在上一篇《从Chrome源码看浏览器如何构建DOM树》介绍了blink如何创建一棵DOM树,在这一篇将介绍事件机制。
上一篇还有一个地方未提及,那就是在构建完DOM之后,浏览器将会触发DOMContentLoaded事件,这个事件是在处理tokens的时候遇到EndOfFile标志符时触发的:
|
|
if(it->type()==HTMLToken::EndOfFile){
// The EOF is assumed to be the last token of this bunch.
ASSERT(it+1==tokens->end());
// There should never be any chunks after the EOF.
ASSERT(m_speculations.isEmpty());
prepareToStopParsing();
break;
}
|
上面代码第1行,遇到结尾的token时,将会在第6行停止解析。这是最后一个待处理的token,一般是跟在</html>后面的一个\EOF标志符来的。
第6行的prepareToStopParsing,会在Document的finishedParseing里面生成一个事件,再调用dispatchEvent,进一步调用监听函数:
|
|
voidDocument::finishedParsing(){
dispatchEvent(Event::createBubble(EventTypeNames::DOMContentLoaded));
}
|
这个dispatchEvent是EventTarget这个类的成员函数。在上一篇描述DOM的结点数据结构时将Node作为根结点,其实Node上面还有一个类,就是EventTarget。我们先来看一下事件的数据结构是怎么样的:
1. 事件的数据结构
画出事件相关的类图:
![]()
在最顶层的EventTarget提供了三个函数,分别是添加监听add、删除监听remove、触发监听fire。一个典型的访问者模式我在《Effective前端5:减少前端代码耦合》提到了,这里重点看一下blink实际上是怎么实现的。
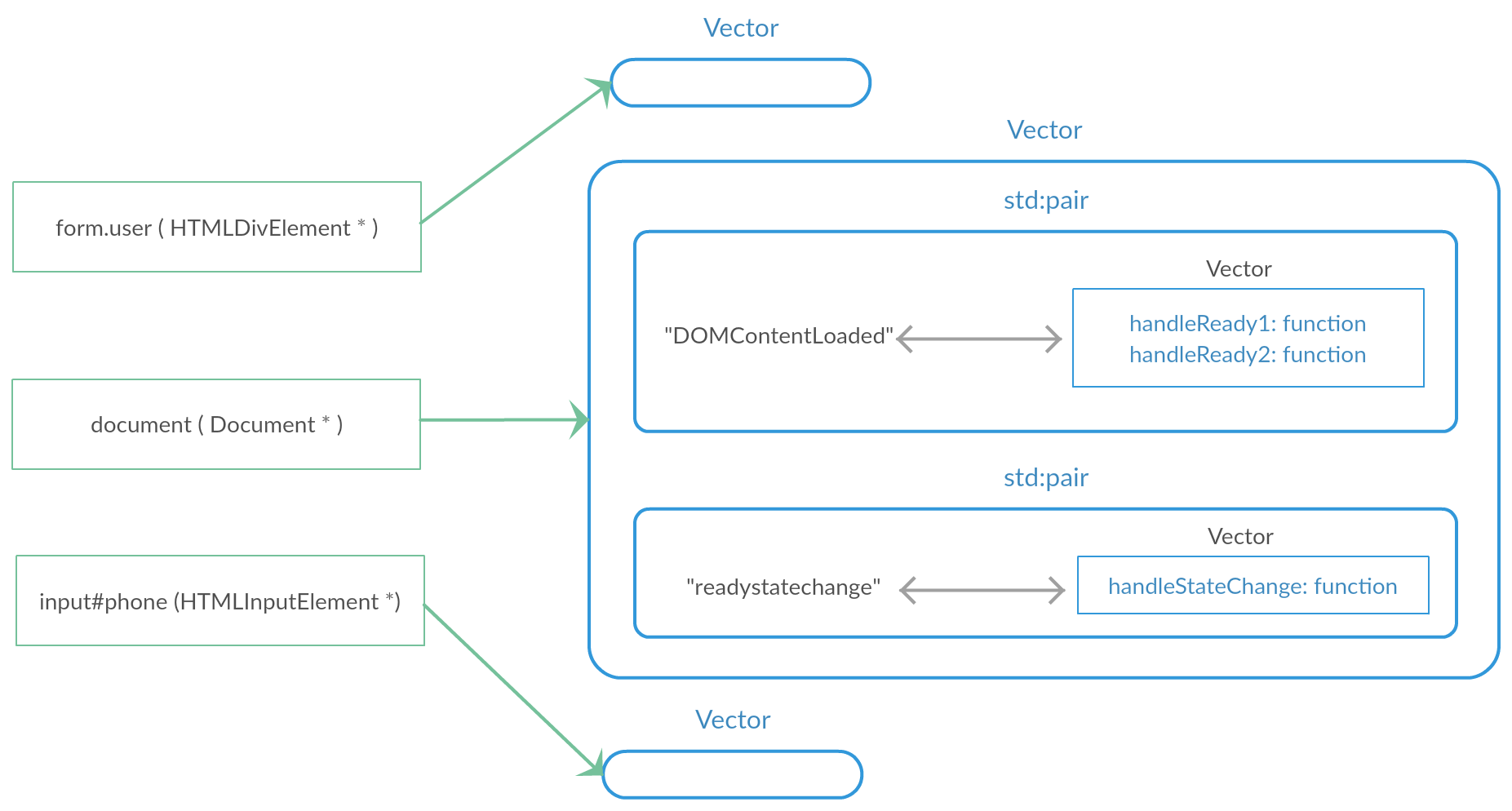
在Node类组合了一个EventTargetDataMap,这是一个哈希map,并且它是静态成员变量。它的key值是当前结点Node实例的指针,value值是事件名称和对应的listeners。如果画一个示例图,它的存储是这样的:
