
从决策树到XGBoost
说在前面
XGBoost自不必多做介绍,想必各位已是如雷贯耳。自XGB问世以来,不仅在各大比赛中一时风头无两,其不依赖特征工程的特点以及完善的API接口也使其成为工业界的宠儿。像我司很长一段时间以来排序模型使用的就是XGB。
不知道大家是否有这种感觉,虽然使用了很久的XGB,但总感觉自己还是原来那个调包侠,对XGB的原理及个中细节还是一知半解。如有同感,不如今天就跟着博主,痛下决心,狠狠撸它一把。
本文XGBoost部分基本照搬xgboost的原理没你想像的那么难一文。惭愧惭愧,非我恬不知耻,实在是 milter 大佬 写的太好了,是本人看到写XGB最好的一篇(这里再安利一下大佬的公众号 工程师milter)。不过本文从源头梳理了XGBoost的进化过程,其中不乏常见面试题答案,请放心食用。
闲话少说,正文开始。
决策树是集成学习模型中最常用的基分类器,因为其有诸多优点:
(1)可解释性强;
(2)不需要做太多特征工程;
(3)对不均衡样本有鲁棒性;
(4)决策树的表达能力和泛化能力可以通过调节树的层数来折中;
(5)在决策树节点分裂的时候,可以随机选择一个特征子集,很好地引入了随机性。
决策树
本部分主要参考李航老师的《统计学系方法(第2版)》第五章的内容。悄悄diss一下,如果是西瓜书读者,建议再读一遍《统计学系方法(第2版)》第五章。
本质上学习决策树,就是学习一系列 if/else 规则的集合。
决策树由结点和有向边组成;结点分为两种:内部结点和叶子结点;内部结点表示一个特征或属性;叶子结点表示一个类。
决策树的学习通常包括三个步骤:
(1)特征选择
(2)决策树生成
(3)剪枝
特征选择就是选取对训练数据具有分类能力的特征,是生成决策树的核心部分。决策树的生成只考虑局部最优,剪枝考虑的是全局最优。所以通过剪枝可以提高决策树的泛化能力,抑制过拟合。
根据特征选择的标准不同,有以下几个经典决策树算法。
ID3
这里就不介绍算法的来头等七七八八的了,咱们单刀直入,直击要点。
ID3 使用信息增益作为特征选择的标准。信息增益是什么?
先摆公式:信息增益 = 信息熵 - 条件熵(其实应该是 经验熵 - 条件经验熵,这里不妨碍理解)
信息熵用来衡量一个系统的混乱程度/不确定度。熵值越大说明系统越混乱,不确定度越高。想要深入了解信息熵,推荐这篇《信息为什么还有单位,熵为什么用 log 来计算?》。(ps:有没有感觉遇到一个宝藏博主)
条件熵(通常表示为H(Y|X) )表示在已知随机变量X的条件下随机变量Y的不确定度。
所以信息增益的含义就是在某个特征或条件下,系统不确定程度减少了多少。这个值当然是越大越好。
决策树生成过程简略如下:
(1)从根节点开始,计算所有特征的信息增益;
(2)选择信息增益最大的特征,然后以该节点的不同取值建立子结点;
(3)对子结点递归调用以上方法,直到终止条件。
另外,ID3没有剪枝策略,所以很容易过拟合。
C4.5
C4.5算法生成决策树的过程与ID3类似。
C4.5使用信息增益率作为特征选择的标准。因为信息增益作为划分准则时,对取值选择较多的特征存在偏向。
不过,信息增益率对取值较少的特征有所偏向。所以可以先从候选特征中找出信息增益高于平均的特征,再从中选择增益率高的特征。
C4.5的剪枝策略就直接放《统计学习方法》原文了。注意,决策树的损失函数是用来对决策树进行剪枝的,即帮助我们寻找更好的树结构(稍后再解释)。


CART
CART假设决策树是二叉树。ID3和C4.5有可能是多叉树,根据特征可选择的特征值数的多少。
ID3和C4.5只能用于分类,所以ID3和C4.5都是分类树,而CART既可以用于分类,也可以用于回归。
这里简单说下分类树和回归树的区别:
1、特征选择标准不同
(1)回归树使用 均方误差
