

监控Linux服务器
监控Linux服务器
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Linux系统监控基础
从性能的角度来看,监控Linux系统主要监控CPU,内存,磁盘存储和带宽的使用情况。
1>.监控CPU使用情况
只要没有使用100%的CPU容量,就可以在系统中使用剩余的容量来支持更多的活动。CPU的使用达到峰值是常见的,但是在CPU使用率过高时,我们的目标是跟踪那些进程导致CPU使用过多。
检查CPU使用去考试应该注意下面几个关键因素:
(1)用户与系统使用情况:
与用户维护操作系统运行的时间成正比,可以确定CPU用于用户应用程序的时间百分比。显然,如果CPU的大部分时间由系统占用了,则可能还需要进一步检查。
(2)可运行进程:
在任务给定的时间,进程要么在运行,要么在等待资源被释放。正在等待资源分配的进程称为可运行进程。大量可运行进程的存在表明系统可能面临容量危机,它是CPU绑定的。
(3)上下文切换和中断:
当操作系统在进程之间切换时,所谓的上线文切换回导致一些开销。如果有太多次的上下文切换时,则CPU使用率会恶化。当完成某些硬件或软件相关任务时,如果操作系统造成的中断太多,也会产生类似的开销。
2>.监控内存使用情况
内存是我们遇到性能问题是首先应该关注的资源之一。如果服务器上的内存不足(RAM),系统可能由于内存交换过多而变慢。内存交换意味着系统将内存页面传输到磁盘设备为其他进程释放内存。
当检查系统内存使用情况时,请注意以下几点:
(1)页面输入和页面输出:
如果在内存使用情况统计信息中看到大量的页面输入和页面输出,则意味着系统正在执行过多的分页,这涉及将页面从内存移动到磁盘,如果可用内存不足的话。
过多的分页可能导致抖动情况,这意味着你正在使用关键系统资源做内存和磁盘之间的页面移动。
(2)换入和换出:
交换统计信息还可以指示系统当前内存分配的充足成都。
(3)活动和非活动页面:
如果活动内存页面太少,则可能意味着物理内存不足。
3>.监控磁盘存储
