
Python爬虫〇三———稍微复杂的爬虫案例一
我们在前面学习了怎么写一个简单的爬虫,现在我们做一个比较复杂的爬虫——爬取KFC指定城市的门店信息。
需求分析
爬取KFC官网上指定城市的餐厅信息
网址:http://www.kfc.com.cn/kfccda/storelist/index.asp页面效果如下
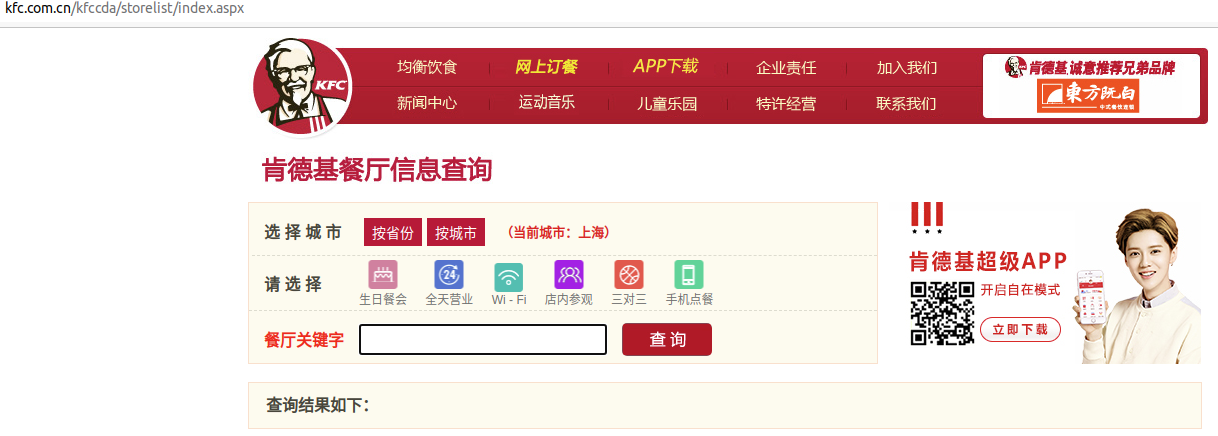
如果我们要查询西安市的KFC所有门店的信息,注意下面的效果

最下面是有个分页效果的,注意我们要拿到点是所有门店的信息。
流程分析
我们用浏览器的抓包工具看一下整个过程是怎么样的。
在输入西安后点击查询按钮,页面上会刷新一个table标签,我们随便输入一个店的地址搜一下
可以发现这个请求是个AJAX的请求过程,不是直接刷出来的。我们再看一看这个请求的请求头
Request URL: http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword
Request Method: POST
Status Code: 200 OK
Remote Address: 139.224.15.100:80
Referrer Policy: no-referrer-when-downgrade
这是一个POST请求,url已经明确出来了,可以从响应头上看出来响应的数据是文本格式的,但是这里在请求的时候是携带了参数的

这个keyword就是在指定的城市名,下面的pageIndex和pageSize是这么个意思:

在我们通过页码选择页数的时候,这个pageIndex就是我们点击的页码,而PageSize我们可以数一下,每次请求后页面上都是10个店面的信息。就是获取了十条数据。
