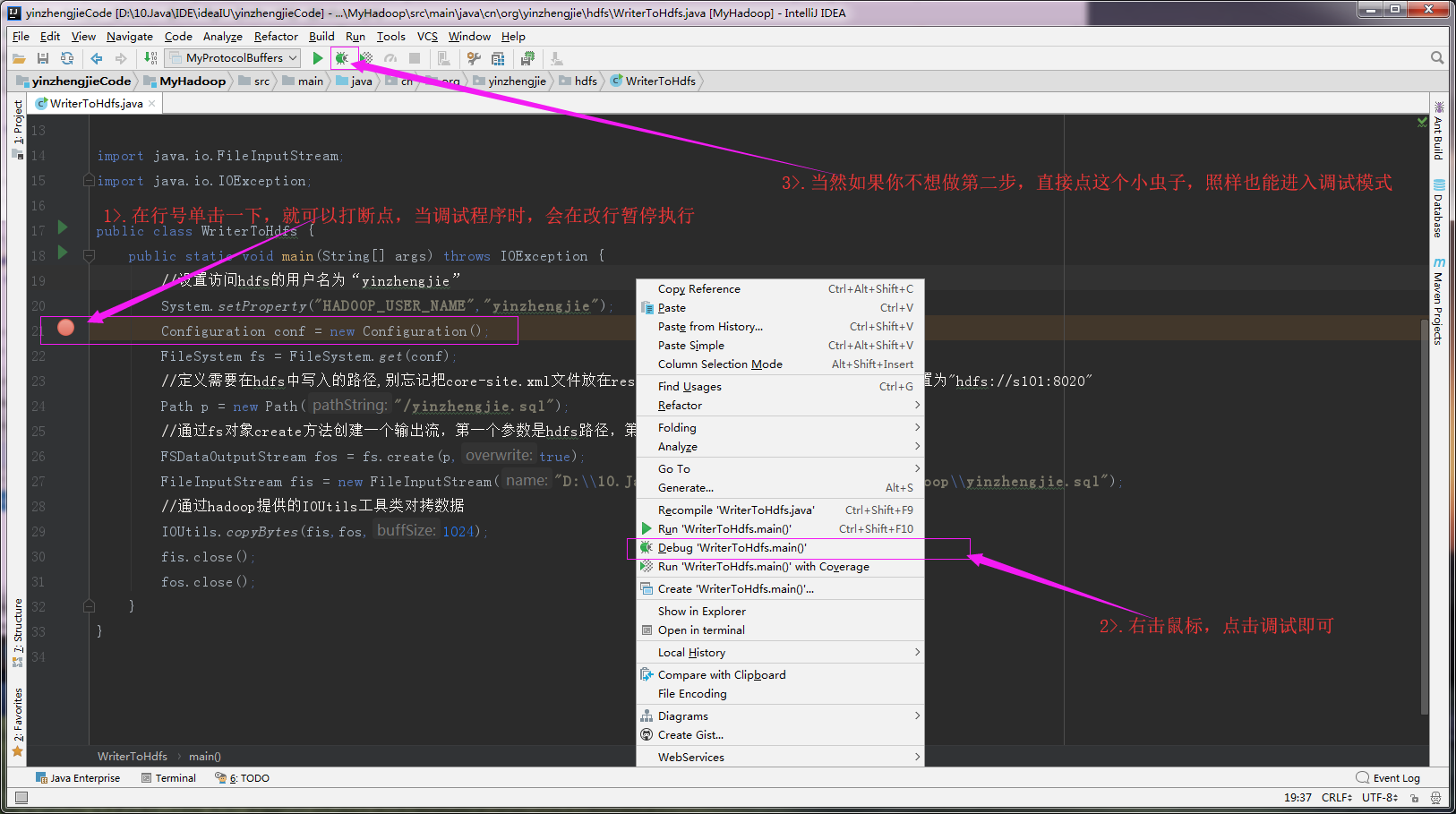
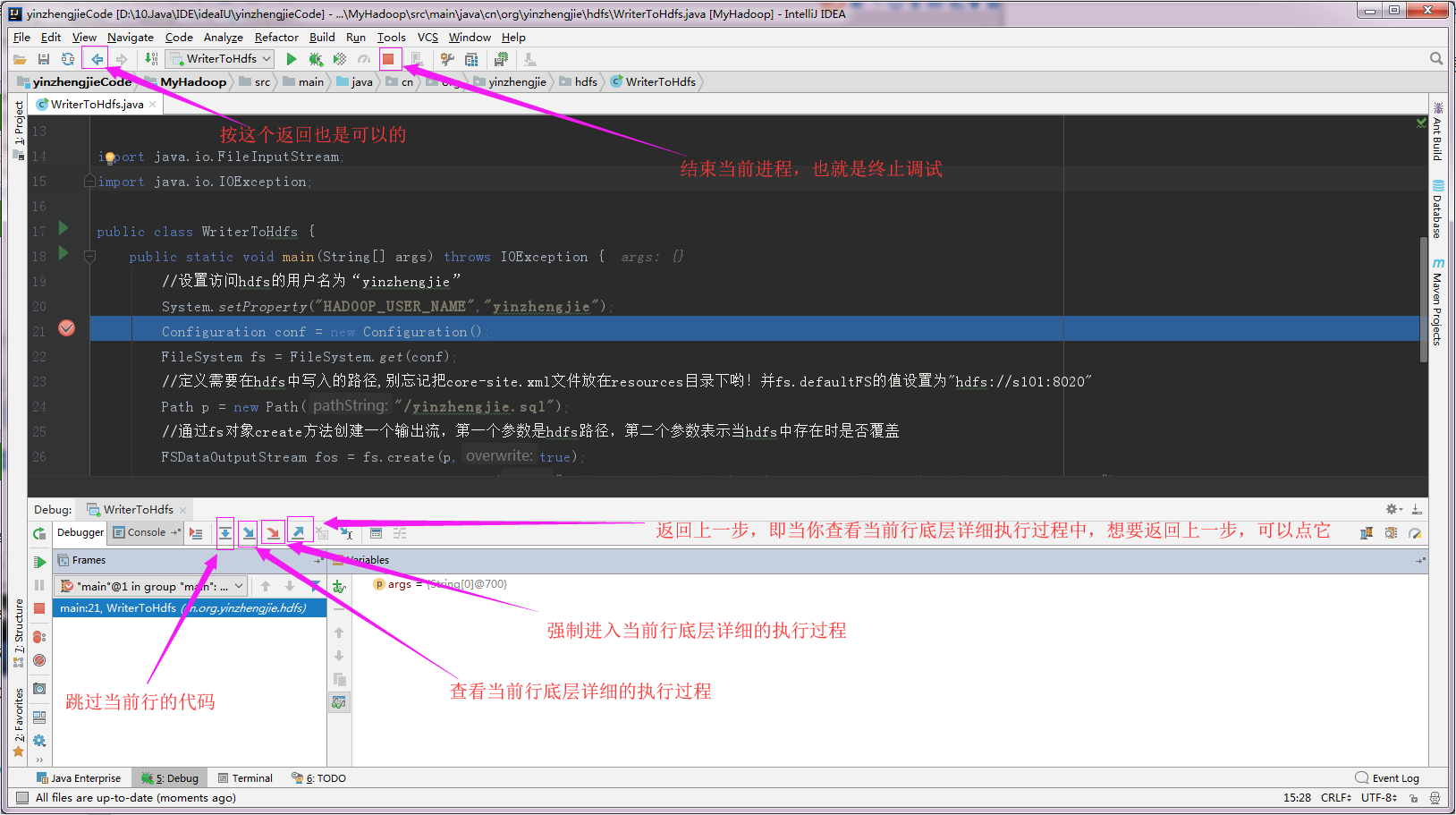
3>.查看源码执行过程,流程控制按键介绍:
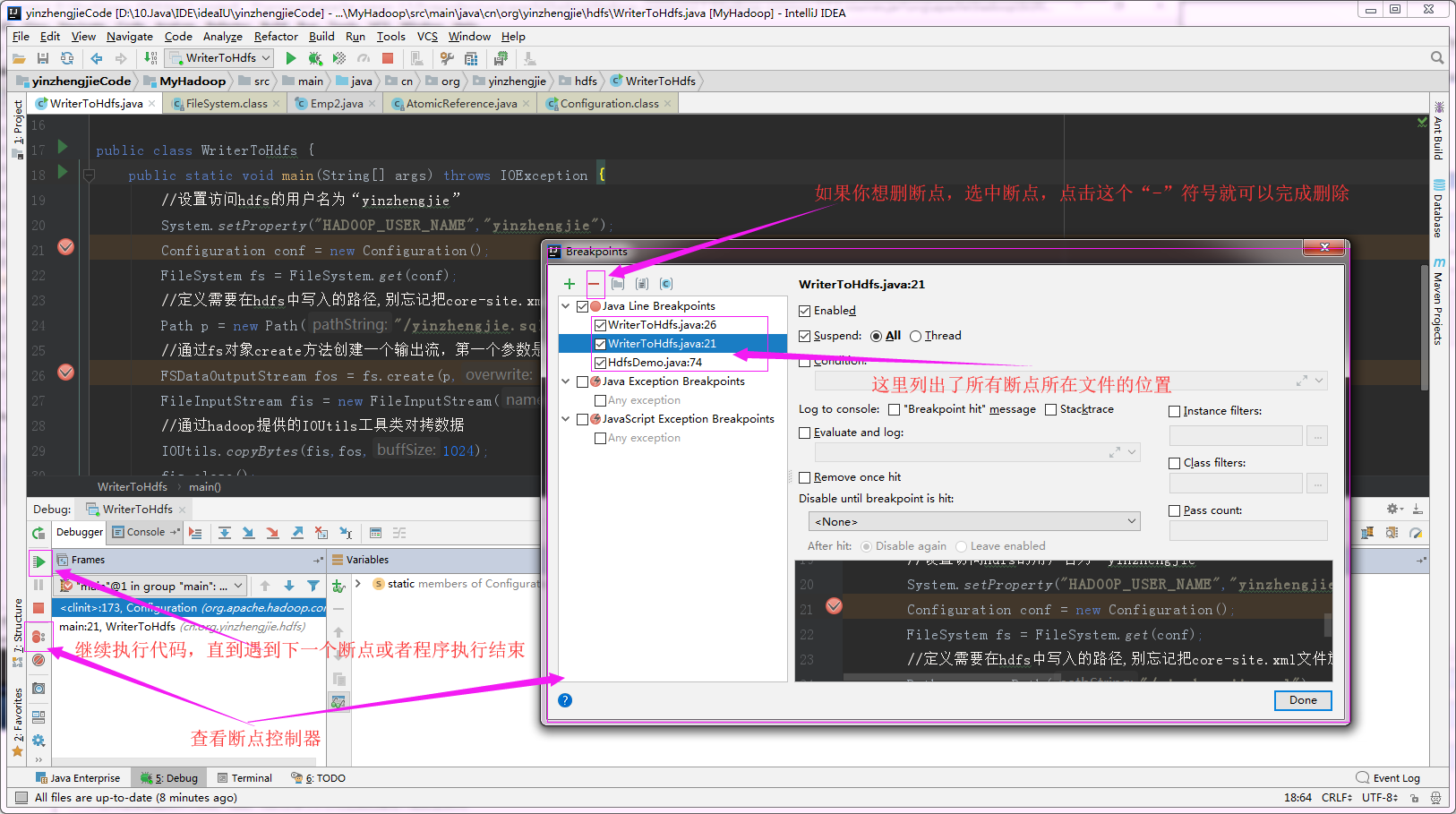
4>.断点列表管理
二.查看 “FileSystem fs = FileSystem.get(conf)” 的由来
1>.查看conf的返回值
