
Transformer笔记
从宏观角度看transformer
1、首先将这个模型看成是一个黑箱操作。在机器翻译中,就是输入一种语言,输出另一种语言。

2、第二步,拆开这个黑箱,可以看到它由编码组件、解码组件以及它们之间的连接组成。
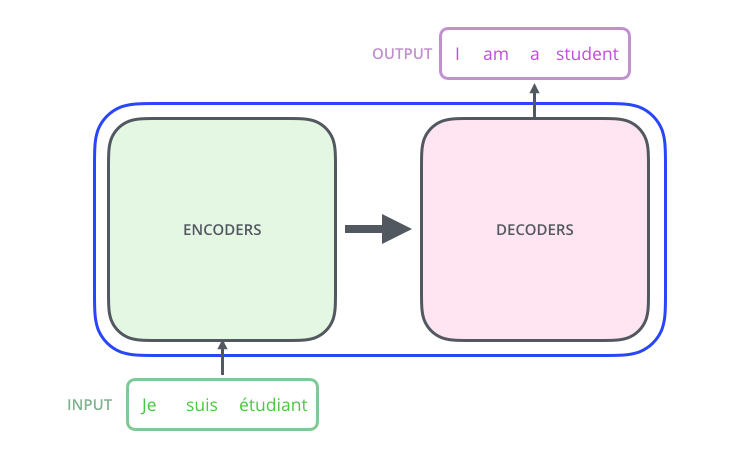
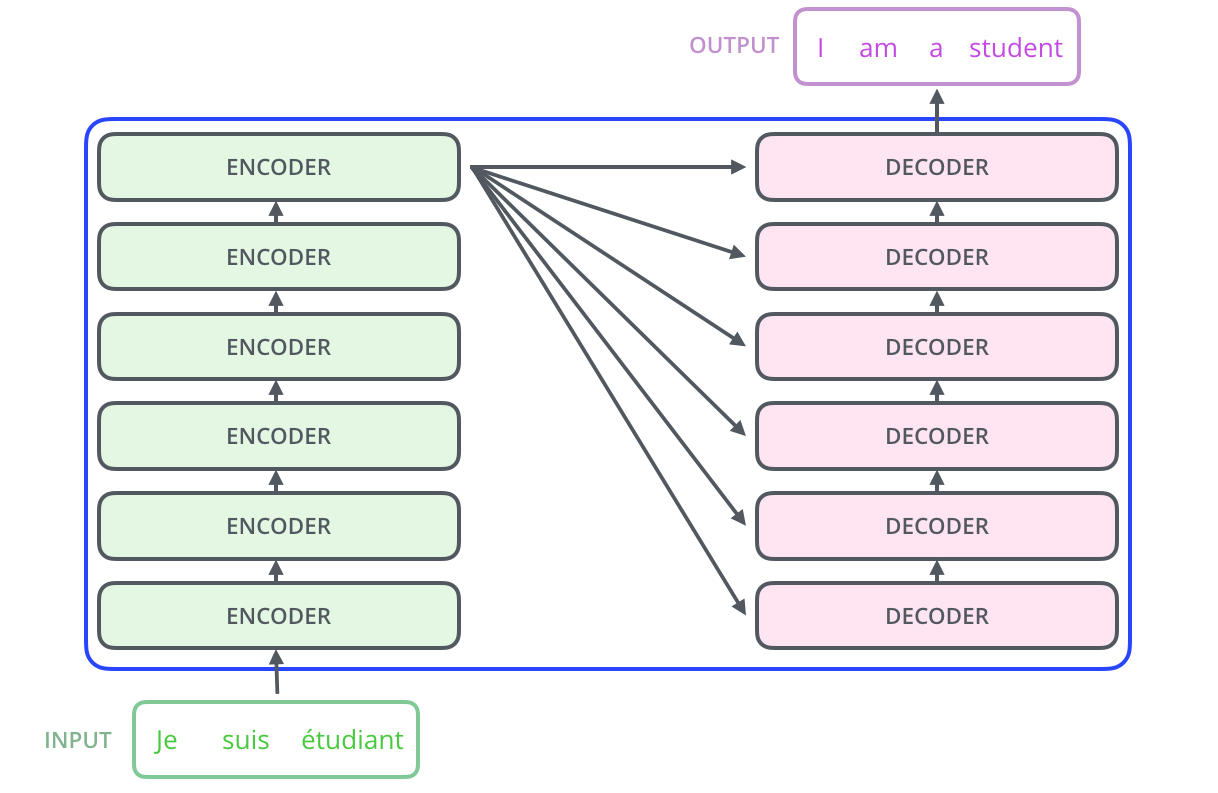
3、编码组件由一堆编码器(encoder)组成(论文中是将6个编码器叠在一起)。解码组件由相同数量的解码器(decoder)组成(也是6个)。
4、所有编码器在结构上是相同的 ,并且它们不共享参数。每个编码器可以分解成两个子层。
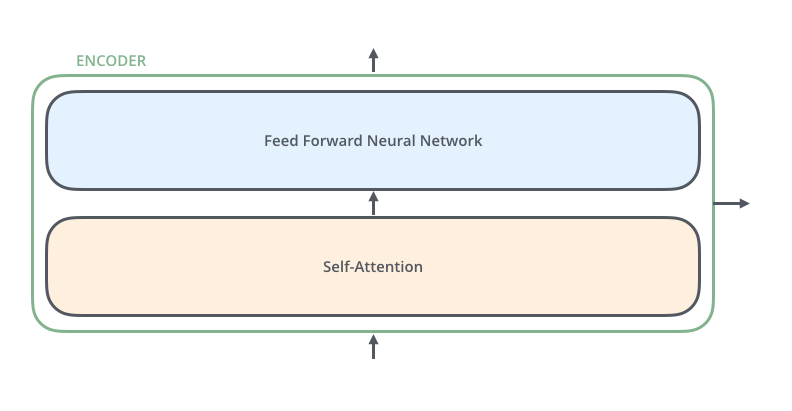
5、编码器的输入首先会经过一个 self-attention层,self-attention层帮助编码器在对每个单词进行编码时关注句子中的其他单词。