![]()
如上,按照正常的思维,存放事件名称和对应的访问者应该是用一个哈希map,但是blink却是用的向量vector + pair,这就导致在查找某个事件的访问者的时候,需要循环所有已添加的事件名称依次比较字符串值是否相等。为什么要用循环来做而不是map,这在它的源码注释做了说明:
|
|
// We use HeapVector instead of HeapHashMap because
// - HeapVector is much more space efficient than HeapHashMap.
// - An EventTarget rarely has event listeners for many event types, and
// HeapVector is faster in such cases.
HeapVector<std::pair<AtomicString,Member<EventListenerVector>>,2>m_entries;
|
意思是说使用vector比使用map更加节省空间,并且一个dom节点往往不太可能绑了太多的事件类型。这就启示我们写代码要根据实际情况灵活处理。
同时还有一个比较有趣的事情,就是webkit用了一个EventTargetDataMap存放所有节点绑定的事件,它是一个static静态成员变量,被所有Node的实例所共享,由于不同的实例的内存地址不一样,所以它的key不一样,就可以通过内存地址找到它绑的所有事件,即上面说的vector结构。为什么它要用一个类似于全局的变量?按照正常思维,每个Node结点绑的事件是独立的,那应该把绑的事件作为每个Node实例独立的数据,搞一个全局的还得用一个map作一个哈希映射。
一个可能的原因是EventTarget是作为所有DOM结点的事件目标的类,除了Node之外,还有FileReader、AudioNode等也会继承于EventTarget,它们有另外一个EventTargetData。把所有的事件都放一起了,应该会方便统一处理。
这个时候你可能会冒出另外一个问题,这个EventTargetDataMap是什么释放绑定的事件的,我把一个DOM结点删了,它会自动去释放绑定的的事件吗?换句话说,删除掉一个结点前需不需要先off掉它的事件?
