
Hadoop基础-HDFS的API实现增删改查
Hadoop基础-HDFS的API实现增删改查
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
本篇博客开发IDE使用的是Idea,如果没有安装Idea软件的可以去下载安装,如何安装IDE可以参考我的笔记:https://www.cnblogs.com/yinzhengjie/p/9080387.html。当然如果有小伙伴已经有自己使用习惯的IDE就不用更换了,只是配置好相应的Maven即可,我这里配置Maven是针对idea界面进行说明的。
一.将模块添加maven框架支持
1>.点击"Add Frameworks Support"
2>.添加Maven框架的支持
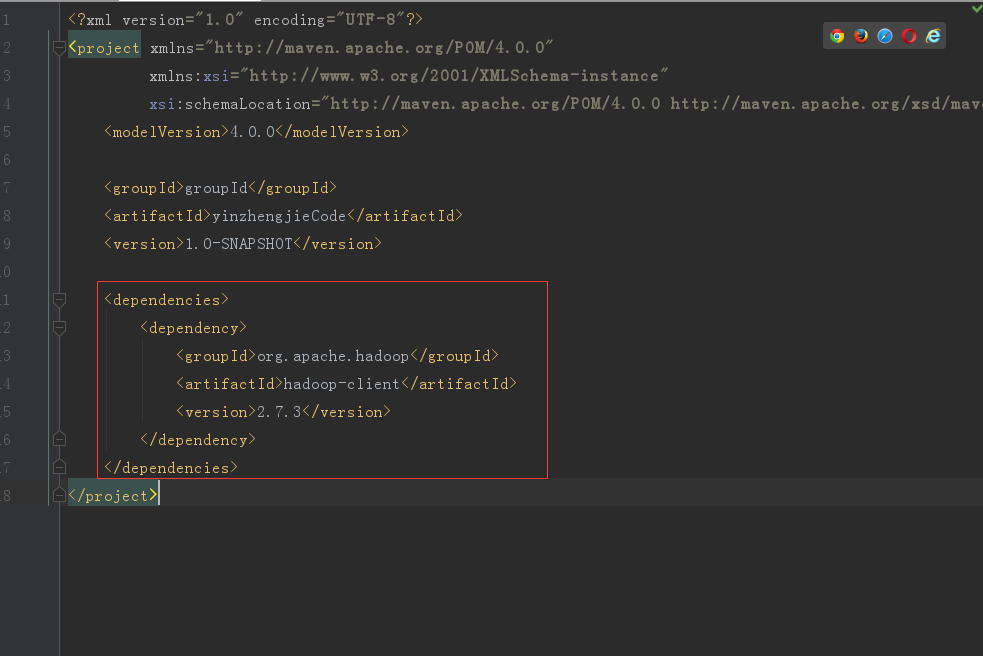
3>.在pom.xml中添加以下依赖关系
4>.启用自动导入

5>.等待下载完成
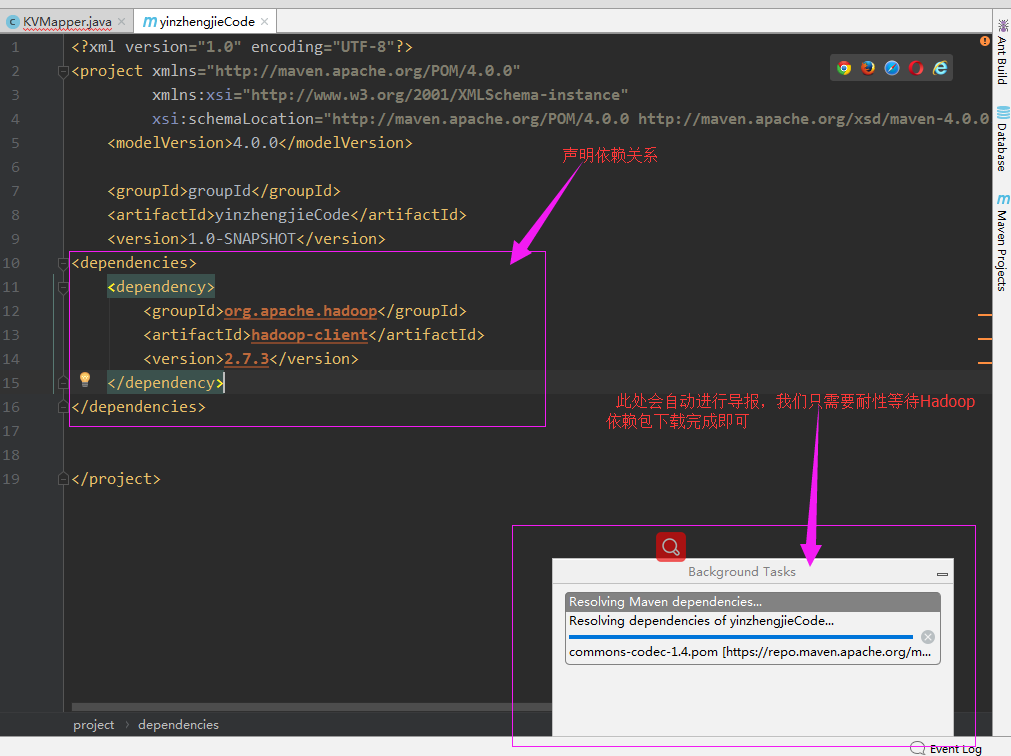
6>.手动刷新Maven项目
二.将Linux服务器端的HDFS文件到项目中的resources目录
1>.查看服务端配置文件
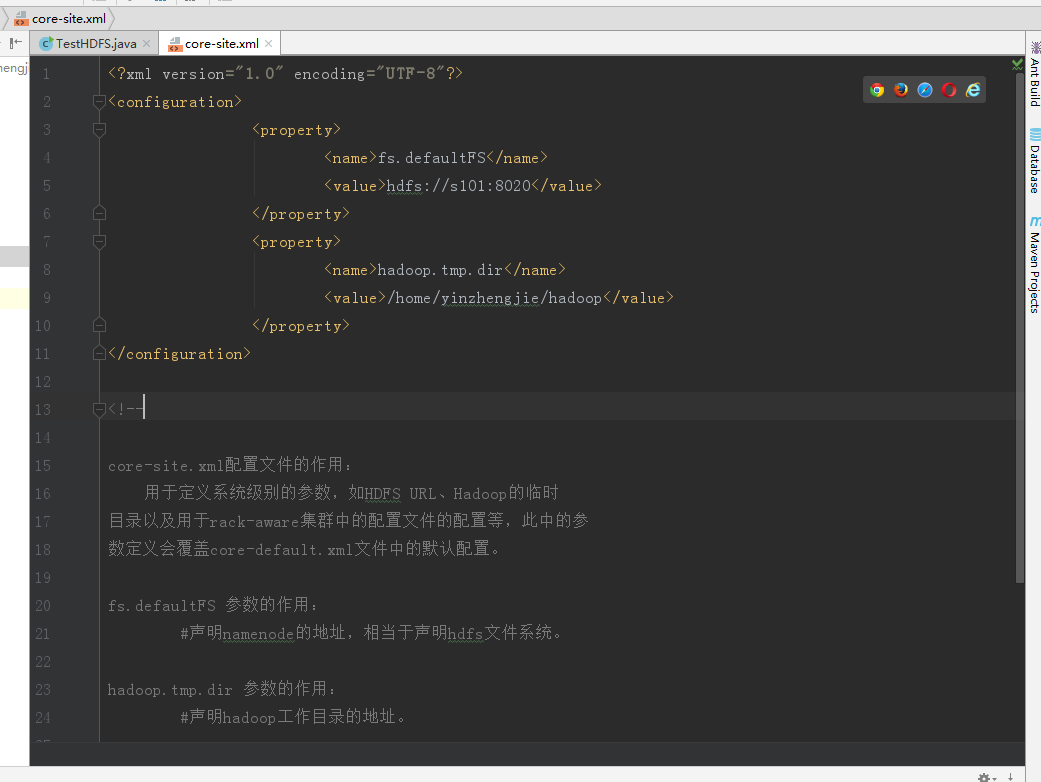
[yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/core-site.xml <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://s101:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/yinzhengjie/hadoop</value> </property> </configuration> <!-- core-site.xml配置文件的作用: 用于定义系统级别的参数,如HDFS URL、Hadoop的临时 目录以及用于rack-aware集群中的配置文件的配置等,此中的参 数定义会覆盖core-default.xml文件中的默认配置。 fs.defaultFS 参数的作用: #声明namenode的地址,相当于声明hdfs文件系统。 hadoop.tmp.dir 参数的作用: #声明hadoop工作目录的地址。 --> [yinzhengjie@s101 ~]$ sz /soft/hadoop/etc/hadoop/core-site.xml rz zmodem trl+C ȡ 100% 850 bytes 85 bytes/s 00:00:10 0 Errors [yinzhengjie@s101 ~]$
2>.将下载的文件拷贝到项目中resources目录下
3>.查看下载的core-site.xml 文件内容
三.HDFS的API实现增删改查
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.day01.note1; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FSDataInputStream; 10 import org.apache.hadoop.fs.FSDataOutputStream; 11 import org.apache.hadoop.fs.FileSystem; 12 import org.apache.hadoop.fs.Path; 13 import java.io.IOException; 14 15 public class HdfsDemo { 16 public static void main(String[] args) throws IOException { 17 insert(); 