6、self-attention层的输出会传递到前馈神经网络层(feed-forward)中。
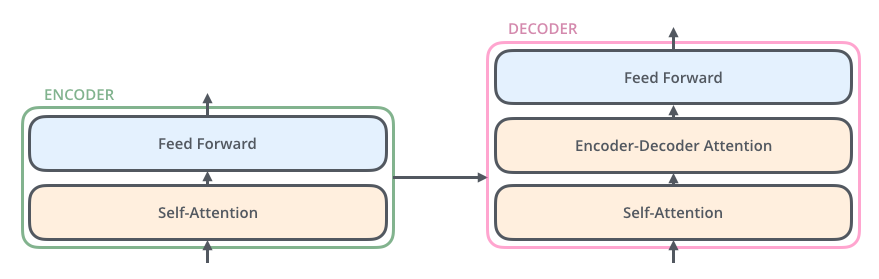
7、解码器中也有编码器中的self-attention层和前馈神经网络层。此外,在这两层中间还有一个attention层,用来关注输入句子的相关部分(和seq2seq模型的注意力作用相似,即目标单词到源单词的一种对齐机制)。
宏观角度理解self-attention
以翻译 “The animal didn't cross the street because it was too tired” 为例。
模型处理输入序列的每个单词时,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。
例如,当我们在编码“it”这个单词的时,注意力机制的部分会去关注“The Animal”,将它的表示的一部分编入“it”的编码中。
self-attention细节
如何计算self-attention?