2. DOM结点删除与事件解绑
从源码可以看到,Node的析构函数并没有去释放当前Node绑定的事件,所以它是不是不会自动释放事件?为验证,我们在添加绑定一个事件后、删掉结点后分别打印这个map里面的数据,为此给Node添加一个打印的函数:
|
|
voidNode::printEventMap(){
EventTargetDataMap::iterator it=eventTargetDataMap().begin();
LOG(INFO)<<"print event map: ";
while(it!=eventTargetDataMap().end()){
LOG(INFO)<<((Element*)it->key.get())->tagName();
++it;
}
}
|
在上面的第5行,循环打印出所有Node结点的标签名。
同时试验的html如下:
|
|
<p id="text">hello, world</p>
<script>
functionclickHandle(){
console.log("click");
}
document.getElementById("text").addEventListener("click",clickHandle);
document.getElementById("text").remove();
document.addEventListener("DOMContentLoaded",function(){
console.log("loaded");
});
</script>
|
打印的结果如下:
[21755:775:0204/181452.402843:INFO:Node.cpp(1910)] print event map:
[21755:775:0204/181452.403048:INFO:Node.cpp(1912)] “P”
[21755:775:0204/181452.404114:INFO:Node.cpp(1910)] print event map:
[21755:775:0204/181452.404287:INFO:Node.cpp(1912)] “P”
[21755:775:0204/181452.404466:INFO:Node.cpp(1912)] “#document”
可以看到remove了p结点之后,它的事件依然存在。
我们看一下blink在remove里面做了什么:
|
|
voidNode::remove(ExceptionState&exceptionState){
if(ContainerNode*parent=parentNode())
parent->removeChild(this,exceptionState);
}
|
remove是后来W3C新加的api,所以在remove里面调的是老的removeChild,removeChild的关键代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
Node*previousChild=child->previousSibling();
Node*nextChild=child->nextSibling();
if(nextChild)
nextChild->setPreviousSibling(previousChild);
if(previousChild)
previousChild->setNextSibling(nextChild);
if(m_firstChild==&oldChild)
setFirstChild(nextChild);
if(m_lastChild==&oldChild)
setLastChild(previousChild);
oldChild.setPreviousSibling(nullptr);
oldChild.setNextSibling(nullptr);
oldChild.setParentOrShadowHostNode(nullptr);
|
前面几行是重新设置DOM树的结点关系,比较好理解。最后面三行,把删除掉的结点的兄弟指针和父指针置为null,注意这里并没有把它delete掉,只是把它隔离开来。所以把它remove掉之后, 这个结点在内存里面依旧存在,你依然可以获取它的innerText,把它重新append到body里面(但是不推荐这么做)。同时事件依然存在那个map里面。
什么时候这个节点会被真正的析构呢?发生在GC回收的时候,GC回收的时候会把DOM结点的内存释放,并且会删掉map里面的数据。为验证,在启动Chrome的时候加上参数:
|
|
chromium test.html --js-flags='--expose_gc'
|
这样可以调用window.gc触发gc回收,然后在上面的js demo代码后面加上:
|
|
setTimeout(function(){
//添加这个事件是为了触发Chrome源码里面添加的打印log
document.addEventListener("DOMContentLoaded",function(){});
setTimeout(function(){
window.gc();
document.addEventListener("DOMContentLoaded",function(){});
},3000);
},3000);
|
打印的结果:
[Node.cpp(1912)] print event map:
[Node.cpp(1914)] “P”
[Node.cpp(1914)] “#document”
[Element.cpp(186)] destroy element “p”
[Node.cpp(1912)] print event map:
[Node.cpp(1914)] “#document”
后面三行是执行了GC回收后的结果——析构p标签并更新存放事件的数据结构。
所以说删掉一个DOM结点,并不需要手动去释放它的事件。
需要注意的是DOM结点一旦存在一个引用,即使你把它remove掉了,GC也不会去回收,如下:
|
|
<script>
varp=document.getElementById("text");
p.remove();
window.gc();
</script>
|
执行了window.gc之后并不会去回收p的内存空间以及它的事件。因为还存在一个p的变量指向它,而如果将p置为null,如下:
|
|
<script>
varp=document.getElementById("text");
p.remove();
p=null;
window.gc();
</script>
|
最后的GC就管用了,或者p离开了作用域:
|
|
<script>
!function(){
varp=document.getElementById("text");
p.remove();
}()
window.gc();
</script>
|
自动销毁,p结点没有人引用了,能够自动GC回收。
还有一个问题一直困扰着我,那就是监听X按钮的click,然后把它的父容器如弹框给删了,这样它自已本身也删了,但是监听函数还可以继续执行,实体都没有了,为什么绑在它身上的函数还可以继续执行呢?通过上面的分析,应该可以找到答案:删掉之后GC并不会立刻回收和释放事件,因为在执行监听函数的时候,里面有个this指针指向了该节点,并且this是只读的,你不能把它置成null。所以只有执行完了回调函数,离开了作用域,this才会销毁,才有可能被GC回收。