18 update(); 19 read(); 20 delete(); 21 } 22 23 //删除文件 24 private static void delete() throws IOException { 25 //由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入 26 // 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定! 27 System.setProperty("HADOOP_USER_NAME","yinzhengjie"); 28 //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) 29 Configuration conf = new Configuration(); 30 //代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。 31 FileSystem fs = FileSystem.get(conf); 32 //这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置 33 // 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写文件名称 34 Path path = new Path("/yinzhengjie.sql"); 35 //通过fs的delete方法可以删除文件,第一个参数指的是删除文件对象,第二参数是指递归删除,一般用作删除目录 36 boolean res = fs.delete(path, true); 37 if (res == true){ 38 System.out.println("===================="); 39 System.out.println(path + "文件删除成功!"); 40 System.out.println("===================="); 41 } 42 //释放资源 43 fs.close(); 44 } 45 46 //将数据追加到文件内容中 47 private static void update() throws IOException { 48 //由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入 49 // 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定! 50 System.setProperty("HADOOP_USER_NAME","yinzhengjie"); 51 52 //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) 53 Configuration conf = new Configuration(); 54 //代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。 55 FileSystem fs = FileSystem.get(conf); 56 //这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置 57 // 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写文件名称 58 Path path = new Path("/yinzhengjie.sql"); 59 //通过fs的append方法实现对文件的追加操作 60 FSDataOutputStream fos = fs.append(path); 61 //通过fos写入数据 62 fos.write("\nyinzhengjie".getBytes()); 63 //释放资源 64 fos.close(); 65 fs.close(); 66 67 } 68 69 //将数据写入HDFS文件系统 70 private static void insert() throws IOException { 71 //由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入 72 // 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定! 73 System.setProperty("HADOOP_USER_NAME","yinzhengjie"); 74 75 //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) 76 Configuration conf = new Configuration(); 77 //代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。 78 FileSystem fs = FileSystem.get(conf); 79 //这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置 80 // 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写文件名称 81 Path path = new Path("/yinzhengjie.sql"); 82 //通过fs的create方法创建一个文件输出对象,第一个参数是hdfs的系统路径,第二个参数是判断第一个参数(也就是文件系统的路径)是否存在,如果存在就覆盖! 83 FSDataOutputStream fos = fs.create(path,true); 84 //通过fos写入数据 85 fos.writeUTF("尹正杰"); 86 //释放资源 87 fos.close(); 88 fs.close(); 89 } 90 91 //在HDFS文件系统中读取数据 92 private static void read() throws IOException { 93 //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) 94 Configuration conf = new Configuration(); 95 //代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。 96 FileSystem fs = FileSystem.get(conf); 97 //这个path是指NameNode中的HDFS分布式系统中的路径映射(注意,我这里写的是主机名,你可以写IP,如果是测试环境的话需要在hosts文件中添加主机名映射哟!) 98 Path path = new Path("hdfs://s101:8020/yinzhengjie.sql"); 99 //通过fs读取数据 100 FSDataInputStream fis = fs.open(path); 101 int len = 0; 102 byte[] buf = new byte[4096]; 103 while ((len = fis.read(buf)) != -1){ 104 System.out.println(new String(buf, 0, len)); 105 } 106 } 107 } 108 109 110 /* 111 以上代码执行结果如下: 112 尹正杰 113 yinzhengjie 114 ==================== 115 /yinzhengjie.sql文件删除成功! 116 ==================== 117 */
