

损失函数相关
参考:https://my.oschina.net/u/876354/blog/1940819
https://zhuanlan.zhihu.com/p/33560183
https://www.jianshu.com/p/cf235861311b
https://blog.csdn.net/rtygbwwwerr/article/details/50778098 交叉熵
0、交叉熵计算过程
参考: https://blog.csdn.net/qq_31829611/article/details/89195148
两个步骤: 1)softmax 2)计算 cross_entropy
1、典型场景(回归、分类)下的损失函数
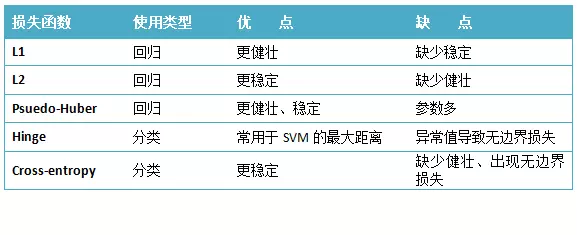
总结:对于回归问题经常会使用MSE均方误差(L2取平均)计算损失,对于分类问题经常会使用Sigmoid交叉熵损失函数。
2、典型损失函数的使用方式
2.1 L2正则损失函数(回归场景)
# L2损失
loss_l2_vals=tf.square(y_pred - y_target)
loss_l2_out=sess.run(loss_l2_vals)
# 均方误差
loss_mse_vals= tf.reduce.mean(tf.square(y_pred - y_target))
loss_mse_out = sess.run(loss_mse_vals)
2.2 tf.nn.sigmoid_cross_entropy_with_logits(分类场景)
- 计算方式:labels和logits的形状都是[batch_size, num_classes],对输入的logits先通过sigmoid函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得的结果不至于溢出。
- 适用:每个类别相互独立但互不排斥的情况:例如一幅图可以同时包含一条狗和一只大象。
- output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用。
由于每个类别互不排斥,输出结果都不是有效的概率分布(一个batch内输出结果经过sigmoid后和不为1),那么如何计算他们的交叉熵呢(交叉熵要求输入的是概率分布)。其实loss的计算是element-wise的,方法返回的loss的形状和labels是相同的,也是[batch_size, num_classes],再调用reduce_mean方法计算batch内的平均loss。所以这里的cross entropy其实是一种class-wise的cross entropy,每一个class是否存在都是一个事件,对每一个事件都求cross entropy loss,再对所有的求平均,作为最终的loss。
import tensorflow as tf
import numpy as np
def sigmoid(x):
return 1.0/(1+np.exp(-x))
# 5个样本三分类问题,且一个样本可以同时拥有多类
y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,1,0],[0,1,0]]
logits = np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]])
# 按计算公式计算
y_pred = sigmoid(logits)
E1 = -y*np.log(y_pred)-(1-y)*np.log(1-y_pred)
print(E1) # 按计算公式计算的结果
# 按封装方法计算
sess =tf.Session()
y = np.array(y).astype(np.float64) # labels是float64的数据类型
E2 = sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=y,logits=logits))
print(E2) # 按 tf 封装方法计算
#交叉熵计算方式 tf.reduce_sum
loss = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(labels=y,logits=logits))
#loss 计算方式 tf.reduce_mean
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y,logits=logits))
#归一化
sigmoid_v = tf.nn.sigmoid(logits, -1)
#类是互斥时,返回多个类别
# 预测权重
pred_probs = sigmoid_v # 示例,分类是互斥时,这里返回值不是单个值,是向量
#如果只返回最大可能性的类别
pred_prob = tf.reduce_max(sigmoid_v) #预测权重
pred_label = tf.argmax(logits, axis=-1, name='label') # 预测类别
if E1.all() == E2.all():
print("True")
else:
print("False")
# 输出的E1,E2结果相同
注意:sigmoid_cross_entropy_with_logits函数的返回值并不是一个数,而是一个向量。如果要求交叉熵,需要使用tf.reduce_sum求和,即对向量里面所有元素求和;如果求loss,使用tf.reduce_mean求均值,对向量求均值!
2.3 tf.nn.softmax_cross_entropy_with_logits(分类场景)
- labels:和logits具有相同type和shape的张量(tensor),,是一个有效的概率,sum(labels)=1, one_hot=True(向量中只有一个值为1.0,其他值为0.0)。
- 计算方式:对输入的logits先通过softmax函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。
- 适用:每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象。
- output:不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用。
import tensorflow as tf
import numpy as np
def softmax(x):
sum_raw = np.sum(np.exp(x),axis=-1)
x1 = np.ones(np.shape(x))
for i in range(np.shape(x)[0]):
x1[i] = np.exp(x[i])/sum_raw[i]
return x1
y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,0,0],[0,1,0]])# 每一行只有一个1
logits =np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]])
# 按计算公式计算
y_pred =softmax(logits)
E1 = -np.sum(y*np.log(y_pred),-1)
print(E1)
# 按封装方法计算
sess = tf.Session()
y = np.array(y).astype(np.float64)
E2 = sess.run(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=logits))
print(E2)
#交叉熵计算方式
loss = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=logits))
#loss 计算方式
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=logits))
# 归一化
pred_probs = tf.nn.softmax(logits)
#取归一化后的最大值
max_pred_prob = tf.reduce_max(pred_probs, axis=-1)
# 预测类别
pred_label = tf.argmax(logits, axis=-1, name='label')
if E1.all() == E2.all():
print("True")
else:
print("False")
# 输出的E1,E2结果相同
2.4 tf.nn.sparse_softmax_cross_entropy_with_logits(分类场景)
这个版本是tf.nn.softmax_cross_entropy_with_logits的易用版本,其logits的形状依然是[batch_size, num_classes],但是labels的形状是[batch_size, ],每个label的取值是从[0, num_classes)的离散值,这也更加符合我们的使用习惯,是哪一类就标哪个类对应的label。
如果已经对label进行了one hot编码,则可以直接使用tf.nn.softmax_cross_entropy_with_logits。
- labels:shape为[batch_size],labels[i]是{0,1,2,……,num_classes-1}的一个索引, type为int32或int64
- 计算方式:对输入的logits先通过softmax函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。
- 适用:每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象 。
- output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用。
import tensorflow as tf
labels = [0,2] #labels形式与softmax_cross_entropy_with_logits不同
logits = [[2,0.5,1],
[0.1,1,3]]
E1 = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits)
with tf.Session() as sess:
print sess.run(E1)
>>>[ 0.46436879 0.17425454]
总结:到底是用sigmoid版本的cross entropy还是softmax版本的cross entropy主要取决于我们模型的目的,以及label的组织方式,这个需要大家在使用的时候去揣摩,到底使用哪一种loss比较合理。
3、Symmetric Cross Entropy
参考: https://blog.csdn.net/jackzhang11/article/details/116197889
如何在标注存在错误(Noisy label)的数据上训练模型一直是机器学习/深度学习中一个重要且有挑战性的任务。Cross Entropy机器学习分类任务中常用的目标函数,然而它在不同类别上的学习速度却是很不一致,在部分类别上可能很快就对错误的标签发生过拟合,对其他类别可能还出去欠拟合状态。这里介绍的Symmetric Cross Entropy,用于缓解这个问题。

其中p是预测结果,q是训练label。 计算举例:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号