还有一种绑事件的方式,没有讨论:
3. DOM Level 0事件
就是使用dom结点的onclick、onfocus等属性,添加事件,由于这个提得比较早,所以它的兼容性最好。如下:
|
|
functionclickHandle(){
console.log("addEventListener click");
}
varp=document.getElementById("text");
p.addEventListener("click",clickHandle);
p.onclick=function(){
console.log("onclick trigger");
};
|
如果点击p标签,将会触发两次,一次是addEventListener绑定的,另一次是onclick绑定的。onclick是如何绑定的呢:
|
|
boolEventTarget::setAttributeEventListener(constAtomicString&eventType,
EventListener*listener){
clearAttributeEventListener(eventType);
if(!listener)
returnfalse;
returnaddEventListener(eventType,listener,false);
}
|
可以看到,最后还是调的上面的addEventListener,只是在此之前要先clear掉上一次绑的属性事件:
|
|
boolEventTarget::clearAttributeEventListener(constAtomicString&eventType){
EventListener*listener=getAttributeEventListener(eventType);
if(!listener)
returnfalse;
returnremoveEventListener(eventType,listener,false);
}
|
在clear函数里面会去获取上一次的listener,然后调removeEventListener,关键在于它怎么根据事件名称eventType获取上次listener呢:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
EventListener*EventTarget::getAttributeEventListener(
constAtomicString&eventType){
EventListenerVector*listenerVector=getEventListeners(eventType);
if(!listenerVector)
returnnullptr;
for(auto&eventListener:*listenerVector){
EventListener*listener=eventListener.listener();
if(listener->isAttribute()/* && ... */)
returnlistener;
}
returnnullptr;
}
|
在代码上看很容易理解,首先获取该DOM结点该事件名称的所有listener做个循环,然后判断这个listener是否为属性事件。判断成立,则返回。怎么判断是否为属性事件?那个是实例化事件的时候封装好的了。
从上面的源代码可以很清楚地看到onclick等属性事件只能绑一次,并且和addEventListener的事件不冲突。
关于事件,还有一个很重要的概念,那就是事件的捕获和冒泡。
4. 事件的捕获和冒泡
用以下html做试验:
|
|
<div id="div-1">
<div id="div-2">
<div id="div-3">hello, world</div>
</div>
</div>
|
js绑事件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
vardiv1=document.getElementById("div-1"),
div2=document.getElementById("div-2"),
div3=document.getElementById("div-3");
functionprintInfo(event){
console.log(“eventPhase=“+””event.eventPhase+" "+this.id);
}
div1.addEventListener("click",printInfo,true);
div2.addEventListener("click",printInfo,true);
div3.addEventListener("click",printInfo,true);
div1.addEventListener("click",printInfo);
div2.addEventListener("click",printInfo);
div3.addEventListener("click",printInfo);
|
第三个参数为true,表示监听在捕获阶段,点击p标签之后控制台打印出:
[CONSOLE] “eventPhase=1 div-1”
[CONSOLE] “eventPhase=1 div-2”
[CONSOLE] “eventPhase=2 div-3”
[CONSOLE] “eventPhase=2 div-3”
[CONSOLE] “eventPhase=3 div-2”
[CONSOLE] “eventPhase=3 div-1”
在Event类定义里面可以找到关到eventPhase的定义:
|
|
enumPhaseType{
kNone=0,
kCapturingPhase=1,
kAtTarget=2,
kBubblingPhase=3
};
|
1表示捕获取阶段,2表示在当前目标,3表示冒泡阶段。把上面的phase转化成文字,并把html/body/document也绑上事件,同时at-target只绑一次,那么整一个过程将是这样的:
“capture document”
“capture HTML”
“capture BODY”
“capture DIV#div-1”,
“capture DIV#div-2”,
“at-target DIV#div-3”,
“bubbling DIV#div-2”,
“bubbling DIV#div-1”,
“bubbling BODY”
“bubbling HTML”
“bubbling document”
从document一直捕获到目标div3,然后再一直冒泡到document,如果在某个阶段执行了:
那么后续的过程将不会继续,例如在document的capture阶段的click事件里面执行了上面的阻止传播函数,那么控制台只会打印出上面输出的第一行。
在研究blink是如何实现之前,我们先来看一下事件是怎么触发和封装的
5. 事件的触发和封装
以click事件为例,Blink在RenderViewImpl里面收到了外面的进程的消息:
|
|
// IPC::Listener implementation ----------------------------------------------
boolRenderViewImpl::OnMessageReceived(constIPC::Message&message){
// Have the super handle all other messages.