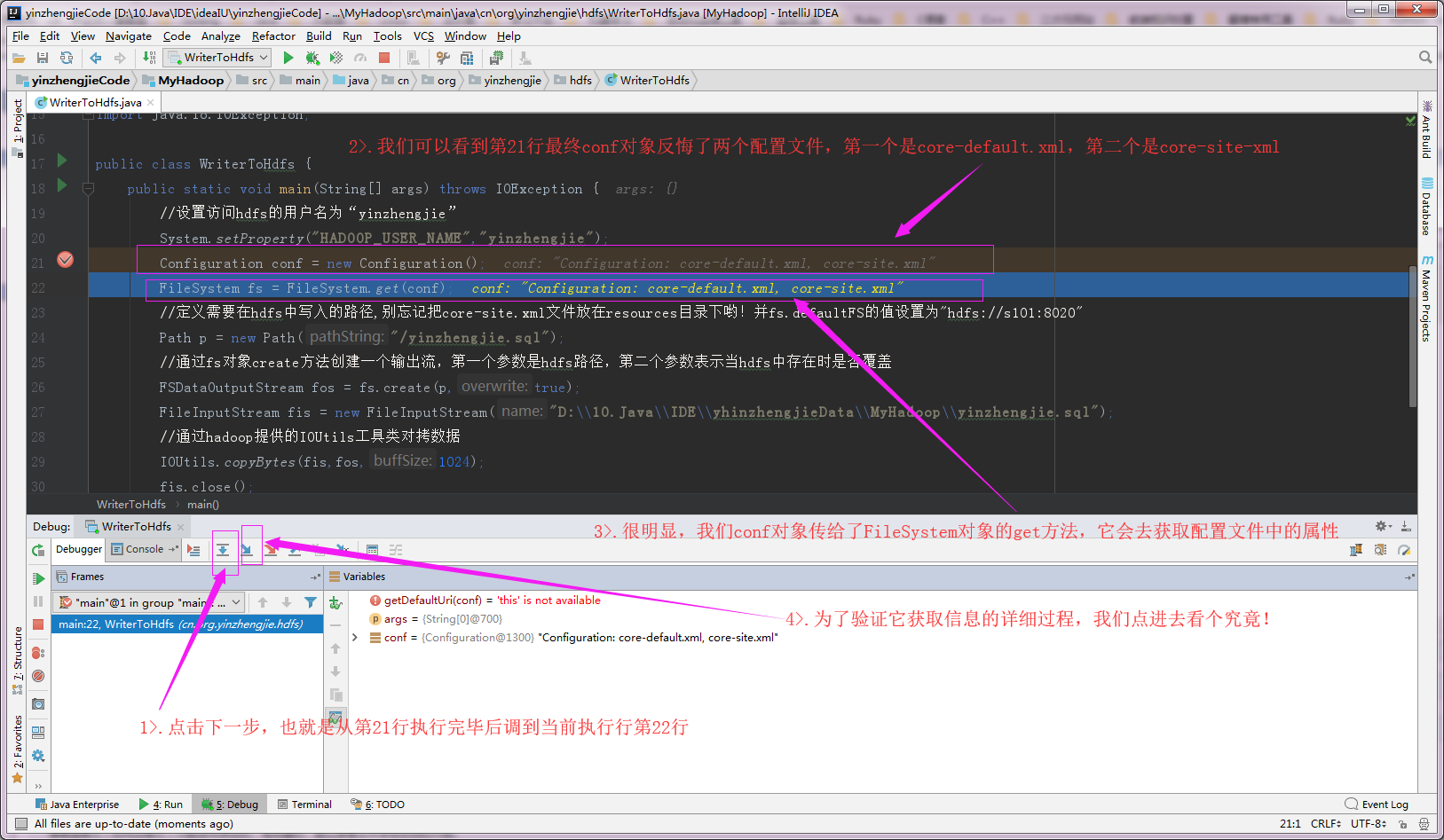
2>.进入“FileSystem.get”方法(我们需要在return那一行右击就可以弹出图中的对话框,其实不用刻意去选中getDefaultUri)
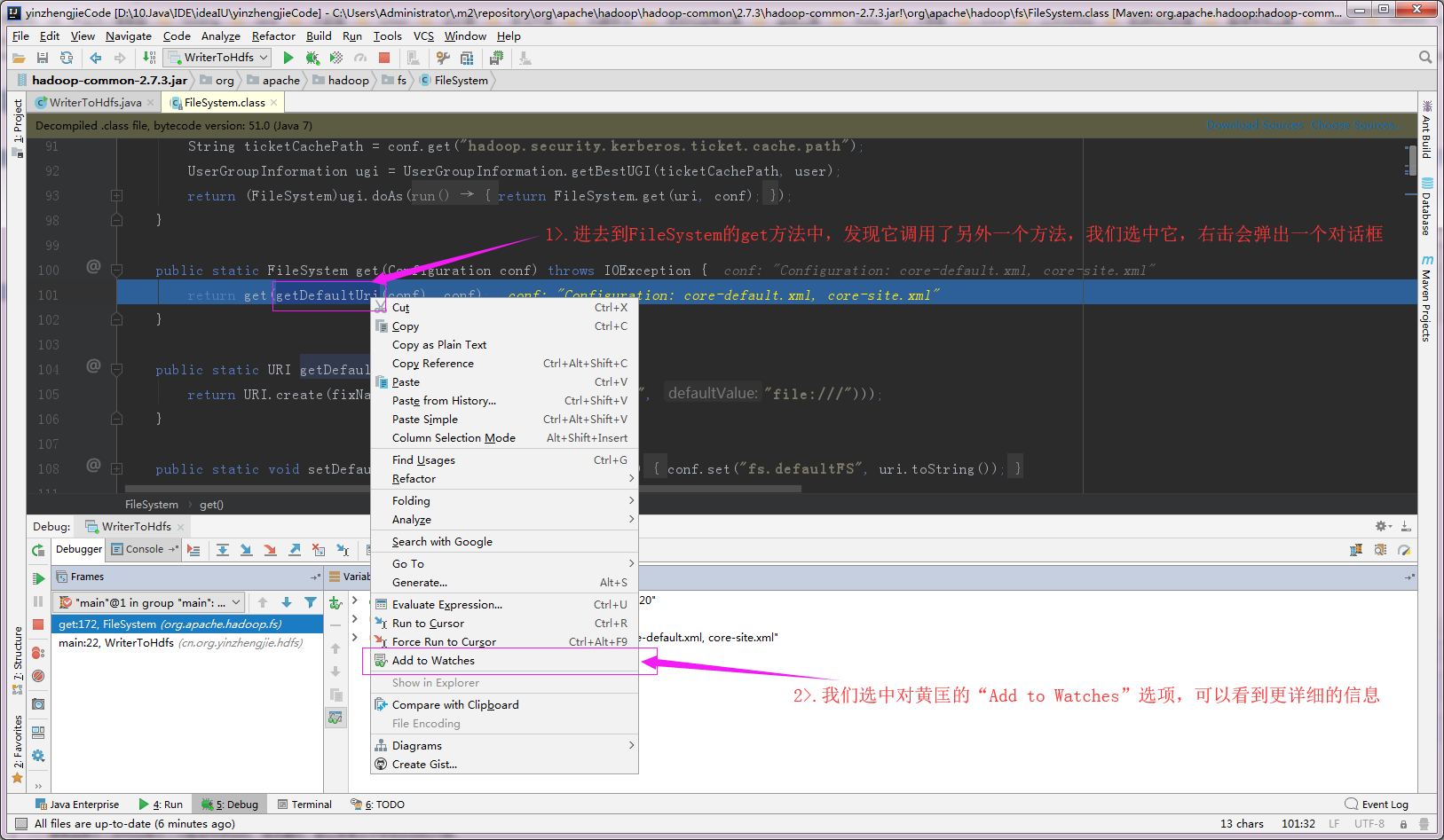
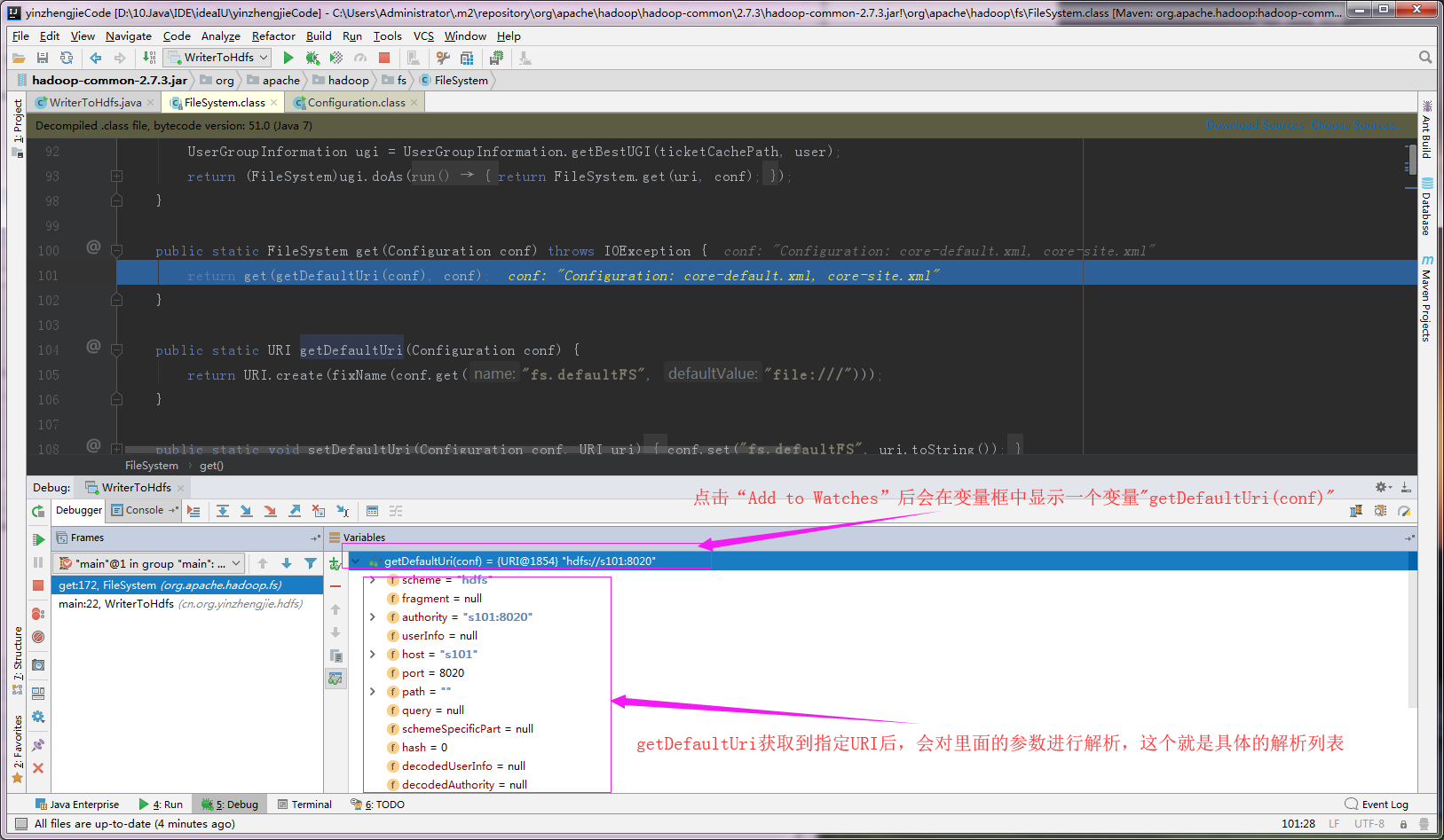