监控磁盘涉及两件事情。首先,检查以确保没有用尽空间,应用程序持续添加更多数据,因而必须不断添加更多的存储空间。其次,观察磁盘性能,磁盘输入/磁盘输出性能较慢,是否存在瓶颈?
要查找的基本信息如下所示:
(1)检查可用空间
使用简单的命令,系统管理员或DBA可用检查系统剩余的可用空间量。最好是定期检查,在资源紧张是监控就太晚了。可用使用df和du命令检查系统上的可用空间。
(2)读取和写入
读取/写入数据可以帮助你了解磁盘的运行有多"热"。通过检查读取/写入数据,可以了解系统是否正在处理其工作负载,或者在任何给定时间是否处理额外的I/O负载。
4>.监控带宽
通过监测网络带宽使用情况,可以计算设备间数据穿度的效率。带宽比简单的I/O或内存使用更难测定,但收集带宽相关统计信息非常有用。
网络是系统的重要组成部分,如果网络连接速度较慢,则一切都会运行缓慢。简单的网络统计信息(如接受和发送的字节数)可帮助我们识别网络问题。
高网络数据包冲突率以及过多的数据传输错误会导致传输瓶颈。需要使用netstat等工具来检查网络,看网络是否存在瓶颈。
二.Linux系统监控工具
为了找出正在运行的进程,最常使用Linux进程命令ps。当然,为了健康系统性能,需要使用比ps命令更复杂的工具。下面介绍可用于监控系统性能的一些重要工具。
1>.监测内存使用vmstat
[root@hadoop101.yinzhengjie.com ~]# vmstat -S M 1 输出如下图所示,个字段说明如下: procs(进程): r: 运行队列中进程数量 b: 等待IO的进程数量 memory(内存): swpd: 使用虚拟内存大小,我禁用了swap分区,因此你会看到虚拟内存始终为0。 free: 剩余空闲内存,即可用内存大小 buff: 用作缓冲的内存大小 cache: 用作缓存的内存大小 swap(虚拟内存我已经禁用了,因此该字段数值始终为0,我们忽略即可): si: 每秒从交换区写到内存的大小 so: 每秒写入交换区的内存大小 io:(磁盘I/O的情况统计信息) bi: 每秒读取的块数,块大小通常是4k,即(4096bytes)。