IPC_MESSAGE_UNHANDLED(handled=RenderWidget::OnMessageReceived(message))
}
|
上文已提到,RenderViewImpl是页面最基础的一个类,当它收到IPC发来的消息时,根据消息的类型,调用相应的处理函数,由于这是一个input消息,所以它会调:
|
|
IPC_MESSAGE_HANDLER(InputMsg_HandleInputEvent,OnHandleInputEvent)
|
上面的IPC_MESSAGE_HANDLER其实是Blink定义的一个宏,这个宏其实就是一个switch-case里面的case。
这个处理函数又会调:
|
|
WebInputEventResult WebViewImpl::handleInputEvent(
constWebInputEvent&inputEvent){
switch(inputEvent.type){
caseWebInputEvent::MouseUp:
eventType=EventTypeNames::mouseup;
gestureIndicator=WTF::wrapUnique(
newUserGestureIndicator(m_mouseCaptureGestureToken.release()));
break;
}
}
|
它里面会根据输入事件的类型如mouseup、touchstart、keybord事件等类型去调不同的函数。click是在mouseup里面处理的,接着在MouseEventManager里面创建一个MouseEvent,并调度事件,即捕获和冒泡:
|
|
WebInputEventResult MouseEventManager::dispatchMouseEvent(EventTarget*target,constAtomicString&mouseEventType,constPlatformMouseEvent&mouseEvent,EventTarget*relatedTarget,boolcheckForListener){
MouseEvent*event=MouseEvent::create(mouseEventType,targetNode->document().domWindow(),mouseEvent/*...*/);
DispatchEventResult dispatchResult=target->dispatchEvent(event);
returnEventHandlingUtil::toWebInputEventResult(dispatchResult);
}
|
上面代码第2行创建MouseEvent,第3行dispatch。我们来看一下这个事件是如何层层封装成一个MouseEvent的:
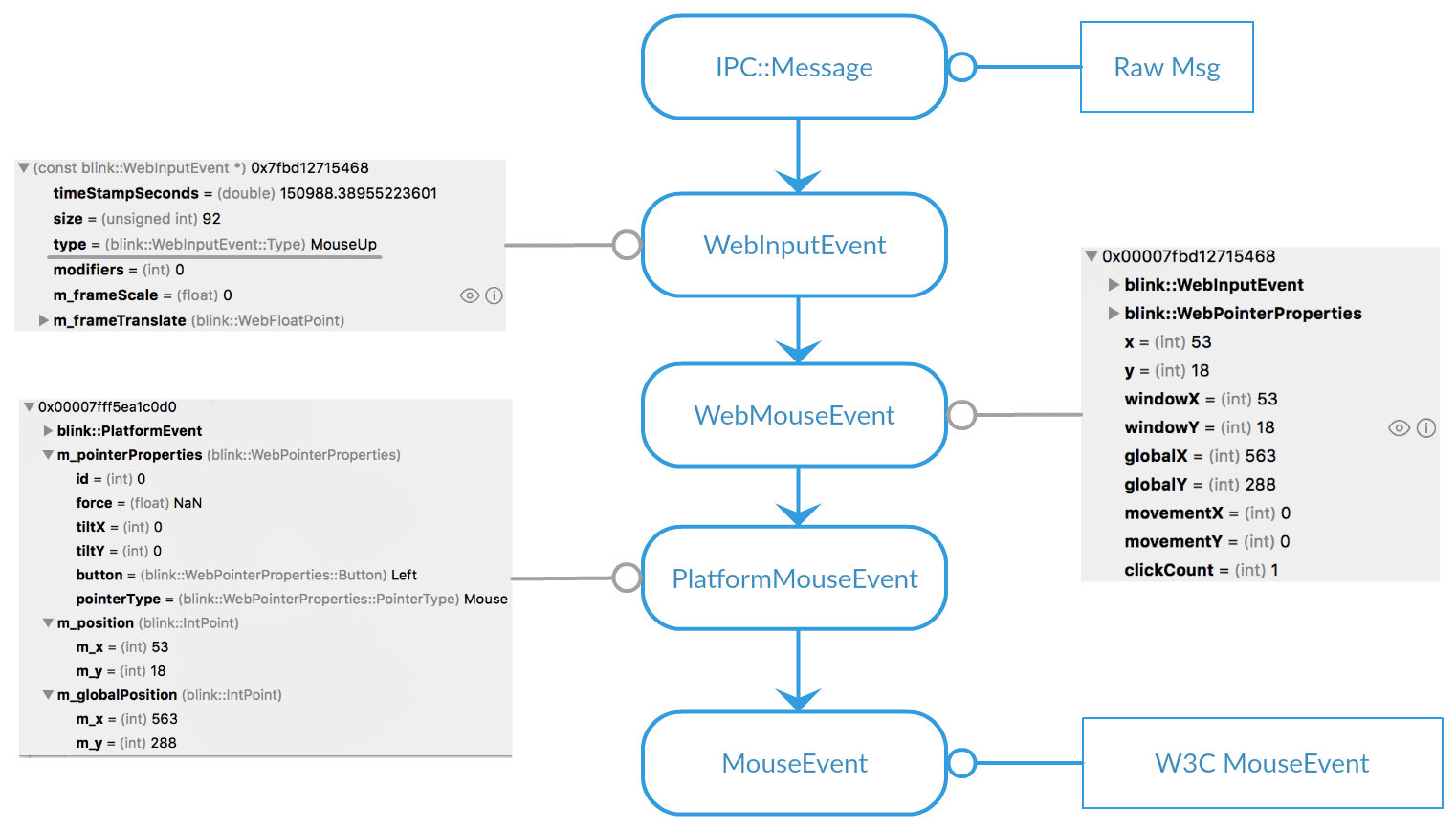
![]()