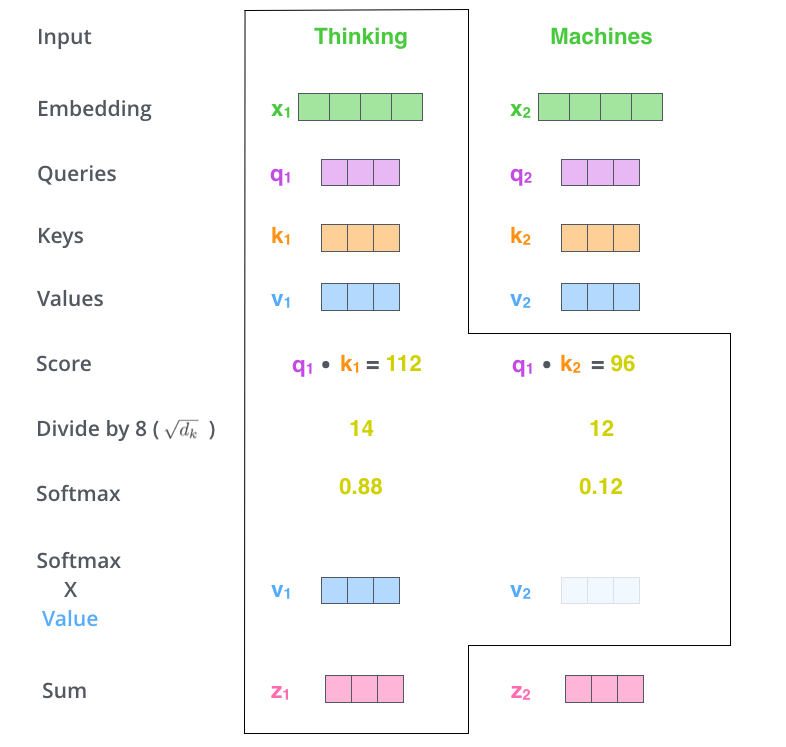
1、首先,从每个编码器的输入向量(每个单词的词向量)中生成三个向量:查询向量q、键向量k、值向量v;
这三个向量是通过词嵌入与三个权重矩阵相乘后创建的。
2、当我们要对句子中的某个词进行编码的时候,需要拿句子中的其他词对当前词进行打分,这个分数就代表了其他词对当前要编码的词的重要度。
怎么打分?
这些分数是通过句子中所有单词对应的键向量与“thinking”的查询向量做点积来计算的(关于attention权重计算方式可参考之前的博客Attention机制理解)。
3、为了使梯度更稳定,通常会将上一步的得分除以键向量维数的算术平方根(论文中键向量为64维,所以除以8);
4、然后对分数使用softmax函数进行归一化,这个softmax分数就代表了每个单词对当前编码的词的重要度;
5、将句子中每个单词的每个值向量乘以对应的softmax分数;
6、对加权值向量求和,最终得到self-attention层在该位置的输出。
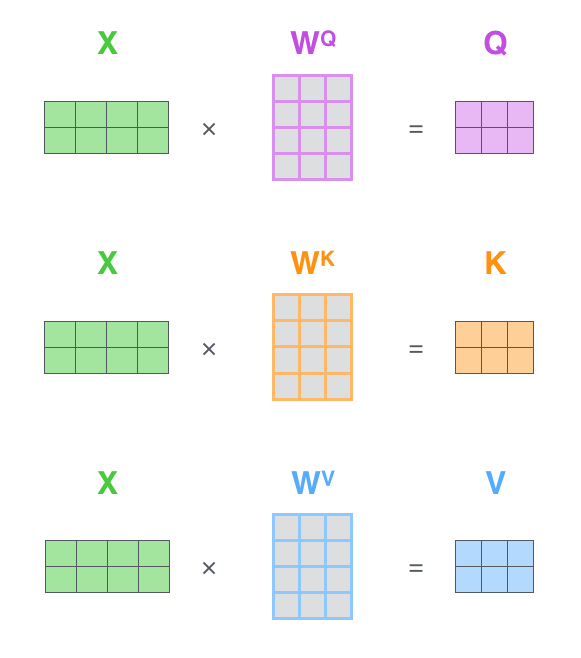
