

Hadoop日志纪录篇
Hadoop日志纪录篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Hadoop日志消息概述
1>.Hadoop日志记录概述
Hadoop日志对于处理失败的作业很有帮助。作业可能由于应用程序中的问题或硬件和平台错误而失败。Hadoop守护程序日志能够显示影响作业的守护进程中的任何问题的来源。
可以分析应用程序日志,以确定发生性能问题的根本原因,例如缓慢运行的作业,运行失败作业的等原因都在日志中有相应的记录。
与Oracle数据库不同,它具有跟踪更改和日志问题的单个警报日志,Hadoop具有复杂的日志的日志记录结构。当你首次处理此复杂的日志记录结构时,会感到困惑。
不过,不要害怕,只要了解了hadoop日志记录结构,就可以轻松地浏览日志框架,并学习如何挖掘日志,以更好地跟踪系统。
在进行故障排除时,需要查看应用程序日志和Hadoop守护日志。但首先,我们来了解一下不同类型的应用程序以及如何查看日志。
2>.日志类型概述
可以通过浏览各个日志文件或通过Hadoop内置的web界面访问Spark,Hive和其他作业的Hadoop日志消息。在大多数时候,通过Web界面访问日志更好,因为可以节省时间,并快速找到发生性能问题或作业失败的根本原因。 Spark和MapReduce作业任务生成的日志有三种类型: stdout: 将所有的system.out.println()消息定向到名为stdout的日志文件,可以为stdout日志使用自定义消息。 stderr: 将所有system.err.println()消息都绑定到名为stderr的日志文件,可以为stderr日志使用自定义消息。 syslog: 将所有log4j(标准日志库)日志发送到名为syslog的日志文件,可以再次发送自定义邮件,这是最重要的日志。 可以通过其了解一个任务的进展,为什么它很慢,启动失败或停止运行。作业执行期间的任何未处理的异常被syslog补货,所以它是了解map与reduce任务失败的地方。 接下来我们举个例子: 假设mapper程序包含以下代码: logger.info("Mapper Key = " + key); 分析如下: 在这种情况下,mapper仅使用Log4j日志记录,并且不会记录到标准输出流。 因此,我们会看到,此作业仅记录syslog文件中的记录信息,无论是否自定义了Log4j日志记录,该文件将始终包含信息,因为它是来自系统的所有Log4j消息的日志。 在这种情况下,你不会在stdout和stderr文件中看到任何记录信息(那里有这两个文件,但文件内容为空)。 假设reducer代码中具有以下与日志相关的代码: logger.info("Reduce Key =" + key); System.out.println("Reducer system.out >>>" + key); System.err.println("Reducer system.err >>>" + key); 分析如下: 由于reducer已经指定了所有三种类型的日志,因此可以在reducer任务的所有三个日志文件(stdout,stderr和syslog)中找到日志信息。 温馨提示: (1)syslog文件始终包含日志信息,stdout和stderr文件为空,除非在代码中指定了stdout和stderr类型的日志记录。 (2)通过编辑"${HADOOP_HOME}/etc/hadoop/log4j.properties"(等效于$HADOOP_CONF_DIR/log4j.properties)配置文件来配置log4j日志。 在默认情况下,该文件位于位于$HADOOP_CONF_DIR变量指定的目录中。一旦更改了日志记录属性,更改会立即生效,而不需要重新启动集群。 (3)严格意义上来讲,除了上面提到的stdout,stderr以及syslog外,还有另外两种日志类型,如下所示: prelaunch.err: 记录启动容器前发生的错误信息。 prelaunch.out: 启动容器前的信息,比如,设置环境变量(Setting up env variables)设置作业资源(Setting up job resources),启动容器(Launching container)等等。