当然,若也可以自定义了文件的块大小,这个我在之前的笔记已经分享过。 bo: 每秒写入的块数。 system(系统信息统计): in: 每秒中断(interrupt)数,包括时钟中断。 cs: 每秒上下文切换数,单位为:counts/second。 cpu(CPU的以百分比表示): us: 用户进程执行时间(user time) sy:
系统进程执行时间(system time) id:
空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。 wa:
等待IO时间

2>.使用meminfo查看内存使用情况和内存空闲情况
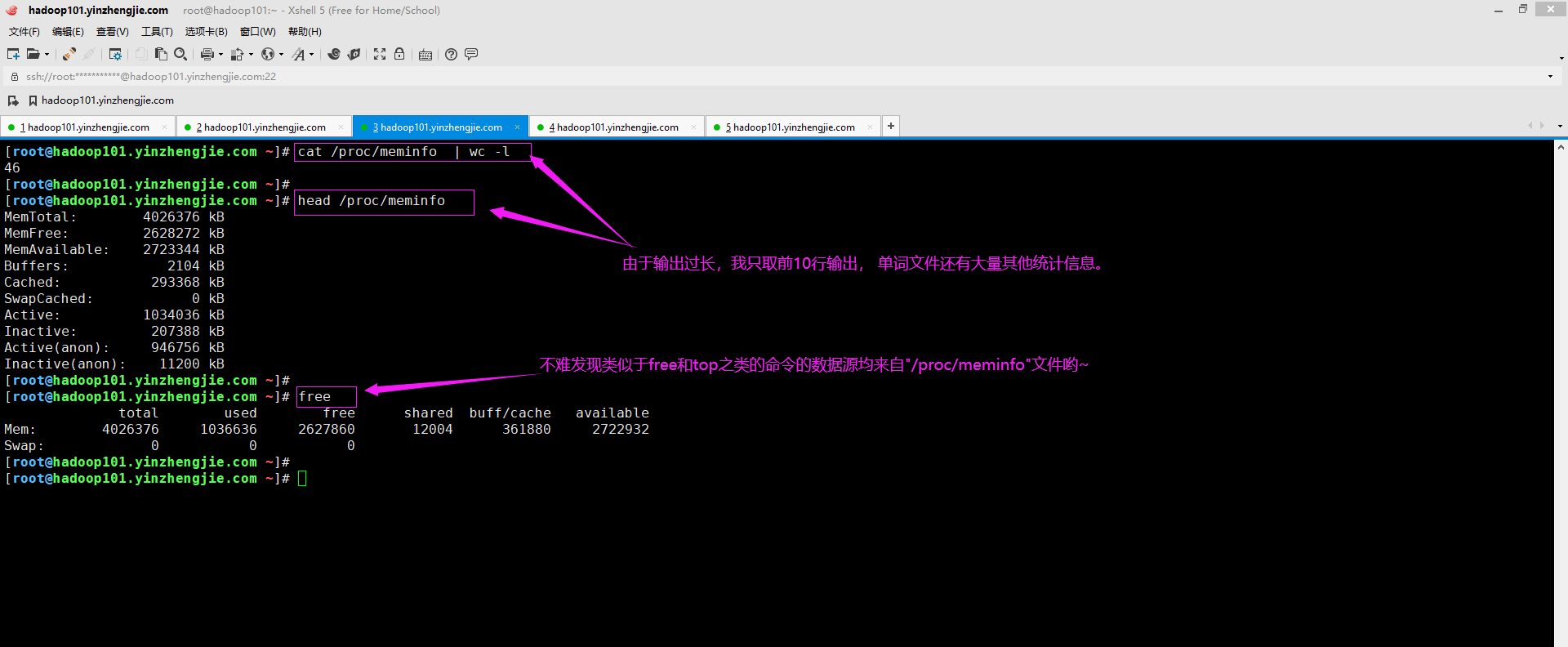
如下图所示,检查服务器内存使用情况的简单方法是使用"/proc/memeinfo"命令。许多Linux工具(如top,free)看了眼使用meminfo文件中的数据作为源。
3>.使用iostat查看I/O统计信息
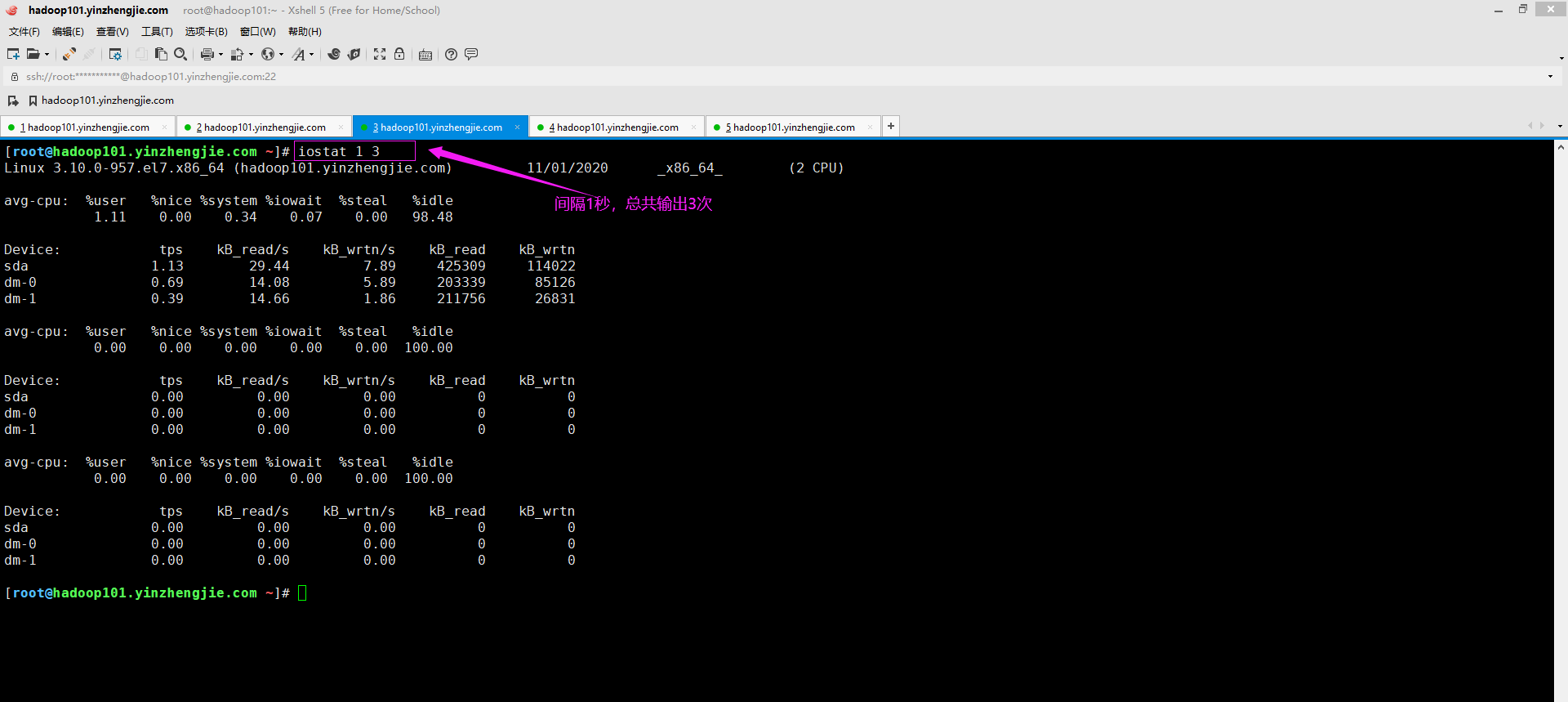
iostat使用程序可以提供程序上所有磁盘的输入/输出统计信息。 avg-cpu属性值说明: %user: CPU处在用户模式下的时间百分比。 %nice: CPU处在带NICE值的用户模式下的时间百分比。 %system: CPU处在系统模式下的时间百分比。 %iowait: CPU等待输入输出完成时间的百分比。若该值持续过高,则说明硬盘存在I/O瓶颈。 %steal: 管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。 %idle: CPU空闲时间百分比。若该值持续过高,则说明CPU比较空闲。 如果%idle值高但系统响应慢时,可能是CPU等待分配内存,应加大内存容量。 如果%idle值持续低于10,表明CPU处理能力相对较低,系统中最需要解决的资源是CPU。 