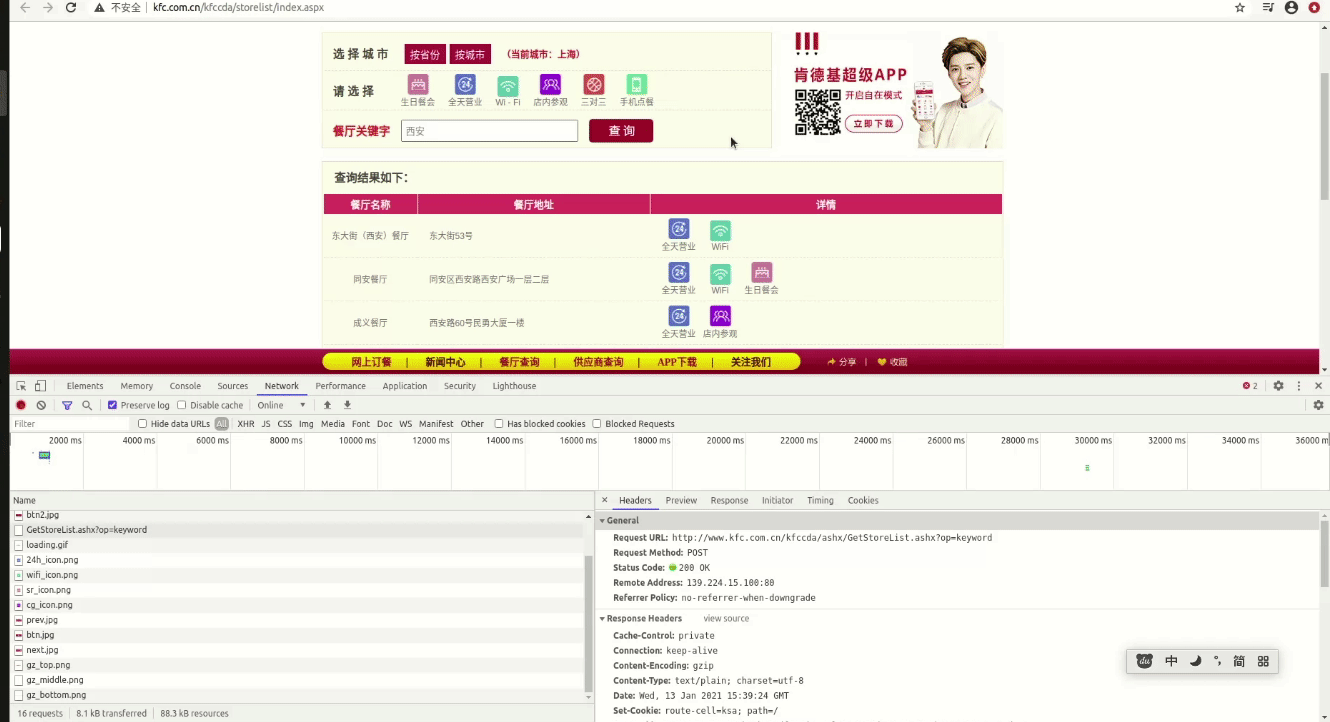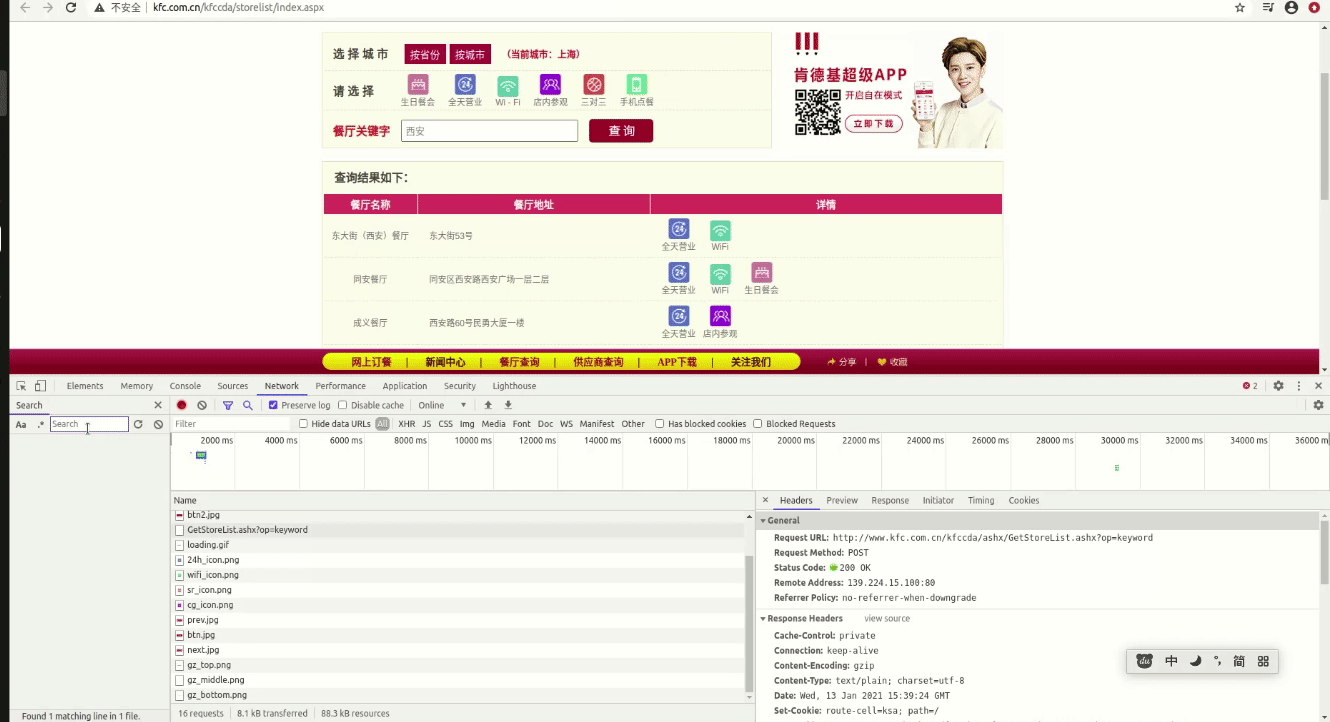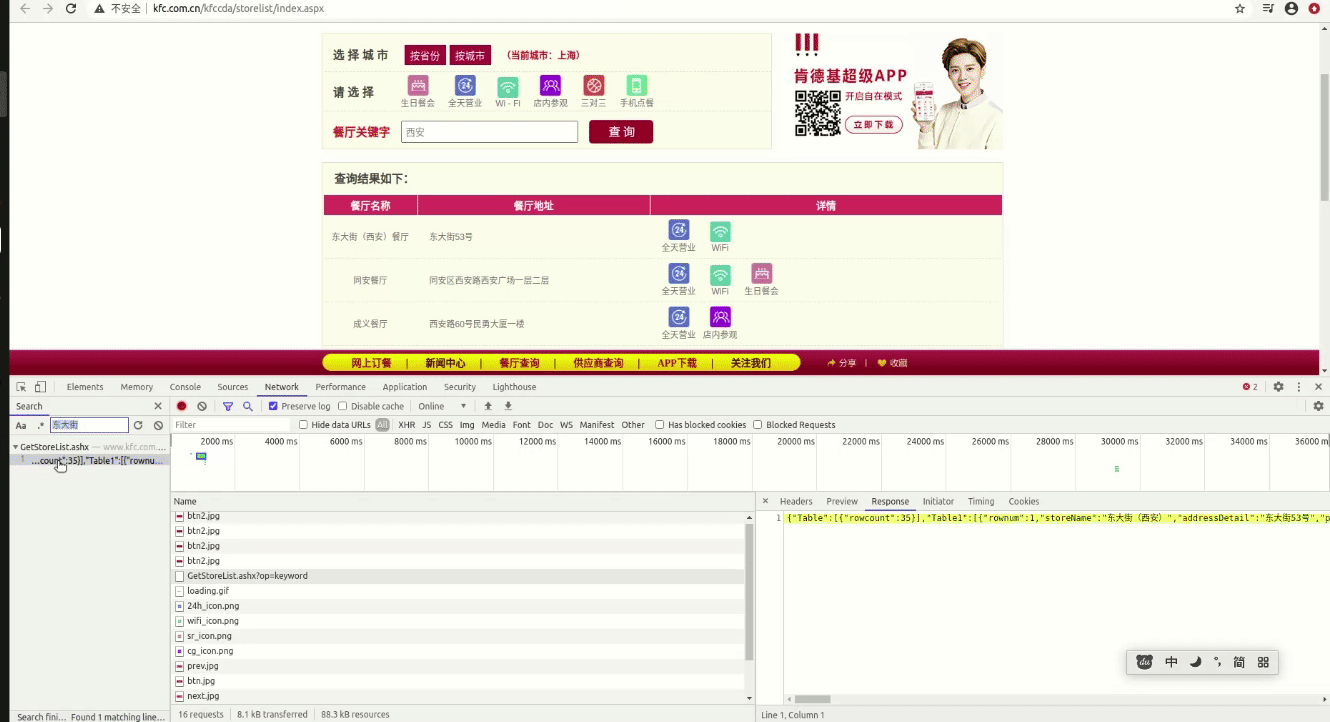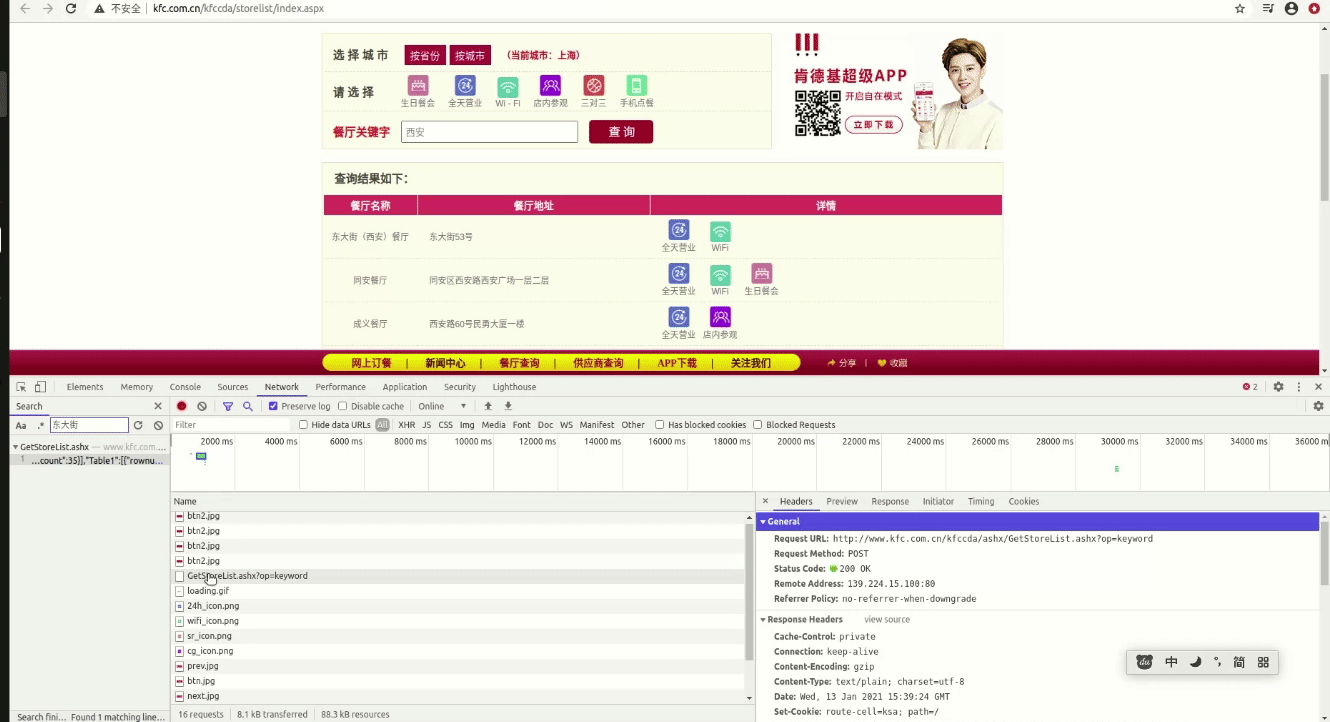
我们再看一看响应的内容,会发现一个很有意思的东西
{"Table":[{"rowcount":35}],"Table1":[{"rownum":21,"storeName":"西安咸宁","addressDetail":"咸宁中路122号乐宁会一层二层","pro":"Wi-Fi,店内参观,礼品卡,生日餐会","provinceName":"陕西省","cityName":"西安市"},{"rownum":22,"storeName":"西安含元","addressDetail":"太华路华东茶城一层","pro":"Wi-Fi,店内参观,礼品卡,生日餐会","provinceName":"陕西省","cityName":"西安市"},{"rownum":23,"storeName":"西安启航","addressDetail":"三桥街道启航时代广场一层","pro":"Wi-Fi,点唱机,礼品卡","provinceName":"陕西省","cityName":"西安市"},{"rownum":24,"storeName":"西安盛龙","addressDetail":"未央路80号盛龙广场1.2层","pro":"Wi-Fi,店内参观,礼品卡","provinceName":"陕西省","