(2)分类树使用 信息增益、增益率、基尼系数
2、达到终止条件时
(1)分类树,若叶子结点中样本的类目不唯一,以多数样本的类别作为该叶子结点的类别;
(2)回归树,若叶子结点中样本的值不唯一,以该叶子结点上所有样本的均值作为节点预测值。
CART分别作为分类树和回归树时,使用不同的特征选择标准。
作为回归树时使用均方误差,作为分类树时使用基尼系数(基尼系数最早是用来衡量贫富差距的,值越大则差距越大)。
至于CART的生成和剪枝,大家自己去看《统计学习方法》吧,我就不搬运了[微笑]。
到这里,三个经典的决策树算法基本介绍完了。那现在问大家一个问题,决策树的参数是什么?这个问题很重要,是后面理解XGB的关键。
确定一棵CART树需要确定两部分:第一部分就是树的结构,这个结构负责将一个样本映射到一个确定的叶子节点上,其本质上就是一个函数;第二部分就是各个叶子节点上的分数。
叶子节点上的分数作为模型参数很好理解,因为我们使用决策树预测时,某个样本的预测结果就是该样本所落到的叶子节点的值。再插一嘴,对于分类问题,这个值就是训练时该叶子节点上多数样本的类别;对于回归问题,这个值就是该叶子结点上所有样本的均值。也就是前面讲的分类树和回归树区别的第二点。
那为什么树的结构也是需要学习的参数呢?回想下当我们训练神经网络时,我们会先定义好网络的结构,网络中层与层之间的权重连接就是我们要学习的参数。但是对于一颗决策树来说,结构可以有千千万万种,我们无法事先知道哪种结构是最优的,所以说决策树的结构也是需要学习的参数。损失函数就是用来帮我们寻找最优结构的。对于普通决策树来说,寻找最优结构的方法就是先建树,再利用损失函数进行剪枝。而XGB一个强大的地方就在于我们可以通过计算得到衡量一个决策树结构好坏的标准,在建树时根据这个标准直接构建最佳结构的树,不需要单独进行剪枝操作。
有没有感觉通透了点?建立大家先休息几分钟,整理下决策树的知识点。
在该部分的最后,再帮大家简单梳理下三个经典决策树算法之间的区别:
(1)ID3、C4.5只能用于分类,CART可分类可回归;
(2)特征选择标准:信息增益、信息增益率、均方误差、基尼系数(自己对号入座吧);
(3)树的生成过程不同,ID3、C4.5类似;
(4)剪枝策略,ID3没有剪枝。
集成学习
集成学习是指采用某种策略,将多个分类器的结果合并起来,作为最终的预测结果。
为什么需要集成学习呢?
集成学习的核心思想就是“三个臭皮匠,胜过诸葛亮”。它没有创造出新的算法,而是把已有的算法进行结合,从而实现 1+1>2 的效果。
集成学习有两种主要的方法:bagging 和 boosting。
bagging 像是一个集体决策的过程,每个个体独立学习,最终决策时,通过投票的方式得到最终结果;boosting将基分类器层层叠加,每一层在训练的时候,对前一层基分类器分错的样本给予更高的权重。测试时,根据各层分类器的结果的加权得到最终结果。boosting又分为adaboost和GBDT两种。
其实还有一种集成学习方法——stacking。stacking的基本思路是学习几个不同的弱学习器,然后训练一个元模型来组合它们。例如,对于分类问题来说,我们可以选择 KNN 分类器、logistic 回归和SVM 作为弱学习器,然后使用LR模型来整合另外三个模型的结果。stacking不是今天的主角,这里就先跳过了。
bagging 和 boosting对比如下(知道你想要什么[狗头]):
| bagging | boosting | |
| 并行计算 | 各预测函数可以并行生成 | 串行,后一个模型需要前一轮模型的结果 |
| 样本选择 | 原始训练集有放回抽样,各训练集之间独立 | 每一轮训练集不变,只是训练集中每个样例在模型中的权重发生了变化 |
| 样例权重 | 每个样例权重相等 | 根据错误率不断调整样例的权值 |