上图展示了从原始的msg转化成了W3C标准的MouseEvent的过程。Blink的消息处理引擎把msg转化成了WebInputEvent,这个event能够直接静态转化成可读的WebMouseEvent,也就是事件在底层的时候已经被封装成带有相关数据且可读的事件了,上层再把它这些数据转化成W3C规定格式的MouseEvent。
我们重点看下MouseEvent的create函数:
|
|
MouseEvent*MouseEvent::create(constAtomicString&eventType,AbstractView*view,constPlatformMouseEvent&event,Node*relatedTarget){
boolisMouseEnterOrLeave=eventType==EventTypeNames::mouseenter||
eventType==EventTypeNames::mouseleave;
boolisCancelable=!isMouseEnterOrLeave;
boolisBubbling=!isMouseEnterOrLeave;
returnMouseEvent::create(
eventType,isBubbling,isCancelable,view,event.position().x()
/*.../*,&event);
}
|
从代码第五行可以看到鼠标事件的mouseenter和mouseleave是不会冒泡的。
另外,每个Event都有一个EventPath,记录它冒泡的路径:
![]()
在dispatchEvent的时候,会初始化EventPath:
|
|
voidEventPath::initialize(){
if(eventPathShouldBeEmptyFor(*m_node,m_event))
return;
calculatePath();
calculateAdjustedTargets();
calculateTreeOrderAndSetNearestAncestorClosedTree();
}
|
第五行会去计算Path,而这个计算Path的核心逻辑非常简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
voidEventPath::calculatePath(){
// For performance and memory usage reasons we want to store the
// path using as few bytes as possible and with as few allocations
// as possible which is why we gather the data on the stack before
// storing it in a perfectly sized m_nodeEventContexts Vector.