3>.查看“getDefaultUri(conf)”返回的参数
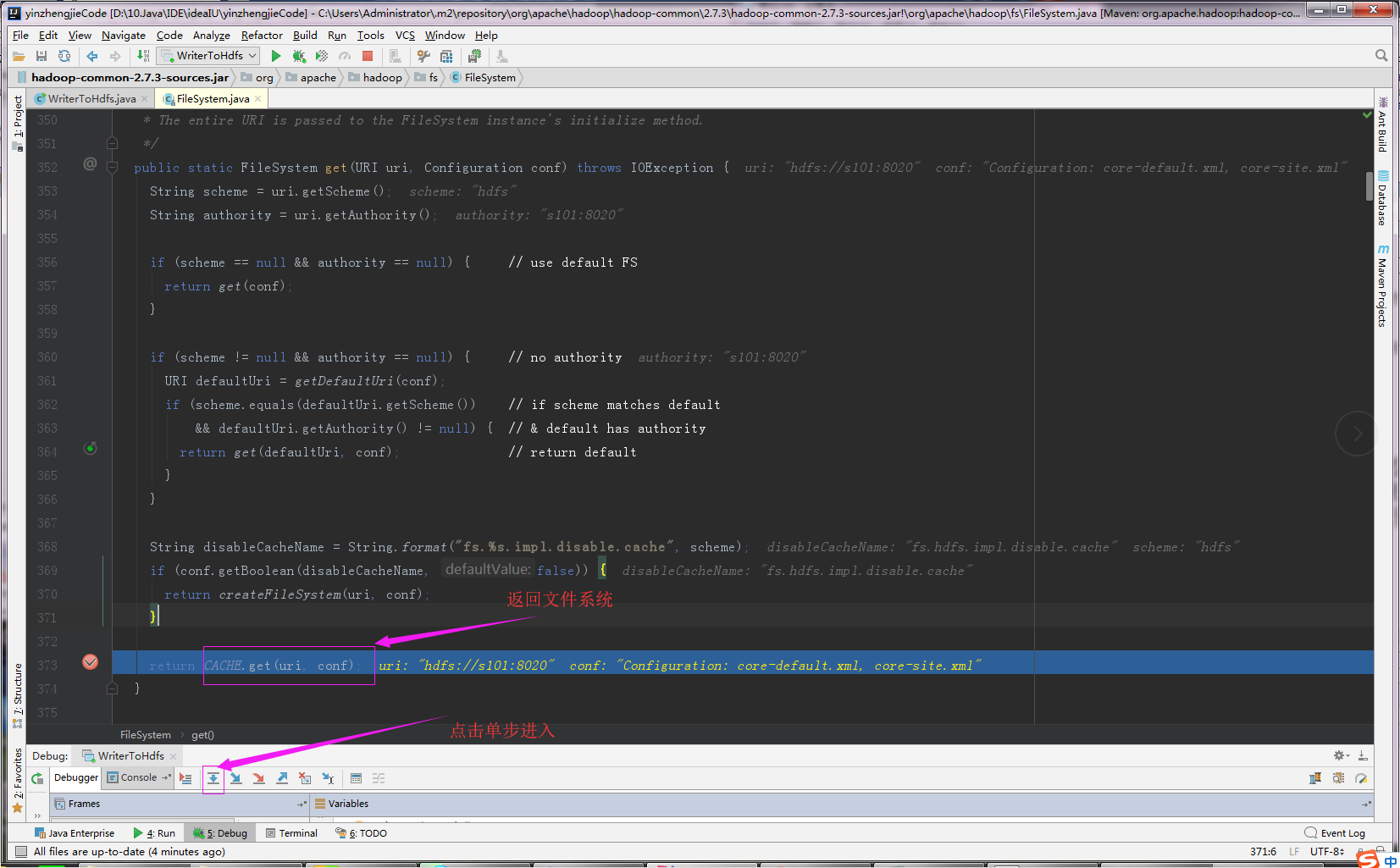
4>.通过“CACHE.get(uri, conf)”返回文件系统
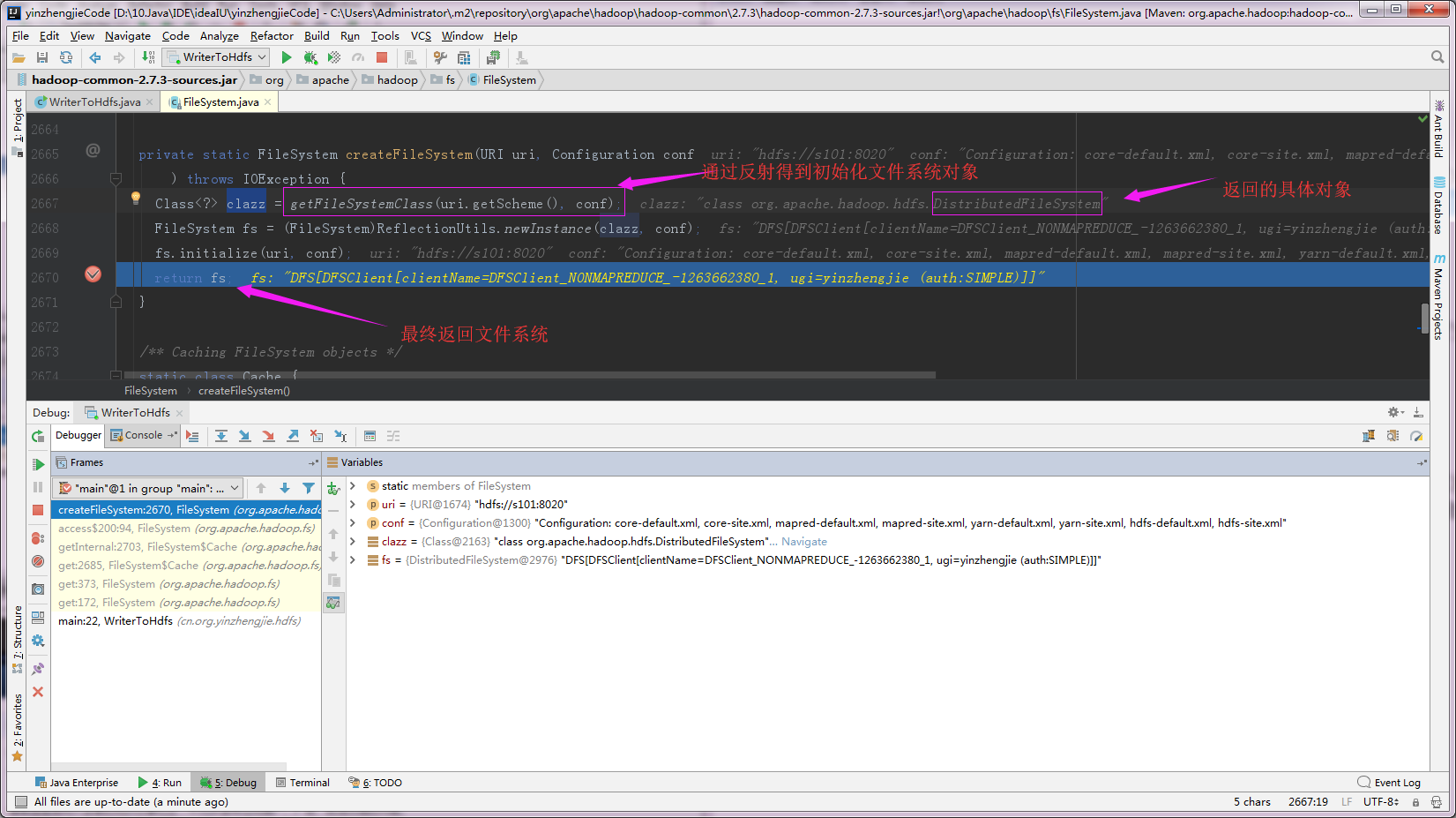
5>.返回文件系统
三.查看“fs.create(p, true)”创建流的详细过程
1>.单步进入“fs.create(p, true)”创建流