矩阵运算实现self-attention
1、计算查询矩阵、键矩阵、值矩阵;
2、利用矩阵操作,可以将上面2-6步骤合并在一起
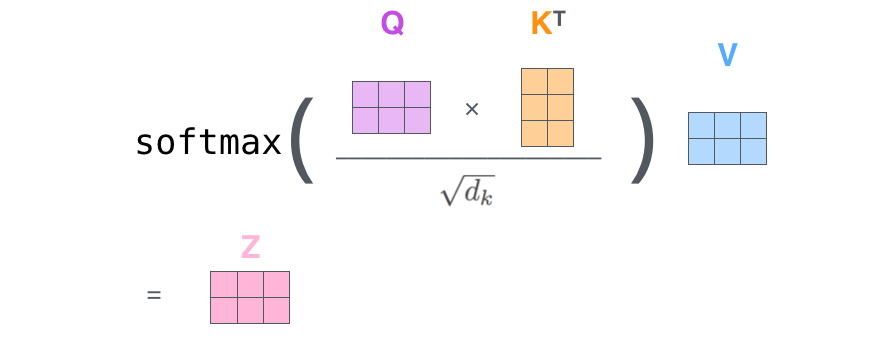
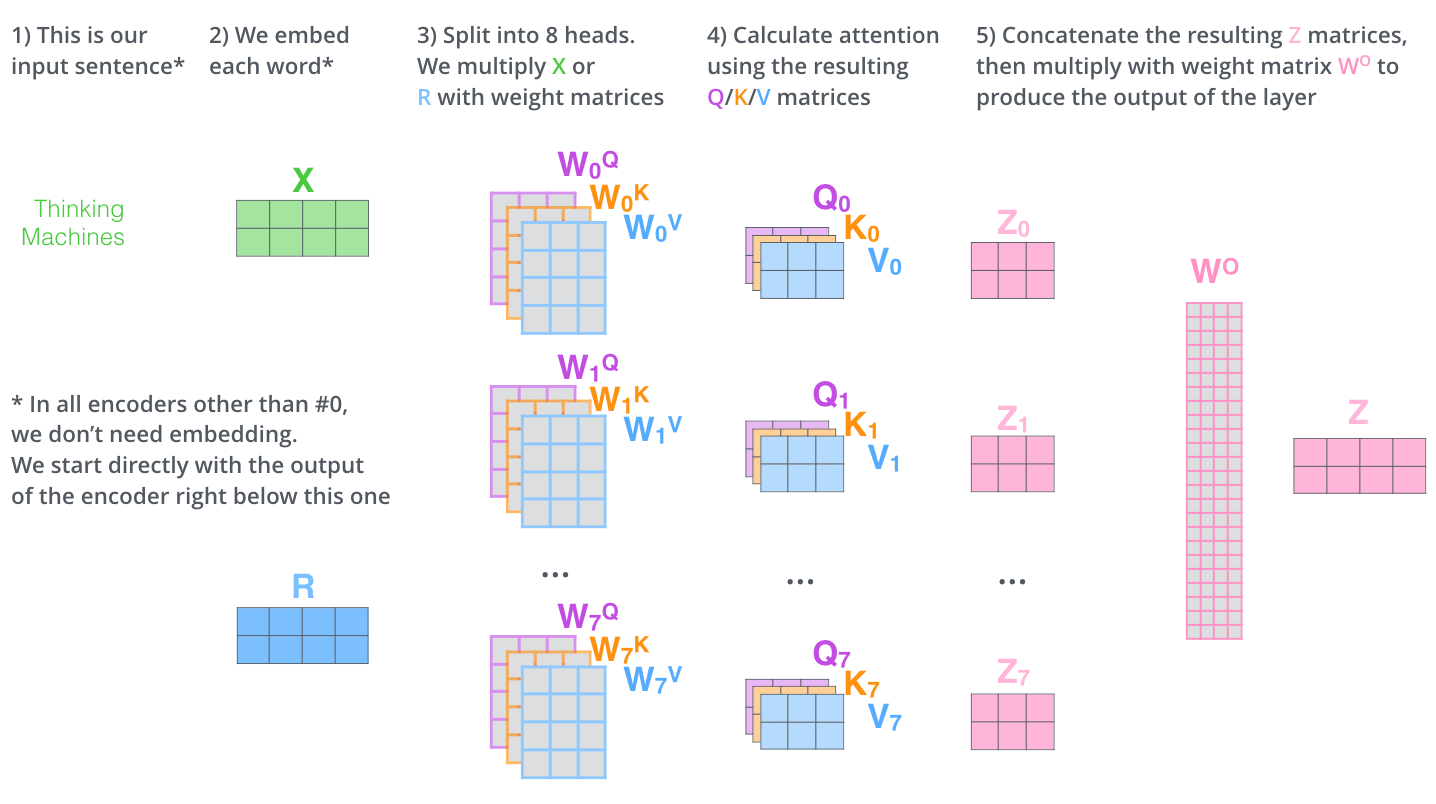
多头注意力机制
Multi-Head Attention相当于多个不同的self-attention的集成(ensemble)。
Multi-Head Attention的输出分成3步:
1、将数据输入到多个(论文中是8个)self-attention中,得到8个加权后的特征矩阵;
2、将8个特征矩阵拼接成一个大的特征矩阵;
3、特征矩阵经过一层全连接层之后得到最终的输出。
作用:
(1)扩展了模型专注于不同位置的能力;
(2)给出了attention层的多个“表示子空间”。
怎么理解呢?仍然以“The animal didn't cross the street because it was too tired”为例。