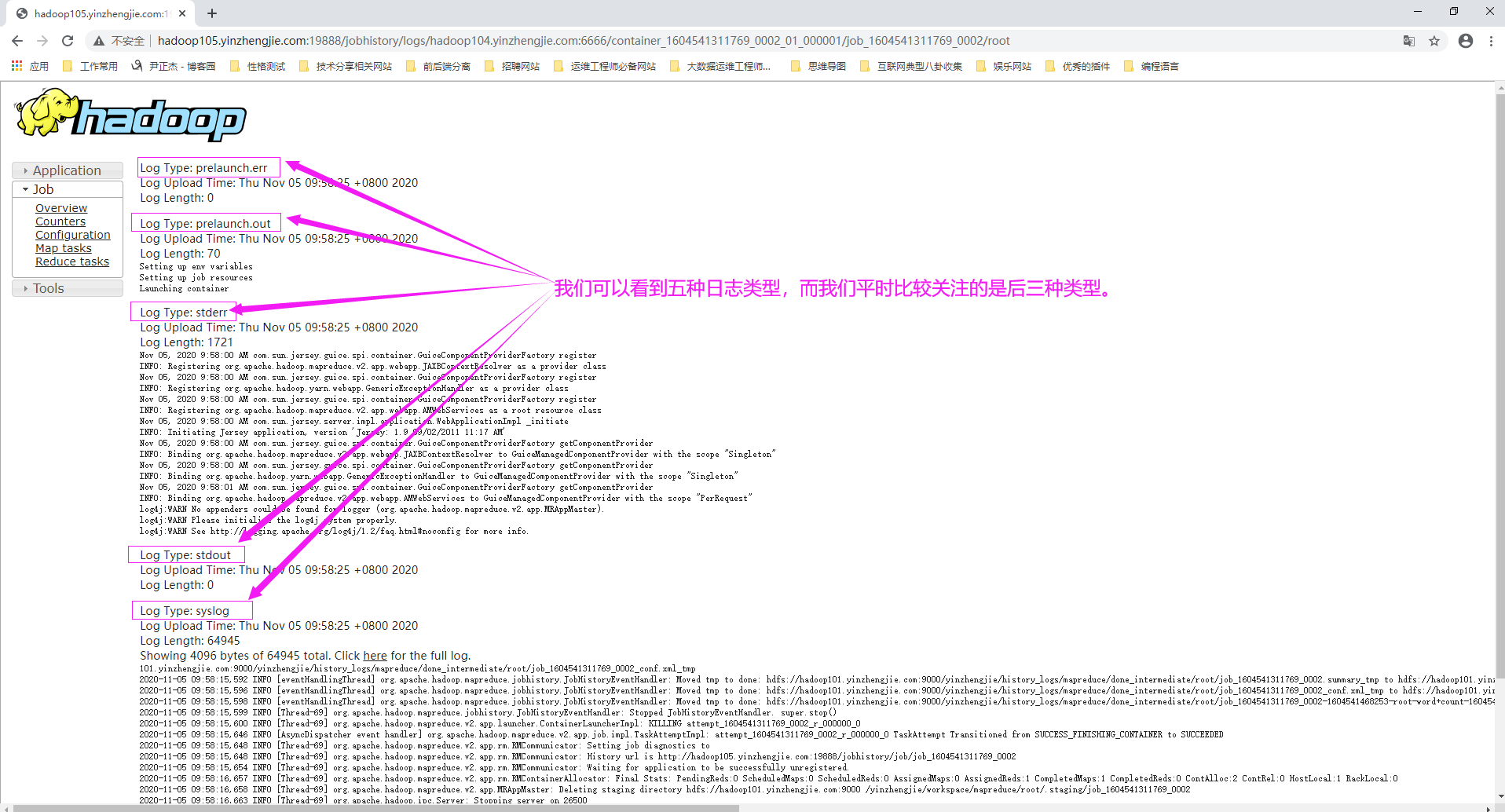
3>.守护进程和应用程序日志以及如何查看这些日志
一些新的Hadoop应用程序开发人员和管理人员在审阅守护程序和应用程序日志时会感到困惑。 如果使用Cloudera或Hortonworks并使用它们的管理界面(如Cloudera Manager或者Ambari),则可以通过单机按钮进入日志。切确的说,在哪里存储各种日志,以及哪些日志可用对于我们很重要。 Hadoop生成两种主要类型的日志: 守护程序日志(例如:HDFS和YARN相关的守护进程): 守护进程日志主要由管理员使用,因为它们有助于排除诸如DataNodes和NameNode等关键Hadoop服务的意外故障。 应用程序日志(例如:MRAppMaster和SparkAppMaster类型的日志): Hadoop应用程序对于应用程序开发人员和管理员非常重要,因为它们可以帮助我们了解作业失败和性能下降的根本原因。 可以通过多种方式查看Hadoop应用程序日志,包括但不限于以下方法: (1)从Hadoop Web UI(特别是ResourceManager Web UI)查看,使用ResourceManager Web UI可以免除访问日志存储位置和查看日志文件的麻烦。还可以通过JobHistory Web UI查看日志。 (2)直接从日志文件检查日志信息,当然,这需要你登录服务器。 (3)对于某些应用程序日志,如果启用了日志聚合功能,则将它们聚合到HDFS存储,强烈建议这样做,因为这样查看日志就毫不费力啦,无需登录服务器; (4)通过yarn命令检查(例如:"yarn logs -applicationId application_1604218163813_0008 > application_1604218163813_0008.log")。 综上所述,对于两种主要类型的日志,需要从Hadoop管理员的角度来关注,接下来我们介绍一下应用程序日志记录,然后讨论如何管理Hadoop守护程序日志。
二.应用程序日志记录的工作原理
应用程序日志在分析Hadoop作业的性能以及处理作业执行问题时至关重要。要想了解如何使用hadoop应用程序日志,首先要了解日志的生成方式。因此,下面首先介绍了MapReduce作业的步骤,最终会生成和存储由Hadoop处理的每个作业的日志文件。
1>.Hadoop存储日志的位置
想要有效地分析Hadoop日志,重要的是了解Hadoop在作业运行时和作业完成后,在系统中的多个位置存储作业相关的信息和日志。有以下三个位置: HDFS集群: 这是Hadoop创建用于存储作业执行文件的暂存目录的位置。如果配置hadoop的日志聚合功能,hadoop还会使用长期(日志的保留有效期是可以自行配置的)的hadoop作业日志,因为它存储在HDFS集群上。 NodeManager本地目录: 这些是在本地文件系统上创建的目录,hadoop在其中存储由NodeManager服务生成的shell脚本(比如"default_container_executor_session.sh","default_container_executor.sh","launch_container.sh"),以便于执行ApplicationMaster容器。 