Divice属性值说明: tps: 该设备每秒的传输次数 kB_read/s: 每秒从设备(drive expressed)读取的数据量; kB_wrtn/s: 每秒向设备(drive expressed)写入的数据量; kB_read: 读取的总数据量; kB_wrtn: 写入的总数量数据量; 温馨提示: 如果你是最小化安装,则可以先安装iostat工具,以CentOS发行版本为例,可在命令行中执行以下命令"yum -y install sysstat"进行安装即可。
4>.使用sar分析读/写操作
Linux sar(系统活动报告器)使用程序是一个非常强大的工具,它可以分析从磁盘到缓冲区花奴才能以及从缓冲区到磁盘的读/写操作。通过sar命令的各种选项,可以监视磁盘和CPU活动,以及缓冲区缓存活动。 如下图所示,这是一个典型的sar命令的输出,这里使用-u选项来监视服务器的CPU活动,每个1秒刷新一次,共计刷新10次。 主要看%iowait和%idle,%iowait过高表示存在I/O瓶颈,即磁盘IO无法满足业务需求,如果%idle过低表示CPU使用率比较严重,需要结合内存使用等情况判断CPU是否瓶颈。
以下是sar各字段的含义:
%user: 用户空间的CPU使用 %nice: 改变过优先级的进程的CPU使用率 %system: 内核空间的CPU使用率 %iowait: CPU等待IO的百分比 %steal: 虚拟机的虚拟机CPU使用的CPU %idle: 空闲的CPU

5>.使用top命令监视资源使用情况
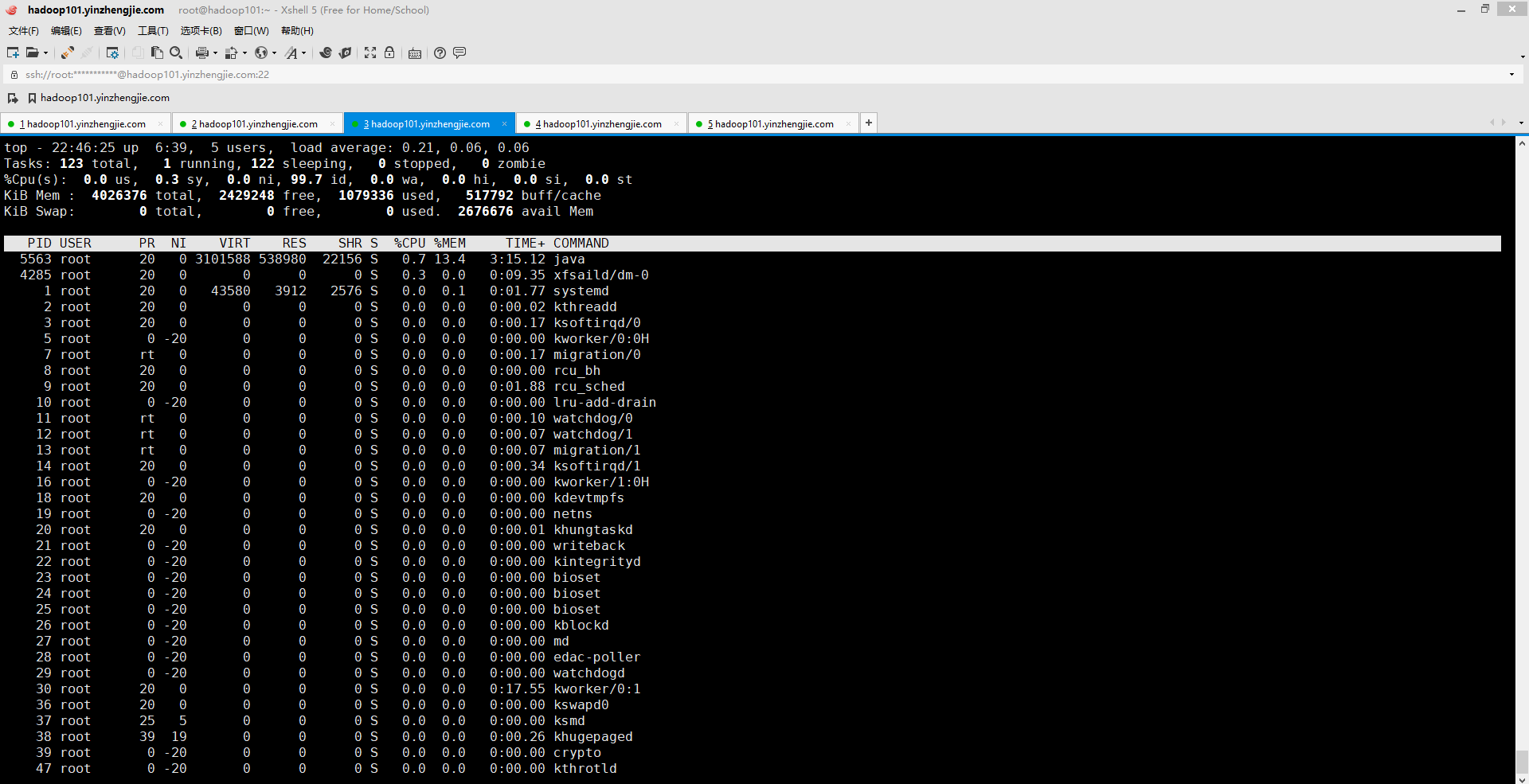
如下图所示,top命令可以查看哪些用户/进程使用的服务器资源最多。 CPU瓶颈抑郁识别,我们会看到非常高的处理器加载时间,例如80%或90%,甚至更高。还可以看到整个集群中的加载程序加载的时间大于50%或60%。由于涉及不当的hadoop作业,单个进程可能会占用太多的CPU时间。 在这种情况下,调整map或减少人为会降低CPU使用率。当然,切换到更快的处理器或添加更多处理器也有助于环节CPU争用问题。 可以通过查看上下文切换和中断来了解CPU争用情况。