| 预测函数 | 所有预测函数权重相等 | 误差小的分类器会有更大的权重 |
| 不均衡数据集处理 | 需要采样(bagging有放回抽样,很可能抽不到正例) | 不需要采样处理 ,因为每个使用全部样本 |
至于决策树为什么常被用作集成学习的基模型,在决策树开始部分已说过,这里不再赘述。
GBDT
前面说到,boosting方法有adaboost和GBDT两种。
XGB采用的就是GBDT的形式,本质上还是一个GBDT,所以先来看下GBDT。
adaBoost对于前一个分类器分错/分对的样本的权值会得到加强/削弱,加权后的全体样本再次被用来训练下一个基分类器。
GBDT的每一次计算都是为了减少上一次的残差(残差 = 真实值 - 预测值),然后在负梯度方向上建立一个新的模型。在预测阶段,GBDT将多棵树的结果累加得到最终的得分。
实际工程中,GBDT是计算负梯度,用负梯度近似残差。
为什么可以用负梯度近似残差?我们分几种情况来看。
1、对于回归问题
回归任务常用的损失函数为 MSE,即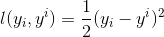 ,此时负梯度为
,此时负梯度为
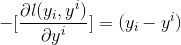
负梯度 = 真实值 - 预测值,即 负梯度 = 残差。
所以,当损失函数取MSE时,拟合负梯度就相当于拟合残差。
插播:GBDT如何用于分类
GBDT无论用于分类还是回归一直使用的CART回归树。
why?
核心原因是GBDT每轮的训练是在上一轮训练模型的负梯度值基础之上训练的,这就要求每轮迭代的时候,真实标签减去弱分类器的输出结果是有意义的,即残差是有意义的。如果选用的弱分类器是分类树,类别相减是没有意义的。
假设样本X总共有K = 3类[0,1,0],针对样本X每个可能的类都训练一个分类回归树,每轮训练中同时训练K = 3课树,对于每棵树预测值使用softmax来产生概率。
了解这些之后,我们可以继续了。
2、对于二分类
二分类常用的损失函数为 二元分类交叉熵,即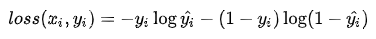 ,此时负梯度为
,此时负梯度为
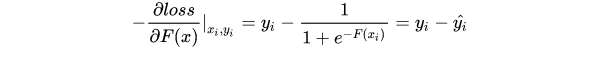
在分类问题中,GBDT需要拟合的残差为真实标签与预测概率之差。所以,当损失函数取二元分类交叉熵时,此时的负梯度为真实值与预测概率之差,也是残差。
3、对于多分类
针对每个可能的类都训练一个回归树,每轮训练中同时训练多课树,对于每棵树预测值使用softmax来产生概率。
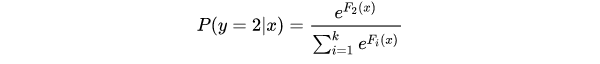
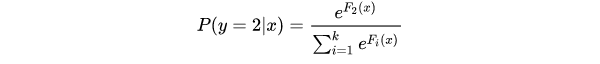

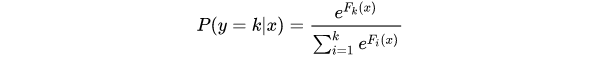
其中
是
个不同的tree ensemble。每一轮的训练实际上是训练了
棵树去拟合softmax的每一个分支模型的负梯度。softmax模型的单样本损失函数为:
这里的 是样本label在k个类别上作one-hot编码之后的取值,只有一维为1,其余都是0。由以上表达式不难推导:
所以,这k棵树同样是拟合了样本的真实标签与预测概率之差,即残差。
在结束本部分之前,再放送一条GBDT的优缺点:
XGBoost
XGB是怎样把速度和效果发挥的极致的?
算了,大家还是直接看《xgboost的原理没你想像的那么难》吧,写的实在是太好了,就不搬运了,我这篇就当是给大佬做铺垫了。
参考
2、《统计学习方法(第2版)》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号