四.HDFS的API实现文件拷贝(不需要我们自己实现数据流的拷贝,而是使用Hadoop自带的IOUtils类实现)
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.day01.note1; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FSDataInputStream; 10 import org.apache.hadoop.fs.FileSystem; 11 import org.apache.hadoop.fs.Path; 12 import org.apache.hadoop.io.IOUtils; 13 14 import java.io.FileOutputStream; 15 import java.io.IOException; 16 17 public class HdfsDemo1 { 18 public static void main(String[] args) throws IOException { 19 get(); 20 } 21 22 //定义方法下载文件到本地 23 private static void get() throws IOException { 24 //由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入 25 // 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定! 26 System.setProperty("HADOOP_USER_NAME","yinzhengjie"); 27 //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) 28 Configuration conf = new Configuration(); 29 //代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。 30 FileSystem fs = FileSystem.get(conf); 31 //这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/xrsync.sh”,但由于core-site.xml配置 32 // 文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写相对路径 33 Path path = new Path("/xrsync.sh"); 34 //通过fs的open方法获取一个对象输入流 35 FSDataInputStream fis = fs.open(path); 36 //创建一个对象输出流 37 FileOutputStream fos = new FileOutputStream("yinzhengjie.sql"); 38 //通过Hadoop提供的IOUtiles工具类的copyBytes方法拷贝数据,第一个参数是需要传一个输入流,第二个参数需要传入一个输出流,第三个指定传输数据的缓冲区大小。 39 IOUtils.copyBytes(fis,fos,4096); 40 System.out.println("文件拷贝成功!"); 41 //别忘了释放资源哟 42 fis.close(); 43 fos.close(); 44 fs.close(); 45 } 46 } 47 48 /* 49 以上代码执行结果如下: 50 文件拷贝成功! 51 */