这些目录如果在运行时去查看的话,除了上面提到的shell文件,如下图1-3所示,你可能会发现还包括但不限于: "job.splitmetainfo","job.split","job.jar","job.xml","file.out","file.out.index","container_tokens"等文件。 可以使用文件中的"yarn.nodemanager.local-dirs"属性指定NodeManager本地目录的位置。如下所示,就是我在生产环境中配置的三个目录。 <property> <name>yarn.nodemanager.local-dirs</name> <value>/yinzhengjie/data/hdfs/nm1,/yinzhengjie/data/hdfs/nm2,/yinzhengjie/data/hdfs/nm3</value> <description> 指定用于存储本地化文件的目录列表(即指定中间结果存放位置,通常会配置多个不同的挂在目录,以增强I/O性能)。默认值为"${hadoop.tmp.dir}/nm-local-dir"。 YARN需要存储其本地文件,例如MapReduce的中间输出,将它们存储在本地文件系统上的某个位置。可以使用此参数指定多个本地目录,YARN的分布式缓存也是用这些本地资源文件(例如切片信息,配置信息,jar包等)。 </description> </property> NodeManager日志目录: 这些是Linux上的本地目录,NodeManager在此存储用户运行的应用程序的实际日志文件。在此节点的NodeManager上执行作业的所有容器(Spark,MapReduce和其他作业任务)并将其应用程序日志存储在此目录中。 该参数的默认值为${yarn.log.dir}/userlogs,需要注意的是,"${yarn.log.dir}"实际上不是一个OS环境变量(例如JAVA_HOME变量)。这是通过"${HADOP_HOME}/etc/hadoop/yarn-env.sh"文件配置的Java系统属性。 在默认情况下,将yarn.log.dir属性设置为与OS环境变量YARN_LOG_DIR的值相同。 在"${HADOOP_HOME}/etc/hadoop/yarn-site.xml"文件中,使用"yarn.nodemanager.log-dirs"属性指定NodeManager日志目录的位置。如下所示,我指定了三个目录(这些目录存储的内容可参考下图4)。 <property> <name>yarn.nodemanager.log-dirs</name> <value>/yinzhengjie/logs/yarn/container1,/yinzhengjie/logs/yarn/container2,/yinzhengjie/logs/yarn/container3</value> <description> 指定存储容器日志的位置,默认值为"${yarn.log.dir}/userlogs"。此属性指定YARN在Linux文件系统上发送应用程序日志文件的路径。通常会配置多个不同的挂在目录,以增强I/O性能。 由于我启用了日志聚合功能,一旦应用程序完成,YARN将删除本地文件。可以通过JobHistroyServer访问它们(从汇总了日志的HDFS上)。 在该示例中将其设置为"/yinzhengjie/logs/yarn/container",只有NondeManager使用这些目录。 </description> 温馨提示: HDFS分段目录和NodeManager本地目录包含具有作业参数和执行ApplicationMaster的shell脚本字段。由于这些目录包含实际的应用程序日志文件,所以在日常工作中NodeManger日志目录对我们更为重要。