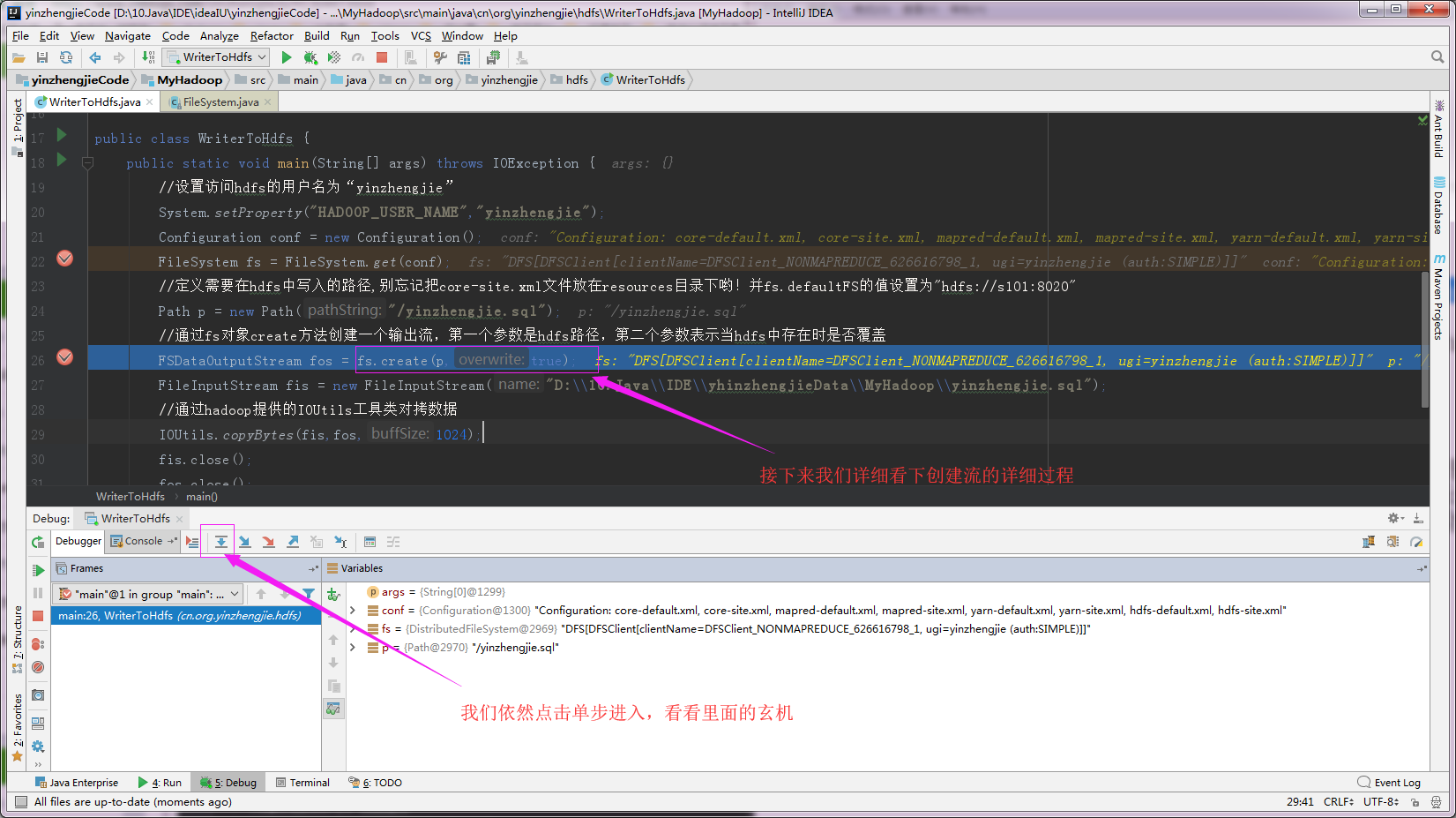
2>.经过断电跟踪,发现最后返回的是HDFSOutputStream,也就是创建流,此时还没有真正的写入数据
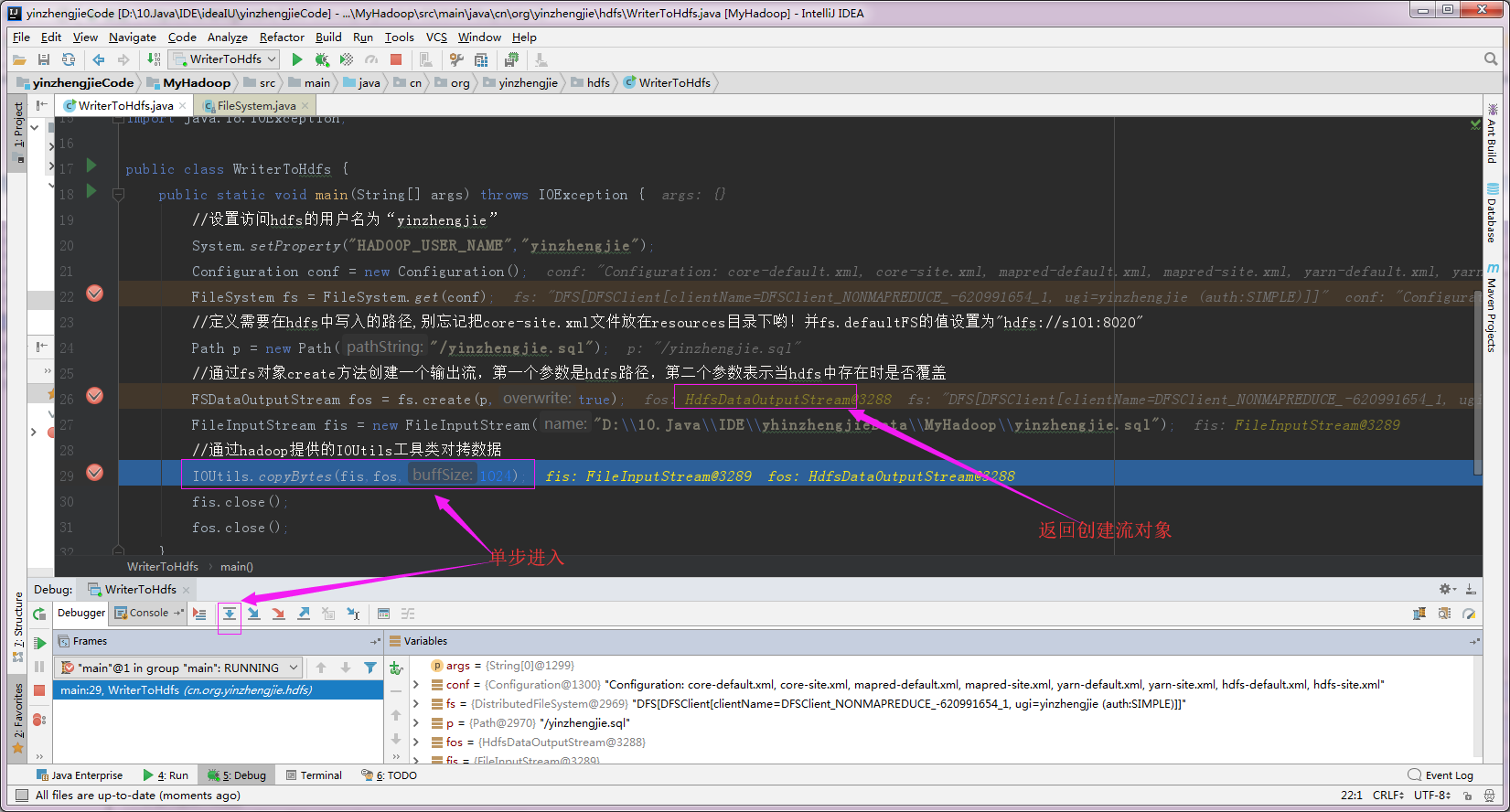
3>.在写入过程中进入到write1方法
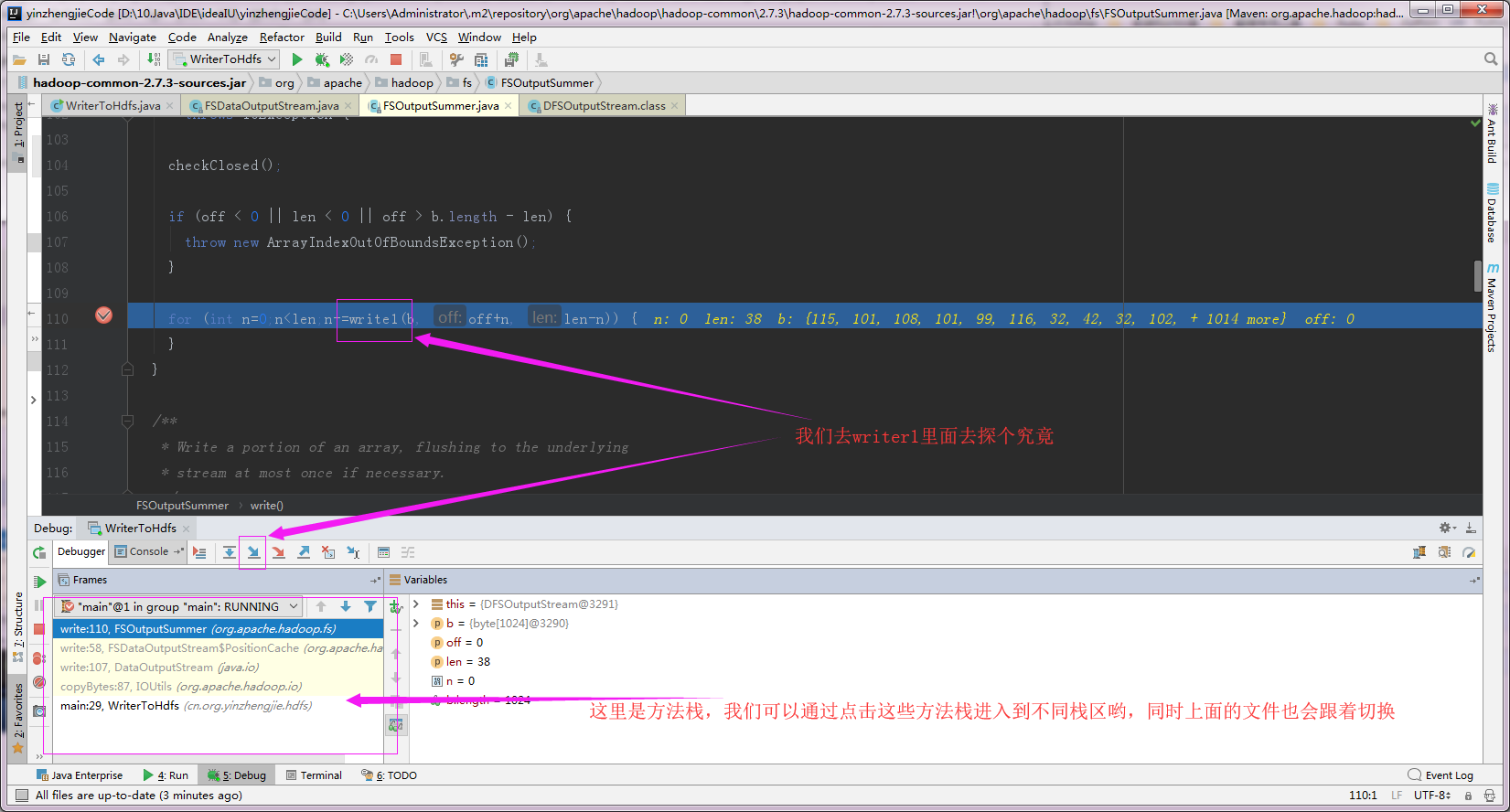
4>.再进入到FlushBuffer,目的是清理chunk