五.自定义块大小写入文件
配置Hadoop的最小blocksize,必须是512的倍数,有可能你会问为什么要设置大小是512的倍数呢?因为hdfs在写入的过程中会进行校验,每512字节进行依次校验,因此需要设置是512的倍数。编辑“hdfs-site.xml”配置文件。
1>.服务器端hdfs的配置文件,修改默认的块大小,默认块大小是1048576字节,我们手动改为1024字节,配合过程如下:(别忘记重启服务,修改配置文件一般都是需要重启服务的哟)
[yinzhengjie@s101 ~]$ more `which xrsync.sh` #!/bin/bash #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie #EMAIL:y1053419035@qq.com #判断用户是否传参 if [ $# -lt 1 ];then echo "请输入参数"; exit fi #获取文件路径 file=$@ #获取子路径 filename=`basename $file` #获取父路径 dirpath=`dirname $file` #获取完整路径 cd $dirpath fullpath=`pwd -P` #同步文件到DataNode for (( i=102;i<=104;i++ )) do #使终端变绿色 tput setaf 2 echo =========== s$i %file =========== #使终端变回原来的颜色,即白灰色 tput setaf 7 #远程执行命令 rsync -lr $filename `whoami`@s$i:$fullpath #判断命令是否执行成功 if [ $? == 0 ];then echo "命令执行成功" fi done [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ more /soft/hadoop/etc/hadoop/hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.fs-limits.min-block-size</name> <value>1024</value> </property> </configuration> <!-- hdfs-site.xml 配置文件的作用: #HDFS的相关设定,如文件副本的个数、块大小及是否使用强制权限 等,此中的参数定义会覆盖hdfs-default.xml文件中的默认配置. dfs.replication 参数的作用: #为了数据可用性及冗余的目的,HDFS会在多个节点上保存同一个数据 块的多个副本,其默认为3个。而只有一个节点的伪分布式环境中其仅用 保存一个副本即可,这可以通过dfs.replication属性进行定义。它是一个 软件级备份。
dfs.namenode.fs-limits.min-block-size 参数的作用:
#该参数是用指定hdfs最小块存储设置 --> [yinzhengjie@s101 ~]$ xrsync.sh /soft/hadoop/etc/full/hdfs-site.xml =========== s102 %file =========== 命令执行成功 =========== s103 %file =========== 命令执行成功 =========== s104 %file =========== 命令执行成功 [yinzhengjie@s101 ~]$
2>.客户端编写API代码如下