HeapVector<Member<Node>,64>nodesInPath;
Node*current=m_node;
nodesInPath.push_back(current);
while(current){
current=current->parentNode();
if(current)
nodesInPath.push_back(current);
}
m_nodeEventContexts.reserveCapacity(nodesInPath.size());
for(Node*nodeInPath:nodesInPath){
m_nodeEventContexts.push_back(NodeEventContext(
nodeInPath,eventTargetRespectingTargetRules(*nodeInPath)));
}
}
|
第9行的while循环不断地获取当前node的父节点并把它push到一个vector里面,直到null即没有父节点为止。最后再把这个vector push到真正用来存储成员变量。这段代码我们又发现一个有趣的注释,它说明了为什么不直接push到成员变量里面——因为vector变量会自动扩展本身大小,当push的时候容量不足时,会不断地开辟内存,blink的实现是开辟一个单位元素的空间,刚好存放一个元素:
|
|
ptr=expandCapacity(size()+1,ptr);
|
所以如果直接push_back到成员变量,会不断地开辟新内存。于是它一开始就初始化了一个size为64的栈变量来存放,减少开辟内存的操作。另外有些vector自动扩充容量的实现,可能是size * 1.5或者size + 10,而不是size + 1,这种情况就会导致有多余的空间没用到。
通过这样的手段,就有了记录事件冒泡路径的EventPath。
6. 事件捕获和冒泡的实现
上面第5点提到的MouseEventManager会调dispatchEvent,这个函数会先创建一个dispatcher,这个dispatcher实例化的时候就会去初始化上面的EventPath,然后再进行dispatch/事件调度:
|
|
EventDispatcher dispatcher(node,&mediator->event());
DispatchEventResult dispatchResult=dispatcher.dispatch();
|
所以核心函数就是第2行调的dispatch,而这个函数最核心的3行代码为:
|
|
if(dispatchEventAtCapturing()==ContinueDispatching){
if(dispatchEventAtTarget()==ContinueDispatching)
dispatchEventAtBubbling();
}
|
(1)先执行Capturing,然后再执行AtTarget,最后再Bubbling,我们来看一下Capturing函数:
|
|
inlineEventDispatchContinuation EventDispatcher::dispatchEventAtCapturing(){
// Trigger capturing event handlers, starting at the top and working our way
// down.
//改变event的阶段为冒泡
m_event->setEventPhase(Event::kCapturingPhase);
//先处理绑在window上的事件,并且如果event的m_propagationStopped被设置为true
//则返回done状态,不再继续传播
if(m_event->eventPath().windowEventContext().handleLocalEvents(*m_event)&&
m_event->propagationStopped())
returnDoneDispatching;
|
上面做了一些初始化的工作后,循环EventPath依次触发响应函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
//从EventPath最后一个元素,即最顶层的父结点开始下滤
for(size_ti=m_event->eventPath().size()-1;i>0;--i){
constNodeEventContext&eventContext=m_event->eventPath()[i];
//触发事件响应函数
eventContext.handleLocalEvents(*m_event);
//如果响应函数设置了stopPropagation,则返回done
if(m_event->propagationStopped())
returnDoneDispatching;
}
returnContinueDispatching;
}
|
注意上面的for循环终止条件的i是大于0,i为0则为currentTarget。而总的size为6,与我们上面demo控制台打印一致。
(2)at-target的处理就很简单了,取i为0的那个Node并触发它的listeners:
|
|
inlineEventDispatchContinuation EventDispatcher::dispatchEventAtTarget(){
m_event->setEventPhase(Event::kAtTarget);
m_event->eventPath()[0].handleLocalEvents(*m_event);
returnm_event->propagationStopped()?DoneDispatching:ContinueDispatching;
}
|
(3)bubbling的处理稍复杂,因为它还要处理cancleBubble的情况,不过总体的逻辑是类似的,核心代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
inlinevoidEventDispatcher::dispatchEventAtBubbling(){
// Trigger bubbling event handlers, starting at the bottom and working our way
// up.
size_t size=m_event->eventPath().size();
for(size_ti=1;i<size;++i){
constNodeEventContext&eventContext=m_event->eventPath()[i];
if(m_event->bubbles()&&!m_event->cancelBubble()){
m_event->setEventPhase(Event::kBubblingPhase);
}
eventContext.handleLocalEvents(*m_event);
if(m_event->propagationStopped())
return;
}
}
|
可以看到bubbling的for循环是从i = 1开始,和capturing相反。因为bubble是三个阶段最后处理的,所以它不用再返回一个标志了。
上面介绍完了事件的捕获和冒泡,我们注意到一个细节,所有的事件都会先在capture阶段在windows上触发。
综合以上,本文从源码角度介绍了事件的数据结构,从一个侧面解绑事件介绍事件和DOM节点的联系,然后重点分析了事件的捕获及冒泡过程。相信看完本文,对事件的本质会有一个更透彻的理解。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号