cityName":"西安市"},{"rownum":25,"storeName":"西安唐兴路","addressDetail":"高新区团结南路与唐兴路十字西南角睿中心一层","pro":"Wi-Fi,店内参观","provinceName":"陕西省","cityName":"西安市"},{"rownum":26,"storeName":"中央大道","addressDetail":"西安路107号中央大道4层","pro":"Wi-Fi,点唱机,店内参观","provinceName":"辽宁省","cityName":"大连市"},{"rownum":27,"storeName":"西安机场T3外卖","addressDetail":"咸阳国际机场T3航站楼到大厅一层","pro":"点唱机","provinceName":"陕西省","cityName":"咸阳市"},{"rownum":28,"storeName":"中央大道甜品站","addressDetail":"沙河口区西安路103-1.103-2.103-3号L4-007.L1-009-B商铺","pro":null,"provinceName":"辽宁省","cityName":"大连市"},{"rownum":29,"storeName":"西安火车站","addressDetail":"环城北路48号西安火车站西广场雨廊","pro":"Wi-Fi","provinceName":"陕西省","cityName":"西安市"},{"rownum":30,"storeName":"西安华为园区","addressDetail":"锦业路127号华为基地","pro":"精选店","provinceName":"陕西省","cityName":"西安市"}]}
是一个字典,第一项是个rowcount,就是所有信息的条数。那么就可以直接通过这个参数请求到所有的数据了!
import requests import json url ='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' head = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36' } city = input('输入城市:') data = {'cname': '', 'pid': '', 'keyword': city, 'pageIndex': '1', 'pageSize': '35', } resp = requests.post(url=url,headers=head,data=data) data = json.loads(resp.text) DataSize = data['Table'][0]['rowcount'] data = {'cname': '', 'pid': '', 'keyword': city, 'pageIndex': '1', 'pageSize': DataSize, } resp = requests.post(url=url,headers=head,data=data) print(resp.json()['Table1'])
相当于重新发一次POST请求,就可以了!后面数据持久化的过程这里就不再说了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号