/* @author :yinzhengjie Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ EMAIL:y1053419035@qq.com */ package cn.org.yinzhengjie.day01.note1; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.apache.hadoop.io.IOUtils; import java.io.FileInputStream; import java.io.IOException; public class HdfsDemo4 { public static void main(String[] args) throws IOException { String path = "F:/yinzhengjie.sql"; customWrite(path); } //定制化写入副本数和块大小(blocksize) private static void customWrite(String path) throws IOException { //由于我的Hadoop完全分布式根目录对yinzhengjie以外的用户(尽管是root用户也没有写入权限哟!因为是hdfs系统,并非Linux系统!)没有写入 // 权限,所以需要手动指定当前用户权限。使用“HADOOP_USER_NAME”属性就可以轻松搞定! System.setProperty("HADOOP_USER_NAME","yinzhengjie"); //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) Configuration conf = new Configuration(); //代码的入口点,初始化HDFS文件系统,此时我们需要把读取到的fs.defaultFS属性传给fs对象。 FileSystem fs = FileSystem.get(conf); //这个path是指是需要在文件系统中写入的数据,里面的字符串可以写出“hdfs://s101:8020/yinzhengjie.sql”,但由于core-site.xml配置文件中已经有“hdfs://s101:8020”字样的前缀,因此我们这里可以直接写相对路径 Path hdfsPath = new Path("/yinzhengjie.sql"); //通过fs的create方法创建一个文件输出对象,第一个参数是hdfs的系统路径,第二个参数是判断第一个参数(也就是文件系统的路径)是否存在,如果存在就覆盖!第三个参数是指定缓冲区大小,第四个参数是指定存储的副本数(规定数据类型必须为short类型),第五个参数是指定块大小。 FSDataOutputStream fos = fs.create(hdfsPath,true,1024,(short) 8,2048); //创建出本地的文件输入流,也就是我们真正想要上传的文件。 FileInputStream fis = new FileInputStream(path); //拷贝文件 IOUtils.copyBytes(fis,fos,1024); //释放资源 fos.close(); fis.close(); } }
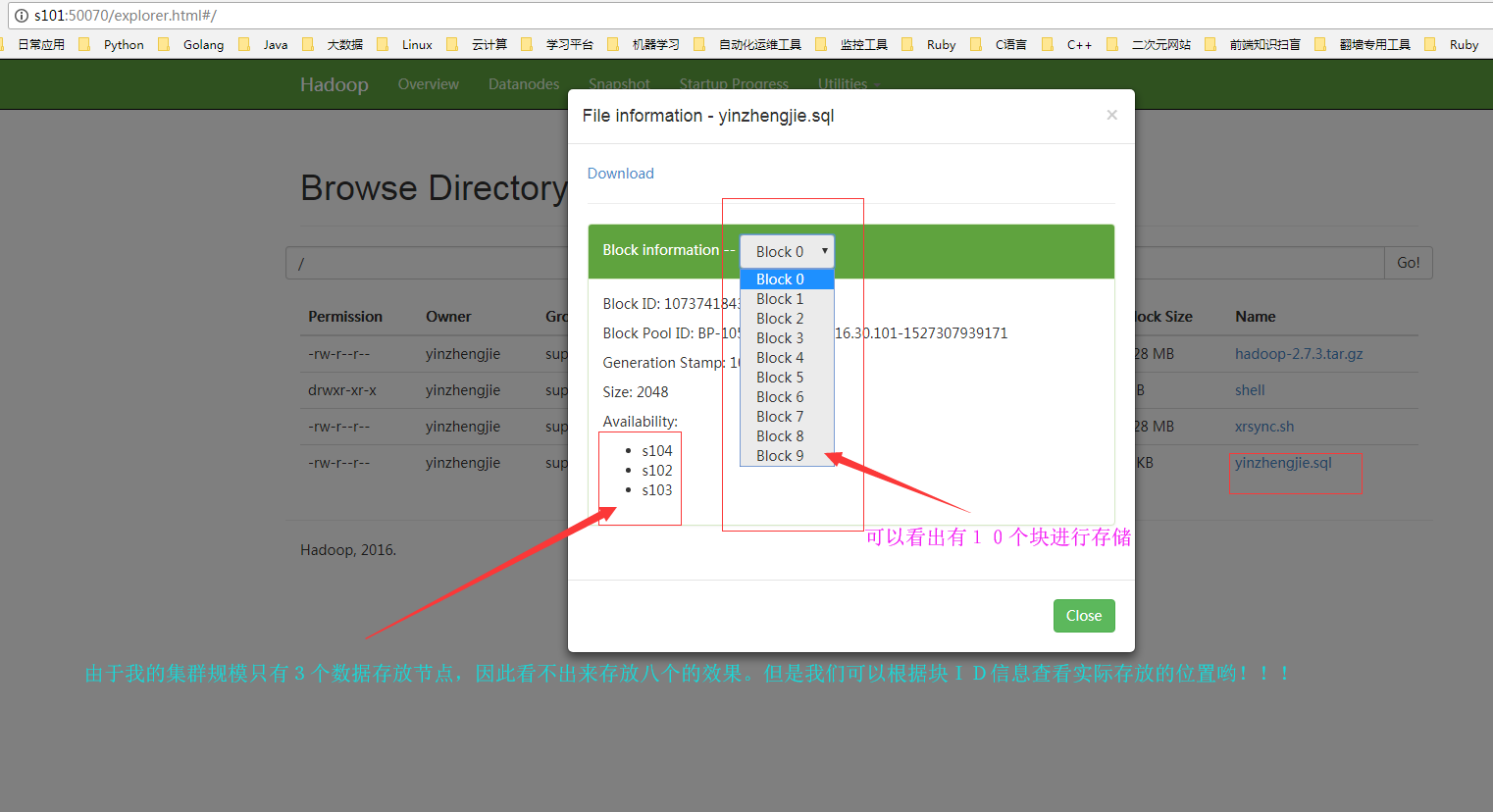
3>.客户端通过浏览器访问NameNode的WEBUI
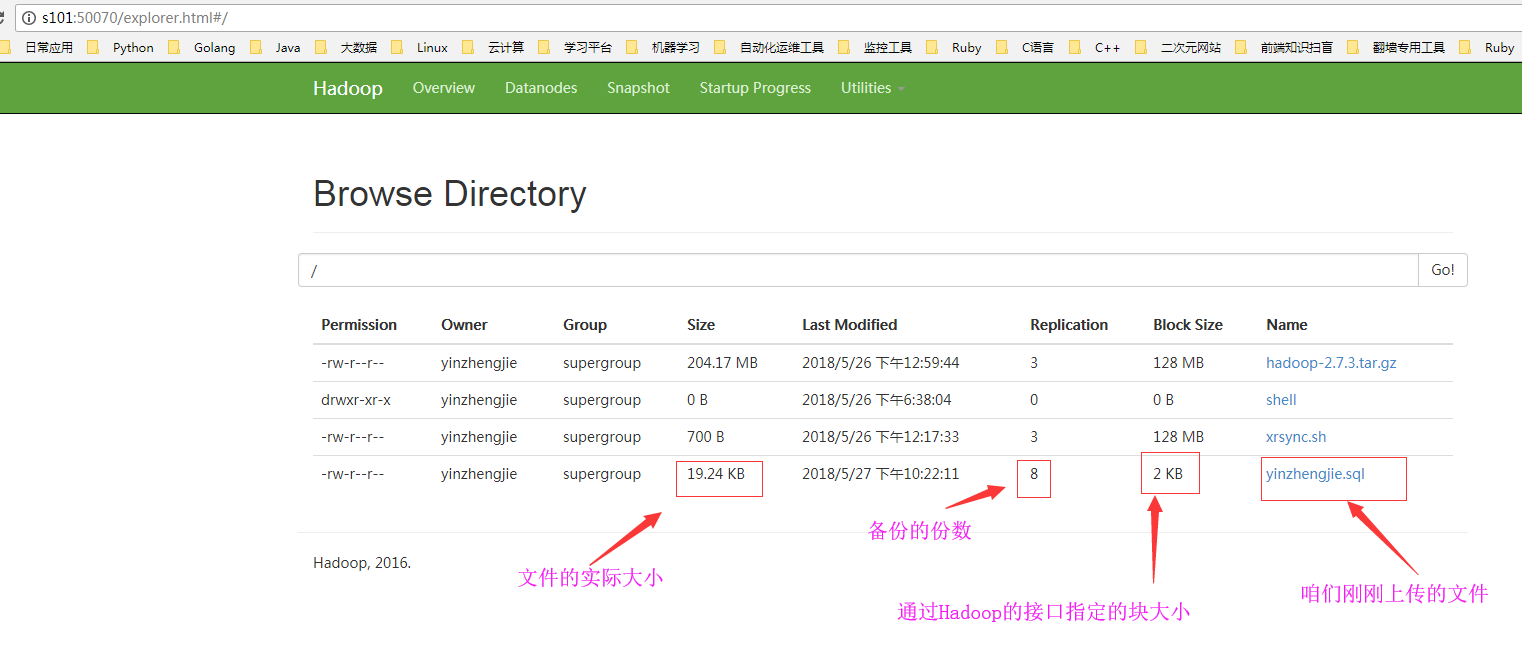
看完上面的信息发现和API设置的几乎一致呢,那必定得一致啊,由于块大小是2KB,而上传的文件是19.25kb,最少得10个块进行存储,我们也可以通过WEBUI来查看。
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/9093850.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号