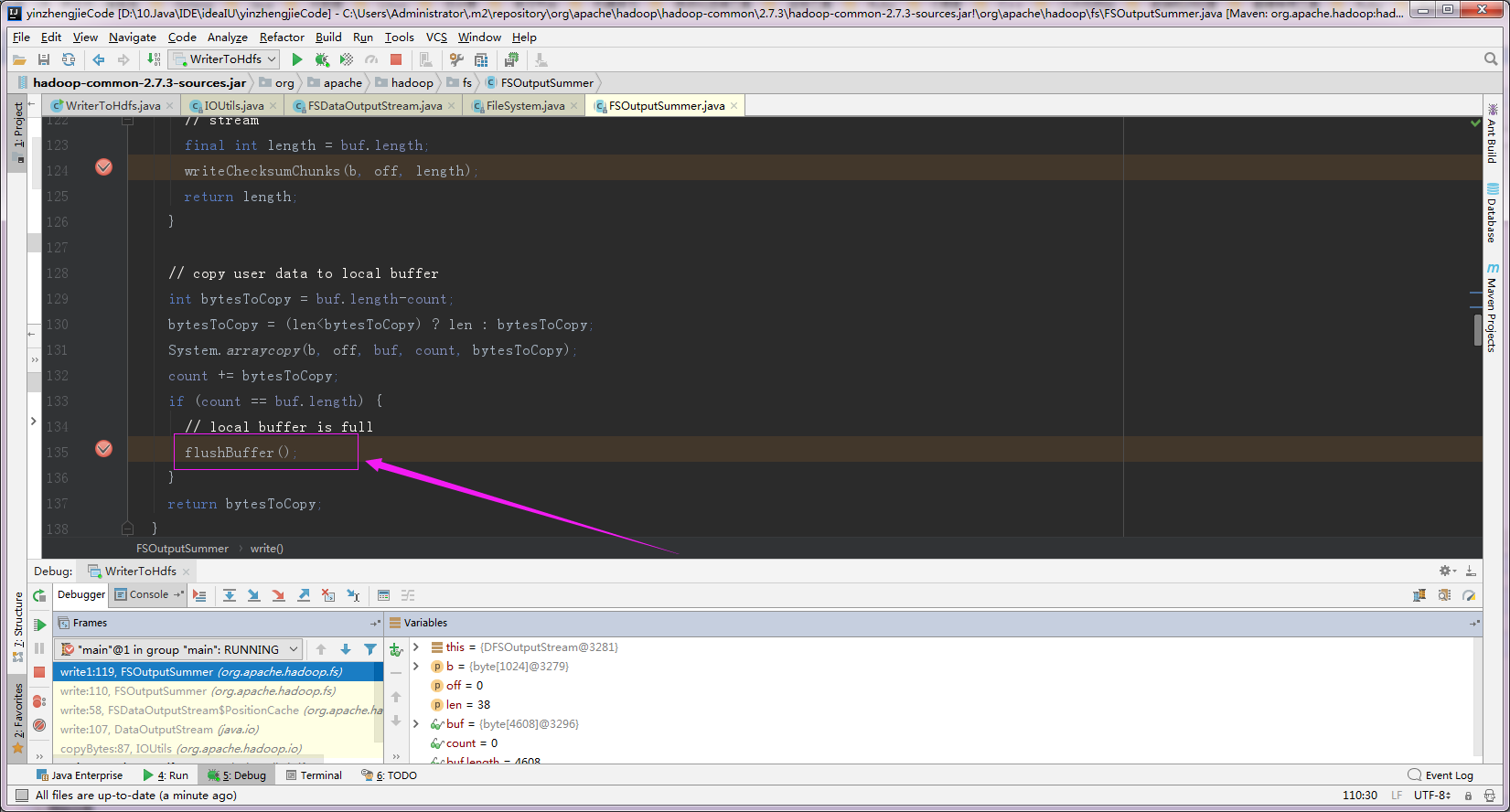
5>.验证chunk大小为512字节
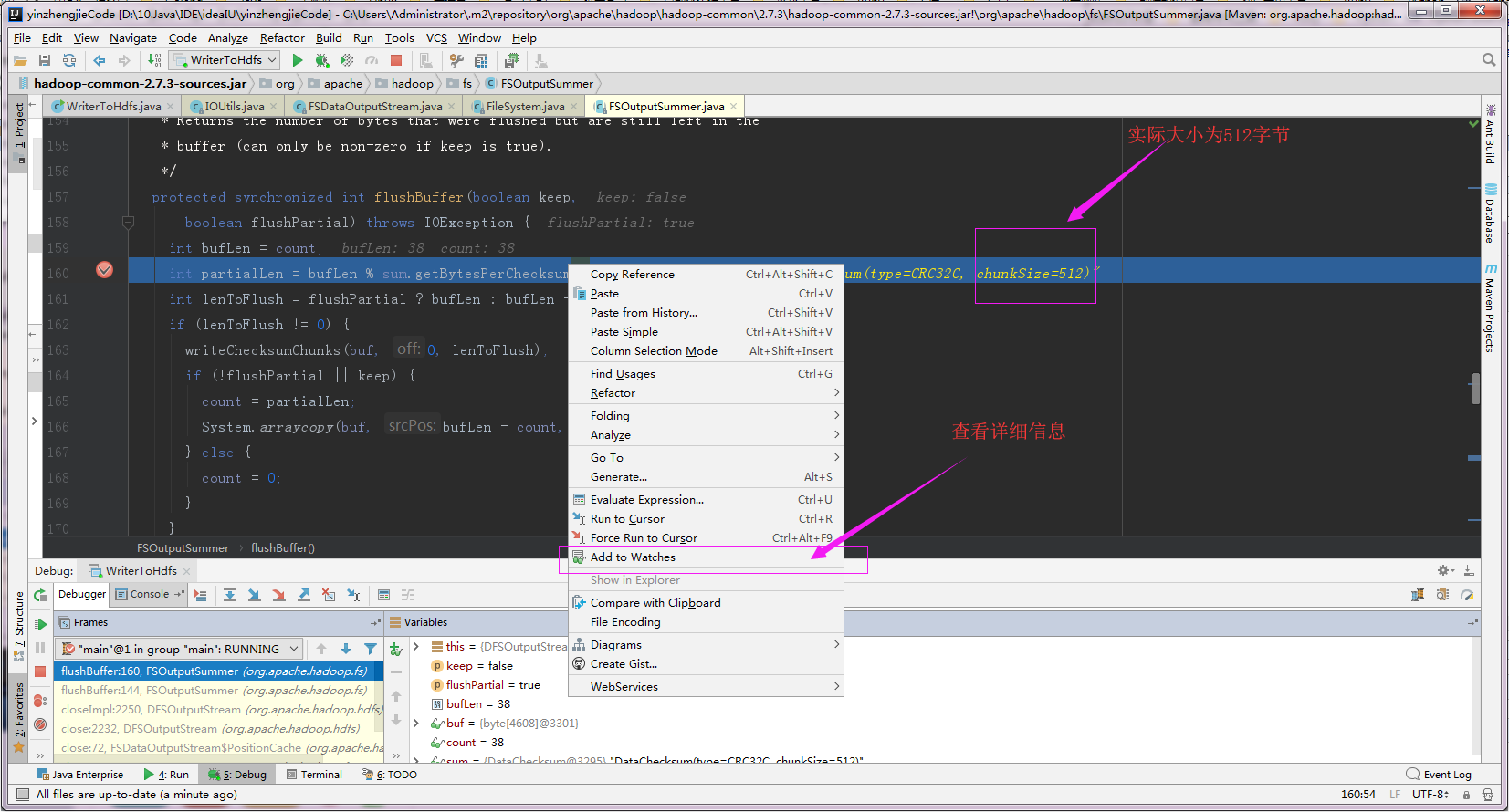
6>.我们通过打断点的方式查出来chunk的大小为512字节,这个大小意思的是每个512字节就会进行一次校验。
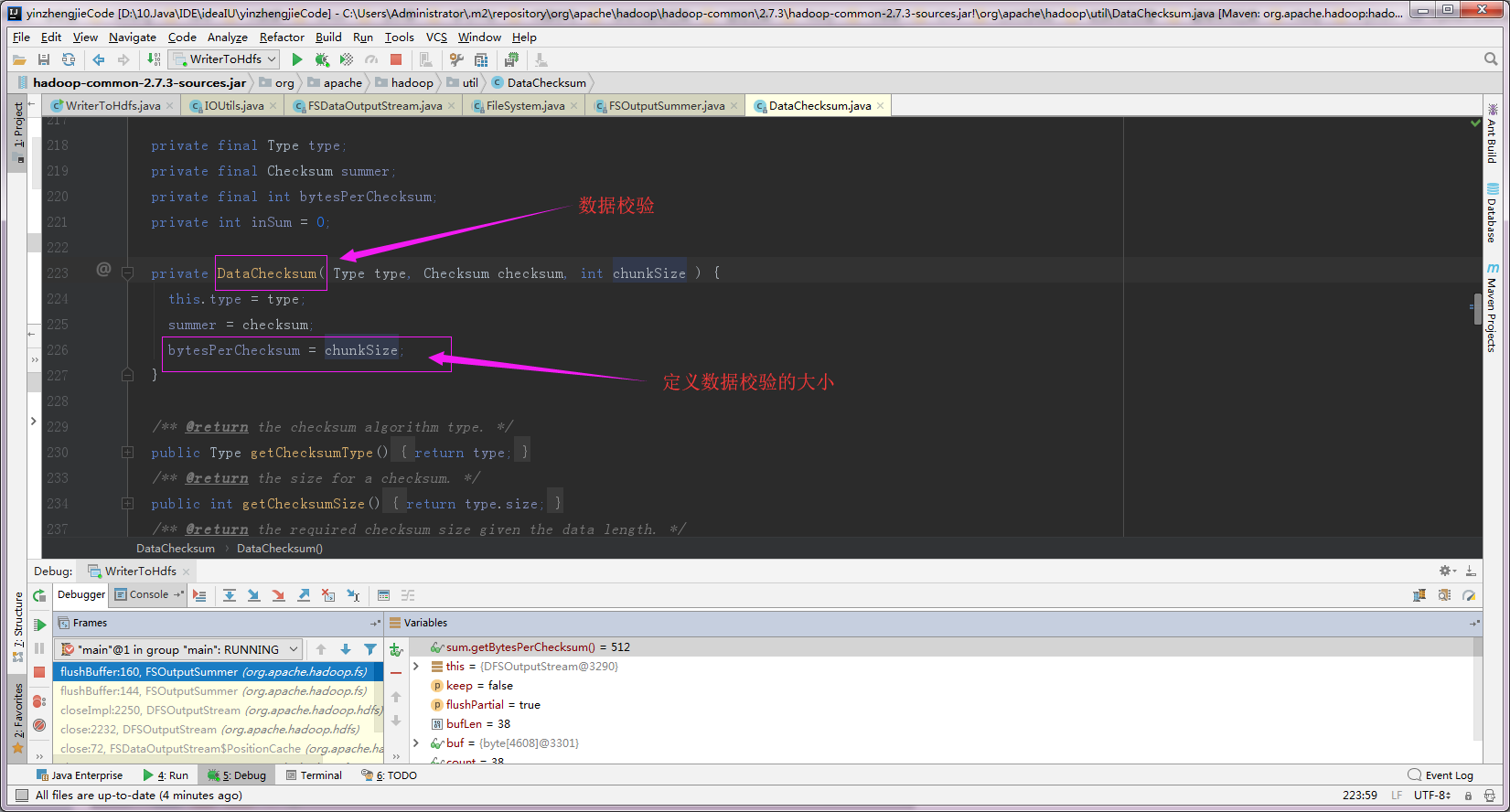