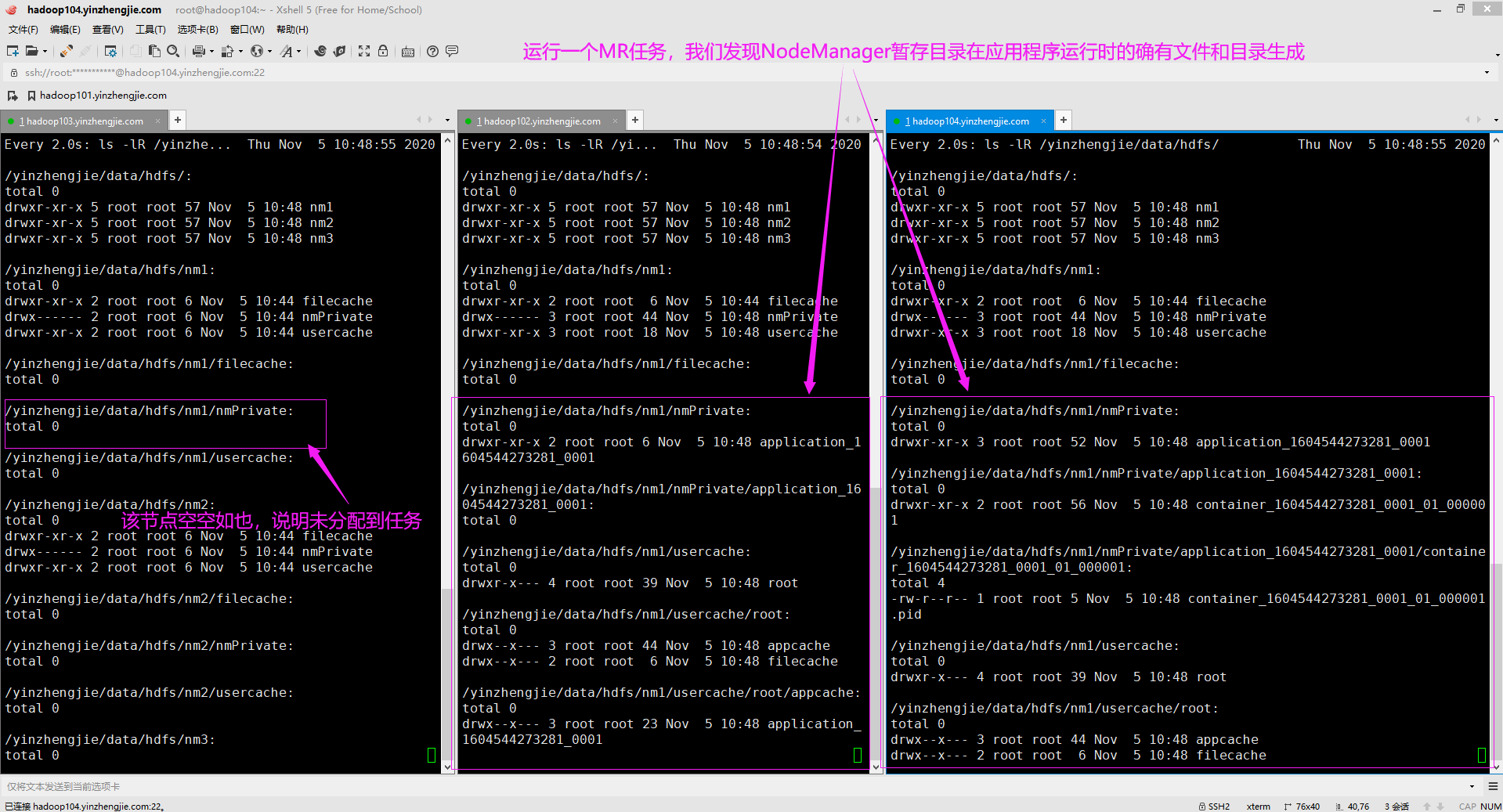
如上图所示,我之所以截图是因为这些是临时文件,当应用程序运行完毕后,这些本地临时文件或被清除。
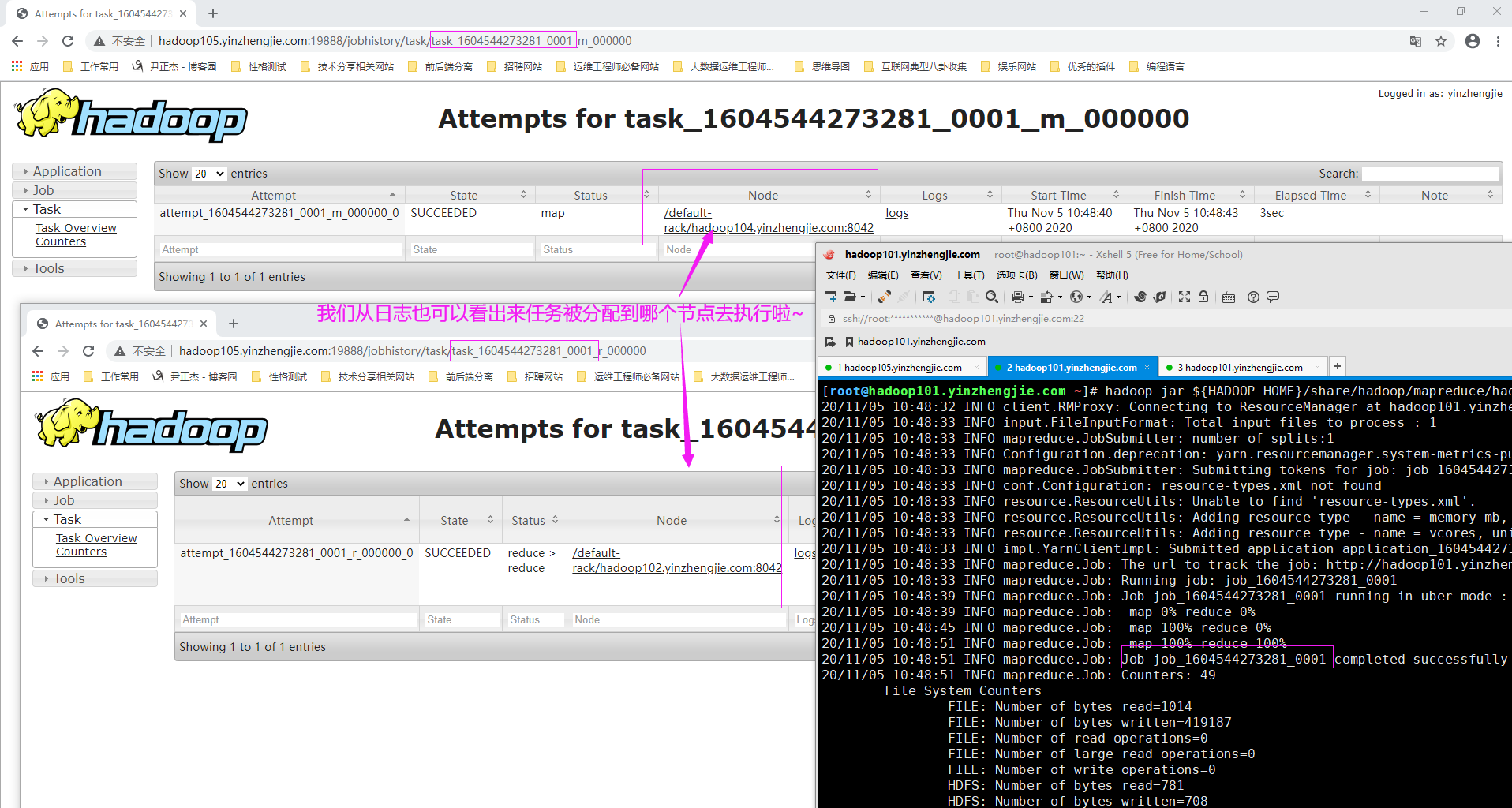
但这并不是无迹可寻,如下图所示,我们可以通过日志信息可以看出,某个特定的job在具体的时间其map和reduce程序分别在哪个主机上运行的。
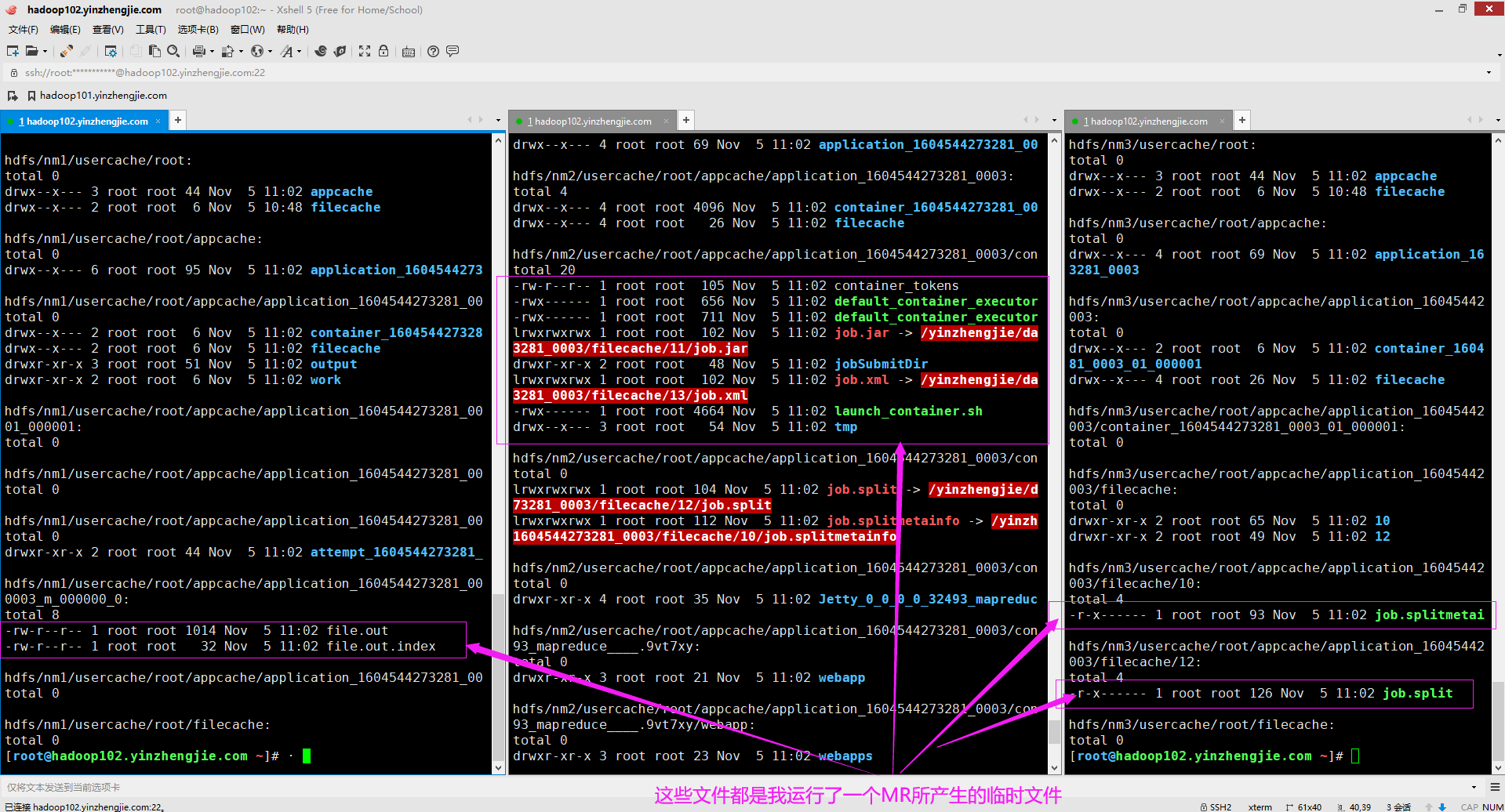
如果你关心中间临时结果有哪些,如下所示,其实是有很多的临时文件,不仅仅包含shell文件,还有一些配置文件,jar包文件,切片信息等。我下面的截图也只是运行一个MR所临时产生的文件(包含了部分内容,图中并未展示全,因为屏幕不够用,哈哈哈~)。
2>.NodeManager日志目录包含的内容
应用程序的日志文件中实际上包含的是容器日志。每个应用程序的本地化日志目录具体以下目录结构: ${yarn.nodemanager.log-dirs}/application_${appid}/ ${appid}变量表示MapReduce作业的应用程序ID。每个容器的日志目录位于此目录下,并使用以下目录命名约定: container_${contid} 如下图所示,各个容器的日志(即"container_${containerID}")位于名为"${yarn.nodemanager.log-dirs}/application_${appid}"目录下。 容器目录中的每个目录都包含我们感兴趣的实际日志文件,它们是本容器生成的五种类型的hadoop日志,包括prelaunch.err,prelaunch.out,stderr,stdout和syslog。这是在运行期间找到有关容器错误信息的地方。
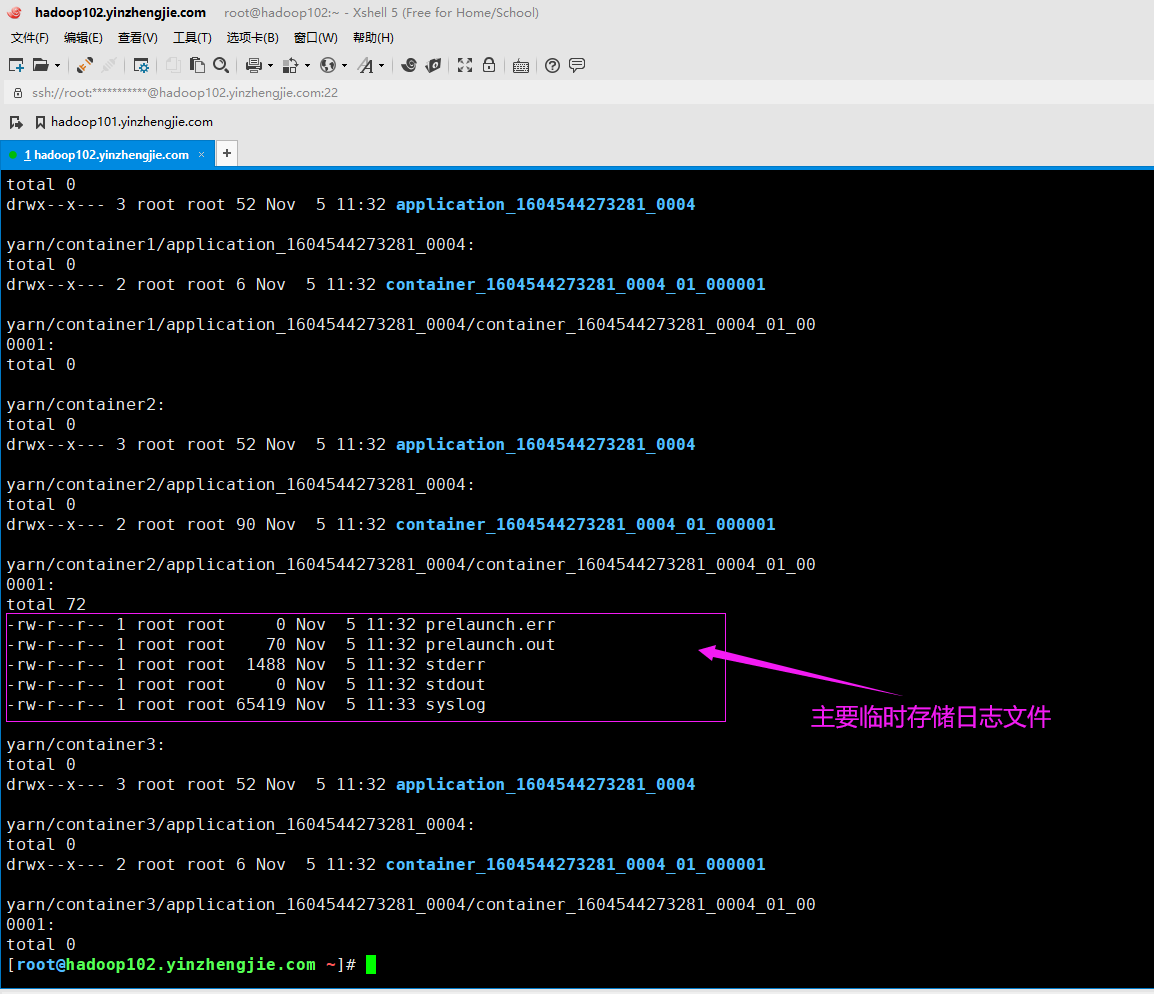
由于我生产环境中配置了日志聚合,yarn.nodemanager.log-dirs配置的属性主要是日志临时存放目录,运行一个MR程序后,可以看到类似上图所示的目录结构,当应用程序运行完毕后,可能会有5秒的延迟,该目录下的所有临时文件都将被删除。
温馨提示:
我上面给出的5秒钟是我跑了一个MR的心理估算的结果,可能并不准确,但相差不会太大。因为它需要将这些临时日志上传到HDFS集群进行聚合,所以才会有这个延迟。
可能是由于我运行的程序处理的数据比较小,生产环境中你的集群删除这些数据可能会有更大的延迟,但我估计也在5-10s之间。
三.Hadoop如何使用HDFS目录和本地目录
当启动YARN作业时,Hadoop会使用HDFS(不是使用HDFS中存储的数据,这里我们讨论hadoop如何使用HDFS来记录和存储作业相关信息)和本地目录中的各种节点。
Hadoop使用HDFS进行作业缓存,使用本地目录存储生成的用于启动作业容器(比如MRAppMaster中的map和reduce任务)的各种脚本。
接下来我们一起看一下在作业执行期间hadoop如何使用HDFS和本地目录。
1>.HDFS如何执行作业
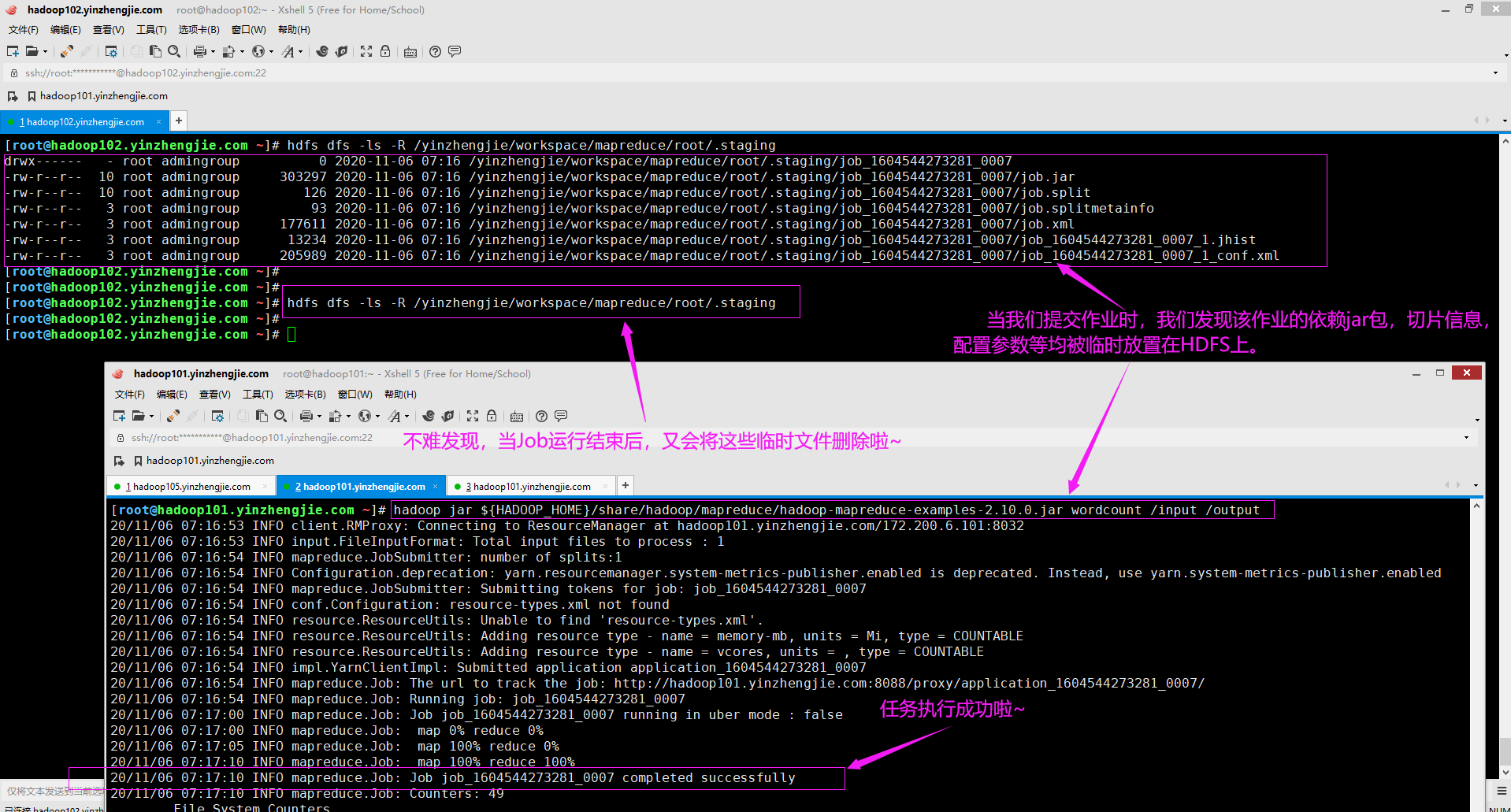
当用户执行MapReduce作业时,他们通常调用作业客户端来配置作业并启动它。作业客户端执行以下操作: (1)它首先检查在HDFS中用户名下是否有暂存目录。如果没有,创建它。暂存目录的格式为: "${yarn.app.mapreduce.am.staging-dir}/${user}/.staging",注意哈,这提到的两个变量并非指操作系统的环境变量。 需要注意的是,"yarn.app.mapreduce.am.staging-dir"属性通常需要在"${HADOOP_HOME}/etc/hadoop/mapred-site.xml"配置文件中指定,如下所示,我自定义了该属性所对应的路径。 <property> <name>yarn.app.mapreduce.am.staging-dir</name> <value>/yinzhengjie/workspace/mapreduce</value> <description> 该参数用于他提交作业的暂存目录,其默认值为"/tmp/hadoop-yarn/staging"。 一般情况下,我们将其指向一个HDFS目录,YARN存储所有应用程序相关信息,例如运行作业时创建的临时文件,作业计数器和作业配置等,该目录路径自定义即可。 </description> </property> (2)如下图所示,作业在客户端在".staging"目录下,在作业(每个Job对应一个HDFS上的目录,例如:"job_1604544273281_0007")以及job.xml文件中创建名为"job_<jobID>_conf.xml"文件,这些文件包括用于执行此作业的hadoop参数。 (3)除了与作业相关的文件外,还将hadoop-mapreduce-client-jobclient.jar的Hadoop JAR(Java 归档)文件放在".staging"目录中,然后将其重命名为"job.jar"。
温馨提示:
(1)若未配置"yarn.app.mapreduce.am.staging-dir"属性。则使用"${HADOOP_HOME}/share/doc/hadoop/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml"中默认值,即"/tmp/hadoop-yarn/staging";
(2)设置了暂存目录后,作业客户端将作业提交到ResourceManager,作业客户端还通过显示作业的map和reduce阶段的完成百分比(如下图所示,"map 100% reduce 100%"),向控制台发送作业进度状态;
(3)请注意,所有这些都是HDFS文件系统中发生的,而不是在Linux服务器的本地目录中。作业客户端启动作业后,此作业的ApplicationManager将变为动作。
2>.NodeManger如何使用本地目录

ResourceManager的ApplicationManager(千万别和Job的ApplicationMaster混淆哈)服务在其中一个集群的节点上选择一个NodeManager,以启动ApplicationMaster进程。 总所周知,ApplicationMaster进程始终是YARN作业中要创建的第一个容器(Container)。ResourceManager选择哪个NodeManager取决于启动作业时的可用资源,我们不能指定用于启动作业的节点(仅就这一点而言,它没有K8S灵活)。 NodeManager服务启动并在本地应用程序缓存(appCache目录)中生成各种脚本,以执行ApplicationMaster容器。 ApplicationMaster的目录位于使用"${HADOOP_HOME}/etc/hadoop/yarn-site.xml"文件中"yarn.nodemanager.log-dirs"属性为NodeManager本地目录指定的位置,关于如何配置我在上面已经介绍过,此处就不再赘述啦。 使用yarn.nodemanager.log-dirs属性,可以提供NodeManager存储其本地文件的目录列表,在这些目录下面,能够找到具体以下目录结构的实际应用程序的本地文件目录: ${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/application_${appid} 要访问各个容器的工作目录,必须深入了解目录结构。