当对 “it”这个词进行编码的时候,某个head关注的可能是“it”指代的是什么(即the animal),某个head关注的可能是为什么(即tired)。

位置编码
目的:为了让模型理解单词的顺序。
具体:位置编码会在词向量中加入了单词的位置信息,这样Transformer就能区分不同位置的单词了。
做法:1、根据数据学习;2、设计编码规则(常用)。
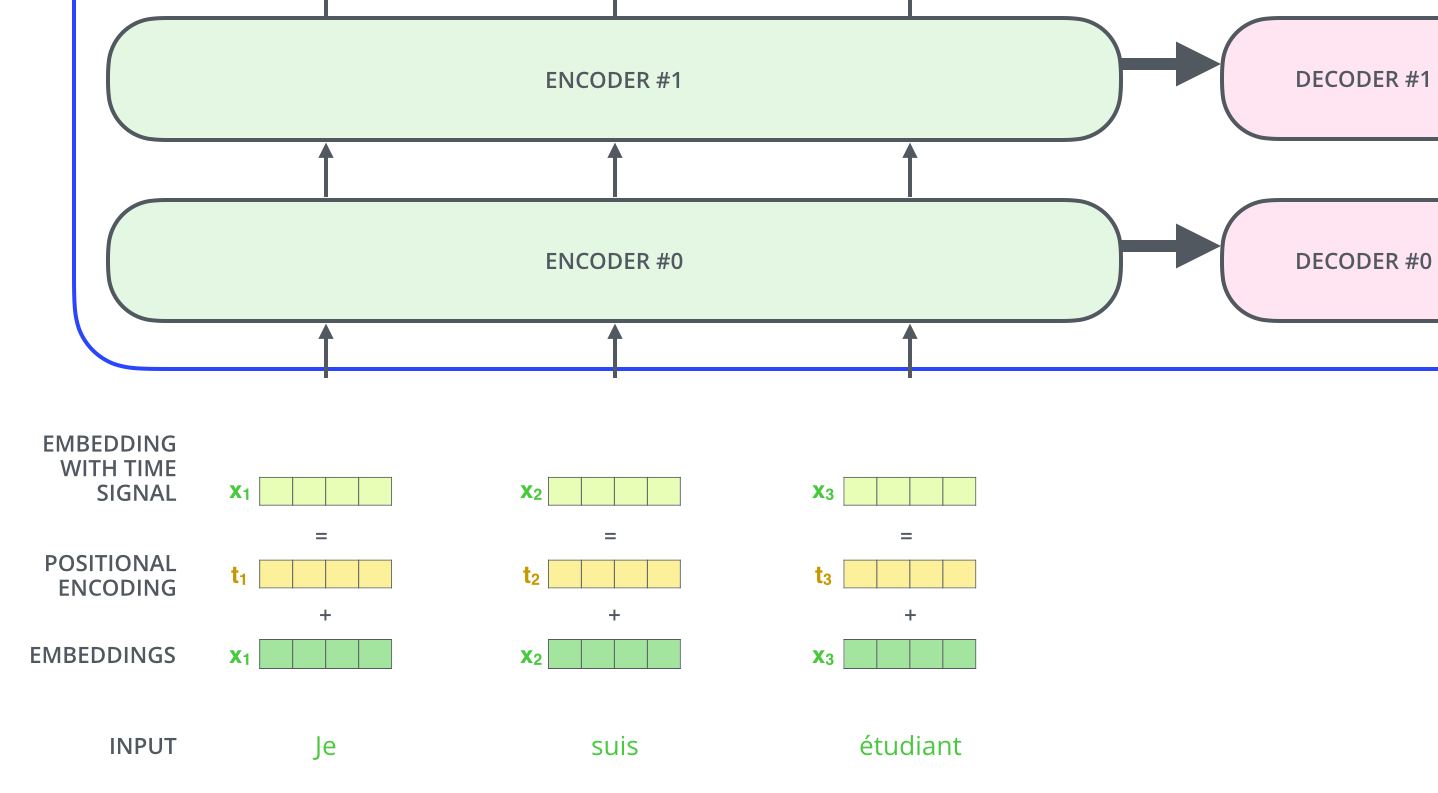
论文中,是将位置编码表示成和词向量相同维度的一个向量,然后和词向量进行加和。也可以根据句子长度,将位置编码成one-hot向量,然后concat到词向量上。 ![]()
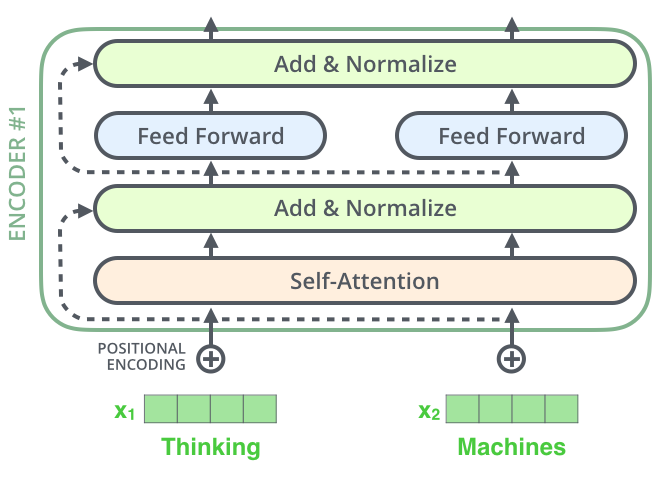
残差模块
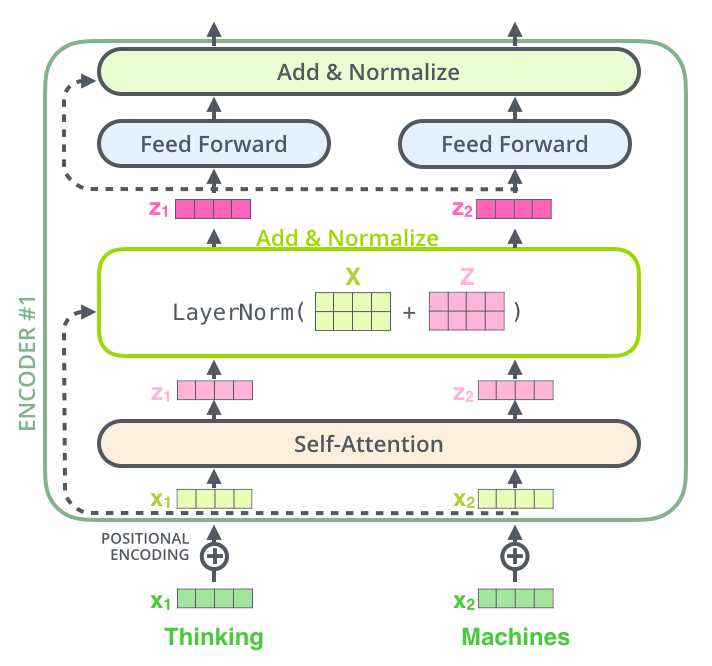
在每个编码器中的每个子层(self-attention、前馈网络)的周围都有一个残差连接,并且都跟随着一个layer-normalization步骤。
残差连接:防止梯度消失。
layer-normalization:LN的作用也不再多说,有问题参考之前的文章https://www.cnblogs.com/yijiewufu/p/14412422.html
编码器计算可视化
解码组件
解码器工作流程类似编码器,注意几个细节:
1、decoder的输入包括encoder的编码和上一时刻的预测;
2、解码器的self-attention层,只被允许处理输出序列中更靠前的那些位置,目的是防止信息泄漏,所以该层被叫做 Masked Mult-Head attention.
总结
Transformer的优点:
(1)使任意两个单词的距离变为1,对解决NLP中的长期依赖问题是非常有效的;
(2)并行性非常好。
Transformer存在的问题:
(1)抛弃RNN和CNN结构,使模型丧失了捕捉局部特征的能力;
(2)丢失了位置信息,在特征向量中加入Position Embedding也只是权宜之计,没有改变Transformer结构上的缺陷。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号