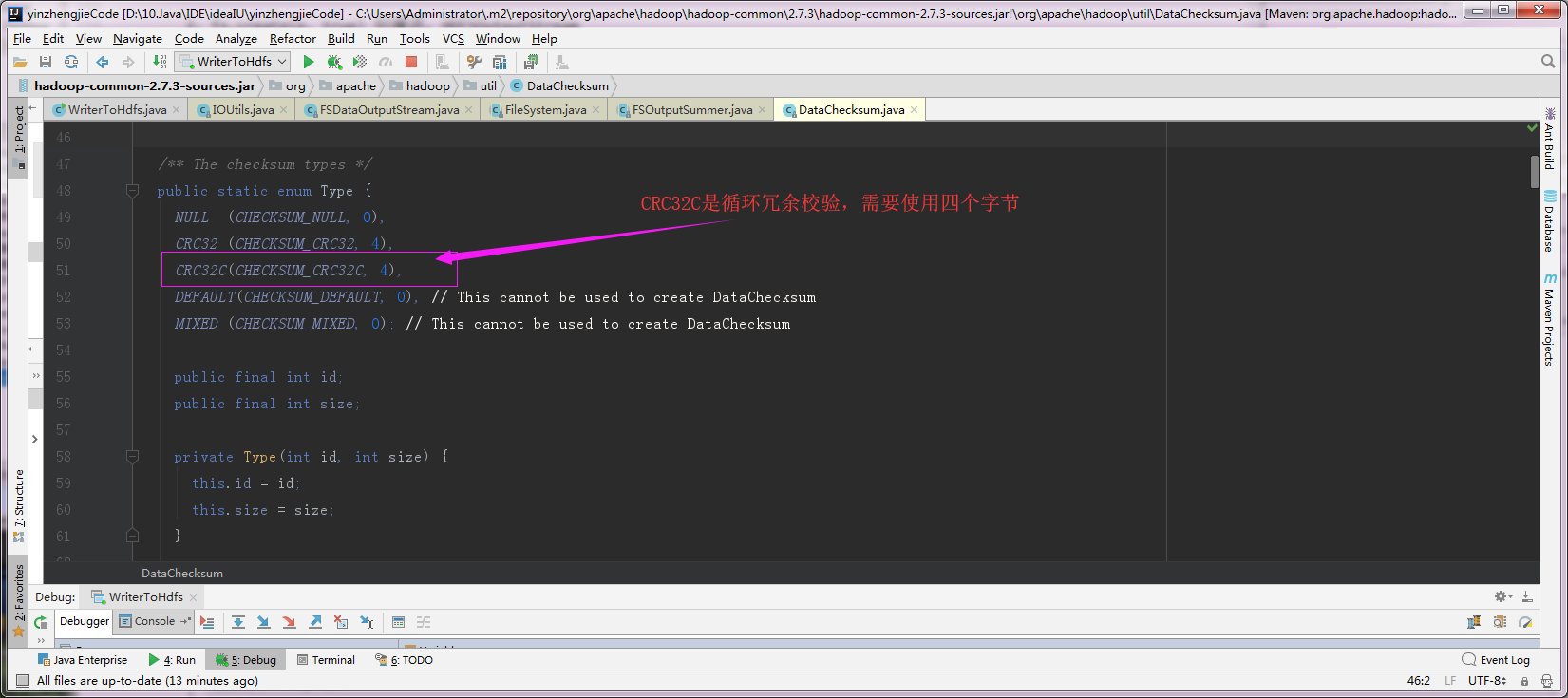
7>.使用“sum.calculateChunkedSums”来计算校验和,使用循环冗余校验(CRC32C),大小4个字节
四.知识点小结
1>.chunk数据块
第一:通过断点调试估计大家也知道chunk的做作用了,它就是数据块,512字节,在上面调试代码中看到的"sum.getBytesChecksum()"的大小就是512,它的意思就是每个512字节进行依次校验;