容器工作目录时应用程序根目录下的子目录,并以容器命名,如下所示: ${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/application_${appid}/container_${contid} 如上图所示,显示了一个MRAppMaster容器目录(其容器编号为"container_1604544273281_0003_01_000001")的内容,注意该目录中的两个文件: job.xml: 该文件包含次作业要使用的YARN,MapReduce和HDFS的配置属性,对于hadoop的每个配置属性(使用"<property></property>"标签指定)。 该文件列出了属性的名称(对应"<name></name>"标签),属性值(对应"<value></value>"标签),是否可以修改(对应"<final></final>"标签)和来源(对应"<source></source>"标签)。 配置属性的来源可能是以下之一: (1)官方默认参数配置文件,比如:core-default.xml,hdfs-default.xml,mapred-default.xml,yarn-default.xml。 (2)用户自定义参数配置文件,比如:core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml。 (3)由用户以编程方式设置,即在代码中指定。 (4)用户提交任务时使用指定属性("-D <property=value>"),如下所示。
"hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount -D mapreduce.job.queuename=root.yinzhengjie.development /input /output" launch_container.sh: 该脚本用来执行ApplicationMaster类并允许ApplicationMaster容器。ApplicationMaster启动并向ResourceManager发送请求,以分配为了托管此应用程序所需的mapper和reducer的必须数量的容器。 温馨提示: final标签和java中的关键字final类似,当其值为true时意味着这个配置项是"固定不变的",当其值为false时则意味着这个配置项是可变的。如下图所示,此job作业有2个属性是不变的。 我们在自定义配置文件(比如:hdfs-site.xml,yarn-site.xml,mapred-site.xml)时,通常无需指定"<final></final>"标签(若不指定默认值为false),但在合并资源的时候,如果要防止配置项的值被覆盖则可以将其值设置为true。

3>.启动NodeManager并创建Map/Reduce容器
ResourceManager会以一个可用的NodeManager列表来响应由ApplicationMaster发出的关于容器分配的请求。ApplicationMaster联系在各个集群节点上运行的NodeManager,以启动完成该作业所需的mapper/reducer容器。
每个NodeManager节点在其本地下的本地应用程序缓存中目录(该目录用户可以自定义,就是由我们上面提到"yarn.nodemanager.local-dirs"属性设置的)中生成各种脚本,这些脚本与ApplicationMaster服务创建的脚本非常相似。
每个容器的应用程序缓存目录都包含"job.xml","launch_container.sh"等文件。应用程序缓存目录以map或reduce容器命名,如下图所示。
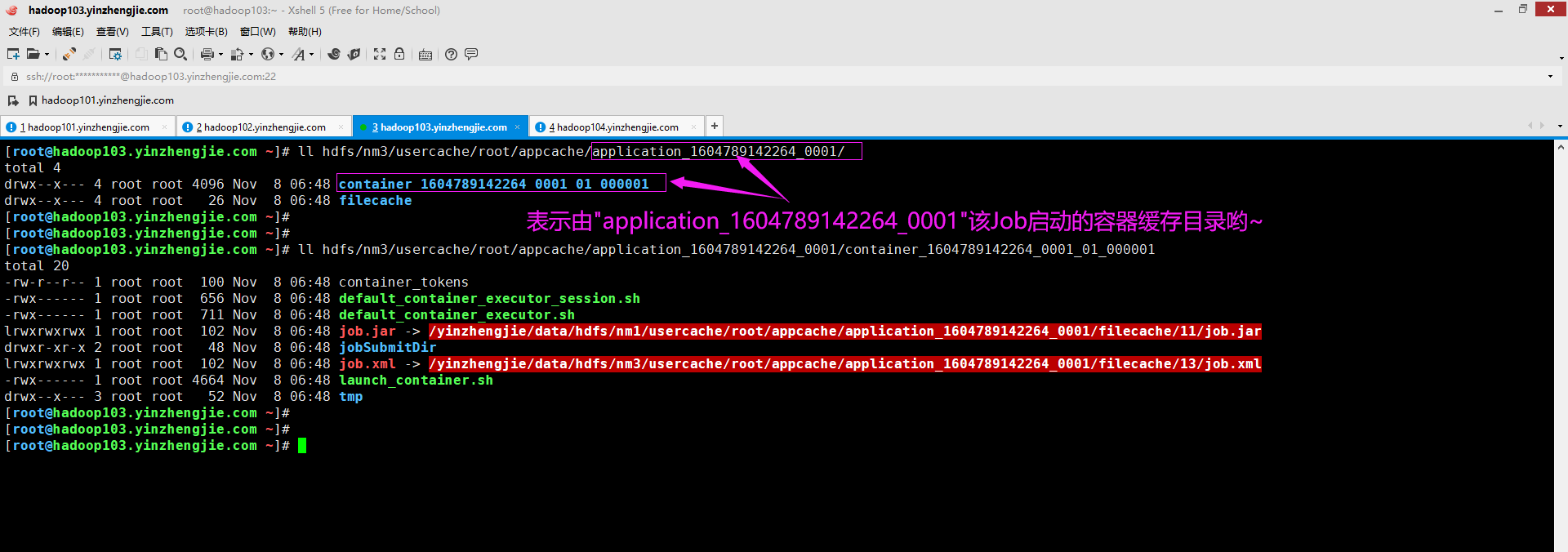