Linux操作系统是一个具有多核CPU的多任务系统。操作系统会在进程切换时存储称为上线文的CPU状态,从而从中断除恢复执行。 恢复上下文称为上下文切换。如果上下文切换次数过多,则表明CPU正忙,需花费大量时间存储/恢复进程状态。通常这是由于为每个节点分配太多map或减少任务造成的。 博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/10367853.html
6>.使用dstat进行网络监控
当在shuffle阶段,reduce任务获得map任务输出时,hadoop会大量使用网络。当reduce作业将结果输出到HDFS时,网络利用率也高。监控网络有助于识别潜在的网络瓶颈。 一个很好的网络监控工具(如dstat)可以显示网络的工作负载,下面有一些 有用的经验法则:
(1)如果网络数据速率约为网络带宽的20%或更高,则表示网络过载;
(2)高中断率表示网络流量超载,dstat工具还同时显示网络数据速率和中断数量,如下图所示。
温馨提示:
如果你的服务器未安装该命令,可以手动安装,以CentOS为例,可以执行"yum -y install dstat"命令进行安装。

三.开源的监控系统
开源的监控系统就多了去了,它们都可以监控Linux操作系统。比如Cacti,Nagios,Zabbix,Open Falcon,Prometheus,Ganglia等等。
每个开源监控系统都有自己擅长的领域,比如Cacti擅长监控网络设备,Nagios有很好的报警功能,Zabbix有不错的WebUI,Open Falcon可以监控数以万计的服务器,Prometheus擅长监控容器,Ganglia擅长大数据组件的监控等等。
温馨提示:
可以结合公司现有的应用,统一使用一个监控系统来监控所有应用。
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/13876422.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号