第二:上图调试中的"sum.caculateChunkedSums"是来计算校验和的,使用 循环冗余校验(CRC32C),占用4个字节;
2>.data数据
数据包括两个方面,估计你也猜到了,没错,就是真实数据和校验数据。校验数据大小 = 7字节头 + 检验和个数(每512字节进行依次校验) x 4
不管你信不信,反转我是信了,我们举个例子,如下:
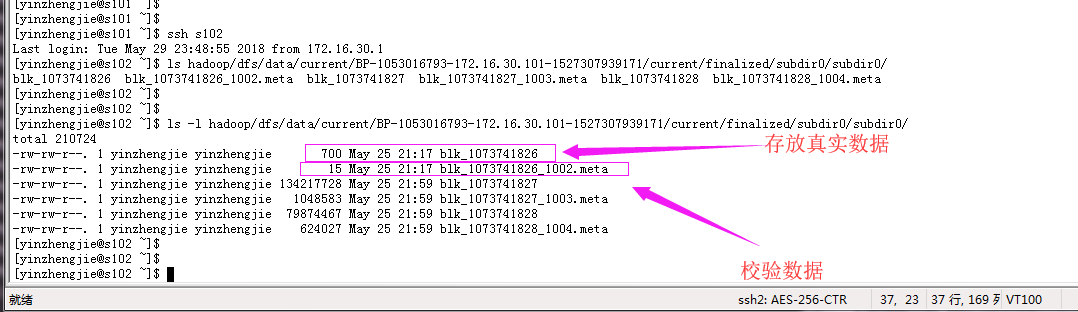
比如上面的“blk_1073741826”大小是700字节,将其除以512字节,商为2(如果有余数的话商要加1)。那么校验大小就应该是"7 + 4 x 2 = 15",即校验和为15字节,
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/9136447.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号