如上图所示,可能有小伙伴会担心各个nodemanager目录下会填满appCache子目录下的作业文件,导致磁盘空间不足的问题。 其实无须担心该问题,因为这些文件在作业完成时会被自动删除。但是,若某些作业确实包含大文件,并且当AppCache目录没有足够的空间来容纳它们时,作业将失败。 我们可以通过配置"yarn.nodemanager.delete.debug-delay-sec"指定应用程序完成后保留本地日志目录的时间(默认以秒为单位),下面就是我生产环境中配置的参数示例: <property> <name>yarn.nodemanager.delete.debug-delay-sec</name> <value>1800</value> <description> 指定应用程序(ApplicationMaster运行的Container)运行完成后,nodemanager的删除服务将删除应用程序的本地化文件目录和日志目录之前的秒数,默认值为0(即运行完成后立即删除)。 如果要诊断YARN的应用程序问题,可以将此属性设置的足够大(例如我这里设置的是1800s,即30分钟),以有充足事件来简称这些目录,更改此属性值后,必须重新启动nodemanager节点才能生效哟~ 生产环境中我不推荐大家将该值设置的过大,或者不设置,建议设置一个合理的值,比如1800-3600秒(即30-60分钟)。设置过小可能来不及处理,设置过大可能会造成过多空间的浪费哟! </description> </property> 需要注意的时,一旦"yarn.nodemanager.delete.debug-delay-sec"配置的时间到期,NodeManager的DeletionService进程会删除应用程序的本地文件目录结构,包括日志目录。 综上所述,建议将此参数的值设置得高一些(例如至少30分钟,即1800秒),以便有足够的时间查看应用程序(ApplicationMaster启动的各种Container)的日志。
4>.应用程序日志
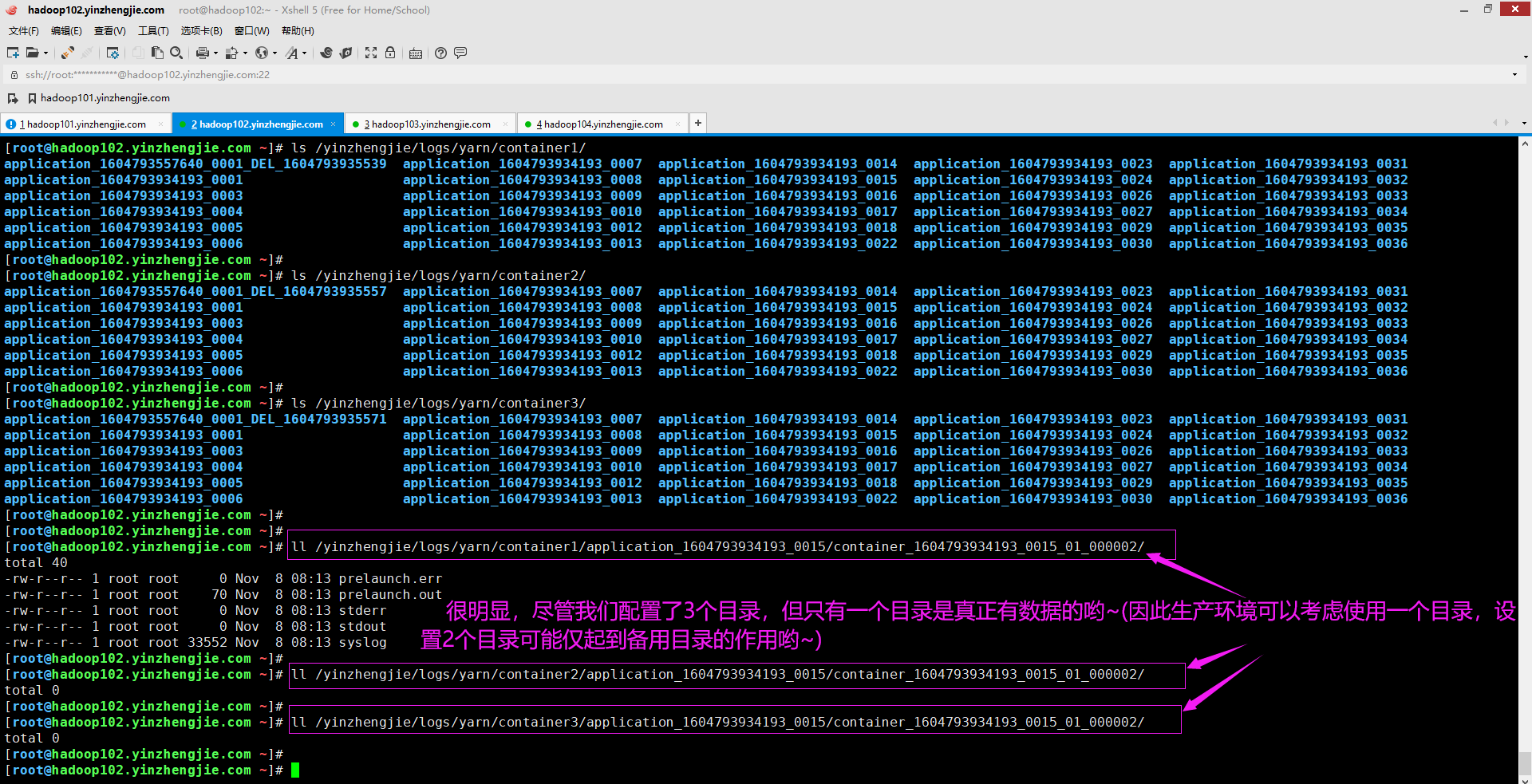
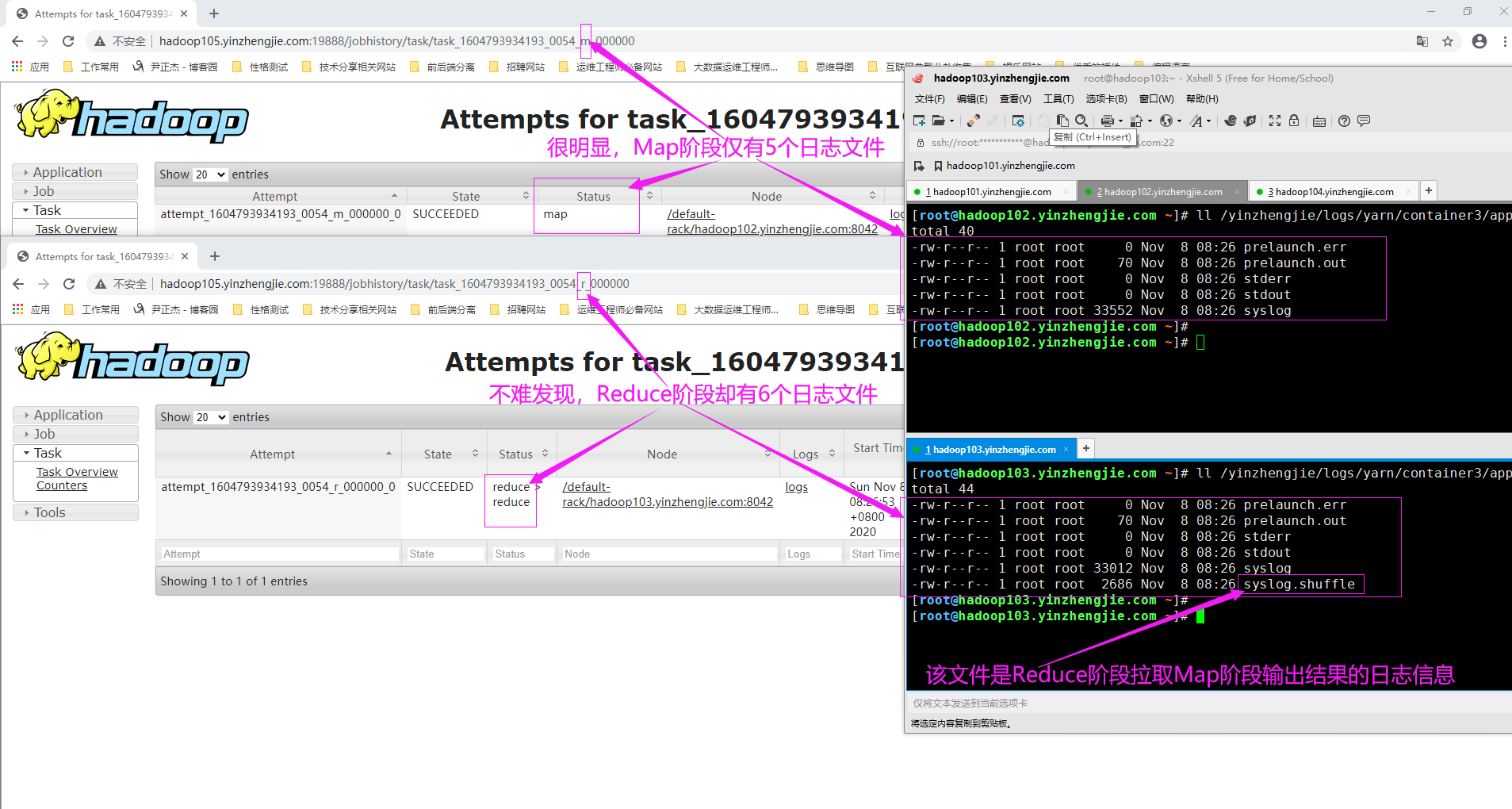
当应用程序运行时,它将生成日志并将它们存储在使用yarn.nodemanager.log.dirs参数指定的目录(在yarn-site.xml)中,如下所示。这里我们指定了多个目录(对应多个挂载点),虽然这。 <property> <name>yarn.nodemanager.log-dirs</name> <value>/yinzhengjie/logs/yarn/container1,/yinzhengjie/logs/yarn/container2,/yinzhengjie/logs/yarn/container3</value> <description> 指定存储容器日志的位置,默认值为"${yarn.log.dir}/userlogs"。可以指定多个目录,但仅有一个目录存储有数据,如上图所示。 </description> </property> 请记住,一个典型的作业(Job)运行在几个节点上,每个节点都有一个独立的NodeManager进程。在每个NodeManager节点上,都会发现与该节点上运行的Job的(mapper/reducer)容器相关的日志。 温馨提示: 如下图所示,就是一个典型的map容器和一个reduce容器。可以很明显的察觉出这两个目录有一定的差异,即Reduce容器多了一个"syslog.shuffle"日志文件。这也印证了shuffle过程是reduce程序去主动从map程序端拉取数据。
5>.map和reduce任务的日志级别
为整个集群设置的标准日志记录级别可能不适用于所有业务和任务。使用以下属性可以为map和reduce任务设置自定义日志记录级别。 <property> <name>mapreduce.map.log.level</name> <value>WARN</value> <description> 指定"MR ApplicationMaster"的map任务的日志记录级别。默认值为:"INFO"。允许的级别包括:"OFF","FATAL","ERROR","WARN","INFO","DEBUG","TRACE"和"ALL". 我这里指定的值为"WARN",需要注意的是,如果你配置了"mapreduce.job.log4j-properties-file"文件,则此处的配置将被覆盖哟~ </description> </property> <property> <name>mapreduce.reduce.log.level</name> <value>WARN</value> <description> 指定"MR ApplicationMaster"的reduce任务的日志记录级别。默认值为:"INFO"。允许的级别包括:"OFF","FATAL","ERROR","WARN","INFO","DEBUG","TRACE"和"ALL". 我这里指定的值为"WARN",需要注意的是,如果你配置了"mapreduce.job.log4j-properties-file"文件,则此处的配置将被覆盖哟~ </description> </property> 温馨提示: map和reduce任务的默日志记录级别都是INFO,可以在"mapreduce.job.log4j-properties-file"中设置不同的值来覆盖集群的设置。
6>.应用程序日志的保留持续时间(其与日志聚合功能冲突,若已经配置了日志聚合功能可直接忽略该参数)
当应用程序持续运行时,NodeManager会将日志数据复杂到该节点上运行的梦容器的日志文件中。作业完成后,NodeManager会将应用程序日志保留3小时(即默认10800s),然后将其删除。 可以通过在"${HADOOP_HOME}/etc/hadoop/yarn-site.xml"文件中设置"yarn.nodemanager.log.retain-seconds"属性的值来更改保留期限,如下所示。 <property> <name>yarn.nodemanager.log.retain-seconds</name> <value>86400</value> <description>保留用户日志的时间(以秒为单位)。仅在禁用日志聚合的情况下适用,默认值为:10800s(即3小时)。我这里设置的是24小时。</description> </property> 温馨提示: (1)上述配置在作业完成后将日志保留24小时,之后删除它们; (2)当然,若想要检查几个小时甚至几天之前完成的作业日志,生产环境中通常会配置日志聚合功能,可以访问旧的日志,如果你真的这样做,则意味着此参数配置无效;
(3)默认情况下禁用日志聚合,这意味着除非显式配置日志聚合,否则所有应用程序的日志将在三个小时后被自动删除。
四.通过日志聚合将作业日志存储在HDFS中
博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/13943340.html
五.使用Hadoop守护程序日志
博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/13943831.html
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/13929630.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号